
热门标签
热门文章
- 1如何用机器学习算法计算特征重要性_基尼指数能计算svm bpnn输入特征的重要度
- 2systemctl系统服务管理_systemctl is-active
- 3微信小程序如何搭建自己的后台(超详细,超完整)(上线必备)!!!_怎么设置自己的微信小程序后台
- 4Python电脑硬件信息获取_python获取电脑硬件信息
- 5从3天到3小时,“文思助手”让行业专业写作“文思泉涌”
- 6css如何画一个梯形
- 7基于ssh(非maven)电影购票管理系统_LW模板
- 8信息科技如何做好风险管理_信息科技风险管理
- 9中国下一代AI开源框架:国际、创新、实用和长期主义_各个开源框架名称
- 10python3scapy库函数使用,发送数据包_scapy 构造ipsec 数据
当前位置: article > 正文
【NLP】MHA、MQA、GQA机制的区别
作者:盐析白兔 | 2024-02-17 23:16:18
赞
踩
【NLP】MHA、MQA、GQA机制的区别
Note
- LLama2的注意力机制使用了GQA。三种机制的图如下:
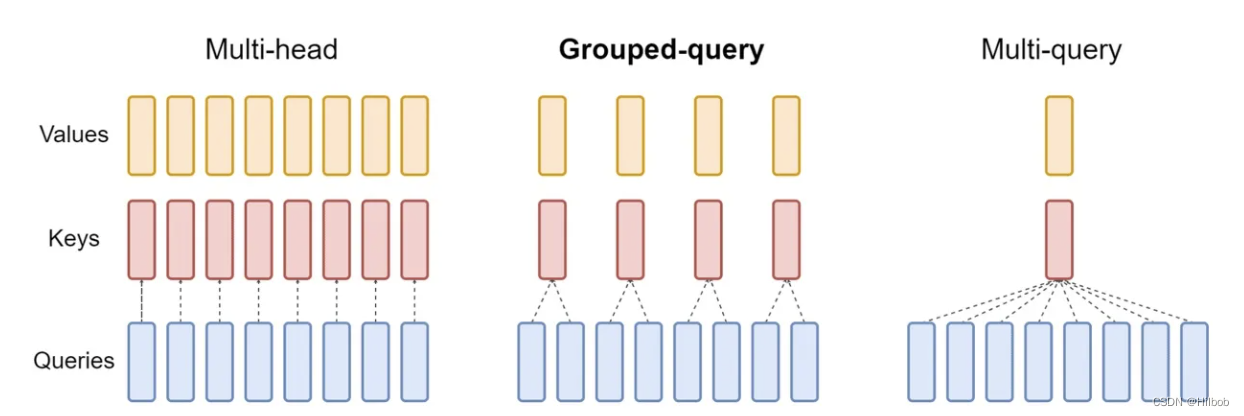
MHA机制(Multi-head Attention)
MHA(Multi-head Attention)是标准的多头注意力机制,包含h个Query、Key 和 Value 矩阵。所有注意力头的 Key 和 Value 矩阵权重不共享
MQA机制(Multi-Query Attention)
MQA(Multi-Query Attention,Fast Transformer Decoding: One Write-Head is All You Need)是多查询注意力的一种变体,也是用于自回归解码的一种注意力机制。与MHA不同的,MQA 让所有的头之间共享同一份 Key 和 Value 矩阵,每个头只单独保留了一份 Query 参数,从而大大减少 Key 和 Value 矩阵的参数量。
GQA机制(Grouped-Query Attention)
GQA(Grouped-Query Attention,GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints)是分组查询注意力,GQA将查询头分成G组,每个组共享一个Key 和 Value 矩阵。GQA-G是指具有G组的grouped-query attention。GQA-1具有单个组,因此具有单个Key 和 Value,等效于MQA。若GQA-H具有与头数相等的组,则其等效于MHA。GQA介于MHA和MQA之间。GQA机制,多头共用 KV Cache。
Reference
[1] 一文通透各种注意力:从多头注意力MHA到分组查询注意力GQA、多查询注意力MQA
[2] Transformer系列:注意力机制的优化,MQA和GQA原理简述
[3] Navigating the Attention Landscape: MHA, MQA, and GQA Decoded
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/102261?site
推荐阅读
相关标签

