
- 1Web Security Tool---SSLyze介绍
- 2合合信息:引领智能文档处理革命,秒级的大模型加速器_waic 合合信息
- 3【C++入门(上)】—— 我与C++的不解之缘(一)
- 4如何有效的谈薪资_公司缺人谈薪资
- 5Rust在内存安全方面的优势如何体现?有哪些内存安全实践?_rust为什么没有内存泄漏
- 6cc2540 communication_gap establish link request
- 7Qt编译错误“GL/gl.h:No such file or directory”的解决方法_:-1: error: cannot find -lgl: no such file or dire
- 8再见Spring Security!推荐一款功能强大的权限认证框架,用起来够优雅!
- 9Openlayers根据kml文件绘制地图_vue+openlayers 加载kml
- 10挥手2020 | 齐飞同学年度总结 | 送你一朵小红花_上天并没有特别喜欢谁、不喜欢谁 ,它只是要求我们都努力地活着,好好品味得失,认真活好每一分钟,珍惜当
Spark数据倾斜解决原理和方法总论_spark 数据均衡
赞
踩
本博文主要包含以下内容:
一:均衡数据是我们的目标,或者说我们要解决数据倾斜的发力点。
一般说shuffle是产生数据倾斜的主要原因,为什么shuffle产生数据倾斜主要是因为网络通信,如果计算之前通过ETL(ETL(Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程)作为BI/DW(Business Intelligence)的核心和灵魂,能够按照统一的规则集成并提高数据的价值,是负责完成数据从数据源向目标数据仓库转化的过程,是实施数据仓库的重要步骤。如果说数据仓库的模型设计是一座大厦的设计蓝图,数据是砖瓦的话,那么ETL就是建设大厦的过程。)等工具作用是很强有力的,
1、去掉shuffle,是解决数据倾斜最好的方式,我们能不进行shuffle就不进行shuffle,广播可以减少shuffle。
2、采用好的数据结构和序列化方式,可以非常好的减少数据量以及提高性能。
3、Spark基于RDD构建了整个调度体系和生态体系,工作核心之一就是复用,而且是基于内存的复用,对RDD的复用,最小化每个job的工作,这样能极大化的减少数据倾斜。
二:数据倾斜解决之Map 端Reduce及问题思考
1、我们尽可能的将Reduce端放在Map端,我们就避免了shuffle,避免了shuffle我们就在很大情况下化解了数据倾斜的问题。
2、什么叫MappedReduce,整个spark是Rdd的链式操作,我们的DAGScheduler根据不同得RDD类型的依赖关系划分成不同的stage,不同类型依赖关系就是宽依赖和窄依赖。宽依赖的时候把stage换分成更小的stage,我们想做的事是把宽依赖减掉,避免掉shuffle,把操作直接放在map端。从stage角度讲,后边stage都是前面前面stage都是后边stage的map的。对我们解决数据倾斜很有帮助。
三:Spark数据倾斜解决之采样分而治之解决方案
1、我们首先谈一下什么叫采样?
我们有一个数据的集合,我们根据一定的规则选取数据的一部。采样一般情况下不能超过30%,采样算法的优劣,决定采样的效果,采样的结果能否更好的代表我们的全局变量。数据倾斜主要某个或某几个key的value特别多,key是我们数据分类的依据,如果我们能找出哪个或者哪几个key导致数据倾斜,这就是完成问题第一步,如果找到我们就可以采用分而治之的办法解决问题。
2、RDD1和RDD2进行Join操作,其中我们采用采样的方式发现RDD1中有严重的数据倾斜的Key:
第一步:采用Spark RDD中提供的采样接口,我们可以很方便的对全体例如100亿条数据进行采样,然后基于采样的数据我们可以计算出哪个(哪些)Key的Values个数最多;
第二步:把全体数据分成两部分,即把原来一个RDD1变成RDD11和RDD12,其中RDD11代表导致数据倾斜的Key,RDD12中包含的是不会产生数据倾斜的Key;
第三步:把RDD11和RDD2进行Join操作,且把RDD12和RDD2进行Join操作,然后把分别Join操作后的结果进行Union操作,从而得出和RDD1与RDD2直接进行Join相同的结果。
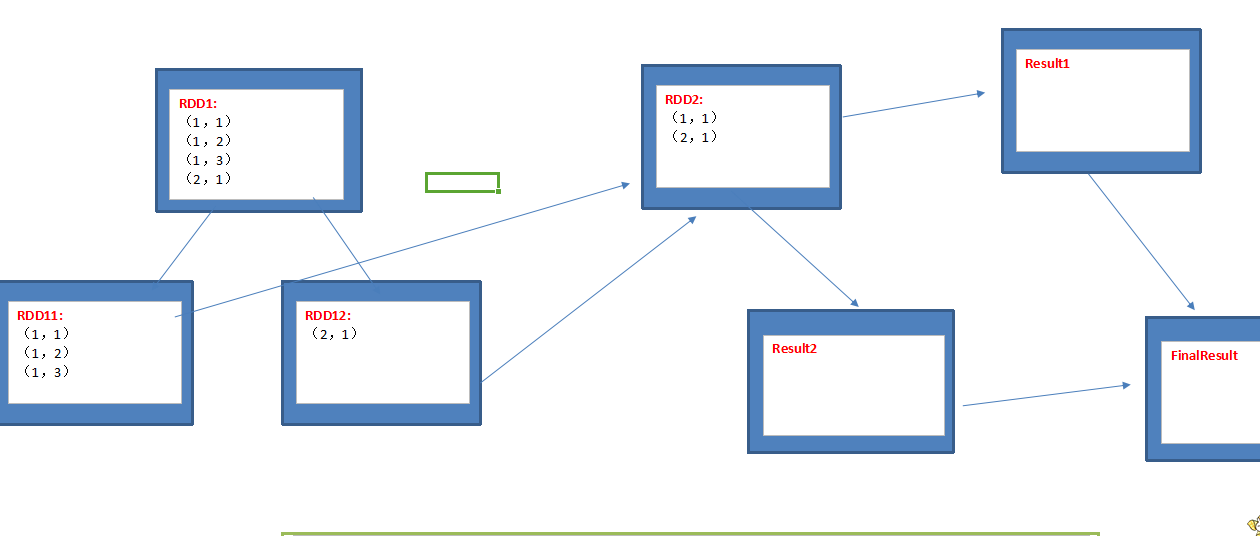
上述流程中:
第一种情况:如果RDD11中的数据量不是很多,可以采用map端的join操作,避免了Shuffle和数据倾斜;
第二种情况:如果RDD11中的数据量特别多,此时之所以能够缓解数据倾斜,是因为采用了Spark Core天然的并行机制对RDD11中的同样一个Key的数据进行了拆分,从而达到让原本倾斜的Key分散到不同的Task的目的,就缓解了数据倾斜;
补充说明:在上述过程中如果把倾斜的Key加上随机数,会怎么样?
加上随机数,并行task数量可增加,具体是如何操作的呢?
RDD11中的倾斜的Key加上1000以内的随机数,然后和RDD2进行Join操作?不行!此时我们一定需要把RDD11中的Key在RDD2中的相同的Key进行1000以内的随机数,然后在进行Join操作,这样做的好处:
让倾斜的Key更加不倾斜,在实际生产环境下会极大的解决在两个进行Join的RDD数量都很大且其中一个RDD有一个或者两三个明显倾斜的Key的情况下的数据倾斜问题
四:Spark据倾斜解决之对于两个RDD数据量都很大且倾斜的Key特别多如何解决?
1、两个RDD数据都特别多且倾斜的Key成千上万个,该如何解决数据倾斜的问题?
初步的想法:在倾斜的Key上面加上随机数
该想法的原因:shuffle的时候把key的数据可以分到不同的task里去
但是:现在的倾斜的key非常之多,成千上万,所以如果说采样找出倾斜的key的话并不是一个非常好的想法
Next?扩容?
首先,什么是扩容?就是把该RDD的中的每一条数据变成5条、10条、20条等,例如RDD中原来是10亿条数据,扩容后可能变成1000亿条数据;
其次,如何做到扩容?flatMapToPair 中对要进行扩容的每一条数据都通过0~N-1个不同的前缀变成N条数据。(不同的key,把我们原先的数据分散到不同的Task中)
2、问题:N的值可以随便取吗?需要考虑当前程序能够使用的Core的数目
答案:N的数字一般不能够取的特别大,通常都会小于50,否则会对磁盘、内存和网络都会形成极大的负担,例如会造成OOM
接下来:
1、将另外一个RDD的每条数据都打上一个n以内的随机前缀。2,最后将两个处理后的RDD进行join即可。
N这个数字取成10和取成1000除了OOM等不同以外,是否还有其它的影响呢?其实N的数字的大小还会对数据倾斜的解决程度构成直接的影响!N 越大,越不容易倾斜,但是也会占用更多的内存、磁盘、网络以及(不必要的)消耗更多的CPU时间。非倾斜的key被无辜扩容啦。
模拟代码:
RDD1 join RDD2
rdd2 2= RDD2.flatMap {
for(1 to 10) {
1_item
}
}
rdd11 = RDD1.map{
Random(10)
random_item
}
result = rdd11.join(rdd22)
result.map{
item_1.split 去掉前缀
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
五: Spark系列之数据倾斜解决之并行度的深度使用
1、用并行度解决数据倾斜的基本应用:例如reduceByKey
改变并行度之所以能够改善数据倾斜的原因在于,如果某个Task有100个Key且数据量特别大,就极有可能导致OOM或者任务运行特别缓慢,此时如果把并行度变大,则可以分解该Task的数据量,例如把原本该Task的100个Key分解给10个Task,这个就可以减少每个Task的数据量,从而有可能解决OOM和任务慢的问题。
对于reduceByKey而言你可以传入并行度的参数,也可以自定义Partitioner
增加Executor:改变计算资源,从仅仅数据倾斜的角度来看并不能够直接去解决数据倾斜的问题,但是也有好处,好处是同时可以并发运行更多的Task,结果是可能加快了运行速度。
2、用并行度解决数据倾斜的高级使用:例如reduceByKey
假设说有倾斜的Key,我们给所有的Key加上一个随机数,然后进行reduceByKey操作;此时同一个Key会有不同的随机数前缀,在进行reduceByKey操作的使用原来的一个非常大的倾斜的Key就分而治之变成若干个更小的Key,不过此时结果和原来不一样,怎么破?进行map操作,map操作的目的是把随机数前缀去掉,然后再次进行reduceByKey操作,(当然,如果你很无聊,可以再次做随机数前缀),这样我们就可以把原本倾斜的Key通过分而治之方案分散开来,最后又进行了全局聚合。在这里的本质还是通过改变并行度去解决数据倾斜的问题。
六: Spark系列之数据倾斜解决方案的“银弹”是什么?
1、逃离Spark技术本身之外来如何解决数据倾斜的问题?
之所以会有这样的想法,是因为从结果上来看,数据倾斜的产生来自于数据和数据的处理技术,前面内容和大家分享都是数据的处理技术层面如何解决数据倾斜,因此,我们现在需要回到数据的层面去解决数据倾斜的问题:
数据本身就是Key-Value的存在方式,所谓的数据倾斜就是说某(几)个Key的Values特别多,所有如果要解决数据倾斜,实质上是解决单一的Key的Values的个数特别多的情况,新的的数据倾斜解决方案由此诞生了:
(1)把一个大的Key-Values的数据分解成为Key-subKey-Values的方式;(用一个ETL方式就可以,或者Hive)
(2)预先和其他表进行join,将数据倾斜提前到上游的Hive ETL;
(3)可以把大的Key-Values中的Values组拼成为一个字符串,从而形成只有一个元素的Key-Value;
(4)加一个中间适配层,当数据进来的时候进行Key的统计和动态排名,基于该排名动态的调整Key分布;
假如10万个Key都发生了数据倾斜,如何解决呢?
此时一般就是加内存和Cores!

