
- 1已解决:pycharm上传代码更新到GitHub的时候怎么更新到对应的 Releases 中_github 发布release
- 2【虚拟化】虚拟机xml文件解析_虚拟机xml文件配置
- 3Spring Cloud Zuul-“网关“灰度发布S_灰度发布如何处理新旧流量切换时未处理完的请求
- 4基于k8s实现算法训练系统(架构思路+落地方案)_算法训练管理
- 5postgresql【数据库管理】用户权限、更改密码、数据备份、启动、停止、重启动数据库_postgres本地账户和密码
- 6基于ChatGPT API的PC端软件开发过程遇到的问题的分析_chatgpt api 开发
- 7Scrapy 爬取旅游景点相关数据( 二 )
- 8使用香橙派Kunpeng Pro自建网站服务器_香橙派可以制作为服务器吗
- 9BadDet: Backdoor Attacks on Object Detection——面向目标检测的后门攻击_attack object detection
- 10从0到1搭建文档库——sphinx + git + read the docs_readthedocs搭建
【Kafka】Kafka与flume整合(四)_kafka flume
赞
踩
Kafka和Flume整合
Kafka与flume整合流程
Kafka整合flume流程图
flume主要是做日志数据(离线或实时)地采集。
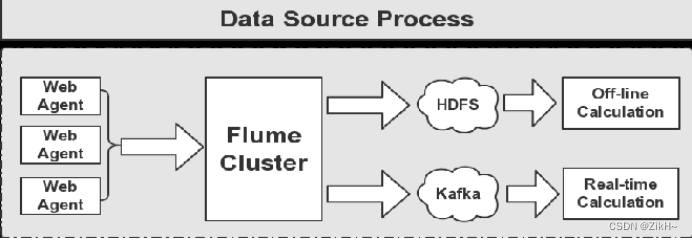
图-1 数据处理
图-1显示的是flume采集完毕数据之后,进行的离线处理和实时处理两条业务线,现在再来学习flume和kafka的整合处理。
配置flume.conf文件
配置如下:
//为我们的source channel sink起名
a1.sources = r1
a1.channels = c1
a1.sinks = k1
//指定我们的source收集到的数据发送到哪个管道 a1.sources.r1.channels = c1
//指定我们的source数据收集策略
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /opt/module/flumedata
a1.sources.r1.deletePolicy = never
a1.sources.r1.fileSuffix =.COMPLETED
a1.sources.r1.ignorePattern = ^(.)*\.tmp$
a1.sources.r1.inputCharset = UTF-8
//指定我们的channel为memory,即表示所有的数据都装进memory当中 a1.channels.c1.type = memory
//指定我们的sink为kafka sink,并指定我们的sink从哪个channel当中读取数据
a1.sinks.k1.channel = c1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k1.kafka.topic = hadoop
a1.sinks.k1.kafka.bootstrap.servers=hadoop101:9092,hadoop102:9092,hadoop103:9092
a1.sinks.k1.kafka.flumeBatchSize = 20 a1.sinks.k1.kafka.producer.acks
= 1
启动flume和kafka的整合测试
1)消费者监听读取的数据。
[root@hadoop102 kafka]$ bin/kafka-console-consumer.sh
–topic test
–bootstrap-server hadoop101:9092,hadoop102:9092,hadoop103:9092
–from-beginning
2)启动flume-agent。
[root@hadoop101 flume]$ bin/flume-ng agent --conf conf --conf-file
conf/flume_kafka.conf --name a1 -Dflume.root.logger=INFO,console
3)发送与接收数据验证。
4)验证结果:显示的发送与接收数据,可以说明flume和kafka的整合成功。

