
- 1ObservableCollection 实现添加后排序_.net observablecollection绑定后排序
- 2C++ 如何设计好用的API_c++ api设计
- 3关于使用imageloader遇到的问题记录_imagesloaded插件报错h is not iterable
- 4curl php 宝塔 开启_用宝塔windows面板建站时nginx+php并发阻塞(用curl请求本地文件无限超时)问题解决方法,提高性能...
- 5python小游戏----外星人入侵_python外星人入侵代码
- 6【Error2013:2013 lost connection to MYSQL server在处理大量数据运行中报错解决方法】_2013 lost connection to server
- 7最全计算机图形学面试资料整理_计算机图形学面试题
- 8SpringBoot3响应式编程----StreamAPI
- 9【目标检测算法】详解 YOLO(You only look once)_yolo 过滤 小
- 10如何计算首屏加载时间?
第3部分 原理篇2去中心化数字身份标识符(DID)(4)
赞
踩
3.2.3. DID解析
3.2.3.1. DID解析参与方
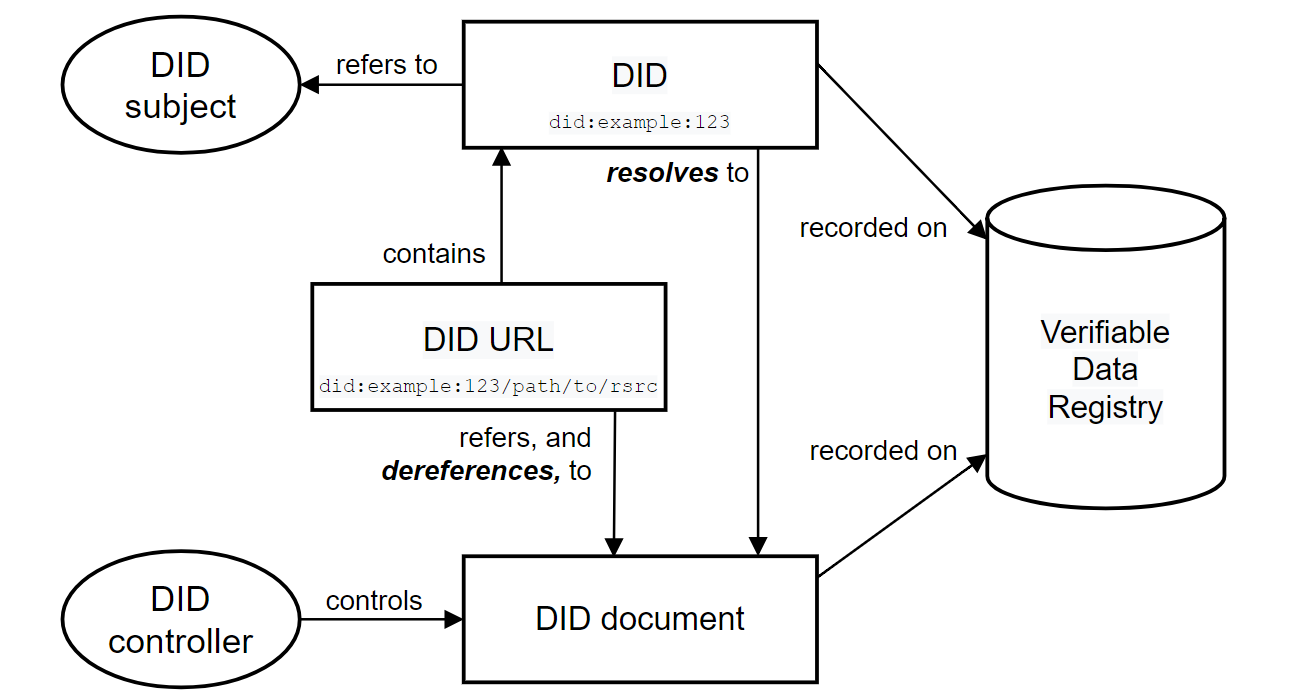
图3-5 DID 解析过程
本聪老师:我们之前提到过,DID 解析过程是将 DID 转换为对应的 DID 文档。这样做的目的是验证 DID 所代表的主体的身份。那么解析过程会涉及哪些概念呢?我们看图3-,DID标识符代表DID主体行使其数字身份的职责,DID标识符有时候被包含在DID URL中,它们可以被解析(DID URL成为解引用)为DID文档。DID标识符和DID文档都被记录在可验证数据注册表中,供查询检索。DID文档的更新等操作受DID控制器管理控制。
3.2.3.2. DID解析过程
小天:解析发生在哪些场景呢?
本聪老师:我们设想这样的场景,小天带着自己的数字毕业证去某公司面试,毕业证上有小天的DID标识符、学校的DID标识符和学校的数字签名。那么公司的人力部门首先要做的是确认学校和小天的身份,如何确认呢?从DID标识符解析为DID文档,文档中会包括各自的公钥和授权等信息,后续可以使用公钥对毕业证上面的数字签名进行验证。
小天:明白了。DID 解析过程有哪些呢?
本聪老师:这里还要提到的是DID URL的解析,术语称为解引用(dereference),与DID标识符的解析过程基本相同,我们在说明过程中会提到不同之处。从原理看,DID解析经历了4个阶段:首先是从DID标识符解析出 DID 方法,这个不难吧?
小明:是截取DID标识符的前两部分就可以,就像”did:example” 是一个 DID 方法。
本聪老师:对。对于DID URL第一步是分离DID标识符和URL路径,获得DID方法。解析的第二阶段是获取 DID 文档,获取的过程其实就是从可验证数据注册表这样的可信基础设施检索的过程。具体来讲就是DID 解析函数通过使用适用的 DID 方法的“读取”操作将 DID 解析为 DID 文档,这里有两个函数resolve 函数和resolveRepresentation 函数。resolve 函数以map形式返回 DID 文档。 resolveRepresentation 函数返回的是符合表示法格式的 DID 文档的字节流。对于DID URL解引用,同样存在dereference函数,以DID URL等参数为输入,除了返回DID文档之外,还会返回URL资源,这些资源同样用于后续的验证过程。
本聪老师:第三阶段是验证 DID 文档,在获取 DID 文档之后,需要对 DID 文档进行验证,以确保其是有效的、未被篡改的并且是与 DID 相关联的实体的正确信息。这可以通过使用 DID 文档中的验证方法来完成。
本聪老师:最后第四阶段就是访问 DID 文档中的信息,一旦验证了 DID 文档,就可以使用其中的信息来验证 DID 所代表的实体的身份或其他目的。
小天:嗯,大致能理解了。说下我的理解,看对不对?DID 解析过程是将 DID 转换为与之相关联的 DID 文档,并验证该文档的有效性和正确性,以便访问其中包含的相关信息。
本聪老师:总的来说是这样的。
3.2.4. DID Auth协议
本聪老师:我们在介绍DID文档结构的时候,了解文档中存在“认证”属性。DIF通过DID Auth协议丰富了DID文档中“authentication”属性的能力,我们本节详细在讨论下这个协议。
小明:是,感觉“authentication”属性理解不是很透彻。
3.2.4.1. 构建“authentication”属性
本聪老师:好的,我们补充下这部分内容。DID Auth协议能做什么呢?简单说,就是身份所有者在各种组件(如网络浏览器、移动设备和其他代理)的帮助下向有验证需求的各方(成为依赖方)证明他们控制着一个DID。
小明:对,这是DID最基本的使用场景。实际场景中是不是存在多种认证模式呢?
本聪老师:对,存在单向认证和双向认证的需求。我们假设小天持有DIDa,小明持有DIDb,单向认证就是小天向小明证明对DIDa的控制,双向认证就是,小天向小明证明对DIDa的控制,小明向小天证明对DIDb的控制。
小云:那么可认证的DID标识符与DID标识符一样吗?
本聪老师:一样的,其实真实生成环境中,每个新生成的DID标识符应该都附带有“authentication”属性。下面我们梳理一下创建DID 的流程。
本聪老师:第一步,用户(DID subject)使用符合DID方法规范的客户端创建一个DID标识符,例如:did:ytm:653ca82******45d85a47。第二步,用户生成对应的DID文档,将文档中的“id”属性设置为刚生成的did:ytm:653ca82******45d85a47。为文档添加“authentication”属性,增加“type”参数值(根据DID方法规定选择),补充其他参数,比如”publicKey”等等认证材料。DID方法平台补充其他属性及参数。下面例子中的代码,包含“authentication”属性,其中有两个type和publicKey,属于同一个owner,但具有不同的编码方式。
- 包含“authentication”属性的例子
{
“@context”: “https://w3id.org/did/v1”,
“id”: “did:example:123456789abcdefghi”,
“authentication”: [{
“type”: “RsaSignatureAuthentication2018”,
“publicKey”: “did:example:123456789abcdefghi#keys-1”
}, {
“type”: “Ed25519SignatureAuthentication2018”,
“publicKey”: “did:example:123456789abcdefghi#keys-2”
}],
“publicKey”: [{
“id”: “did:example:123456789abcdefghi#keys-1”,
“type”: “RsaVerificationKey2018”,
“owner”: “did:example:123456789abcdefghi”,
“publicKeyPem”: “—–BEGIN PUBLIC KEY…END PUBLIC KEY—–\r\n”
}, {
“id”: “did:example:123456789abcdefghi#keys-2”,
“type”: “Ed25519VerificationKey2018”,
“owner”: “did:example:123456789abcdefghi”,
“publicKeyBase58”: “H3C2AVvLMv6gmMNam3uVAjZpfkcJCwDwnZn6z3wXmqPV”
}]
}
小明:嗯,接下来呢?
本聪老师:好。第三步就是把DID标识符和DID文档存储到可验证数据注册表,这里的可验证数据注册表可以是区块链分布式账本,也可以是其他中心化存储系统。DID文档的创建过程就完成了。
3.2.4.2. 认证的过程
小明:使用的过程是怎样的?
本聪老师:使用的过程就是认证的过程。DID Auth协议认为这个过程是挑战-响应的循环。通过这个循环,依赖方对身份所有者的DID进行认证。
小云:挑战应该依赖方发起的吧?
本聪老师:对。身份所有者面临挑战的情形很多,比如点击网站上的 “用DID Auth登录 “按钮、扫描二维码或者是后台调用API。依赖方发起挑战时,一般不知道谁来响应,所以挑战中不会包含DID,但会包含随机数,用来区别后续的挑战,并且防止重放攻击。
小天:那么响应呢?
本聪老师:身份所有者会根据挑战构建一个响应,响应中通常会包括一个加密数字签名,证明自己对DID标识符的控制。接下来,响应发给依赖方。依赖方在收到响应后,会解析身份所有者的DID标识符为DID文档,使用其中的公钥验证响应中包含的数字签名。大家看下下面的图3-6就应该明白了。我说一下基本环境,看大家能否说清楚流程。身份所有者是个人用户,他使用web浏览器登陆一个网站,移动app中安装有DID方法的客户端(其中包含认证材料)。依赖方是网站,需要验证用户的登陆行为。
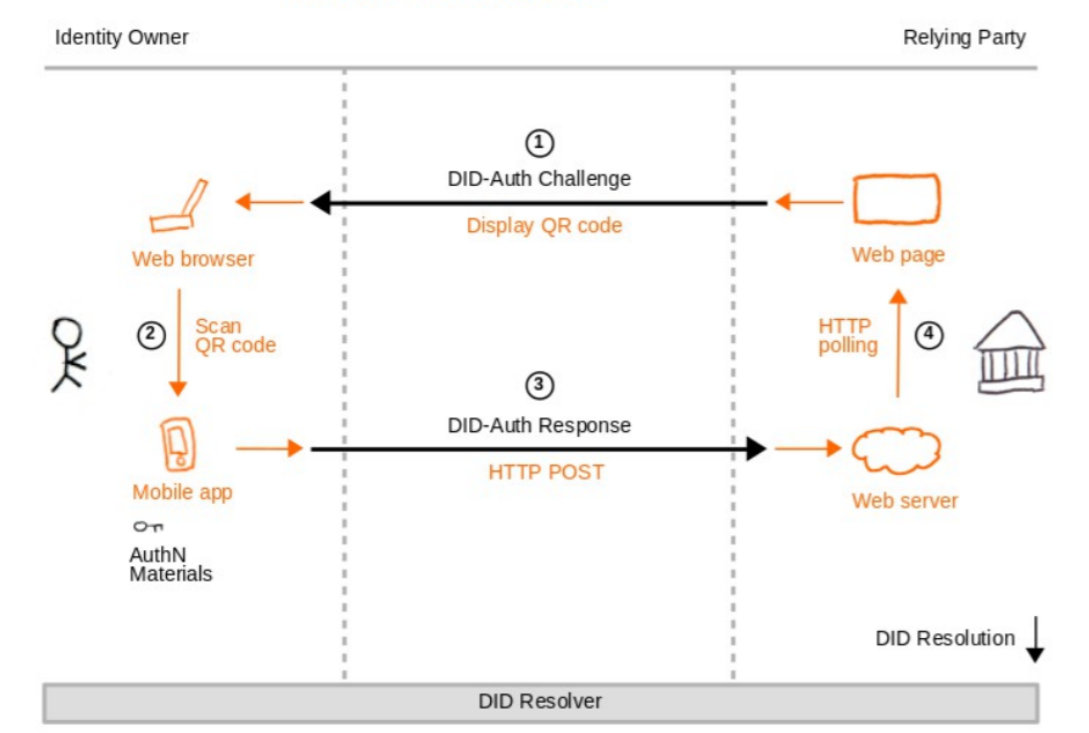
图3-6 挑战过程
小明:我说说。用户打开login页面,其中内嵌一个登陆二维码(这里包含挑战的内容给你),他用手机app扫描二维码,将自己的DID标识符和数字签名构建成响应发给WEB服务器,web服务器将DID标识符提交给DID解析器,得到DID文档,获得其中的公钥,验证数字签名。网站页面会周期性轮WEB服务器,验证无误,表示认证过程通过,用户浏览器可以登陆进入网站。
本聪老师:基本是这样。图3-只是一种情形,还有上面提到的用户登陆移动app接受认证,甚至用户本身就是一家机构,认证方式和流程略有不同,但原理基本是这样。
本文内容摘自《对话去中心化数字身份》。作者:乔布施。首发平台:https://ytm.app
欢迎转载,请注明出处及作者。

