
- 1业界AI 推理芯片比较_主流推理芯片比较
- 2unity 制作行李箱密码_unity密码箱
- 3LLM - Chinese-Llama-2-7b 初体验
- 4ElementUI中引入图标_引入elemnt ui 图标
- 5Python统计词频的几种方法_python词频统计
- 6小白Vue3+Nginx实现部署_vue3 nginx
- 7opencv自带face-detection范例代码,编程实现人脸检测_opencv\face_detection_yunet.onnx
- 8混合专家模型 (MoE) 详解
- 9C# Winform UI Ant Design 5.0 设计语言
- 10python win32gui.FindWindow()找不到窗口(亲测有效)
集成学习之bagging、boosting及AdaBoost的实现_训练一个bagging集成与直接使用
赞
踩
本文所有代码都是基于python3.6的,数据及源码下载:传送门
引言
前面博客分享,我们已经讲解了不少分类算法,有knn、决策树、朴素贝叶斯、逻辑回归、svm。我们知道,当做重要决定时,大家可能都会考虑吸取多个专家而不是一个人的意见。机器学习处理问题时同样如此。集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务,有时被称为多分类器学习系统、基于委员会的学习等。
个体与集成
下图显示出集成学习的一般结构:先产生一组“个体学习器”,再用某种策略将它们结合起来。
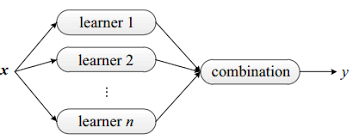
我们前面已经分享了五种不同的分类算法,我们可以将其用不同的分类器组合起来,这种组合结果则被称为集成方法或者元算法。使用集成方法时会有多种形式:1.集成中只包含同种类型的个体学习器,这种个体学习器也被称为基学习器。2.集成中也可包含不同类型的个体学习器,这种异质集成的个体学习器是由不同的学习算法生成。
一般来说,集成学习通过将多个学习器进行结合,常可获得比单一学习器显著优越的泛化性能。但是从实际经验中发现,要获得好的集成,个体学习器应“好而不同”,即个体学习器要有一定的“准确性”,即学习器不能太坏,并且要有“多样性”,即学习器之间具有差异。
根据个体学习器的生成方式,目前的集成学习方法有两大代表:一个是bagging,一个是boosting。
bagging
自举汇聚法,也称bagging方法,是一种基于数据随机重抽样的分类器构建方法。bagging原理如下:
给定包含m个样本的数据集,我们先随机取出一个样本放入采样集中,再把该样本放回初始数据集,使得下次采样时刻该样本仍有肯能被选中,这样经过m次随机采样操作,我们得到含m个样本的采样集,初始训练集中有的样本在采样集中多次出险,有的则从未出现。照这样,我们可采样出T个含m个训练样本的采样集。
bagging的特点
- 训练一个bagging集成与直接使用基学习算法训练一个学习器的复杂度同阶
- 与标准的adboost只适用于二分类任务不同的是,bagging能不经修改地用于多分类、回归等任务
- 由于自助采样过程的性质,包外样本可以用作包外估计,可用来辅助剪枝,减小过拟合风险
- 从偏差-方差角度看,bagging主要关注降低方差,因此它在不剪枝决策树、神经网络等易受样本扰动的学习器上效用更明显。
随机森林
随机森林是更先进的bagging方法。RF是在以决策树为基学习器构建bagging集成的基础上,进一步在决策树的训练过程中引入了随机属性选择。此处详情请戳:RF
boosting
boosting是一种与bagging很类似的技术。不论是boosting还是bagging,所使用的分类器的类型都是一致的。但是bagging是个体学习器间不存在强依赖关系、可同时生成的并行化方法;boosting是个体学习器间存在强依赖关系、必须串行生成的序列化方法。
boosting不同的分类器是通过串行训练而获得的,每个新分类器都根据已训练出的分类器性能来进行训练。boosting是通过集中关注被已有分类器错分的那些数据来获得新的分类器。
由于boosting分类的结果是基于所有分类器的加权求和结果的,因此boosting与bagging不太一样。bagging中的分类器权重是相等的,而boosting中的分类器权重并不相等,每个权重代表其对应分类器在上一轮迭代中的成功度。
boosting族算法最具代表性的是AdaBoost。关于AdaBoost我前面有篇博客有分享:利用AdaBoost元算法提高分类性能。这里我将结合那篇博客的内容深入分析AdaBoost的原理与实现。
最小化指数损失函数
AdaBoost算法有很多的推导方式,比较容易理解的是基于“加性模型”,即基学习器的线性组合:
H
(
x
)
=
∑
t
=
1
T
α
t
h
t
(
x
)
H(x) = \sum_{t=1}^{T}\alpha_th_t(x)
H(x)=t=1∑Tαtht(x)
来最小化指数损失函数,中间推导不作详细介绍。
AdaBoost是adaptive boosting的缩写,其运行过程如下:
训练数据中的每个样本,并赋予其一个权重,这些权重构成了向量D。一开始这些权重全部被初始化成相等的值。首先在训练数据上训练出一个弱分类器并计算该分类器的错误率,然后在同一数据集上再次训练弱分类器。在分类器的第二次训练中,将会重新调整每个样本的权重,其中第一次分对的样本权重将会降低,而第二次分错的样本权重将会提高。为了从所有弱分类器中得到最终的分类结果,AdaBoost为每个分类器都分配了一个权重值alpha,这些alpha值是基于每个弱分类器的错误率进行计算的。
我们定义弱分类器的错误率为:
ε
=
未
正
确
分
类
的
样
本
数
所
有
样
本
数
\varepsilon = \frac{未正确分类的样本数}{所有样本数}
ε=所有样本数未正确分类的样本数
通过最小化损失函数,求得AdaBoost给每个分类器分配的权重值alpha,公式如下:
α
=
1
2
l
n
(
1
−
ε
t
ε
t
)
\alpha = \frac{1}{2}ln(\frac{1-\varepsilon_t}{\varepsilon_t})
α=21ln(εt1−εt)
AdaBoost算法的流程如下图所示:
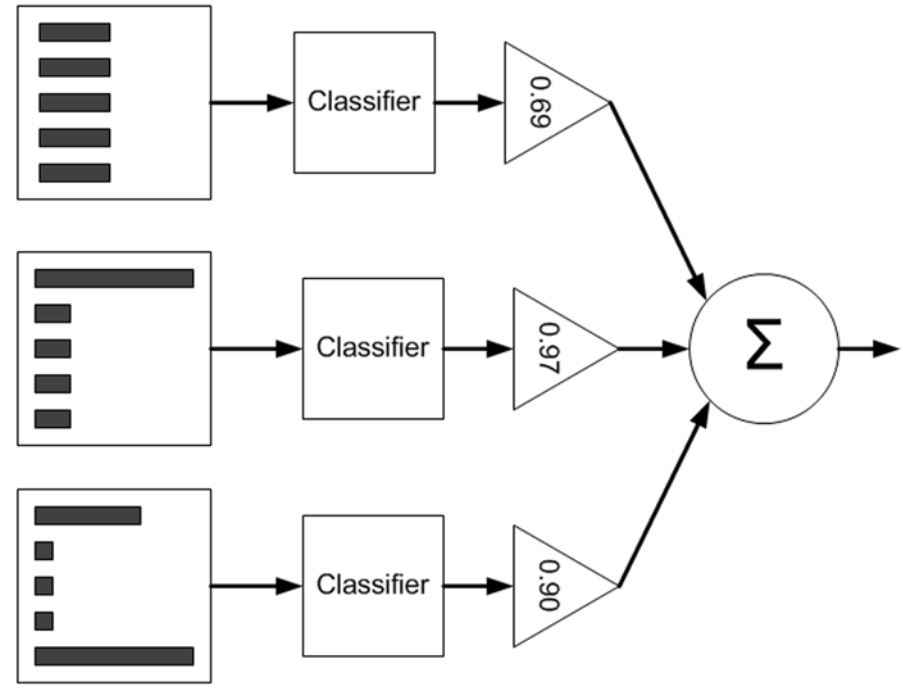
如上图所示:左边是数据集,其中直方图的不同宽度表示每个样例上的不同权重。经过一个分类器之后,加权的预测结果会通过三角形中的alpha值进行加权。每个三角形中输出的加权结果在圆形中求和,从而得到最终的输出结果。
计算出alpha值后可以对权重向量D进行更新,以使得那些正确分类的样本的权重降低,而错分样本的权重升高。D的计算方法如下。
如果某个样本被正确分类,那么该样本的权重更改为:
D
i
(
t
+
1
)
=
D
i
(
t
)
e
−
α
S
u
m
(
D
)
D_i^{(t+1)} = \frac{D_i^{(t)}e^{-\alpha}}{Sum(D)}
Di(t+1)=Sum(D)Di(t)e−α
如果某个样本被错分,那么该样本的权重更改为:
D
i
(
t
+
1
)
=
D
i
(
t
)
e
α
S
u
m
(
D
)
D_i^{(t+1)} = \frac{D_i^{(t)}e^{\alpha}}{Sum(D)}
Di(t+1)=Sum(D)Di(t)eα
在计算出D之后,AdaBoost又开始进入下一轮迭代。AdaBoost会不断地重复训练和调整权重的过程,直到训练错误率为0或者弱分类器的数目达到用户的指定值为止。
##AdaBoost的实现
###基于单层决策树构建弱分类器
单层决策树是一种简单的决策树。前面我们已经介绍了决策树的工作原理,接下来构建一个单层决策树,而它仅仅基于单个决策特征来做决策。由于这棵树只有一次分裂过程,因此它实际上就是一个树桩。因此也被称为决策树桩。
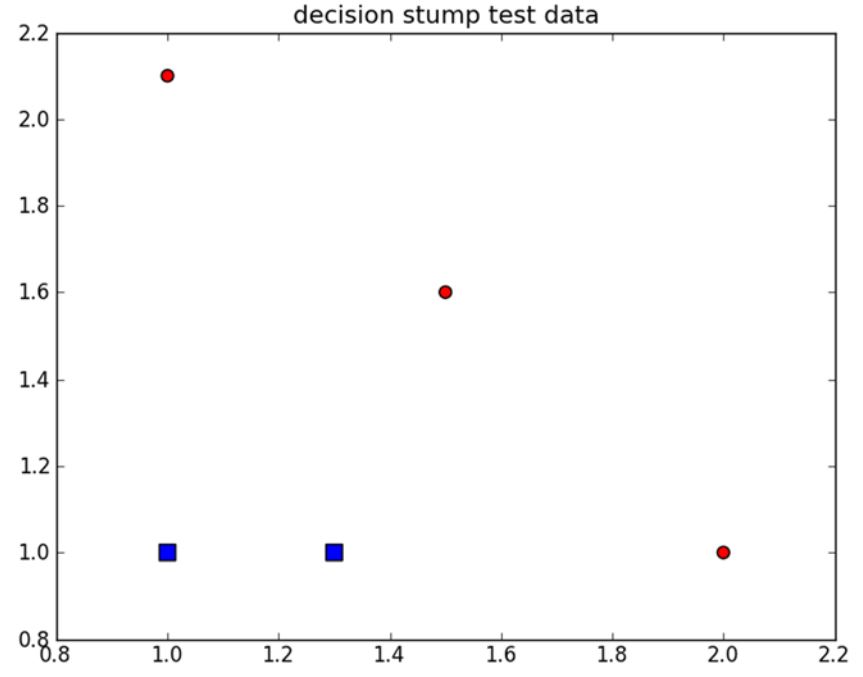
如上图所示,我们希望从某个坐标轴上选择一个值来将上图中的所有圆形点和方形点分开,这显然是不可能的。这就是单层决策树难以处理的一个著名的问题。通过使用多棵单层决策树,我们就能构建出对该数据集完全正确分类的分类器。
单层决策树的伪代码如下所示:

上述伪代码的核心思想就是寻找具有最低错误率的单层决策树。
代码如下:
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):#just classify the data
retArray = ones((shape(dataMatrix)[0],1))
if threshIneq == 'lt':
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0
return retArray
def buildStump(dataArr,classLabels,D):
dataMatrix = mat(dataArr); labelMat = mat(classLabels).T
m,n = shape(dataMatrix)
numSteps = 10.0; bestStump = {}; bestClasEst = mat(zeros((m,1)))
minError = inf #init error sum, to +infinity
for i in range(n):#loop over all dimensions
rangeMin = dataMatrix[:,i].min(); rangeMax = dataMatrix[:,i].max();
stepSize = (rangeMax-rangeMin)/numSteps
for j in range(-1,int(numSteps)+1):#loop over all range in current dimension
for inequal in ['lt', 'gt']: #go over less than and greater than
threshVal = (rangeMin + float(j) * stepSize)
predictedVals = stumpClassify(dataMatrix,i,threshVal,inequal)#call stump classify with i, j, lessThan
errArr = mat(ones((m,1)))
errArr[predictedVals == labelMat] = 0
weightedError = D.T*errArr #calc total error multiplied by D
#print "split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshVal, inequal, weightedError)
if weightedError < minError:
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump,minError,bestClasEst
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
上述代码权重错误weightedError是AdaBoost和分类器交互的地方。构建决策树桩的算法核心就是在一个加权的数据集中循环,然后找到具有最低错误率的单层决策树。
到目前为止我们已经构建了一个决策树桩,接下来我们就通过使用多个弱分类器来构建AdaBoost代码。
基于决策树桩的AdaBoost的构建
AdaBoost训练
AdaBoost训练的伪代码构造如下:

代码如下:
def adaBoostTrainDS(dataArr,classLabels,numIt=40):
weakClassArr = []
m = shape(dataArr)[0]
D = mat(ones((m,1))/m) #init D to all equal
aggClassEst = mat(zeros((m,1)))
for i in range(numIt):
bestStump,error,classEst = buildStump(dataArr,classLabels,D)#build Stump
#print "D:",D.T
alpha = float(0.5*log((1.0-error)/max(error,1e-16)))#calc alpha, throw in max(error,eps) to account for error=0
bestStump['alpha'] = alpha
weakClassArr.append(bestStump) #store Stump Params in Array
#print "classEst: ",classEst.T
expon = multiply(-1*alpha*mat(classLabels).T,classEst) #exponent for D calc, getting messy
D = multiply(D,exp(expon)) #Calc New D for next iteration
D = D/D.sum()
#calc training error of all classifiers, if this is 0 quit for loop early (use break)
aggClassEst += alpha*classEst
#print "aggClassEst: ",aggClassEst.T
aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T,ones((m,1)))
errorRate = aggErrors.sum()/m
print "total error: ",errorRate
if errorRate == 0.0: break
return weakClassArr,aggClassEst
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
AdaBoost测试
这里我们只是简单地应用了单层决策树。输出的估计类别值乘上该单层决策树的alpha权重,然后进行累加,就完成了分类过程。代码如下:
def adaClassify(datToClass,classifierArr):
dataMatrix = mat(datToClass)#do stuff similar to last aggClassEst in adaBoostTrainDS
m = shape(dataMatrix)[0]
aggClassEst = mat(zeros((m,1)))
for i in range(len(classifierArr)):
classEst = stumpClassify(dataMatrix,classifierArr[i]['dim'],\
classifierArr[i]['thresh'],\
classifierArr[i]['ineq'])#call stump classify
aggClassEst += classifierArr[i]['alpha']*classEst
print aggClassEst
return sign(aggClassEst)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Adaboost应用
我们应用上图方形与圆形数据点数据,来进行分类。
首先我们看一下训练数据:

然后看一下训练结果:
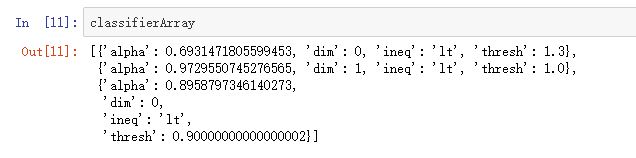
这里训练了三个弱分类器。
最后看一下测试结果,这里我们选择了两个训练数据(0,0);(5,5):
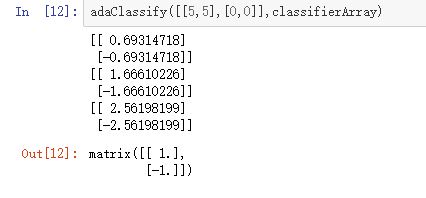
总结
本次分享介绍了两种集成方法:bagging,boosting。在bagging中,是通过随机抽样的替换方式得到与原始数据集规模一样的数据集。boosting比bagging思想更进一步,在数据集上顺序应用了多个不同的分类器。本文后半部分重点讲述了AdaBoost的简化版实现方法,AdaBoost函数可以应用于任意分类器,只要该分类器能够处理加权数据即可。

