
- 1Python | 02.下载视频(普通视频、m3u8加密视频ts)_m3u8下载 请求头
- 2Python大数据处理:利用Python处理海量数据_你在使用 python 进行数据分析时,如何处理大型数据集(例如大于内存大小的文件)?
- 3进程 zabbix_记录一次线上zabbix监控数据库占用硬盘过多处理
- 4xkISP 开源IP核的使用
- 5cvpr2016 paper list_2016cvpr期刊目录
- 6SpringBoot项目中实现返回结果和枚举类的国际化_springboot接口返回封装类国际化
- 7Python数据可视化:分析某宝商品数据,进行可视化处理_基于python淘宝数据可视化
- 8Everypixel: AI图片搜索引擎
- 9好用的弱口令字典
- 10开源人脸融合 AI换脸工具-FaceFusion
Transformer简版实战教程_transformer实战
赞
踩
Transformer简版实战教程
至于Transformer的理论内容可以参考Transformer 与 Attention和Transformer 与 Attention的一些Trick
本文主要实战, 这是一个简单版本的Transformer实现,也便于大家理解。

准备
需要准备的是翻译的语料集sentences以及模型参数src_vocab-输入词表, tgt_vocab目标词表,src_len 和tgt_len是句子的最大长度,d_model是hidden_size维度大小, d_ff是前馈网络中间CNN的输出维度。n_layers 是transformer block的个数,n_heads是头的个数, 因此多头的后最后维度为d_model/n_heads(64)。注意ich mochte ein bier P中的’P’是Padding值。
## 语料集准备 sentences = ['ich mochte ein bier P', 'S i want a beer', 'i want a beer E'] ## 模型参数 src_vocab = {'P': 0, 'ich': 1, 'mochte': 2, 'ein': 3, 'bier': 4} src_vocab_size = len(src_vocab) tgt_vocab = {'P': 0, 'i': 1, 'want': 2, 'a': 3, 'beer': 4, 'S': 5, 'E': 6} ## 目标词表大小 number_dict = {i: w for i, w in enumerate(tgt_vocab)} ## tgt_vocab_size = len(tgt_vocab) src_len = 5 # length of source tgt_len = 5 # length of target d_model = 512 # Embedding Size d_ff = 2048 # FeedForward dimension d_k = d_v = 64 # dimension of K(=Q), V n_layers = 6 # number of Encoder of Decoder Layer n_heads = 8 # number of heads in Multi-Head Attention

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
Transfomer
Transformer主要是由encoder、decoder和Linear组成。
输入:
- enc_inputs:[batch_size, src_len, hidden_size]
- dec_inputs:[batch_size, tgt_len, hidden_size]
矩阵变换: - enc_outputs:[batch_size, src_len, hidden_size]
- dec_outputs:[batch_size, tgt_len, hidden_size]
- enc_self_attns:
- dec_self_attns:
- dec_logits [batch_size, src_len, tgt_len]
输出:
dec_logits.view(-1, dec_logits.size(-1)): [batch_size* src_len, tgt_len]
class Transformer(nn.Module):
def __init__(self):
super(Transformer, self).__init__()
self.encoder = Encoder()
self.decoder = Decoder()
self.projection = nn.Linear(d_model, tgt_vocab_size, bias=False)
def forward(self, enc_inputs, dec_inputs):
enc_outputs, enc_self_attns = self.encoder(enc_inputs)
dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs)
dec_logits = self.projection(dec_outputs) # dec_logits : [batch_size x src_vocab_size x tgt_vocab_size]
return dec_logits.view(-1, dec_logits.size(-1)), enc_self_attns, dec_self_attns, dec_enc_attns
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Encoder
主要由src_embedding, postion_embedding和n_layer个EncoderLayer组成。
输入:
- enc_inputs:[batch_size, src_len]
- [[1,2,3,4,0]] 其实也是输入,因为是一个batch,固定写死了, 0是padding值
矩阵变换:
enc_outputs :[batch_size, src_len, hidden_size] (开始时input embedding与position embedding相加)
enc_self_attn_mask :[batch_size, src_len, src_len] (encoder层注意力掩码)
enc_self_attn:[batch_size, n_head, src_len, src_len]
输出:
enc_outputs:[batch_size, src_len, hidden_size]
enc_self_attns:[batch_size, n_head, src_len, src_len]
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.src_emb = nn.Embedding(src_vocab_size, d_model)
self.pos_emb = nn.Embedding.from_pretrained(get_sinusoid_encoding_table(src_len+1, d_model),freeze=True)
self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)])
def forward(self, enc_inputs): # enc_inputs : [batch_size x source_len]
enc_outputs = self.src_emb(enc_inputs) + self.pos_emb(torch.LongTensor([[1,2,3,4,0]]))
enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs)
enc_self_attns = []
for layer in self.layers:
enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask)
enc_self_attns.append(enc_self_attn)
return enc_outputs, enc_self_attns
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
位置编码
位置编码很好理解,偶数位置sin函数,奇数位置cos函数。
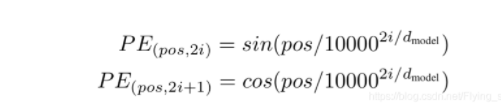
def get_sinusoid_encoding_table(n_position, d_model):
def cal_angle(position, hid_idx):
return position / np.power(10000, 2 * (hid_idx // 2) / d_model)
def get_posi_angle_vec(position):
return [cal_angle(position, hid_j) for hid_j in range(d_model)]
sinusoid_table = np.array([get_posi_angle_vec(pos_i) for pos_i in range(n_position)])
sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i
sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1
return torch.FloatTensor(sinusoid_table)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
attention mask
mask主要是Q与K的注意力掩码,当然在Transformer中Q,K和V是相同的,都是input值。
pad_attn_mask :[batch_size,1, k_len]
pad_attn_mask.expand(batch_size, len_q, len_k): [batch_size , q_len , k_len]
def get_attn_pad_mask(seq_q, seq_k):
batch_size, len_q = seq_q.size()
batch_size, len_k = seq_k.size()
# eq(zero) is PAD token
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # batch_size x 1 x len_k(=len_q), one is masking
return pad_attn_mask.expand(batch_size, len_q, len_k) # batch_size x len_q x len_k
- 1
- 2
- 3
- 4
- 5
- 6
EncoderLayer
主要由多头注意力层(MultiHeadAttention)和前馈层(PoswiseFeedForwardNet)组成。
输入:
- enc_inputs:[batch_size, src_len, hidden_size]
- enc_self_attn_mask: [batch_size, src_len, src_len] (即 [batch_size, q_len, k_len])
矩阵变换: - enc_outputs:[batch_size, src_len, hidden_size]
- attn:[batch_size, n_head, src_len, src_len]
输出:
enc_outputs和attn
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.enc_self_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, enc_inputs, enc_self_attn_mask):
enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, enc_self_attn_mask) # enc_inputs to same Q,K,V
enc_outputs = self.pos_ffn(enc_outputs) # enc_outputs: [batch_size x len_q x d_model]
return enc_outputs, attn
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
MultiHeadAttention
主要由Q K V线性层和LayerNorm组成
输入:
- Q, K , V : [batch_size, src_len, hidden_size]
- attn_mask [batch_size, src_len, src_len]
矩阵变换:
q_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1,2)[batch_size, , src_len, hidden_size] 转为 [batch, n_head, src_len, hidden_size//n_head] ,这里每个头是64。
attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1)将维度变为 [batch, n_head, src_len, hidden_size//n_head] 便于注意力掩码计算。
ScaledDotProductAttention()(q_s, k_s, v_s, attn_mask)注意力计算,下面会介绍。
context.transpose(1, 2).contiguous().view(batch_size, -1, n_heads * d_v)维度变为原来的[batch_size, , src_len, hidden_size]
self.layer_norm(output + residual)残差+layerNorm ->[batch_size, , src_len, hidden_size]
输出:
class MultiHeadAttention(nn.Module): def __init__(self): super(MultiHeadAttention, self).__init__() self.W_Q = nn.Linear(d_model, d_k * n_heads) self.W_K = nn.Linear(d_model, d_k * n_heads) self.W_V = nn.Linear(d_model, d_v * n_heads) self.linear = nn.Linear(n_heads * d_v, d_model) self.layer_norm = nn.LayerNorm(d_model) def forward(self, Q, K, V, attn_mask): # q: [batch_size x len_q x d_model], k: [batch_size x len_k x d_model], v: [batch_size x len_k x d_model] residual, batch_size = Q, Q.size(0) # (B, S, D) -proj-> (B, S, D) -split-> (B, S, H, W) -trans-> (B, H, S, W) q_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) # q_s: [batch_size x n_heads x len_q x d_k] k_s = self.W_K(K).view(batch_size, -1, n_heads, d_k).transpose(1,2) # k_s: [batch_size x n_heads x len_k x d_k] v_s = self.W_V(V).view(batch_size, -1, n_heads, d_v).transpose(1,2) # v_s: [batch_size x n_heads x len_k x d_v] attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1) # attn_mask : [batch_size x n_heads x len_q x len_k] # context: [batch_size x n_heads x len_q x d_v], attn: [batch_size x n_heads x len_q(=len_k) x len_k(=len_q)] context, attn = ScaledDotProductAttention()(q_s, k_s, v_s, attn_mask) context = context.transpose(1, 2).contiguous().view(batch_size, -1, n_heads * d_v) # context: [batch_size x len_q x n_heads * d_v] output = self.linear(context) return self.layer_norm(output + residual), attn # output: [batch_size x len_q x d_model]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
ScaledDotProductAttention

每个head的Q与响应的K相乘得到注意力得分, attn_mask的作用是padding部分填充-1e9,使其在注意力中不起作用, 权重得分变小。然后进行Softmax,得到权重分布,最后乘以V 得到加权后的得分。维度一致保持[batch_size, n_head, src_len, d_k]
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k) # scores:[batch_size x n_heads x len_q(=len_k) x len_k(=len_q)]
scores.masked_fill_(attn_mask, -1e9) # Fills elements of self tensor with value where mask is one.
attn = nn.Softmax(dim=-1)(scores)
context = torch.matmul(attn, V)
return context, attn
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
PoswiseFeedForwardNet
主要由两层CNN、一层激活层和一层LayerNorm组成。
输入:
- inputs:[batch_size, src_len, hidden_size]
矩阵变换: - 第一层CNN:
inputs.transpose(1, 2)改变维度位置,因为torch dim=1的位置是channel,输出为[batch_size, 2048, hidden_size] - 激活函数RELU:
- 第二层CNN:[batch_size, src_len, hidden_size]
self.layer_norm(output + residual)残差+layerNorm ->[batch_size, , src_len, hidden_size]
class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
self.conv1 = nn.Conv1d(in_channels=d_model, out_channels=d_ff, kernel_size=1)
self.conv2 = nn.Conv1d(in_channels=d_ff, out_channels=d_model, kernel_size=1)
self.layer_norm = nn.LayerNorm(d_model)
def forward(self, inputs):
residual = inputs # inputs : [batch_size, len_q, d_model]
output = nn.ReLU()(self.conv1(inputs.transpose(1, 2)))
output = self.conv2(output).transpose(1, 2)
return self.layer_norm(output + residual)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
------------------------------------------ Encoder的部分结束,下面我们讲解Decoder部分 ----------------------------------------------
Decoder(也是encdder输出与decoder输入交互层,重点)

主要由tgt_input embedding、tgt_postion embedding和n_layer个DecoderLayer组成。
输入:
- dec_inputs: [batch_size, tgt_len, hidden_size]
- enc_inputs:[batch_size, src_len, hidden_size]
- enc_outputs:[batch_size, src_len, hidden_size]
矩阵变换
dec_self_attn_pad_maskdecoder开始的padding 掩码部分,与encoder掩码一样,只是输入的是decoder的输入。
dec_self_attn_subsequent_mask解码掩码上三角,因为在翻译的时候,当前词是看不到后面词的信息。get_attn_subsequent_mask函数中np.triu方法返回的是上三角矩阵[batch_size, src_len, src_len],如下图
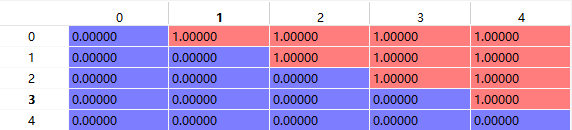
torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequent_mask), 0) -> torch.gt(a,b)函数比较a中元素大于(这里是严格大于)b中对应元素目的是转为bool值。
get_attn_pad_mask(dec_inputs, enc_inputs) 最终的encoder-decoder padding掩码,与单纯的encoder或者decoderpadding掩码不一样, 输入的是decoder input和encoder input, 其中decoder 部分最为Q, decoder部分最为K, 最中掩码维度为[batch_size, q_len, k_len]
输出:
- dec_outputs:[batch_size, tgt_len, hidden_size]
- dec_self_attns:[batch_size, tgt_len, tgt_len]
- dec_enc_attns:[batch_size, tgt_len, src_len]
class Decoder(nn.Module): def __init__(self): super(Decoder, self).__init__() self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model) self.pos_emb = nn.Embedding.from_pretrained(get_sinusoid_encoding_table(tgt_len+1, d_model),freeze=True) self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)]) def forward(self, dec_inputs, enc_inputs, enc_outputs): # dec_inputs : [batch_size x target_len] dec_outputs = self.tgt_emb(dec_inputs) + self.pos_emb(torch.LongTensor([[5,1,2,3,4]])) dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs) dec_self_attn_subsequent_mask = get_attn_subsequent_mask(dec_inputs) dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequent_mask), 0) dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs) dec_self_attns, dec_enc_attns = [], [] for layer in self.layers: dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask) dec_self_attns.append(dec_self_attn) dec_enc_attns.append(dec_enc_attn) return dec_outputs, dec_self_attns, dec_enc_attns def get_attn_subsequent_mask(seq): attn_shape = [seq.size(0), seq.size(1), seq.size(1)] subsequent_mask = np.triu(np.ones(attn_shape), k=1) subsequent_mask = torch.from_numpy(subsequent_mask).byte() return subsequent_mask
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
DecoderLayer
主要由自注意力MultiHeadAttention,交互注意力MultiHeadAttention(输入的是dec_enc_attn_mask掩码),和前馈神经PoswiseFeedForwardNet组成(与encoder一样)
输入:
- dec_inputs: [batch_size, tgt_len, hidden_size]
- enc_outputs:[batch_size, src_len, hidden_size]
- dec_self_attn_mask:[batch_size, tgt_len, tgt_len]
- dec_enc_attn_mask:[batch_size, tgt_len, src_len]
矩阵变化:
对头注意力层和前馈层与encoder的结构一样, 这里不一一介绍。这里需要注意的是交互注意力层输入不一样。
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.dec_self_attn = MultiHeadAttention()
self.dec_enc_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):
dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask)
dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask)
dec_outputs = self.pos_ffn(dec_outputs)
return dec_outputs, dec_self_attn, dec_enc_attn
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
最后是一层线性层,输出logit,维度为[batch_size, src_len, tgt_vocab_size]
完整代码
# -*- coding:UTF-8 -*- # author:user # contact: test@test.com # datetime:2021/12/22 16:32 # software: PyCharm """ 文件说明: """ import numpy as np import torch import torch.nn as nn import torch.optim as optim import matplotlib.pyplot as plt # S: Symbol that shows starting of decoding input # E: Symbol that shows starting of decoding output # P: Symbol that will fill in blank sequence if current batch data size is short than time steps def make_batch(sentences): input_batch = [[src_vocab[n] for n in sentences[0].split()]] output_batch = [[tgt_vocab[n] for n in sentences[1].split()]] target_batch = [[tgt_vocab[n] for n in sentences[2].split()]] return torch.LongTensor(input_batch), torch.LongTensor(output_batch), torch.LongTensor(target_batch) def get_sinusoid_encoding_table(n_position, d_model): def cal_angle(position, hid_idx): return position / np.power(10000, 2 * (hid_idx // 2) / d_model) def get_posi_angle_vec(position): return [cal_angle(position, hid_j) for hid_j in range(d_model)] sinusoid_table = np.array([get_posi_angle_vec(pos_i) for pos_i in range(n_position)]) sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1 return torch.FloatTensor(sinusoid_table) def get_attn_pad_mask(seq_q, seq_k): batch_size, len_q = seq_q.size() batch_size, len_k = seq_k.size() # eq(zero) is PAD token pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # batch_size x 1 x len_k(=len_q), one is masking return pad_attn_mask.expand(batch_size, len_q, len_k) # batch_size x len_q x len_k def get_attn_subsequent_mask(seq): attn_shape = [seq.size(0), seq.size(1), seq.size(1)] subsequent_mask = np.triu(np.ones(attn_shape), k=1) subsequent_mask = torch.from_numpy(subsequent_mask).byte() return subsequent_mask class ScaledDotProductAttention(nn.Module): def __init__(self): super(ScaledDotProductAttention, self).__init__() def forward(self, Q, K, V, attn_mask): scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k) # scores : [batch_size x n_heads x len_q(=len_k) x len_k(=len_q)] scores.masked_fill_(attn_mask, -1e9) # Fills elements of self tensor with value where mask is one. attn = nn.Softmax(dim=-1)(scores) context = torch.matmul(attn, V) return context, attn class MultiHeadAttention(nn.Module): def __init__(self): super(MultiHeadAttention, self).__init__() self.W_Q = nn.Linear(d_model, d_k * n_heads) self.W_K = nn.Linear(d_model, d_k * n_heads) self.W_V = nn.Linear(d_model, d_v * n_heads) self.linear = nn.Linear(n_heads * d_v, d_model) self.layer_norm = nn.LayerNorm(d_model) def forward(self, Q, K, V, attn_mask): # q: [batch_size x len_q x d_model], k: [batch_size x len_k x d_model], v: [batch_size x len_k x d_model] residual, batch_size = Q, Q.size(0) # (B, S, D) -proj-> (B, S, D) -split-> (B, S, H, W) -trans-> (B, H, S, W) q_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) # q_s: [batch_size x n_heads x len_q x d_k] k_s = self.W_K(K).view(batch_size, -1, n_heads, d_k).transpose(1,2) # k_s: [batch_size x n_heads x len_k x d_k] v_s = self.W_V(V).view(batch_size, -1, n_heads, d_v).transpose(1,2) # v_s: [batch_size x n_heads x len_k x d_v] attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1) # attn_mask : [batch_size x n_heads x len_q x len_k] # context: [batch_size x n_heads x len_q x d_v], attn: [batch_size x n_heads x len_q(=len_k) x len_k(=len_q)] context, attn = ScaledDotProductAttention()(q_s, k_s, v_s, attn_mask) context = context.transpose(1, 2).contiguous().view(batch_size, -1, n_heads * d_v) # context: [batch_size x len_q x n_heads * d_v] output = self.linear(context) return self.layer_norm(output + residual), attn # output: [batch_size x len_q x d_model] class PoswiseFeedForwardNet(nn.Module): def __init__(self): super(PoswiseFeedForwardNet, self).__init__() self.conv1 = nn.Conv1d(in_channels=d_model, out_channels=d_ff, kernel_size=1) self.conv2 = nn.Conv1d(in_channels=d_ff, out_channels=d_model, kernel_size=1) self.layer_norm = nn.LayerNorm(d_model) def forward(self, inputs): residual = inputs # inputs : [batch_size, len_q, d_model] output = nn.ReLU()(self.conv1(inputs.transpose(1, 2))) output = self.conv2(output).transpose(1, 2) return self.layer_norm(output + residual) class EncoderLayer(nn.Module): def __init__(self): super(EncoderLayer, self).__init__() self.enc_self_attn = MultiHeadAttention() self.pos_ffn = PoswiseFeedForwardNet() def forward(self, enc_inputs, enc_self_attn_mask): enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, enc_self_attn_mask) # enc_inputs to same Q,K,V enc_outputs = self.pos_ffn(enc_outputs) # enc_outputs: [batch_size x len_q x d_model] return enc_outputs, attn class DecoderLayer(nn.Module): def __init__(self): super(DecoderLayer, self).__init__() self.dec_self_attn = MultiHeadAttention() self.dec_enc_attn = MultiHeadAttention() self.pos_ffn = PoswiseFeedForwardNet() def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask): dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask) dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask) dec_outputs = self.pos_ffn(dec_outputs) return dec_outputs, dec_self_attn, dec_enc_attn class Encoder(nn.Module): def __init__(self): super(Encoder, self).__init__() self.src_emb = nn.Embedding(src_vocab_size, d_model) self.pos_emb = nn.Embedding.from_pretrained(get_sinusoid_encoding_table(src_len+1, d_model),freeze=True) self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)]) def forward(self, enc_inputs): # enc_inputs : [batch_size x source_len] enc_outputs = self.src_emb(enc_inputs) + self.pos_emb(torch.LongTensor([[1,2,3,4,0]])) enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs) enc_self_attns = [] for layer in self.layers: enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask) enc_self_attns.append(enc_self_attn) return enc_outputs, enc_self_attns class Decoder(nn.Module): def __init__(self): super(Decoder, self).__init__() self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model) self.pos_emb = nn.Embedding.from_pretrained(get_sinusoid_encoding_table(tgt_len+1, d_model),freeze=True) self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)]) def forward(self, dec_inputs, enc_inputs, enc_outputs): # dec_inputs : [batch_size x target_len] dec_outputs = self.tgt_emb(dec_inputs) + self.pos_emb(torch.LongTensor([[5,1,2,3,4]])) dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs) dec_self_attn_subsequent_mask = get_attn_subsequent_mask(dec_inputs) dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequent_mask), 0) dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs) dec_self_attns, dec_enc_attns = [], [] for layer in self.layers: dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask) dec_self_attns.append(dec_self_attn) dec_enc_attns.append(dec_enc_attn) return dec_outputs, dec_self_attns, dec_enc_attns class Transformer(nn.Module): def __init__(self): super(Transformer, self).__init__() self.encoder = Encoder() self.decoder = Decoder() self.projection = nn.Linear(d_model, tgt_vocab_size, bias=False) def forward(self, enc_inputs, dec_inputs): enc_outputs, enc_self_attns = self.encoder(enc_inputs) dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs) dec_logits = self.projection(dec_outputs) # dec_logits : [batch_size x src_vocab_size x tgt_vocab_size] return dec_logits.view(-1, dec_logits.size(-1)), enc_self_attns, dec_self_attns, dec_enc_attns def showgraph(attn): attn = attn[-1].squeeze(0)[0] attn = attn.squeeze(0).data.numpy() fig = plt.figure(figsize=(n_heads, n_heads)) # [n_heads, n_heads] ax = fig.add_subplot(1, 1, 1) ax.matshow(attn, cmap='viridis') ax.set_xticklabels(['']+sentences[0].split(), fontdict={'fontsize': 14}, rotation=90) ax.set_yticklabels(['']+sentences[2].split(), fontdict={'fontsize': 14}) plt.show() if __name__ == '__main__': sentences = ['ich mochte ein bier P', 'S i want a beer', 'i want a beer E'] # Transformer Parameters # Padding Should be Zero src_vocab = {'P': 0, 'ich': 1, 'mochte': 2, 'ein': 3, 'bier': 4} src_vocab_size = len(src_vocab) tgt_vocab = {'P': 0, 'i': 1, 'want': 2, 'a': 3, 'beer': 4, 'S': 5, 'E': 6} number_dict = {i: w for i, w in enumerate(tgt_vocab)} tgt_vocab_size = len(tgt_vocab) src_len = 5 # length of source tgt_len = 5 # length of target d_model = 512 # Embedding Size d_ff = 2048 # FeedForward dimension d_k = d_v = 64 # dimension of K(=Q), V n_layers = 6 # number of Encoder of Decoder Layer n_heads = 8 # number of heads in Multi-Head Attention model = Transformer() criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) enc_inputs, dec_inputs, target_batch = make_batch(sentences) for epoch in range(20): optimizer.zero_grad() outputs, enc_self_attns, dec_self_attns, dec_enc_attns = model(enc_inputs, dec_inputs) loss = criterion(outputs, target_batch.contiguous().view(-1)) print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss)) loss.backward() optimizer.step() # Test predict, _, _, _ = model(enc_inputs, dec_inputs) predict = predict.data.max(1, keepdim=True)[1] print(sentences[0], '->', [number_dict[n.item()] for n in predict.squeeze()]) print('first head of last state enc_self_attns') showgraph(enc_self_attns) print('first head of last state dec_self_attns') showgraph(dec_self_attns) print('first head of last state dec_enc_attns') showgraph(dec_enc_attns)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235

