
- 1基于webgl高性能地图解决方案:二次开发keper.gl地图可视化分析工具 - openstreetmap街道地图离线部署(一)_openstreetmap离线部署
- 2信息安全等级保护的政策依据及相关标准_1999年信息安全保障文件27号文件是什么
- 3并查集(Union-Find Disjoint Sets)_并查集csdn
- 4黑苹果/Mac如何升级 Mac 新系统 Sequoia Beta 版_macos更改beta版更新所用账号
- 5挑战CSS难点:解决子元素继承父元素opacity属性的技巧_css opacity不继承
- 6oracle数据和mysql库基本语句_数据库基本概念及Oracle基本语句
- 7无情的独裁者-特斯拉的马斯克_space x 马斯克 没有人情味的老板
- 8java word模版占位符替换(${xx})替换_java替换word占位符并保留其格式
- 9Three.js机器人与星系动态场景(四):封装Threejs业务组件
- 10c语言 数据结构栈的创建_建立栈数据结构
三、茴香豆:搭建你的 RAG 智能助理_rag包含native rag?
赞
踩
(1)RAG 基础知识介绍

茴香豆是一款新的应用,由于没有使用相关的资料去训练模型,原始的InternLM2-Chat-7B模型便无法回答相关问题、胡编乱造
传统上:
- 采集新增语料
- 微调再训练
传统解决方法的缺点:
- 知识更新太快
- 语料知识库太大
- 训练成本高
- 语料难以收集
RAG技术概述:

RAG很好地解决了上述问题,无需额外训练。其最大的特点是解决大模型处理知识密集任务时的各种挑战。
RAG工作原理:
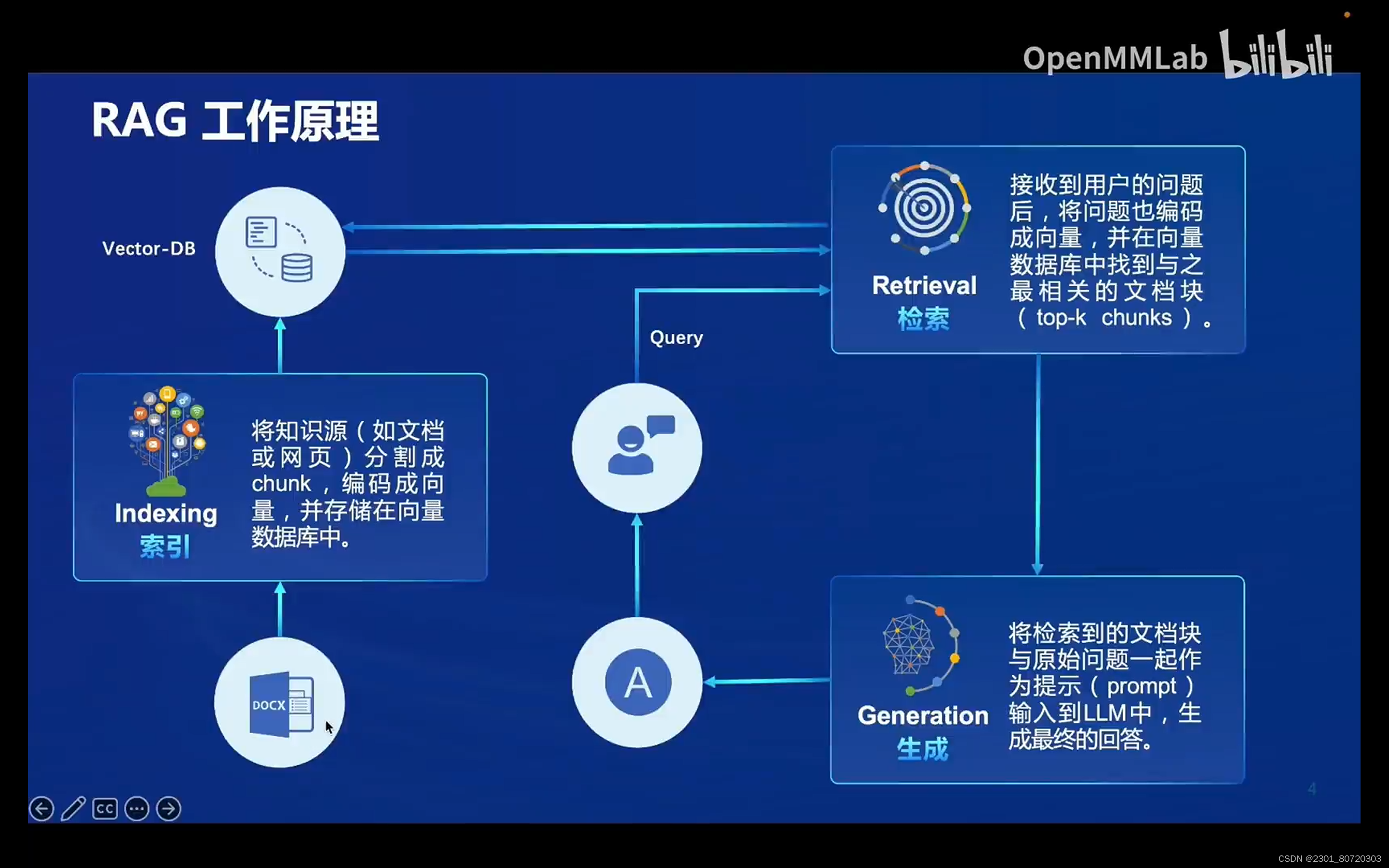
- 从外部知识源检索相关信息,并将这些信息用于指导语言模型生成更准确、更丰富的回答
- RAG相当于搜索引擎,用户输入的内容相当于索引,大模型生成的内容作为回答
向量数据库:

通过余弦相似度或点乘来判断向量之间的相似度,然后根据相似度的排分进行结果的排序,把最相关的内容用于后续回答的生成。
在面向大规模的数据以及需要高速响应的需求时,向量数据库也是需要优化的,其中非常重要的是对向量表示的优化,例如使用更高级的文本编码技术、更好的预训练模型,也包括尝试不同的句子、段落嵌入
RAG流程示例:
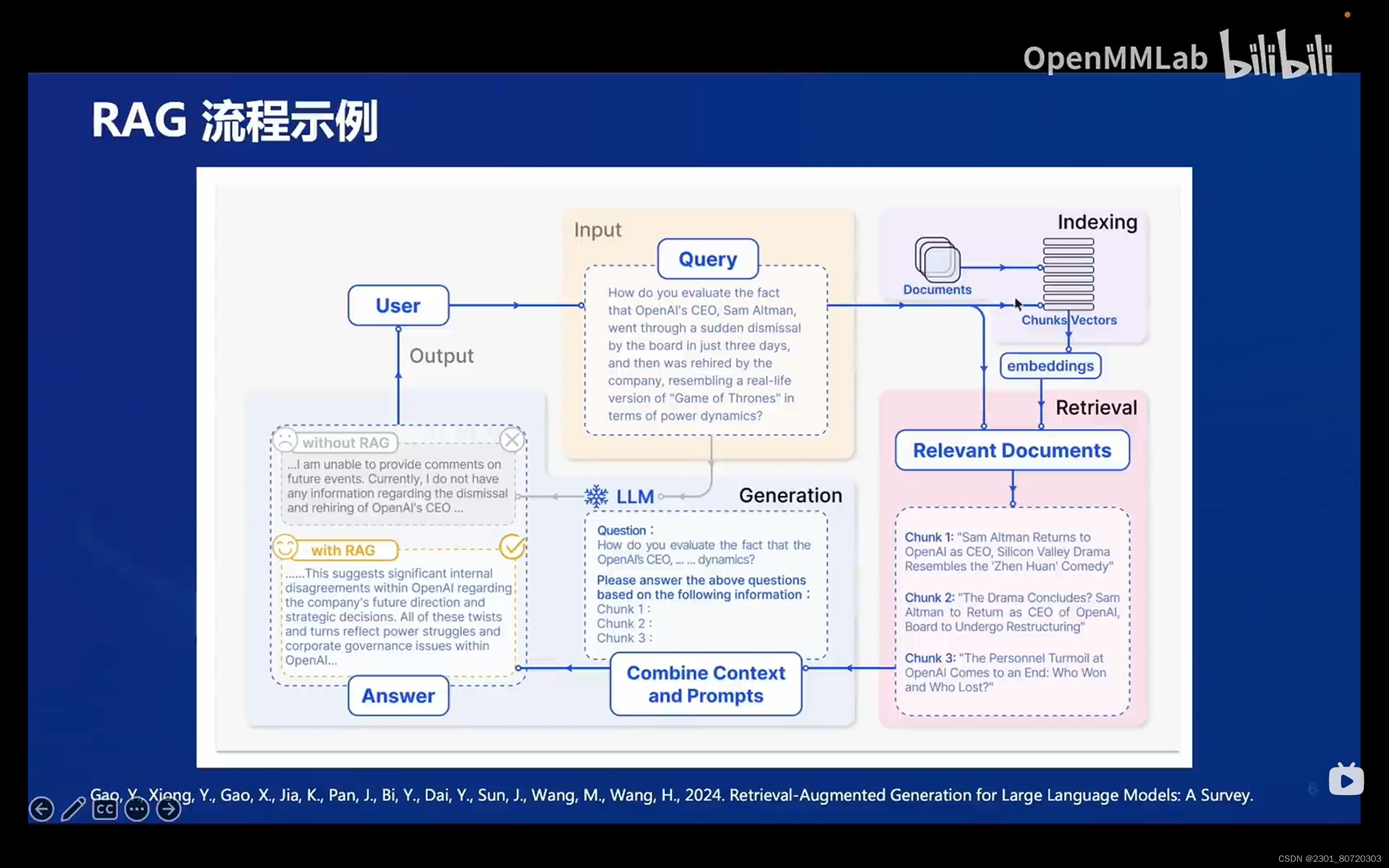
Indexing(索引) Retrieval(检索) embeddings(嵌入) Chunks Vectors(向量数据库)
RAG无需训练,只需更新向量数据库即可
RAG发展进程:
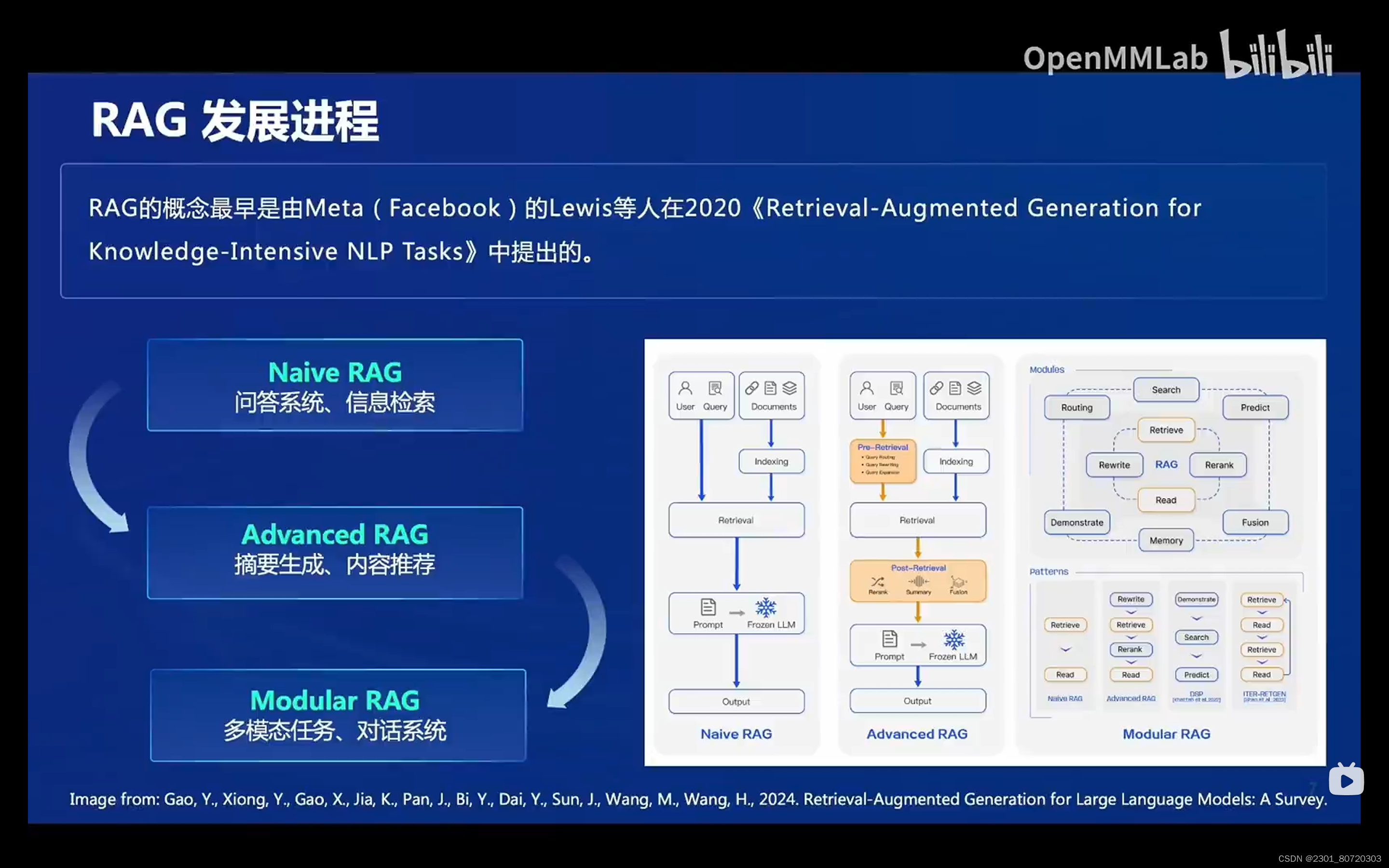
Native RAG:索引、检索、生成三个基础部分
Advanced RAG:在三个基础部分(索引、检索、生成)之外,对检索前后都进行增强,在检索之前对用户的问题进行路由扩展、重写等,对检索到的信息进行重排序、总结融合等处理,使信息处理和收集能力更高
Modular RAG:将RAG的基础部分和后续各种优化技术及功能模块化,可以根据实际业务需求定制,完成如图中更高级的应用
RAG常见优化方法:
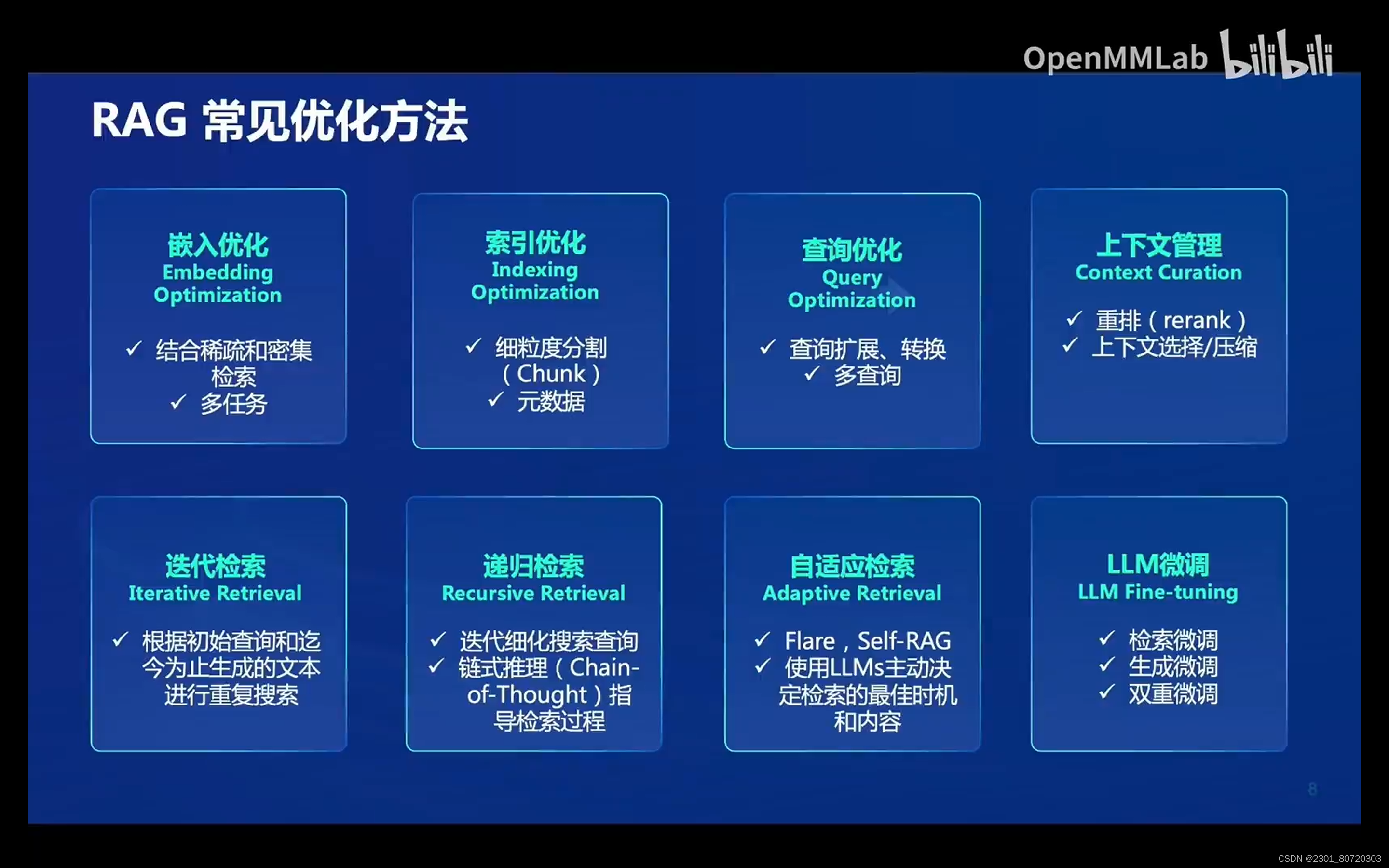
嵌入优化、索引优化:这两种方法通过提高向量数据库的质量,来对RAG进行性能的提升
上下文管理:通过如图中的方法减少检索的冗余信息,并提高大模型的处理效率。如可以使用小一点的语言模型,来检测和移除不重要的标记,或者训练信息提取器和压缩器
查询优化、上下文管理:advice中RAG前检索后检索部分
迭代检索:为大模型生成提供全面的知识基础
递归检索:通过迭代细化搜索查询来改进搜索结果的深度和相关性,使用链式推理指导检索过程并根据检索结果细化推理过程
自适应检索:让大模型能够自主的决定其所要检索的内容
迭代检索、递归检索、自适应检索:retrieval检索部分是优化中的重中之重
LLM微调:优化RAG一种常见的思路,可根据场景和数据特征,对大模型进行定向微调;对模型生成和参与进行针对性微调。
RAG VS 微调(Fine-tuning):

提示工程(不建议)
RAG总结:

(2)茴香豆介绍

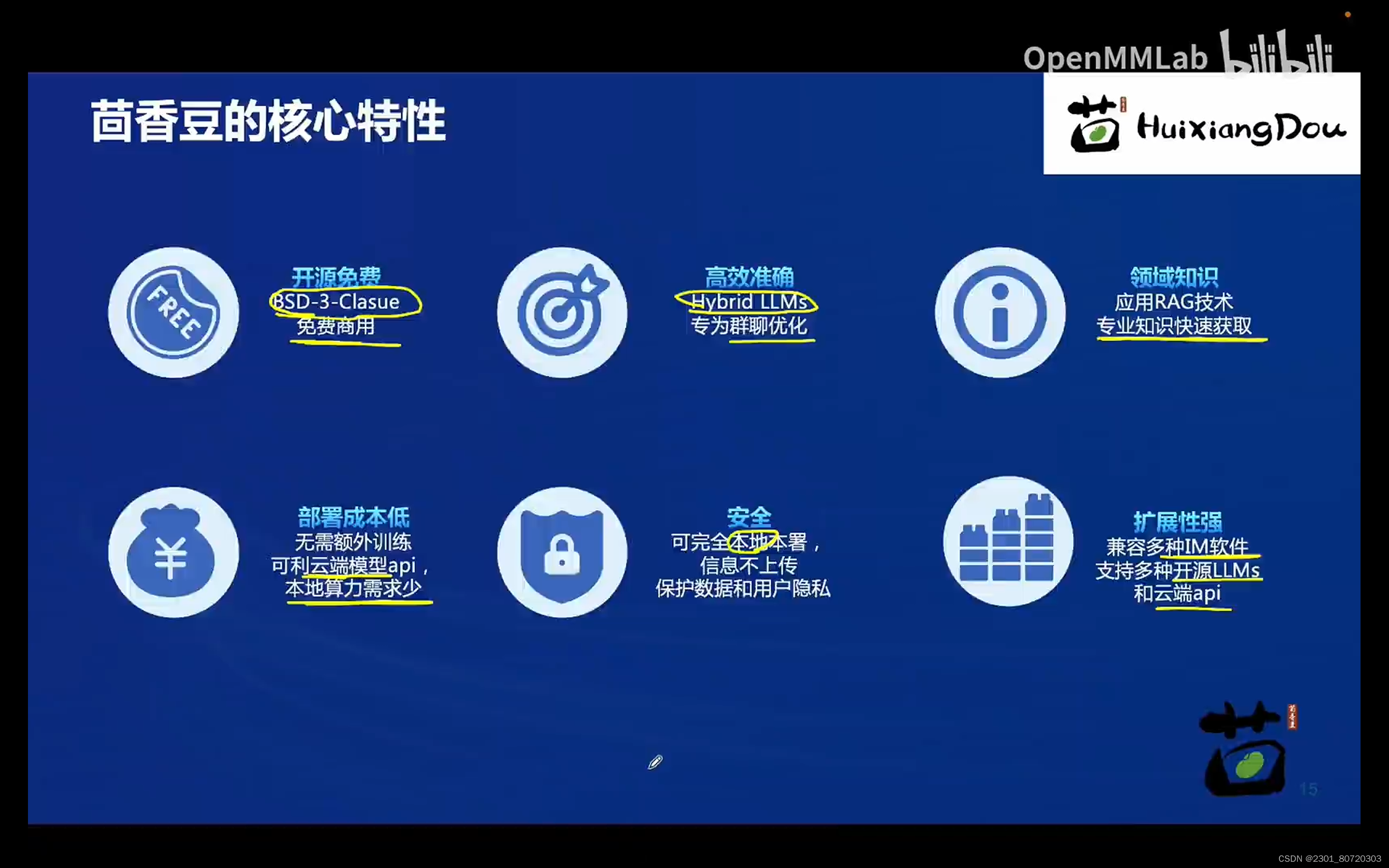
核心特性:
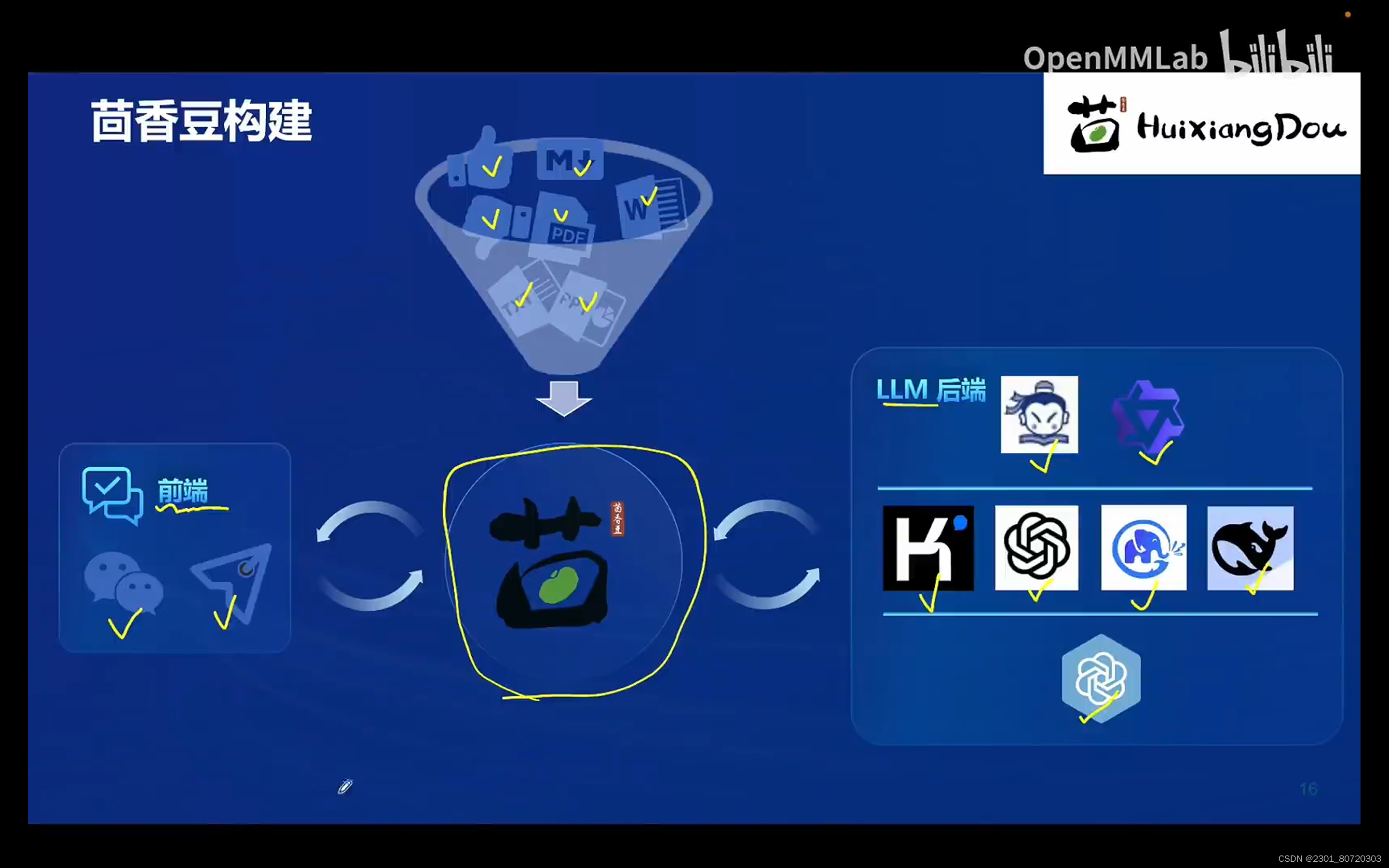
构建:
工作流:


其应答模块采用多来源检索、混合检索、安全评估来保证输出内容的准确性
其综合多来源检索到的信息,通过评分来控制内容筛选,方便控制输出内容的严谨性


