
热门标签
热门文章
- 1网络初识之协议分层_协议层次结构中上层实体收到协议数据单元后,在向下交给下层实体要去掉首部
- 2C++核心知识点汇总(面试)_c++面试基本知识
- 3跳动的心代码实现_pycharm心动
- 4web服务器创建站点,服务器:如何使用IIS建立网站
- 5网站五_6k55com
- 6不为人知的程序员真实世界_程序员的工作世界
- 7车辆行人检测学习笔记_检测出人和车辆
- 8【Qt】QLocalSocket与QLocalServer问题:接收不到数据、只能收到第一条、数据不完整解决方案【2023.05.24】_qt udp组播接收不到
- 9C++Primer第五版 9.3.6节练习_c++ primer 9.3.6
- 10在OK6410上运行QT程序找不到libQtGui.so.4的解决---Ubuntu_error while loading shared libraries: libqtgui.so.
当前位置: article > 正文
BP-LSTM-Attention-transformer,含数据,可直接运行,TensorFlow_lstm+attention+tranzformer组合
作者:2023面试高手 | 2024-02-18 17:30:50
赞
踩
lstm+attention+tranzformer组合
1、摘要
本文主要讲解:BP-LSTM-Attention-transformer,含数据,可直接运行,TensorFlow
主要思路:
- 使用bp神经网络做多分类
- 使用cnn-lstm-attention做时间序列预测
- 使用transformer做时间序列预测
2、数据介绍
bp的数据有八个类别,每个类别里有不同的特征的数据
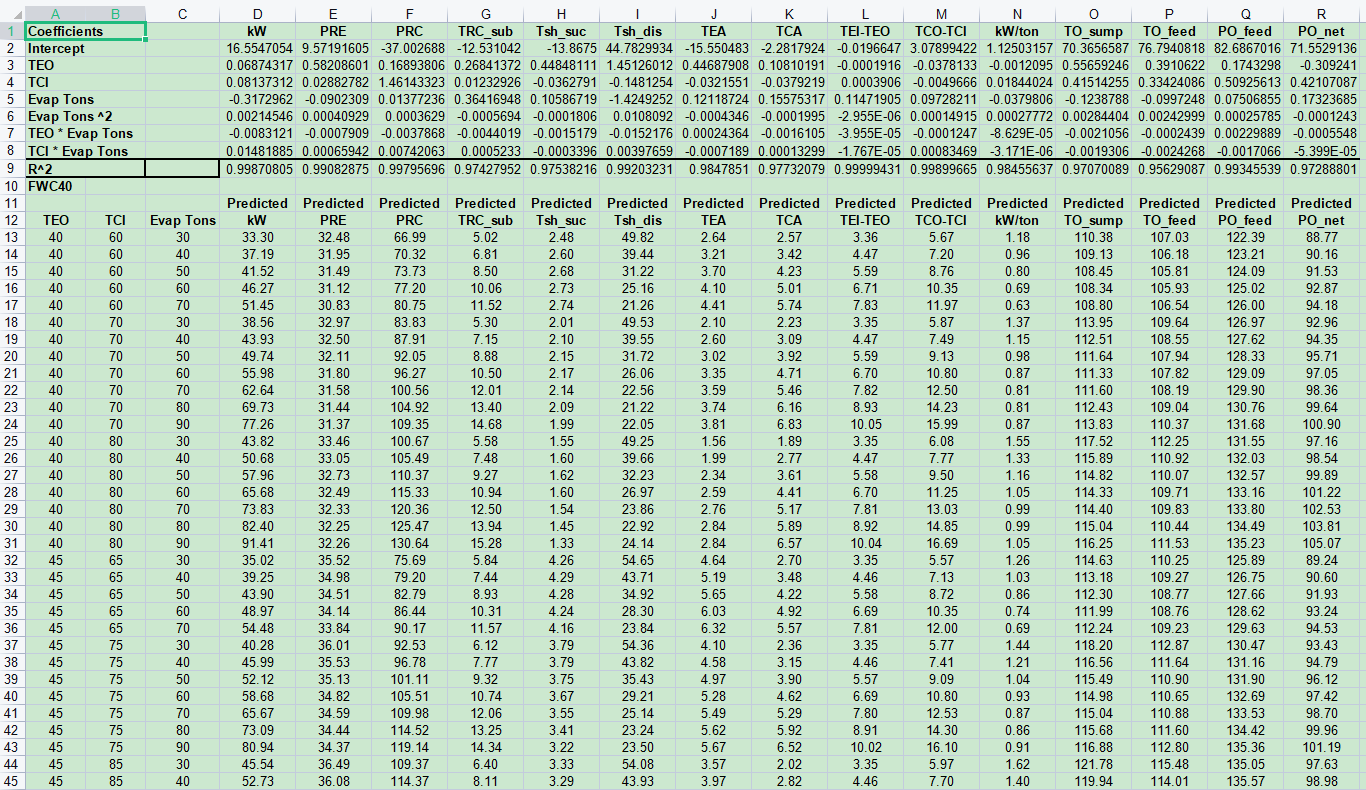
lstm+attention的数据是时间序列数据,蓄电池按时间的寿命数据
transformer数据是温度值跟pue的关系

3、文件介绍

4、完整代码和步骤
此代码的依赖环境如下:
tensorflow==2.5.0
keras==2.6.0
numpy==1.19.5
matplotlib==3.5.2
torch==1.8.0
opencv-python==4.2.0.32
pandas==1.1.5
scikit-learn==0.22.1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
代码输出如下:
主运行程序入口
import math import os import time import csv import numpy as np import pandas as pd import torch import torch.nn as nn import matplotlib.pyplot as plt from sklearn import metrics from sklearn import preprocessing # 导入库 from sklearn.feature_selection import SelectKBest, f_regression from sklearn.metrics import mean_squared_error from sklearn.model_selection import train_test_split from sklearn.preprocessing import MinMaxScaler from torch.autograd import Variable # os.chdir(r'D:\项目\transformer-pue\实验') def writeOneCsv(relate_record, src): with open(src, 'a', newline='\n') as csvFile: writer = csv.writer(csvFile) writer.writerow(relate_record) def min_max_select(X_train, y_train, head_feature_num): scaler = MinMaxScaler(feature_range=(0, 1)) all_data = pd.DataFrame(scaler.fit_transform(X_train), columns=X_train.columns) scaled = pd.DataFrame(preprocessing.scale(all_data), columns=all_data.columns) X_train = scaled.loc[0:len(X_train) - 1] # 特征选择 X_scored = SelectKBest(score_func=f_regression, k='all').fit(X_train, y_train) feature_scoring = pd.DataFrame({ 'feature': X_train.columns, 'score': X_scored.scores_ }) feat_scored = feature_scoring.sort_values('score', ascending=False).head(head_feature_num)['feature'] writeOneCsv([head_feature_num, feat_scored.values.tolist()], '选择后的特征.csv') X_train = X_train[X_train.columns[X_train.columns.isin(feat_scored)]] return X_train.values, y_train.values class PositionalEncoding(nn.Module): def __init__(self, d_model, max_len=5000): super(PositionalEncoding, self).__init__() pe = torch.zeros(max_len, d_model) position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)) pe[:, 0::2] = torch.sin(position * div_term) pe[:, 1::2] = torch.cos(position * div_term) pe = pe.unsqueeze(0).transpose(0, 1) self.register_buffer('pe', pe) def forward(self, x): return x + self.pe[:x.size(0), :] class TransAm(nn.Module): def __init__(self, feature_size=250, num_layers=1, dropout=0.1): super(TransAm, self).__init__() self.model_type = 'Transformer' self.src_mask = None self.pos_encoder = PositionalEncoding(feature_size) self.encoder_layer = nn.TransformerEncoderLayer(d_model=feature_size, nhead=2, dropout=dropout) self.transformer_encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=num_layers) self.decoder = nn.Linear(2 * feature_size, 1) self.init_weights() self.feature_size = feature_size self.num_layers = num_layers self.dropout = dropout def feature(self): return {"feature_size": self.feature_size, "num_layers": self.num_layers, "dropout": self.dropout} def init_weights(self): initrange = 0.1 self.decoder.bias.data.zero_() self.decoder.weight.data.uniform_(-initrange, initrange) def forward(self, src): if self.src_mask is None or self.src_mask.size(0) != len(src): device = src.device mask = self._generate_square_subsequent_mask(len(src)).to(device) self.src_mask = mask src = self.pos_encoder(src) output = self.transformer_encoder(src, self.src_mask) output = output.view(output.shape[0], -1) output = self.decoder(output) return output def _generate_square_subsequent_mask(self, sz): mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1) mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0)) return mask class General_Regression_Training_3d(): def reg_calculate(self, true, prediction): ''' To calculate the result of regression, including mse, rmse, mae, r2, four criterions. ''' prediction[prediction < 0] = 0 mse = mean_squared_error(true, prediction) mae = metrics.mean_absolute_error(true, prediction) return mse, mae def __init__(self, net, learning_rate=[1e-3, 1e-5, 1e-7], batch_size=1024, epoch=2000, use_more_gpu=False, weight_decay=1e-8, device=0, save_path='CNN_Result'): self.net = net self.resultDict = {"learning_rate": learning_rate, "batch_size": batch_size, "epoch": epoch, "weight_decay": weight_decay, "use_more_gpu": use_more_gpu, "device": device, } self.resultDict = dict(self.resultDict, **self.net.feature()) self.batch_size = batch_size self.use_more_gpu = use_more_gpu self.lr = learning_rate self.epoch = epoch self.weight_decay = weight_decay self.device = device self.epoch = epoch self.save_path = save_path # 设置一条保存路径,直接把所有的值都收藏起来 if not os.path.exists(self.save_path): os.makedirs(self.save_path) self.avgLossList = [] # put the avgLoss data self.TrainLosses = [] self.TestLosses = [] self.t = 0 self.D = [] self.n = 0 # 来记录 梯度衰减 的次数 self.limit = [1e-5, 1e-6, 1e-7] def create_batch_size(self, X_train, y_train): p = np.random.permutation(X_train.shape[0]) data = X_train[p] label = y_train[p] batch_size = self.batch_size batch_len = X_train.shape[0] // batch_size + 1 b_datas = [] b_labels = [] for i in range(batch_len): try: batch_data = data[batch_size * i: batch_size * (i + 1)] batch_label = label[batch_size * i: batch_size * (i + 1)] except: batch_data = data[batch_size * i: -1] batch_label = label[batch_size * i: -1] b_datas.append(batch_data) b_labels.append(batch_label) return b_datas, b_labels def fit(self, X_train, y_train, X_test, y_test): ''' training the network ''' # input the dataset and transform into dataLoad # if y is a scalar if y_train.ndim == 1: y_train = y_train.reshape(-1, 1) if y_test.ndim == 1: y_test = y_test.reshape(-1, 1) self.X_train, self.X_test, self.y_train, self.y_test = X_train, X_test, y_train, y_test b_data, b_labels = self.create_batch_size(X_train, y_train) save_result = os.path.join(self.save_path, 'Results.csv') try: count = len(open(save_result, 'rU').readlines()) except: count = 1 net_weight = os.path.join(self.save_path, 'Weight') if not os.path.exists(net_weight): os.makedirs(net_weight) net_path = os.path.join(net_weight, str(count) + '.pkl') net_para_path = os.path.join(net_weight, str(count) + '_parameters.pkl') # set the net use cpu or gpu device = torch.device(self.device if torch.cuda.is_available() else "cpu") if torch.cuda.is_available(): print("Let's use GPU: {}".format(self.device)) else: print("Let's use CPU") if self.use_more_gpu and torch.cuda.device_count() > 1: print("Let's use", torch.cuda.device_count(), "GPUs") self.net = nn.DataParallel(self.net) self.net.to(device) # network change to train model self.net.train() # set optimizer and loss function try: optim = torch.optim.Adam(self.net.parameters(), lr=self.lr[0], weight_decay=self.weight_decay) except: optim = torch.optim.Adam(self.net.parameters(), lr=self.lr, weight_decay=self.weight_decay) criterion = torch.nn.MSELoss() # Officially start training start = time.time() # 计算时间 limit = self.limit[0] for e in range(self.epoch): tempLoss = [] self.net.train() for i in range(len(b_data)): if torch.cuda.is_available(): train_x = Variable(torch.FloatTensor(b_data[i])).to(device) train_y = Variable(torch.FloatTensor(b_labels[i])).to(device) else: train_x = Variable(torch.FloatTensor(b_data[i])) train_y = Variable(torch.FloatTensor(b_labels[i])) prediction = self.net(train_x) loss = criterion(prediction, train_y) tempLoss.append(float(loss)) optim.zero_grad() loss.backward() optim.step() self.D.append(loss.cpu().data.numpy()) avgloss = np.array(tempLoss).sum() / len(tempLoss) self.avgLossList.append(avgloss) if ((e + 1) % 100 == 0): print('Training... epoch: {}, loss: {}'.format((e + 1), self.avgLossList[-1])) self.net.eval() if torch.cuda.is_available(): test_x = Variable(torch.FloatTensor(self.X_test)).to(device) test_y = Variable(torch.FloatTensor(self.y_test)).to(device) else: test_x = Variable(torch.FloatTensor(self.X_test)) test_y = Variable(torch.FloatTensor(self.y_test)) test_prediction = self.net(test_x) test_loss = criterion(test_prediction, test_y) self.TrainLosses.append(avgloss) self.TestLosses.append(test_loss.cpu().data.numpy()) self.test_prediction = test_prediction.cpu().data.numpy() self.test_prediction[self.test_prediction < 0] = 0 # epoch 终止装置 if len(self.D) >= 20: loss1 = np.mean(np.array(self.D[-20:-10])) loss2 = np.mean(np.array(self.D[-10:])) d = np.float(np.abs(loss2 - loss1)) # 計算loss的差值 if d < limit or e == self.epoch - 1 or e > (self.epoch - 1) / 3 * ( self.n + 1): # 加入遍历完都没达成limit限定,就直接得到结果 self.D = [] # 重置 self.n += 1 print('The error changes within {}'.format(limit)) self.e = e + 1 print( 'Training... epoch: {}, loss: {}'.format((e + 1), loss.cpu().data.numpy())) torch.save(self.net, net_path) torch.save(self.net.state_dict(), net_para_path) self.net.eval() if torch.cuda.is_available(): test_x = Variable(torch.FloatTensor(self.X_test)).to(device) test_y = Variable(torch.FloatTensor(self.y_test)).to(device) else: test_x = Variable(torch.FloatTensor(self.X_test)) test_y = Variable(torch.FloatTensor(self.y_test)) test_prediction = self.net(test_x) test_loss = criterion(test_prediction, test_y) self.test_prediction = test_prediction.cpu().data.numpy() self.test_prediction[self.test_prediction < 0] = 0 plt.figure(figsize=(10, 10)) plt.plot(test_prediction.tolist(), color="red") plt.plot(test_y.tolist(), color="green") plt.title('real vs pred test') plt.ylabel('pue') plt.xlabel('x') plt.legend(['pred', 'real'], loc='lower right') plt.savefig("real_pred_" + str(feature_selection_ratio) + '.png', dpi=500, bbox_inches='tight') plt.show() self.mse, self.mae = self.reg_calculate(self.y_test, self.test_prediction) print('\033[1;35m Testing epoch: {}, loss: {} , mae: {} \033[0m!'.format((e + 1), test_loss.cpu().data.numpy(), self.mae)) # 已经梯度衰减了 2 次 if self.n == 2: print('The meaning of the loop is not big, stop!!') break limit = self.limit[self.n] print('Now learning rate is : {}'.format(self.lr[self.n])) optim.param_groups[0]["lr"] = self.lr[self.n] mse_list.append(test_loss.cpu().data.numpy()) end = time.time() self.t = end - start print('Training completed!!! Time consuming: {}'.format(str(self.t))) mse_list = [] ratio_list = [] for i in range(1, 11): pue = pd.read_csv('pue.csv', encoding='gbk') pue.dropna(axis=0, how='all') pue.fillna(0, inplace=True) train = pue.drop(['下一时刻PUE', '时间戳'], axis=1) target = pue['下一时刻PUE'] print('feature_selection_ratio') feature_selection_ratio = i / 10 print(feature_selection_ratio) ratio_list.append(feature_selection_ratio) head_feature_num = int(feature_selection_ratio * train.shape[1]) train, target = min_max_select(train, target, head_feature_num) # 切割数据样本集合测试集 X_train, x_test, y_train, y_true = train_test_split(train, target, test_size=0.2) # 20%测试集;80%训练集 X_train_Double = [] for line in X_train: tempList = [] for l in line: tempList.extend([l, l]) X_train_Double.append([np.array(tempList), np.array(tempList)]) X_train_Double = np.array(X_train_Double) X_test_Double = [] for line in x_test: tempList = [] for l in line: tempList.extend([l, l]) X_test_Double.append([np.array(tempList), np.array(tempList)]) X_test_Double = np.array(X_test_Double) print("X_train_Double.shape:", X_train_Double.shape, "X_test_Double.shape:", X_test_Double.shape) feature_size = X_train_Double.shape[2] model = TransAm(feature_size=feature_size, num_layers=1, dropout=0.2) grt = General_Regression_Training_3d(model, learning_rate=[1e-3, 1e-6, 1e-8], batch_size=512, use_more_gpu=False, weight_decay=1e-3, device=0, save_path='transformer_Result', epoch=5000) grt.fit(X_train_Double, y_train, X_test_Double, y_true) plt.figure(1) plt.plot(ratio_list, mse_list, 'r-.p', label="mse") plt.xlabel("feature_selection_ratio") plt.ylabel("mse") plt.savefig('feature_selection_ratio_mse.png') plt.show()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- 362
- 363
- 364
- 365
- 366
- 367
- 368
- 369
- 370
- 371
所有完整代码和数据请移步:
BP-LSTM-Attention-transformer,含数据,可直接运行,TensorFlow
本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

