- 1基于Python校园购物商城系统(Django框架)开题答辩常规问题和如何回答
- 2ssh、Xmanager远程linux运行图形界面程序_设置xmanager和ssh能调用图形
- 3MATLAB算法实战应用案例精讲-【图像处理】三维重建(补充篇)_单目三维重建matlab
- 4如何使用C++max函数
- 5Examination:《计算机系统与网络技术》计算机三级考试重点笔记记录_网络技术三级考试笔记
- 6【prompt-me】一个专为GPT Prompt Engineer设计LLM Prompt Layer框架_gpt-engineer
- 7亿某通电子文档安全管理系统任意文件上传漏洞 CNVD-2023-59471
- 8Visual C++ 网络编程经典案例详解 第2章 Winsock网络程序开发流程 基于TCP的Sockets编程 TCP客户端_vc ctcpclient
- 9Reformer 模型 - 突破语言建模的极限
- 10《快速掌握PyQt5》第十三章 学会使用文档——Qt Assistant_qt 的assistant 在哪里
【计算机视觉 | 注意力机制】13种即插即用涨点模块分享!含注意力机制、卷积变体、Transformer变体等_即插即用的注意力机制
赞
踩
用即插即用的模块“缝合”,加入自己的想法快速搭积木炼丹。
这种方法可以简化模型设计,减少冗余工作,帮助我们快速搭建模型结构,不需要从零开始实现所有组件。除此以外,这些即插即用的模块都具有标准接口,意味着我们可以很方便地替换不同的模块进行比较,加快论文实验迭代的速度。
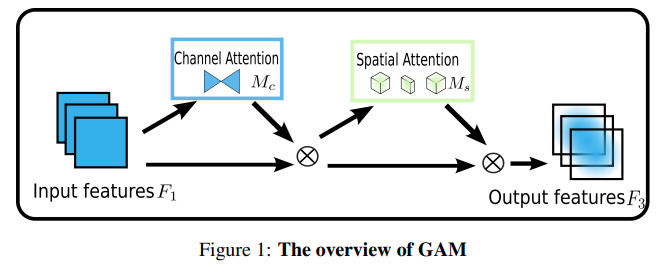
1. GAM 注意力模块
论文:Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions
全局注意力机制:保留信息以增强通道-空间交互
「简介:」各种注意力机制被研究用以提高不同计算机视觉任务的性能。然而,之前的方法忽略了保留通道和空间两个方面的信息以增强跨维度交互的重要性。因此,论文提出一种全局注意力机制,通过通道和空间双注意力减少信息损失,增强全局特征交互,从而提升视觉任务的性能。
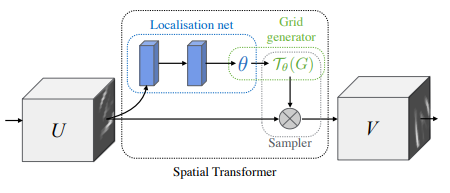
2. STN模块
论文:Spatial Transformer Networks
空间转换器网络
「简介:」卷积神经网络定义了一个非常强大的模型类,但仍受限于以计算和参数高效的方式对输入数据空间不变性的缺乏能力。在这项工作中,作者引入了一个新的可学习模块,即空间转换器,它明确地允许网络内的数据进行空间操作。该可微分模块可以插入现有的卷积架构中,赋予神经网络主动根据特征图自身对特征图进行空间变换的能力,而无需任何额外的训练监督或优化过程的修改。
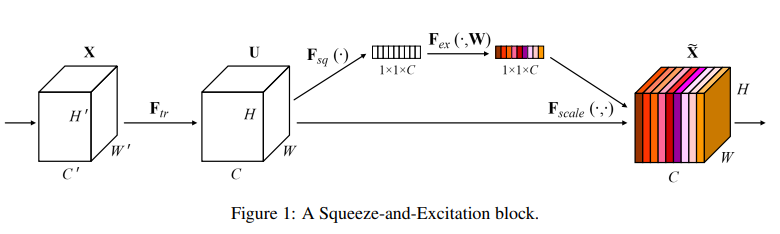
3. SENet 通道注意力模块
论文:Squeeze-and-Excitation Networks
挤压和激励网络
「简介:」卷积神经网络建立在卷积操作之上,通过在局部感受野内融合空间和通道信息来提取有效特征。为了增强网络的表示能力,几种最近的方法展示了增强空间编码的好处。在本文中,作者关注通道关系,并提出了一种新的架构单元“Squeeze-and-Excitation”(SE)模块,它通过明确建模通道之间的依赖关系,自适应地重新校准通道级特征响应。
4. DConv动态卷积
论文:OMNI-DIMENSIONAL DYNAMIC CONVOLUTION
全维动态卷积
「简介:」全维动态卷积(ODConv)是一种新颖的卷积模块,可以作为常规卷积的直接替代,插入到许多CNN架构中。它利用多维注意力机制,沿卷积核的所有四个维度(空间大小、输入通道数、输出通道数和核数量)学习核的互补注意力,以获得更强的特征表达能力。ODConv可以显著提升各种CNN网络的性能,包括轻量级和大型模型,同时参数量不增。即使只用单核,它也可以匹敌或超过现有的多核动态卷积模块。
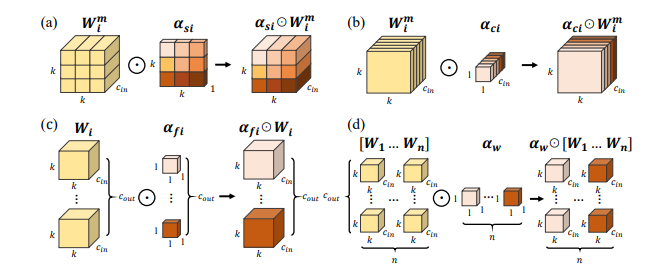
5. 完全注意力FANs
论文:Understanding The Robustness in Vision Transformers
理解视觉鹅transformer的鲁棒性
「简介:」最新的研究显示,视觉Transformer(ViTs)在处理各种图像损坏时表现出很强的鲁棒性。尽管这种鲁棒性部分归因于自注意力机制,但我们对其中的工作原理还不是很清楚。论文通过引入全注意力网络(FANs)中的注意力通道模块,加强了自注意力在学习鲁棒特征表示方面的作用。
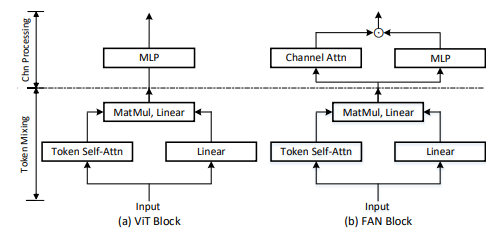
6. CA注意力
论文:Coordinate Attention for Efficient Mobile Network Design
移动网络设计的协同注意力机制
「简介:」移动网络中的通道注意力机制通常会忽略空间位置信息,这对生成位置敏感的注意力图很重要。本文提出了一种坐标注意力机制,将位置编码嵌入到通道注意力中,以获得对位置敏感的注意力。它将通道注意力分解成两个方向的1D特征编码,每个方向聚合一维的特征,这样就可以在一个方向上捕获长程依赖,同时在另一个方向保留精确的位置信息。
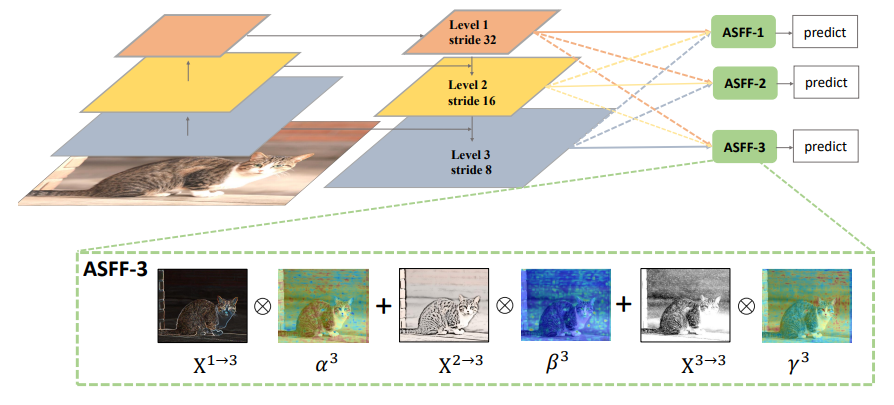
7. 自适应空间特征融合(ASFF)
论文:Learning Spatial Fusion for Single-Shot Object Detection
空间融合模块用于单镜头物体检测的学习
「简介:」为了处理物体检测中尺度变化的挑战,金字塔特征表示是常见的做法。但是,基于特征金字塔的单阶段检测器,不同尺度特征之间的不一致性是其主要局限。本文提出了一种新颖的数据驱动的金字塔特征融合策略,即自适应空间特征融合。它可以学习空间过滤冲突信息的方式来抑制不一致性,从而提高特征的尺度不变性,并增加很小的推理开销。
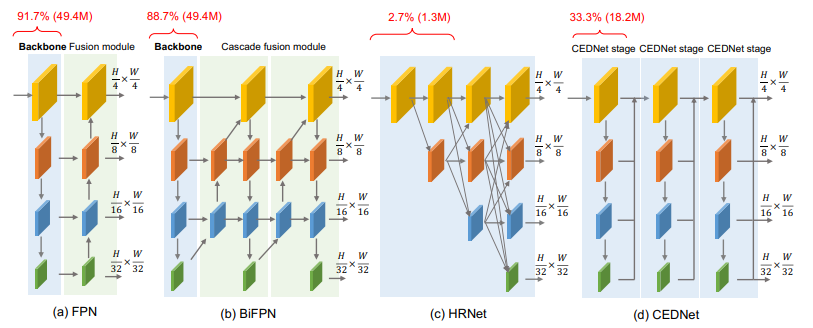
8. 全新多尺度融合(CFNet 2023年)
论文:DNET: A CASCADE ENCODER-DECODER NET-WORK FOR DENSE PREDICTION
DNET:用于稠密预测的级联编码器-解码器网络
「简介:」多尺度特征对稠密预测任务非常重要。现有方法通常在分类骨干网络提取多尺度特征后,采用轻量级模块融合,但因计算资源集中在分类骨干网络,多尺度特征融合往往推迟,导致特征融合不充分。论文提出了一种流线型的级联编码器-解码器网络CEDNet,所有阶段共享编码器-解码器结构,在解码器内进行多尺度特征融合。
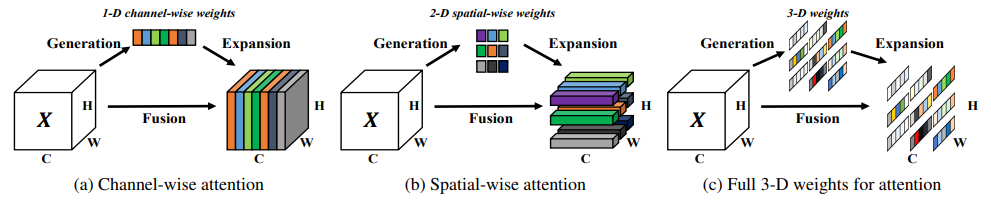
9. 无参数注意力机制(simAM)
论文:SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks
SimAM:一种用于卷积神经网络的简单无参数注意力模块
「简介:」论文提出一个简单高效的卷积神经网络注意力模块SimAM。不同于现有逐通道或空间注意力,SimAM不增加网络参数就可以为层内特征图推断三维注意力。具体来说,作者定义一个能量函数并导出闭式解来发现每个神经元的重要性,用少于10行代码实现。SimAM运算符选择基于能量函数解得出,避免结构调优。
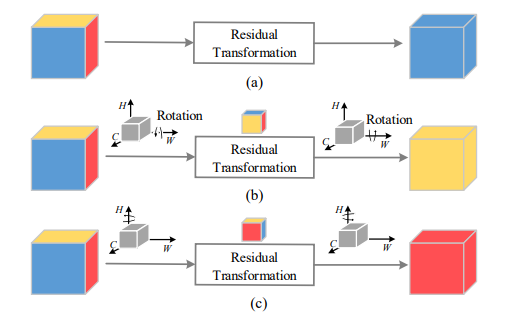
10. 卷积三重注意力模块
论文:Rotate to Attend: Convolutional Triplet Attention Module
卷积三元组注意力模块
「简介:」本文研究了一种轻量级但有效的注意力机制——三元组注意力,它通过三分支结构和旋转操作来捕获输入张量不同维度之间的交互,从而计算注意力权重。该方法可以轻松集成到典型的CNN模型中,对计算和参数量影响很小。
11. Selective Query Recollection(SQR)
论文:Enhanced Training of Query-Based Object Detection via Selective Query Recollection
选择性查询回忆增强了基于查询的目标检测的训练
「简介:」这篇论文研究了基于查询的目标检测器在最后解码阶段预测错误而在中间阶段预测正确的现象。通过回顾训练过程,作者归因该现象于两个限制:后期阶段缺乏训练强调以及解码顺序导致的级联错误。为此,作者设计了选择性查询回忆(SQR)策略来增强基于查询的目标检测器的训练。该策略累积收集中间查询,并选择性地将其直接输入后期阶段,从而强调后期阶段的训练,并让后期阶段可以直接使用中间查询。

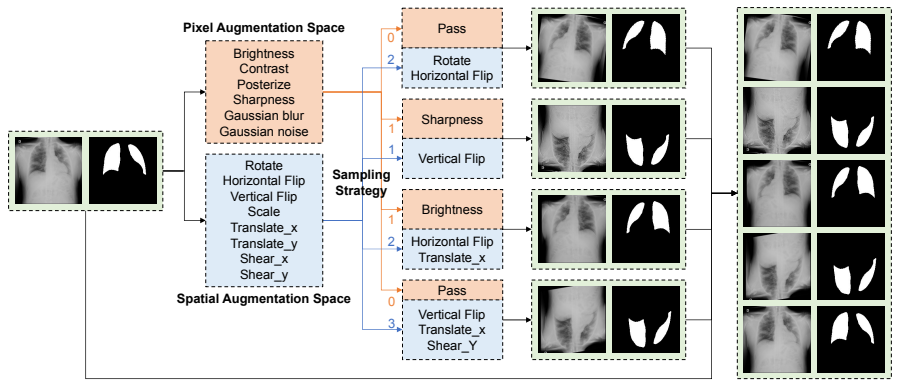
12. CV自动数据增强插件(MedAugment)
论文:MedAugment: Universal Automatic Data Augmentation Plug-in for Medical Image Analysis
医学图像分析的通用自动数据增强插件
「简介:」本文提出了一个名为MedAugment的可即插即用的数据增强方法,以利用自动的数据增强来推动医学图像分析领域的发展。考虑到自然图像和医学图像的差异,作者将增强空间分为像素增强空间和空间增强空间,并设计了一种新的操作采样策略来从这两个空间中采样增强操作。
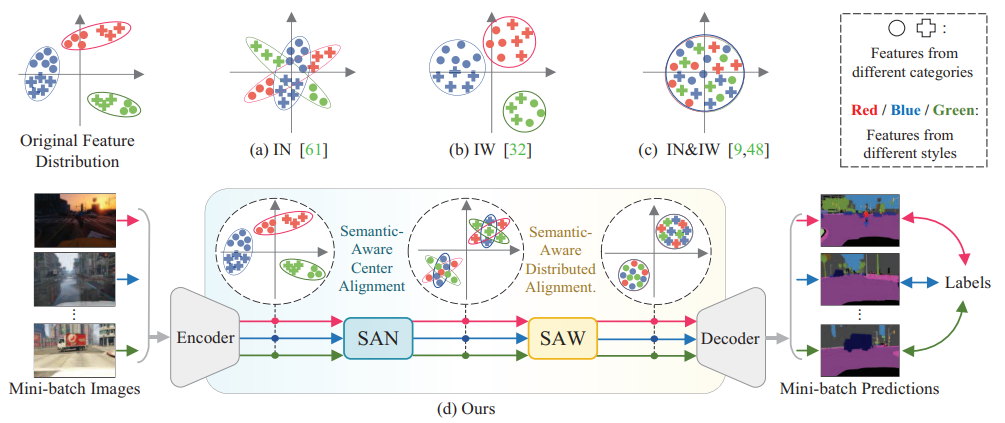
13. 域泛化语义分割模型
论文:Semantic-Aware Domain Generalized Segmentation
语义感知的域泛化分割
「简介:」本文提出了一个框架来解决语义分割的域泛化问题,其中分割模型在源域训练后需要在未见的数据分布不同的目标域上进行泛化。该框架包含两个新模块:语义感知正则化(SAN)和语义感知拉伸(SAW)。SAN通过类别级的特征中心对齐来促进不同域之间的域不变性。SAW在已经对齐的特征上施加分布对齐来增强类别间的区分度。