
- 1网络安全:存储型XSS
- 2linux 字符界面_linux字符界面
- 3import pandas as pd 报错_chapter5-1 数据处理常见bug报错整理1
- 4关于php、php-fpm的解释
- 5逆向分析系列——常见的脱壳工具_逆向脱壳工具
- 6解决Visio和office365安装兼容问题_visio 365
- 7斯坦福大学的 CS231n(全称:面向视觉识别的卷积神经网络)
- 8postman测试时传递对象中是list参数_postman如何测试对象里套对象list
- 9Vue3组件间通信知识整理——父组件向子组件传参_vue3父组件向子组件传递事件
- 10利用Ubuntu22.04启动U盘对电脑磁盘进行格式化
Spring cloud alibaba--Nacos注册中心_spring.cloud.nacos.username
赞
踩
目录
1.什么是Nacos
官方:一个更易于构建云原生应用的动态服务发现、服务配置、服务管理平台
Nacos的关键特性包括:
(1)服务发现和服务健康监测
(2)动态配置服务
(3)动态DNS服务
(4)服务及其元数据管理
2.注册中心演变及其设计思想
管理所有微服务,解决微服务之间调用关系错综复杂,难以维护的问题。
(1)硬编码方法:把服务写入到代码里面
存在问题:ip和port变更,服务迁移、集群部署时,都需要重新修改url

(2)维护一张注册表方式:url有变动,在表中进行编辑链接
存在问题:订单服务进行水平扩容后,没法负载均衡调用;某个服务宕机了,没法响应服务
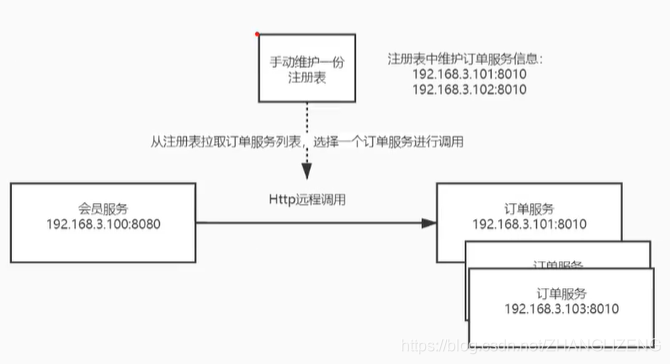
(3)引入nginx进行负载均衡:nginx通过配置订单服务url,负载均衡请求
存在问题:成千上万的服务,nginx配置文件会特别复杂,每有一个服务地址变动需要在nginx中进行配置,难以维护

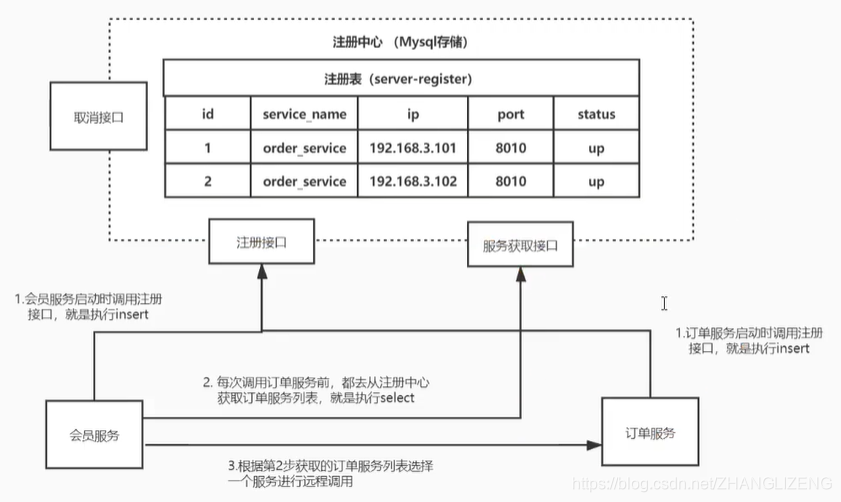
(4)服务启动后向注册中心写入接口服务:nacos服务器,当服务启动时,向注册中心注册表中添加接口服务信息;调用服务时,再从注册中心中获取服务地址。
存在问题:每次都需要去注册中心中拉取url信息,太浪费资源;若是拉取到的服务宕机了,没法响应请求;注册中心宕机了,整个服务都没法响应。
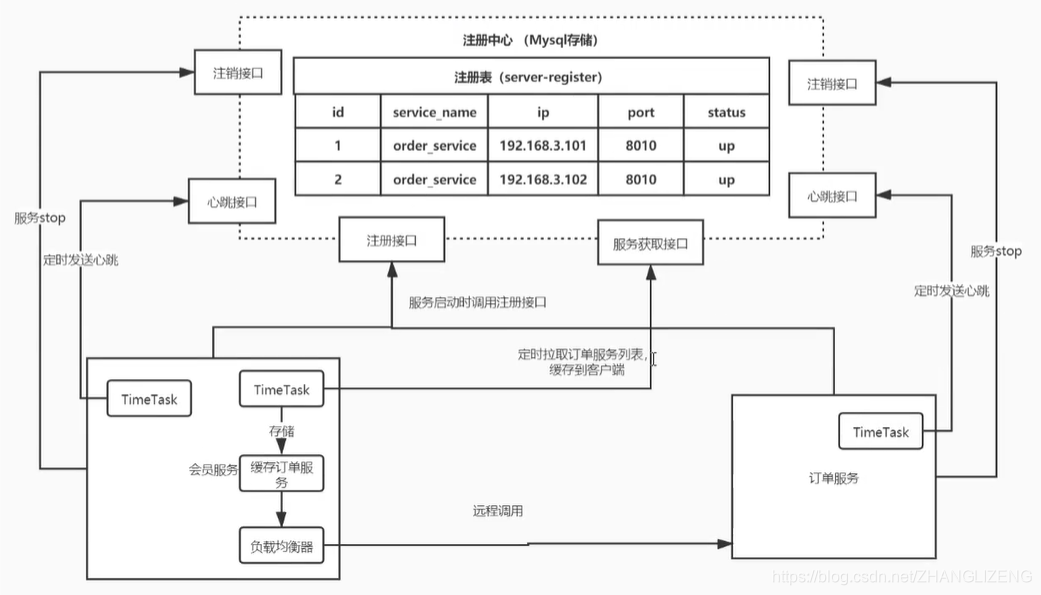
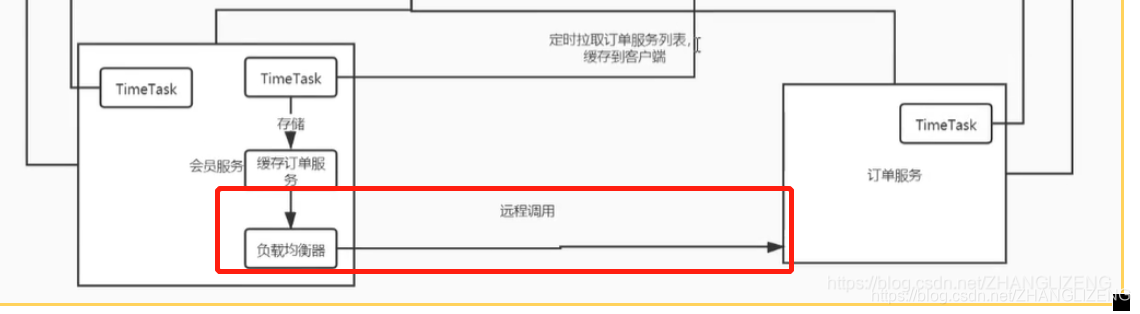
(5)nacos注册中心添加心跳、缓存、负载均衡:服务启动时,向nacos注册中心写入接口服务;订单服务TimeTask定时访问心跳接口,若是过了心跳接口没接收到订单服务的访问,则状态status由up改为down;若是过了一定的时间点,心跳接口还是没有收到心跳调用,则从注册表中移出这个注册信息;当服务停止stop时,向注销接口中发送请求,从注册表中移出服务地址;定时器获取服务调用接口,缓存获取到的服务接口,当调用时从缓存中获取接口服务;当远程调用时使用负载均衡器从缓存中获取到接口服务url
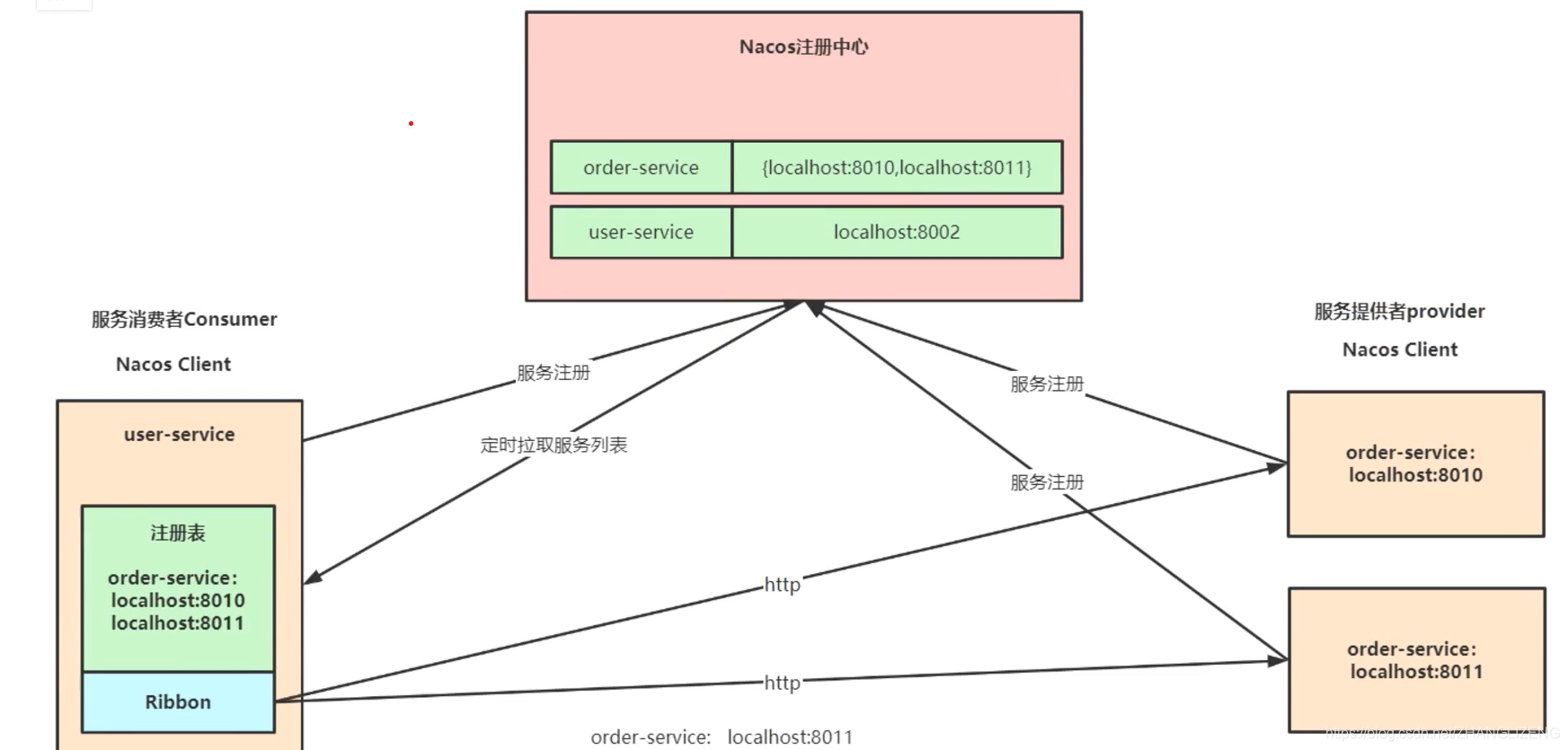
3.Nacos注册中心服务架构
4.Nacos核心功能
(1)服务注册:Nacos Client会通过发送REST请求的方式向Nacos Server注册自己的服务,提供自身的元数据,例如ip地址、端口等信息。Nacos Servcer接收到注册请求后,就会把这些元数据信息存储在一个双层的内存Map中。
(2)服务心跳:在服务注册后,Nacos Client会维护一个定时心跳来持续通知Nacos Server,说明服务一直处于可用状态,防止被剔除。默认5s发送一次心跳
(3)服务同步:Nacos Server集群之间会互相同步服务实例,用来保证服务信息的一致性。leader raft
(4)服务发现:服务消费者(Nacos Client)在调用服务提供者的服务时,会发送一个REST请求给Nacos Server,获取上面的注册服务清单,并且缓存在Nacos Client本地,同时会在Nacos Client本地开启一个定时任务定时拉取服务端最新的注册表信息更新到本地缓存
(5)服务健康检查:Nacos Server会开启一个定时任务来检查注册服务实例的健康情况,对应超过15s没有收到客户端心跳的实例会将他的healthy属性设置为false(此时客户端服务再来获取服务列表时获取不到它)。如果某个实例超过30秒没有收到心跳,直接剔除该实例(被剔除的实例如果恢复发送心跳则会重新注册)。
5.Nacos Server 部署
(1)下载安装包
地址:Releases · alibaba/nacos · GitHub,找到我们需要的nacos版本1.4.2,下载window系统的安装包
(2)解压下载的nacos压缩文件,bin目录存放启动文件,conf存放配置信息文件
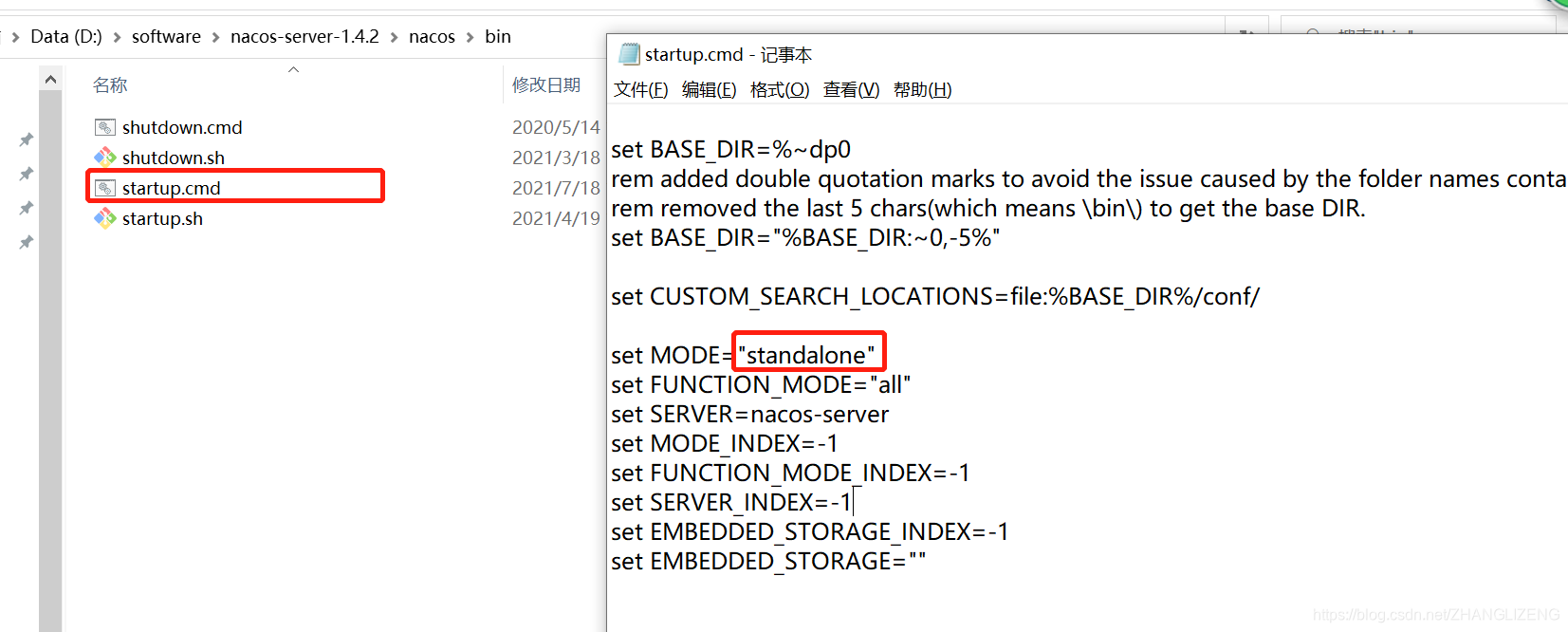
(3)在目录bin/startup.cmd编辑nacos为单机模式,启动项默认是集群的方式
默认的启动方式为集群:
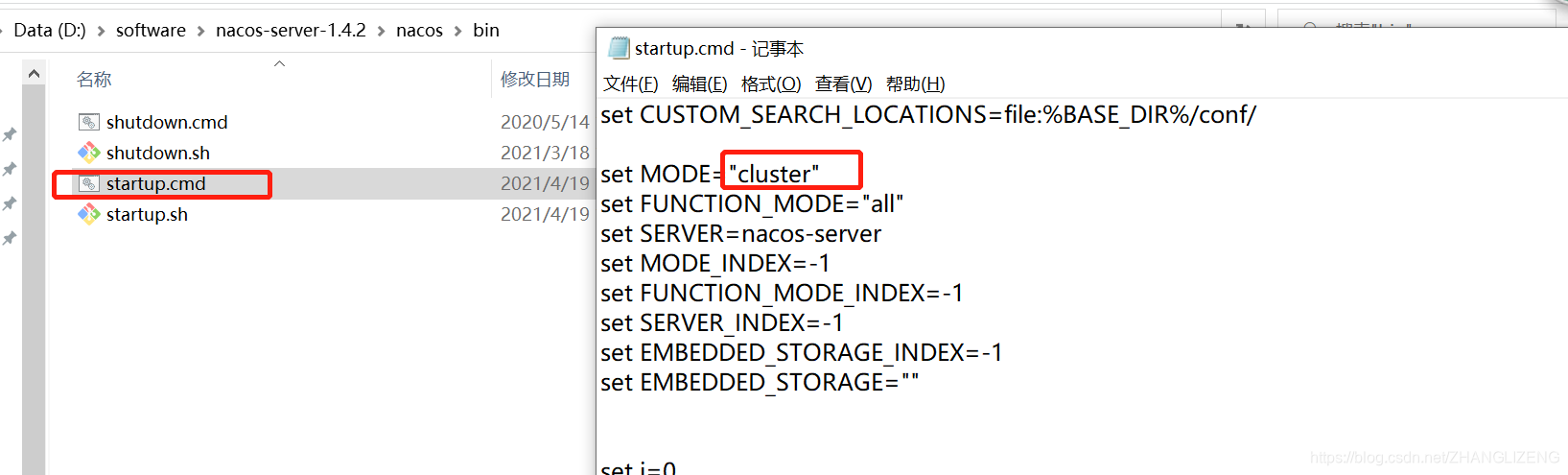
修改为单体的方式:
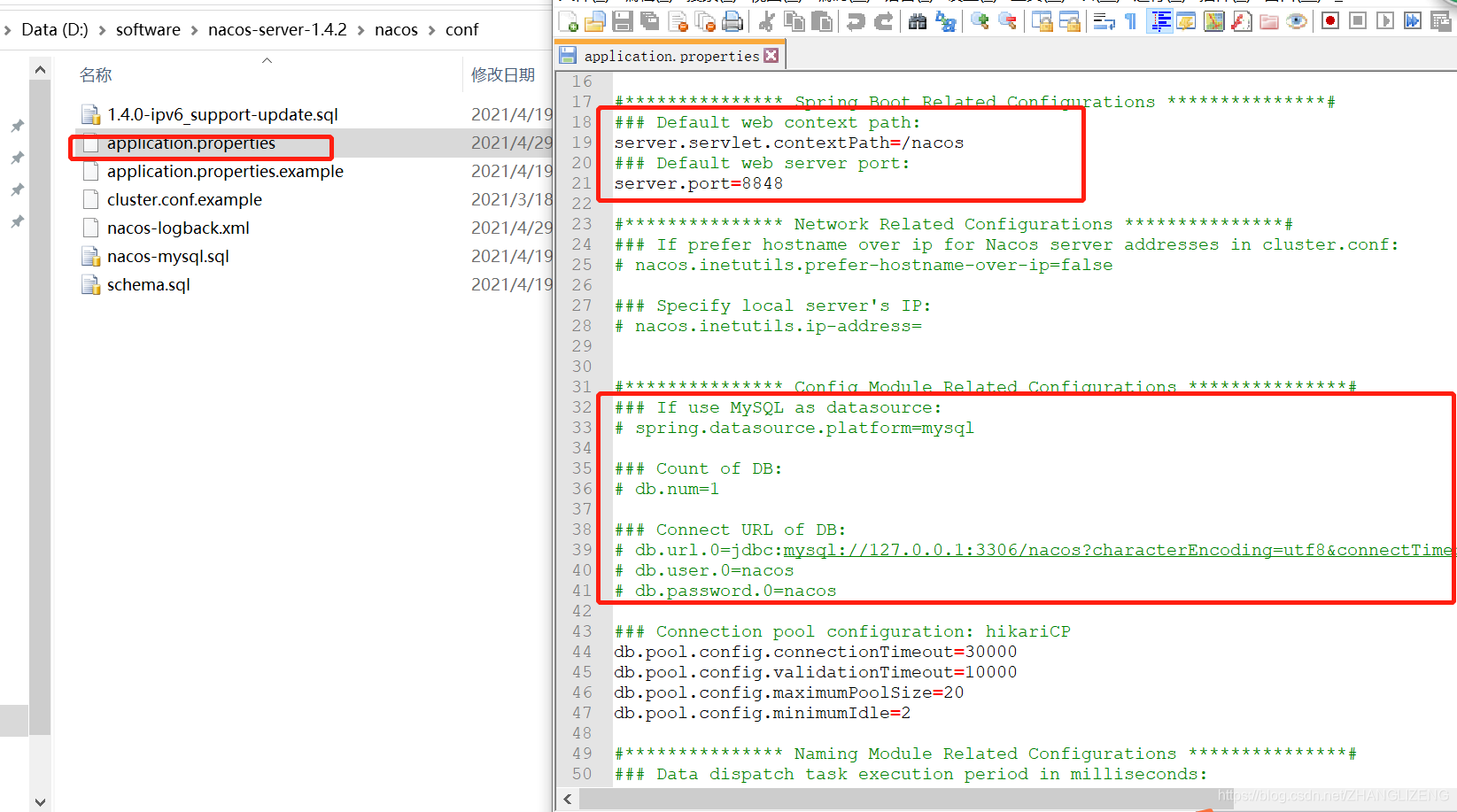
(4)在目录conf/application.properties可以修改启动的端口,是否使用数据库,数据库的配置信息等,单体的情况下不做任何修改
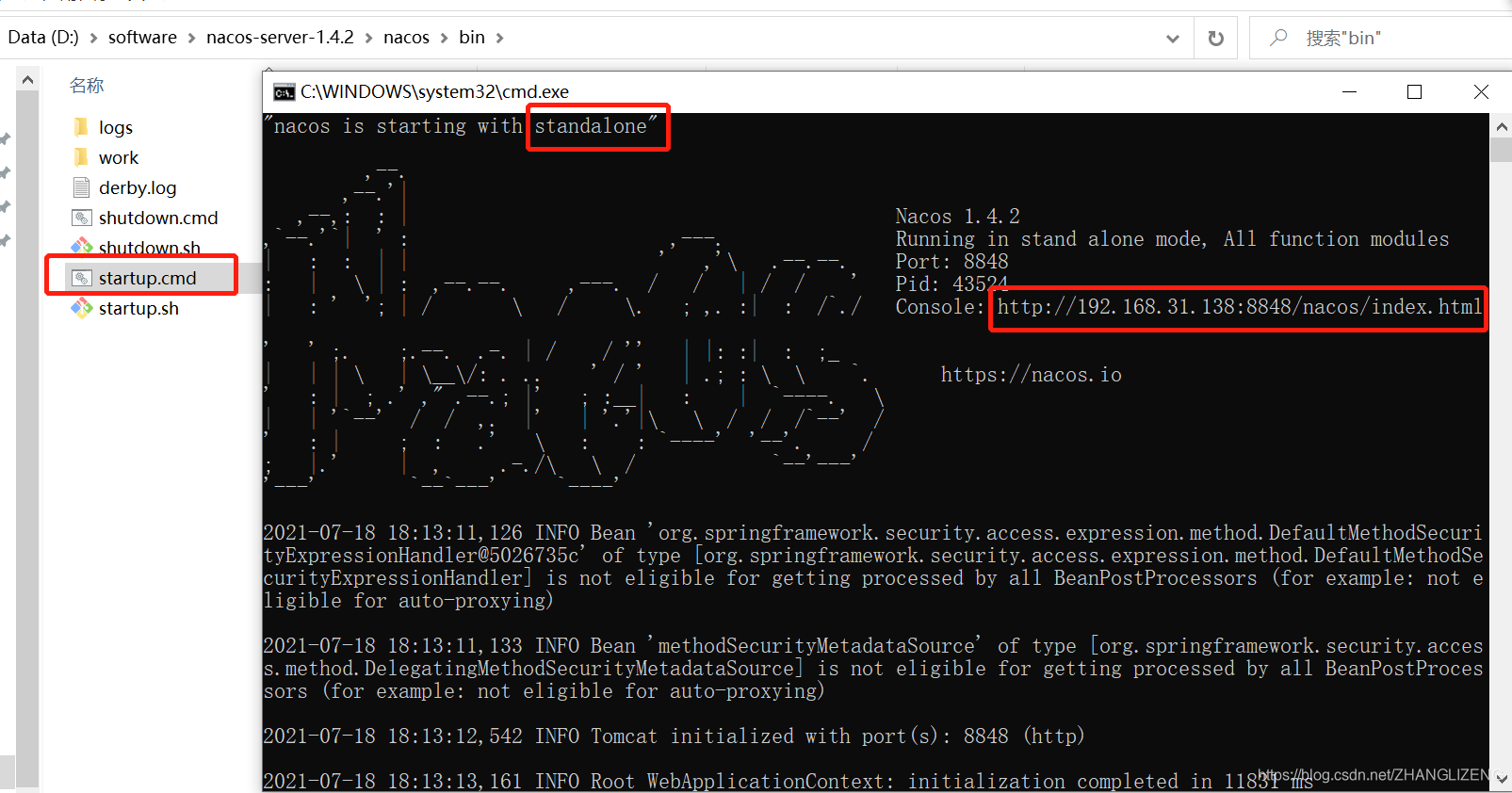
(5)目录bin/startup.cmd下双击,控制台打印出nacos启动模式,以及控制台访问连接
(6)通过Console的连接访问系统
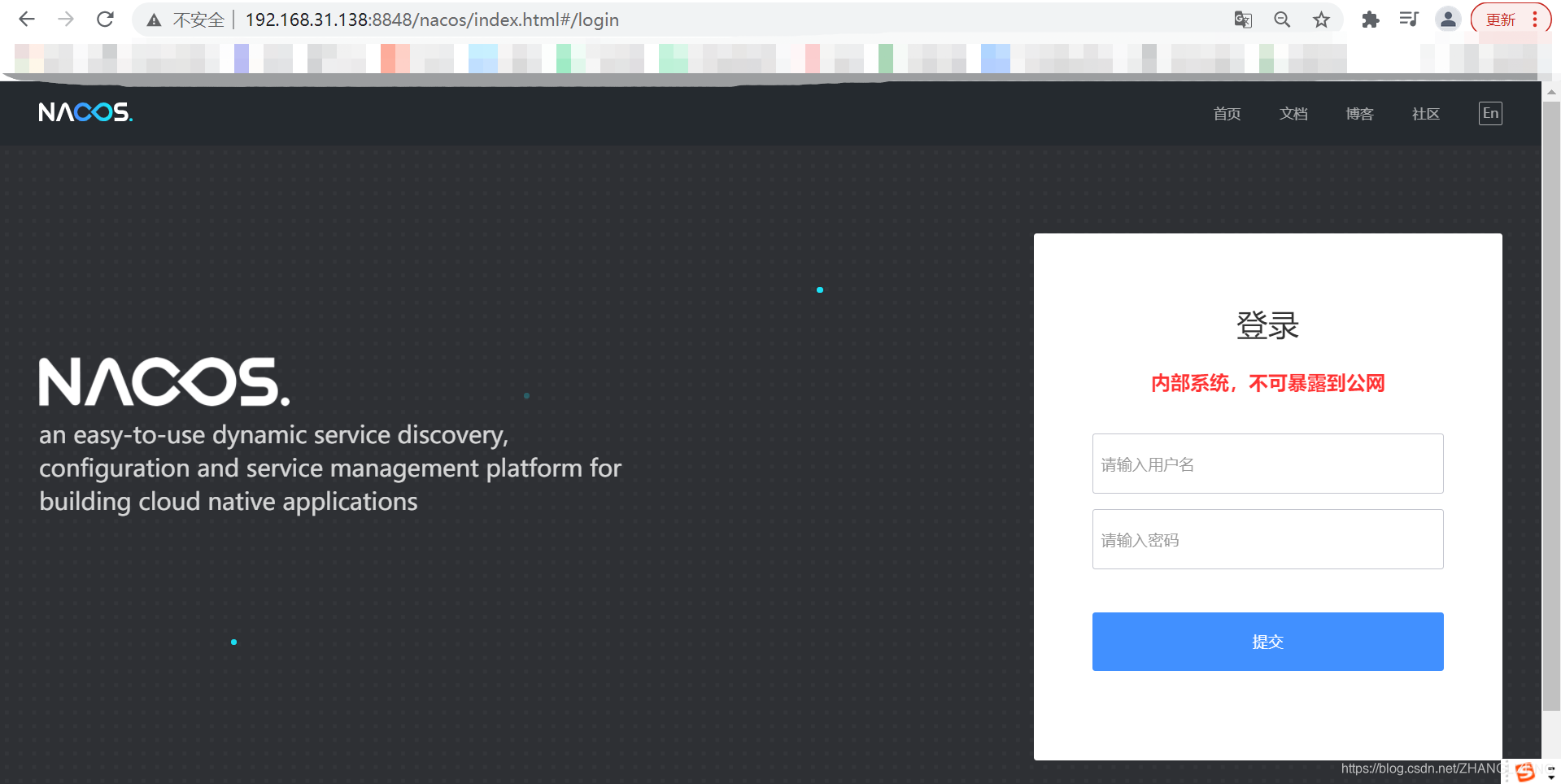
(7)输入默认用户名密码nacos/nacos,访问系统
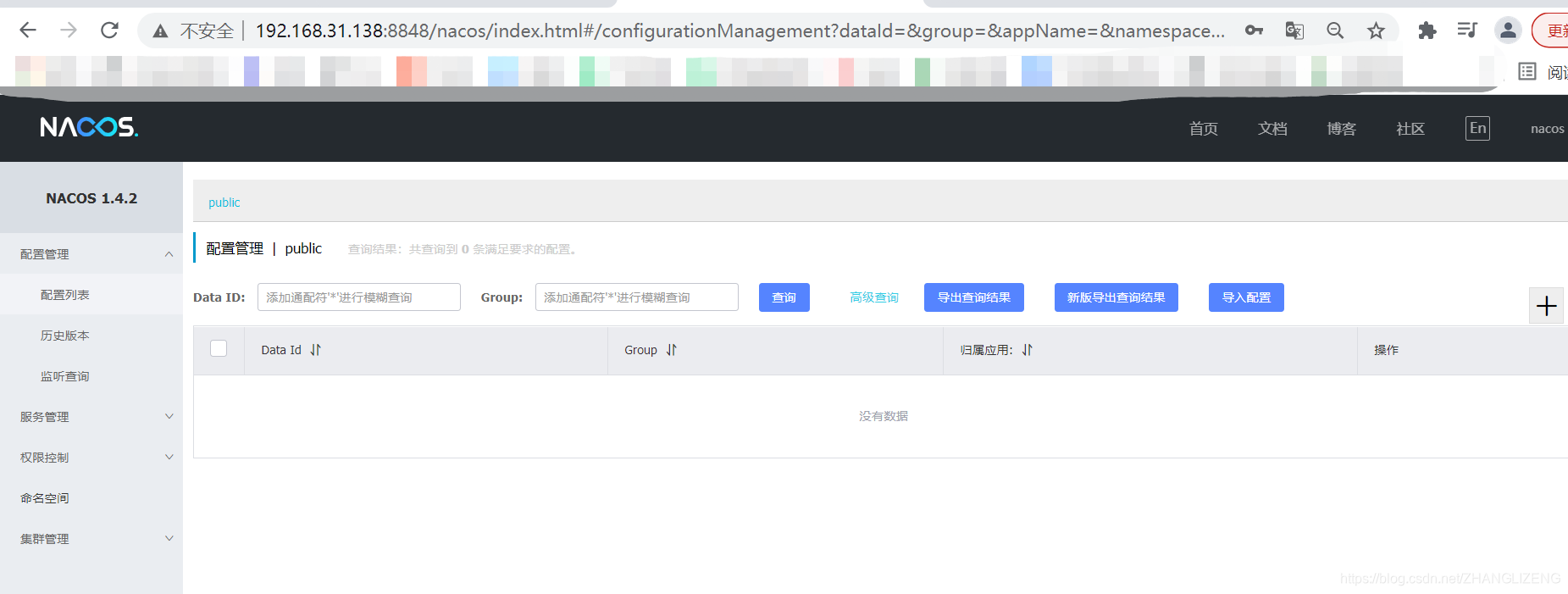
6.搭建Nacos Client服务
(1)在Spring cloud alibaba--环境搭建时创建项目的基础上,复制一份Order,命名为OrderNacos;复制一份Stock,命名为StockNacos。

(2)新复制的项目删除Order.iml和Stock.iml,分别编辑pom.xml的artifactId为OrderNacos、StockNacos
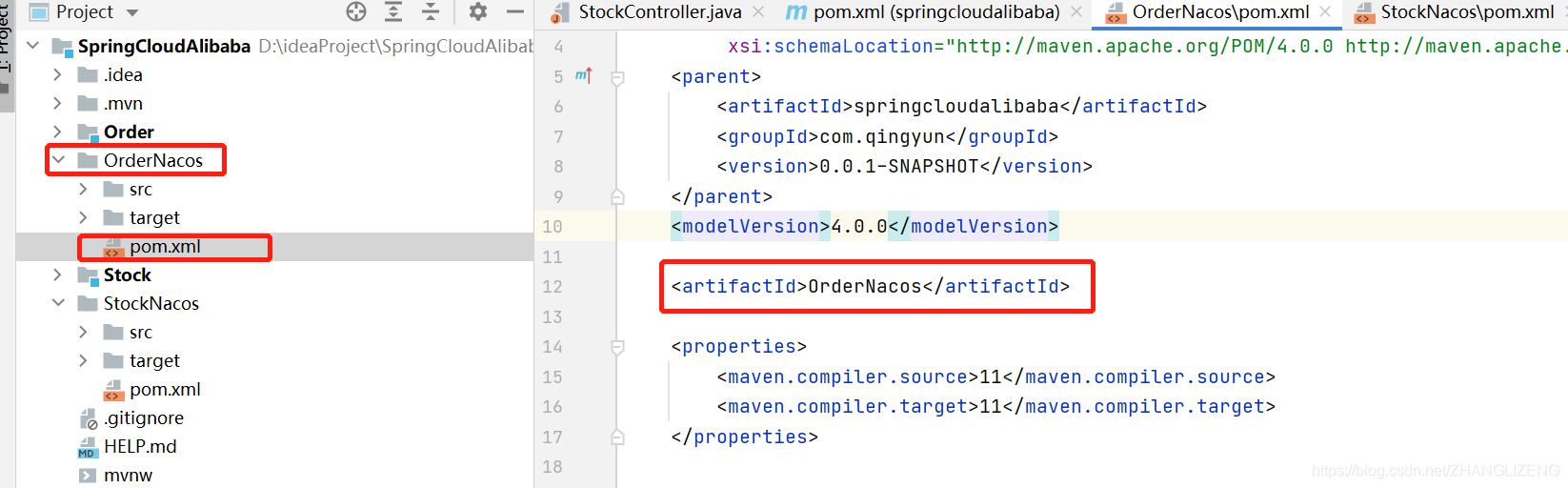
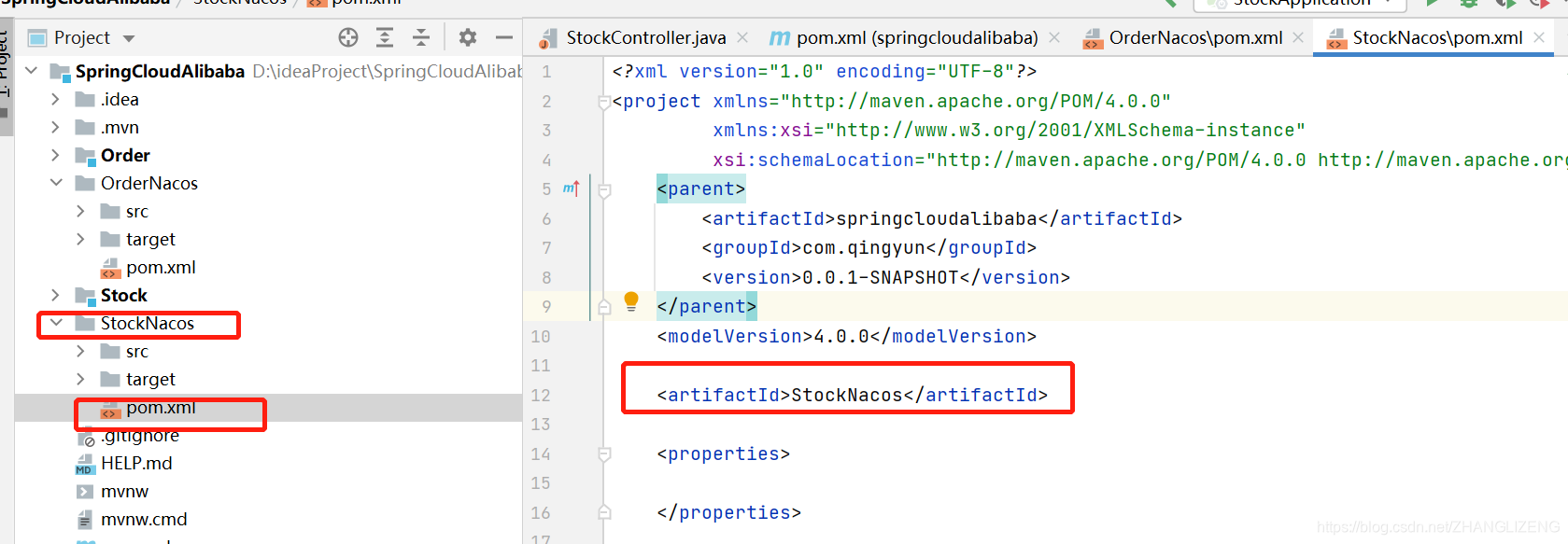
(3)由于是复制出来的项目,需要在父项目SpringCloudAlibaba的pom.xml中进行model配置,若是点击父项目新建出来的,会自动在pom.xml中配置
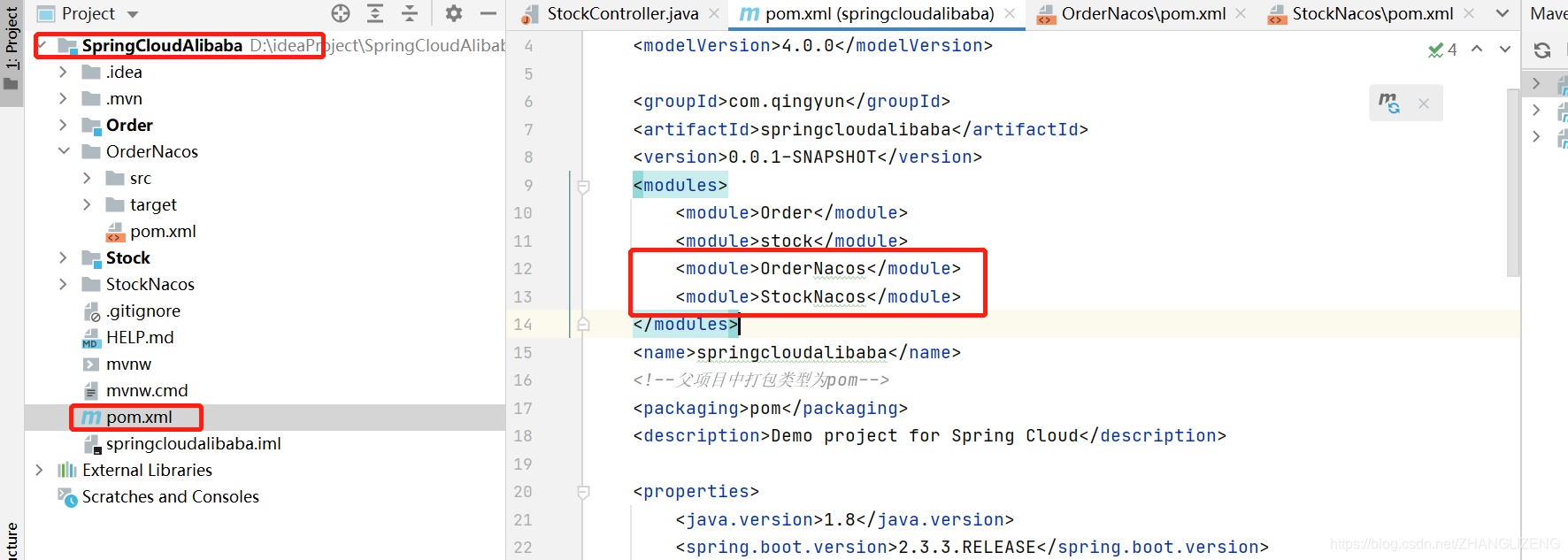
(4)刷新工程,形成编译的maven项目(项目上有蓝色框)
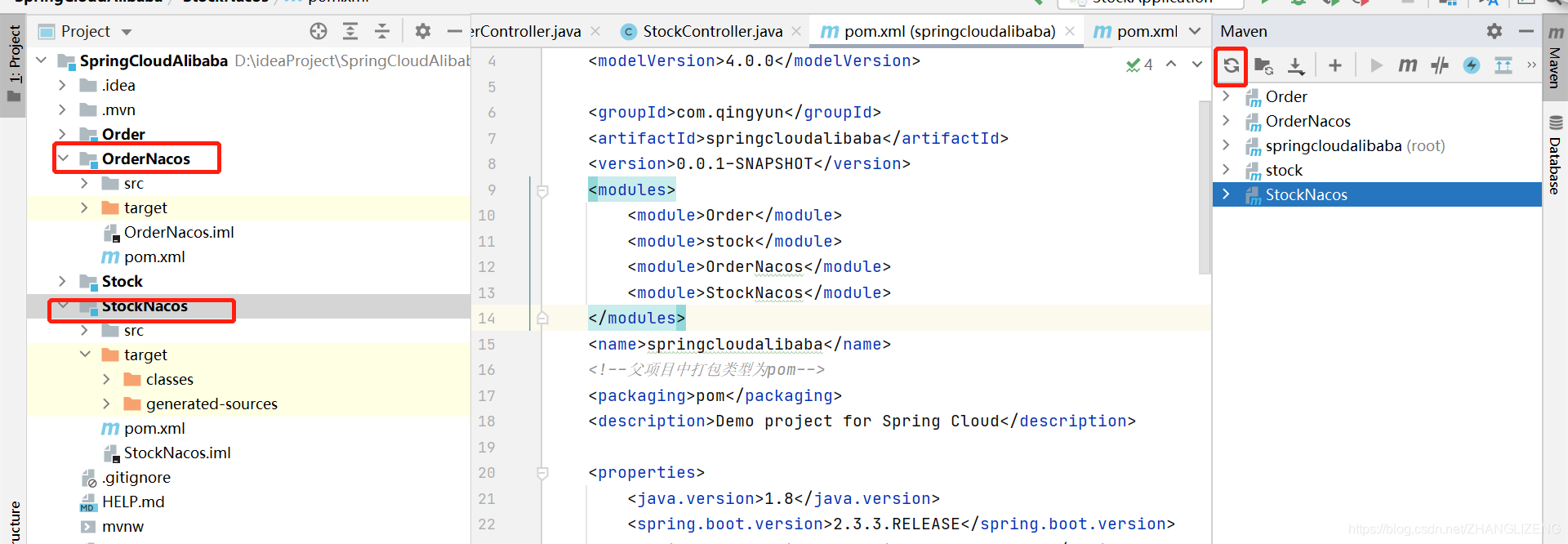
(5)OrderNacos和StockNacos项目在pom.xml中添加Nacos服务注册发现依赖
- <!-- Nacos服务注册发现-->
- <dependency>
- <groupId>com.alibaba.cloud</groupId>
- <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
- </dependency>
(6)OrderNacos和StockNacos项目在application.properties中添加Nacos服务注册的相关信息。OrderNacos项目的application.properties:
- server.port=8084
- #应用名称,nacos会将该名称当做服务名称
- spring.application.name=order-service
- #nacos服务连接地址
- spring.cloud.nacos.server-addr=127.0.0.1:8848
- #nacos discovery连接用户名
- spring.cloud.nacos.discovery.username=nacos
- #nacos discovery连接密码
- spring.cloud.nacos.discovery.password=nacos
- #nacos discovery工作空间
- spring.cloud.nacos.discovery.workspace=public
StockNacos项目的application.properties:
- server.port=8085
- #应用名称,nacos会将该名称当做服务名称
- spring.application.name=stock-service
- #nacos服务连接地址
- spring.cloud.nacos.server-addr=127.0.0.1:8848
- #nacos discovery连接用户名
- spring.cloud.nacos.discovery.username=nacos
- #nacos discovery连接密码
- spring.cloud.nacos.discovery.password=nacos
- #nacos discovery工作空间
- spring.cloud.nacos.discovery.workspace=public
(7)启动项目,控制台打印nacos注册成功--服务注册
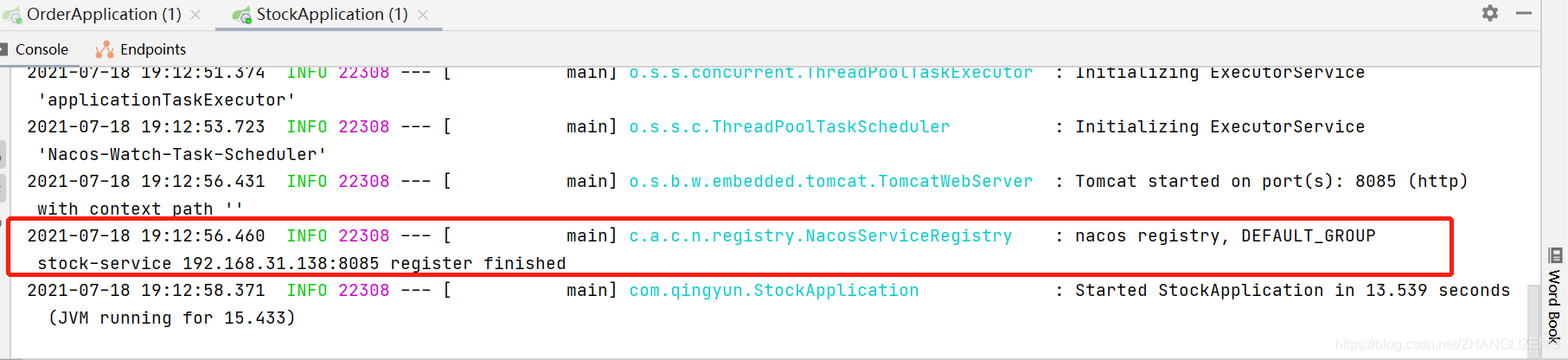
刷新Nacos控制平台,可以看到两个服务已经注册到nacos中来。

7.nacos服务心跳、服务健康检查
(1)服务心跳:在服务注册后,Nacos Client会维护一个定时心跳来持续通知Nacos Server,说明服务一直处于可用状态,防止被剔除。默认5s发送一次心跳。
(2)服务健康检查:Nacos Server会开启一个定时任务来检查注册服务实例的健康情况,对应超过15s没有收到客户端心跳的实例会将他的healthy属性设置为false(此时客户端服务再来获取服务列表时获取不到它)。如果某个实例超过30秒没有收到心跳,直接剔除该实例(被剔除的实例如果恢复发送心跳则会重新注册)。
(3)停止一个服务stock-service,通过控制台刷新查看服务列表变化。
15秒后触发保护阈值,由false变为true:
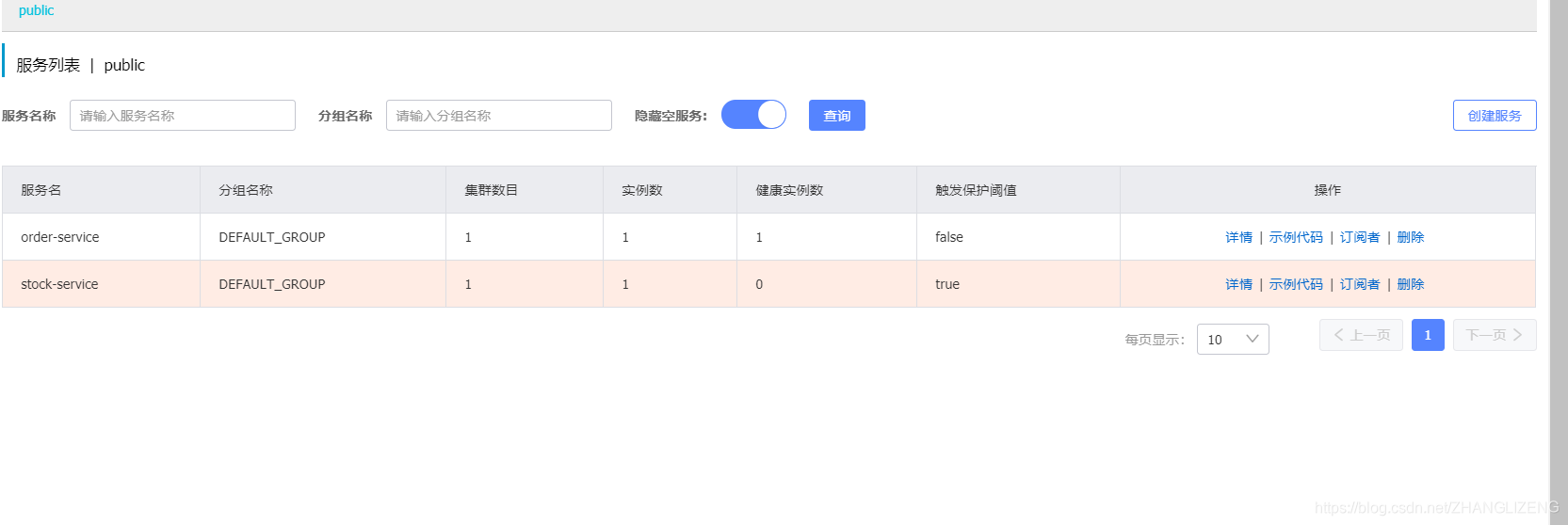
点击详情查看健康状态为false:
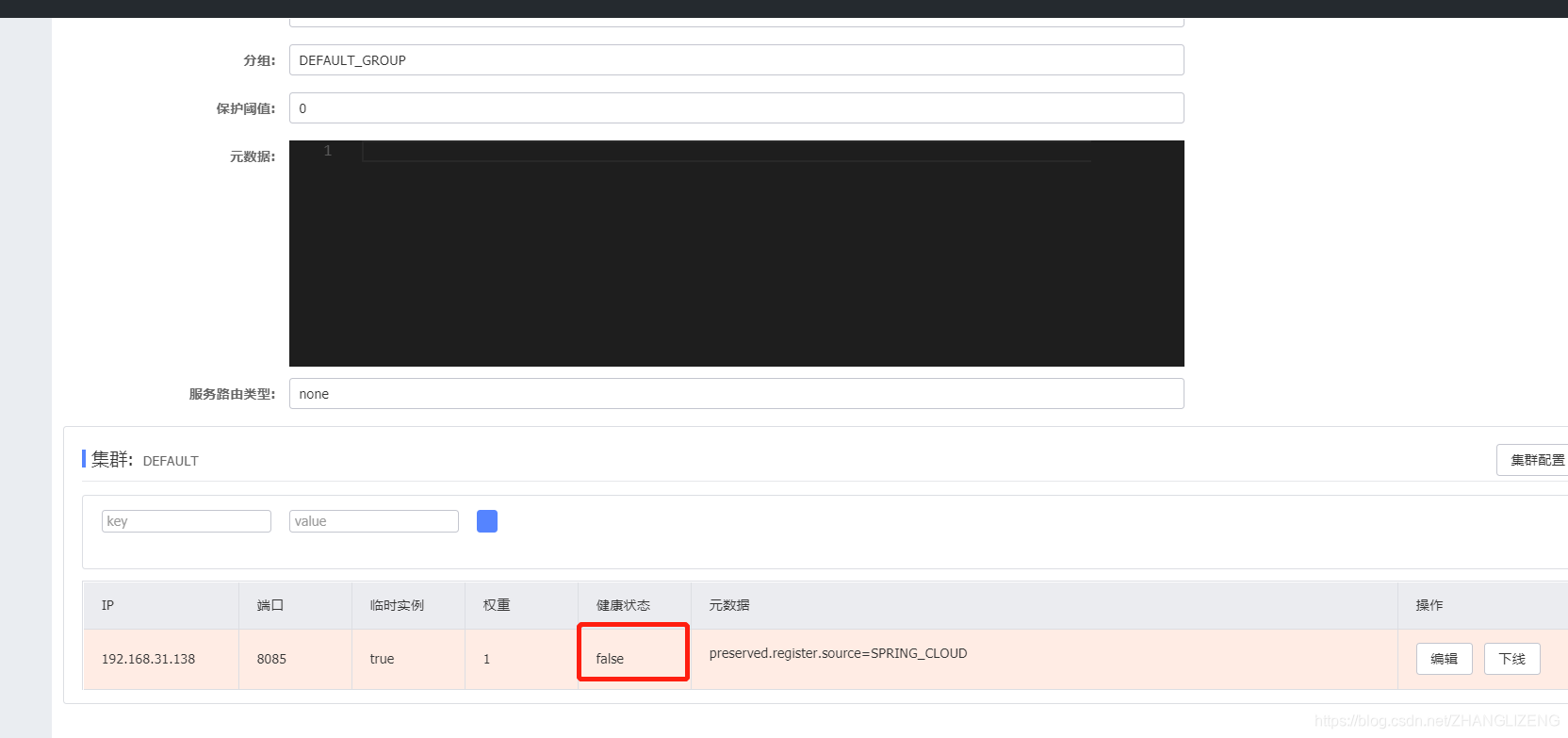
30秒之后,从服务列表中移出: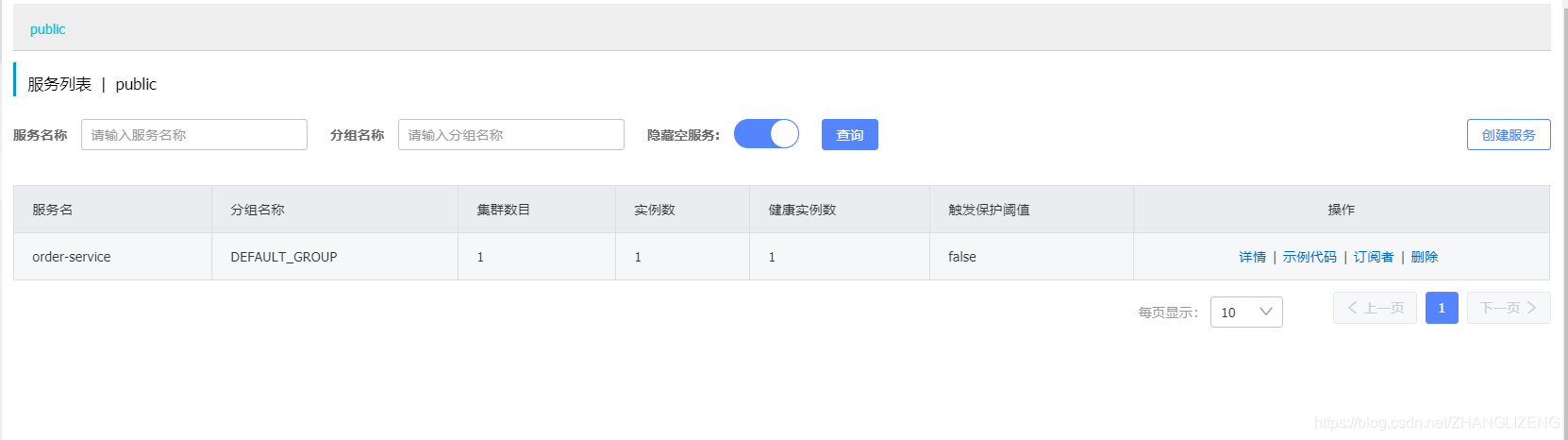
再次启动服务,再次把服务注册进来:
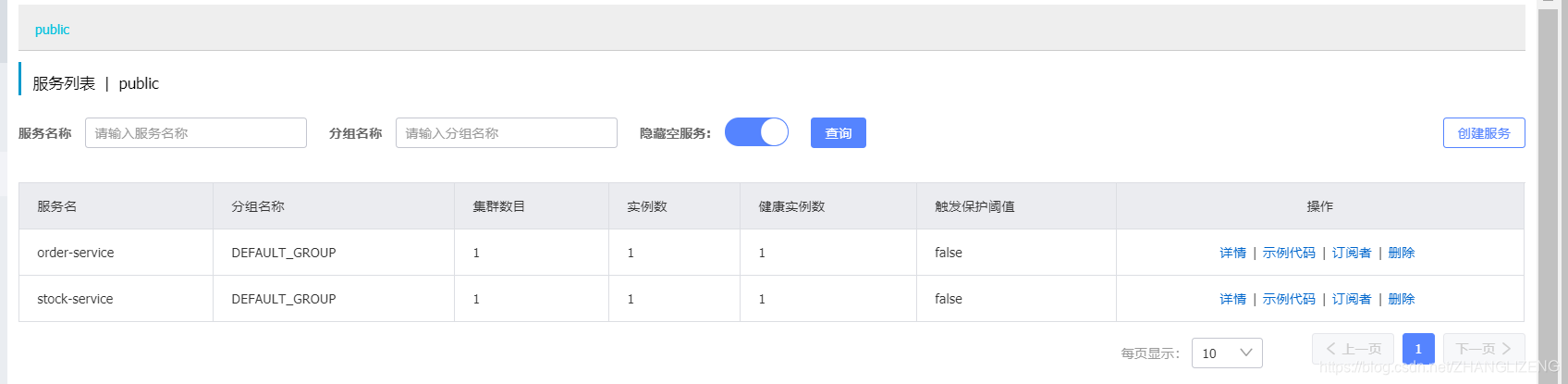
Nacos客户端心跳机制原理:
当客户端启动后,会向nacos中注册服务,同时创建一个ScheduledThreadPoolExecutor定时线程池,使用线程池的定时机制向nacos服务器发送注册服务,每次发送心跳完成,再次创建一个定时任务。创建ScheduledThreadPoolExecutor的源码:
- public class BeatReactor {
- public BeatReactor(NamingProxy serverProxy, int threadCount) {
- this.serverProxy = serverProxy;
- // 创建一个线程池
- executorService = new ScheduledThreadPoolExecutor(threadCount, new ThreadFactory() {
- @Override
- public Thread newThread(Runnable r) {
- Thread thread = new Thread(r);
- thread.setDaemon(true);
- thread.setName("com.alibaba.nacos.naming.beat.sender");
- return thread;
- }
- });
- }
- }
第一次发送心跳注册的源码:
- public void addBeatInfo(String serviceName, BeatInfo beatInfo) {
- NAMING_LOGGER.info("[BEAT] adding beat: {} to beat map.", beatInfo);
- String key = buildKey(serviceName, beatInfo.getIp(), beatInfo.getPort());
- BeatInfo existBeat = null;
- //fix #1733
- if ((existBeat = dom2Beat.remove(key)) != null) {
- existBeat.setStopped(true);
- }
- dom2Beat.put(key, beatInfo);
- /**
- * 这个schedule只会发送一次心跳
- */
- executorService.schedule(new BeatTask(beatInfo), beatInfo.getPeriod(), TimeUnit.MILLISECONDS);
- MetricsMonitor.getDom2BeatSizeMonitor().set(dom2Beat.size());
- }
发送执行的Runnable是BeatTask类,看下BeatTask的源码:
- @Override
- public void run() {
- if (beatInfo.isStopped()) {
- return;
- }
- long nextTime = beatInfo.getPeriod();
- try {
- /**
- * 这里是去调用服务端的心跳检测的代码
- * 这里返回的报文中,会有一个下次心跳检测的执行间隔
- */
- JsonNode result = serverProxy.sendBeat(beatInfo, BeatReactor.this.lightBeatEnabled);
- long interval = result.get("clientBeatInterval").asLong();
- boolean lightBeatEnabled = false;
- if (result.has(CommonParams.LIGHT_BEAT_ENABLED)) {
- lightBeatEnabled = result.get(CommonParams.LIGHT_BEAT_ENABLED).asBoolean();
- }
- BeatReactor.this.lightBeatEnabled = lightBeatEnabled;
- if (interval > 0) {
- nextTime = interval;
- }
- int code = NamingResponseCode.OK;
- if (result.has(CommonParams.CODE)) {
- code = result.get(CommonParams.CODE).asInt();
- }
- if (code == NamingResponseCode.RESOURCE_NOT_FOUND) {
- Instance instance = new Instance();
- instance.setPort(beatInfo.getPort());
- instance.setIp(beatInfo.getIp());
- instance.setWeight(beatInfo.getWeight());
- instance.setMetadata(beatInfo.getMetadata());
- instance.setClusterName(beatInfo.getCluster());
- instance.setServiceName(beatInfo.getServiceName());
- instance.setInstanceId(instance.getInstanceId());
- instance.setEphemeral(true);
- try {
- serverProxy.registerService(beatInfo.getServiceName(),
- NamingUtils.getGroupName(beatInfo.getServiceName()), instance);
- } catch (Exception ignore) {
- }
- }
- } catch (NacosException ex) {
- NAMING_LOGGER.error("[CLIENT-BEAT] failed to send beat: {}, code: {}, msg: {}",
- JacksonUtils.toJson(beatInfo), ex.getErrCode(), ex.getErrMsg());
-
- }
- /**
- * 在心跳机制的方法里面,会循环调用这个方法进行重复发送心跳
- */
- executorService.schedule(new BeatTask(beatInfo), nextTime, TimeUnit.MILLISECONDS);
- }

每次调用executorService.schedule定时任务,任务的具体执行者是BeatTask,当BeatTask执行完成,又调用executorService.schedule,循环访问,实现心跳注册机制。
8. Nacos服务调用、负载均衡
(1)服务之间调用,需要使用负载均衡器
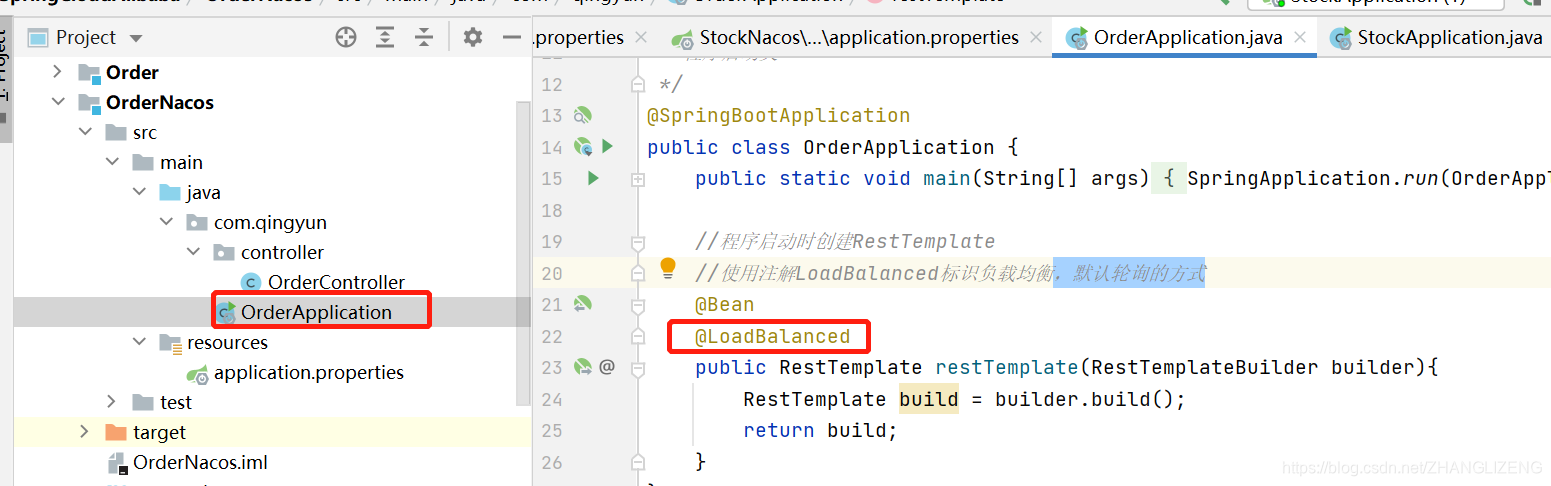
(2)RestTemplate创建时添加负载均衡配置@LoadBalanced,默认轮询的方式
(3)服务调动的地址,可以把ip+端口替成系统名称
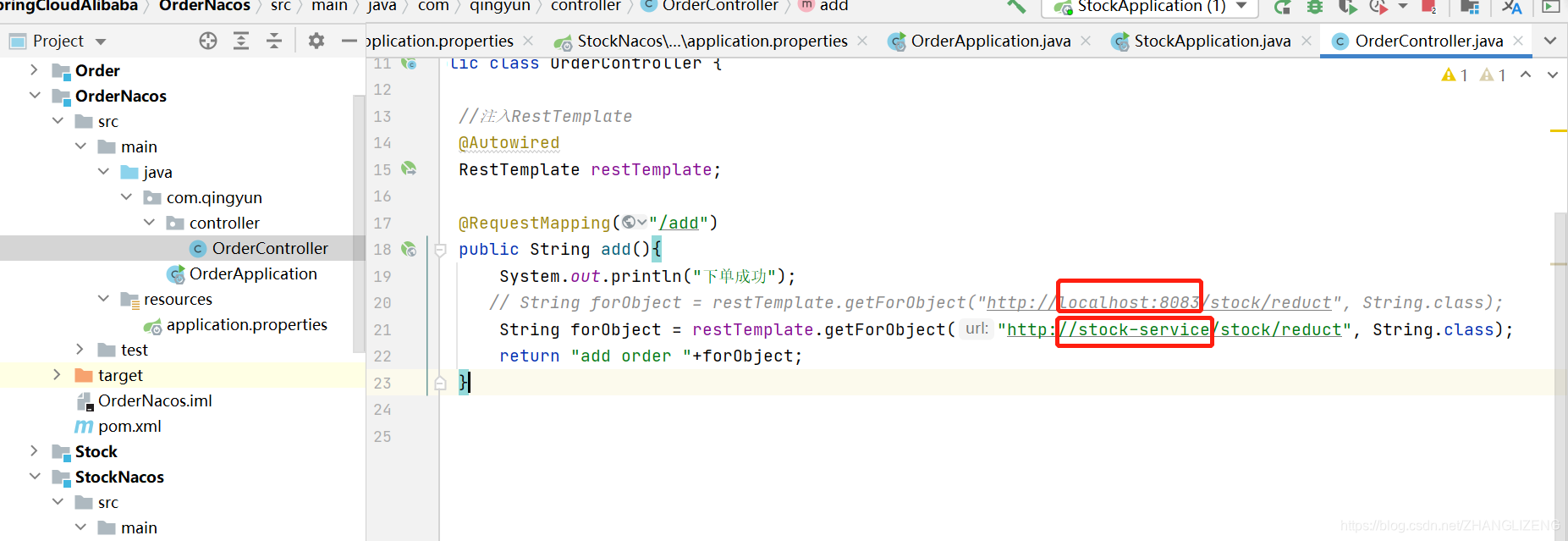
库存系统服务名称:

(4)页面访问订单系统方法,使用负载均衡调用另一个系统,返回结果值

9.启动多个提供者,进行负载均衡调用
(1)idea2020开启Services管理多个启动类,之前版本是Run dashboard
控制台添加services:View->Tool Windows ->Services
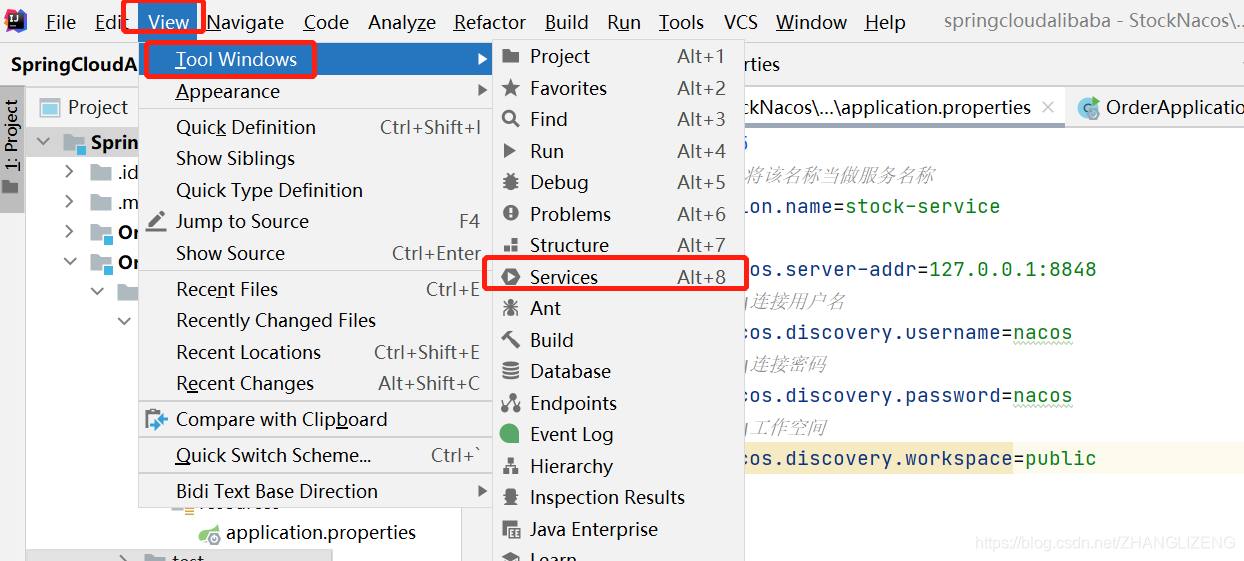
点开底栏的Services,第一次点开是一片空白。点add,点Run Configuration Type,弹出一个菜单,选择Spring Boot。
此时会罗列出一系列的Spring Boot启动类
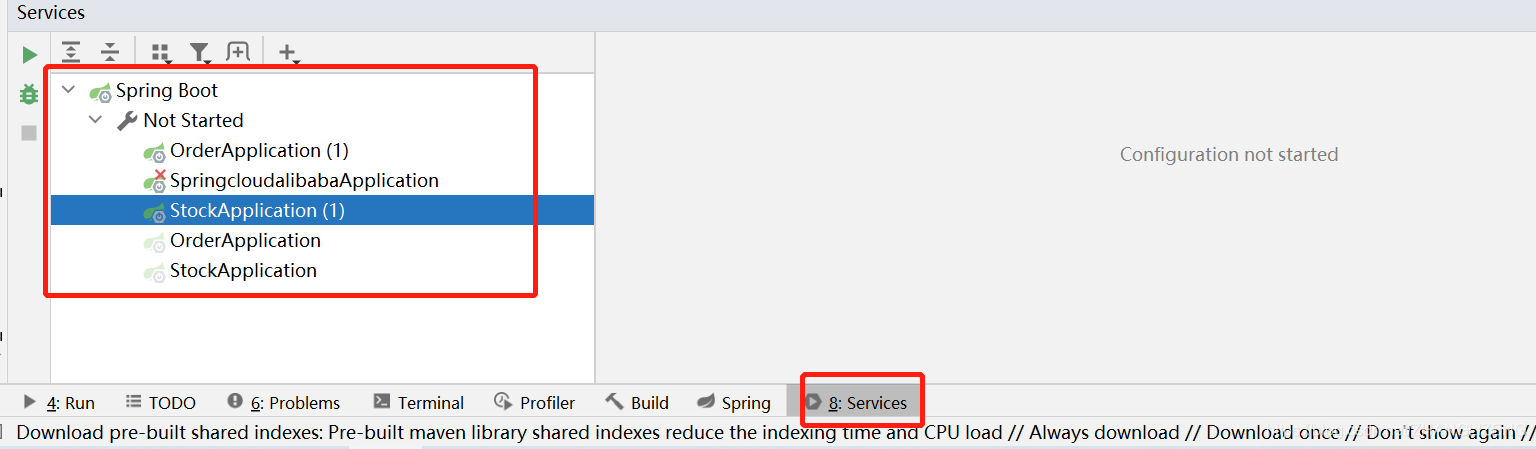
可以右键编辑启动服务类名
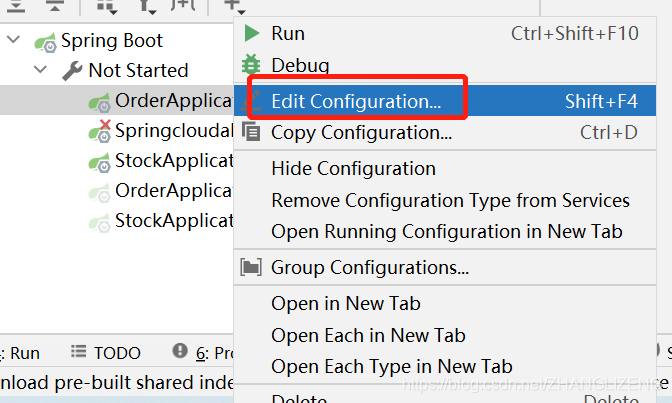
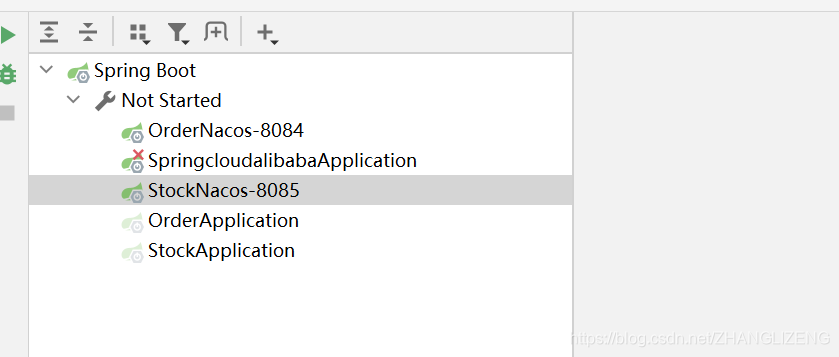
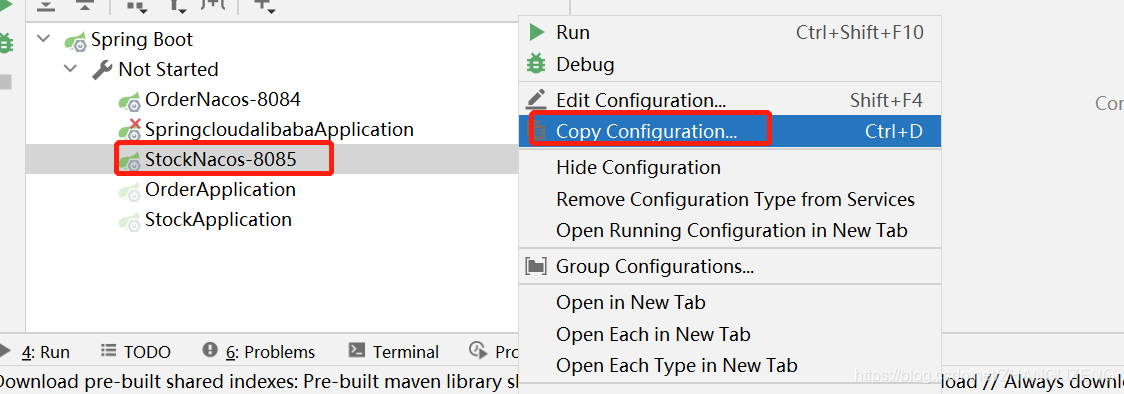
(2)复制一份库存订单启动系统,修改下端口:右键启动项选择Copy Configuration
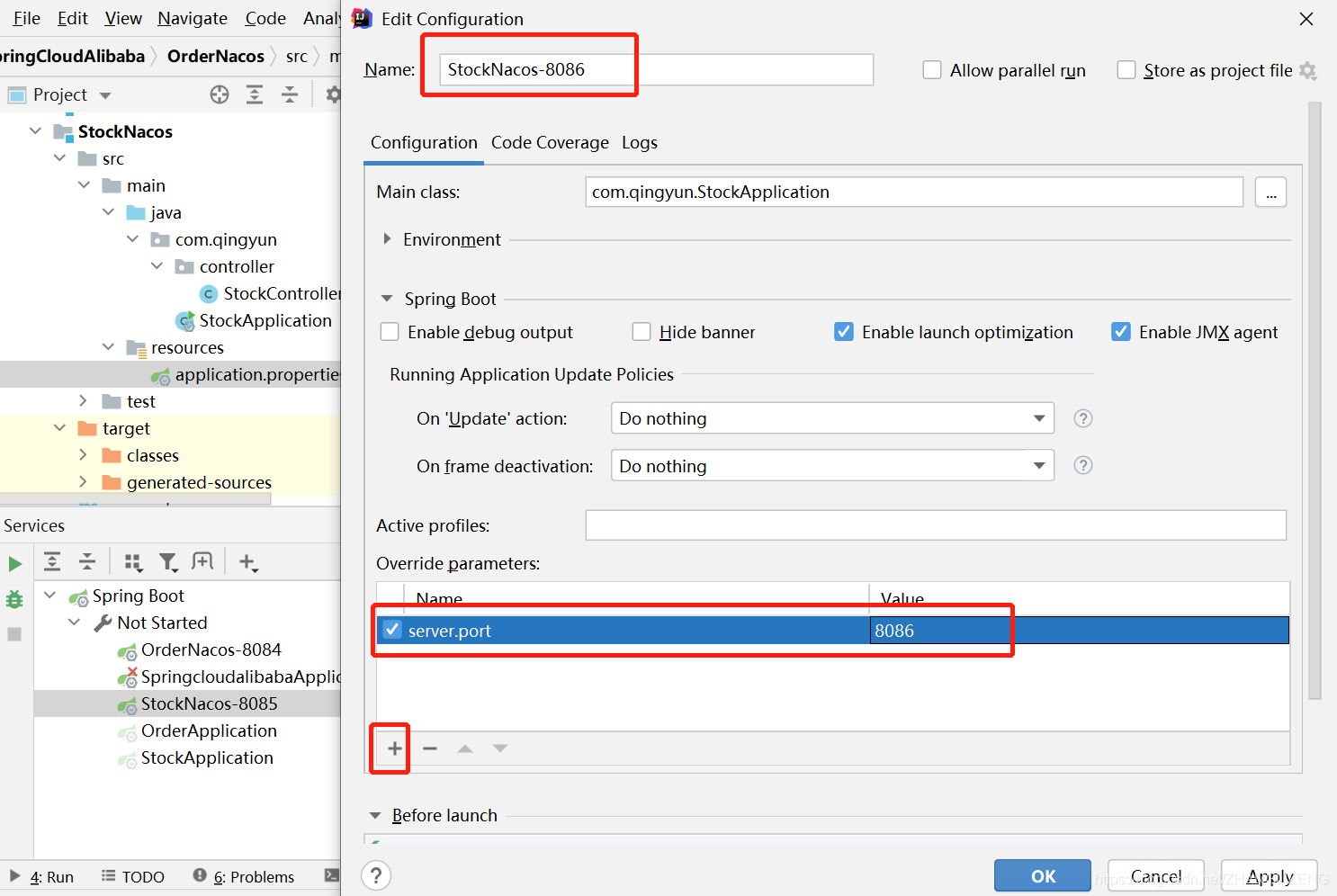
修改Name名称,覆盖的参数为server.port系统端口号
(3)配置通过服务名调用服务
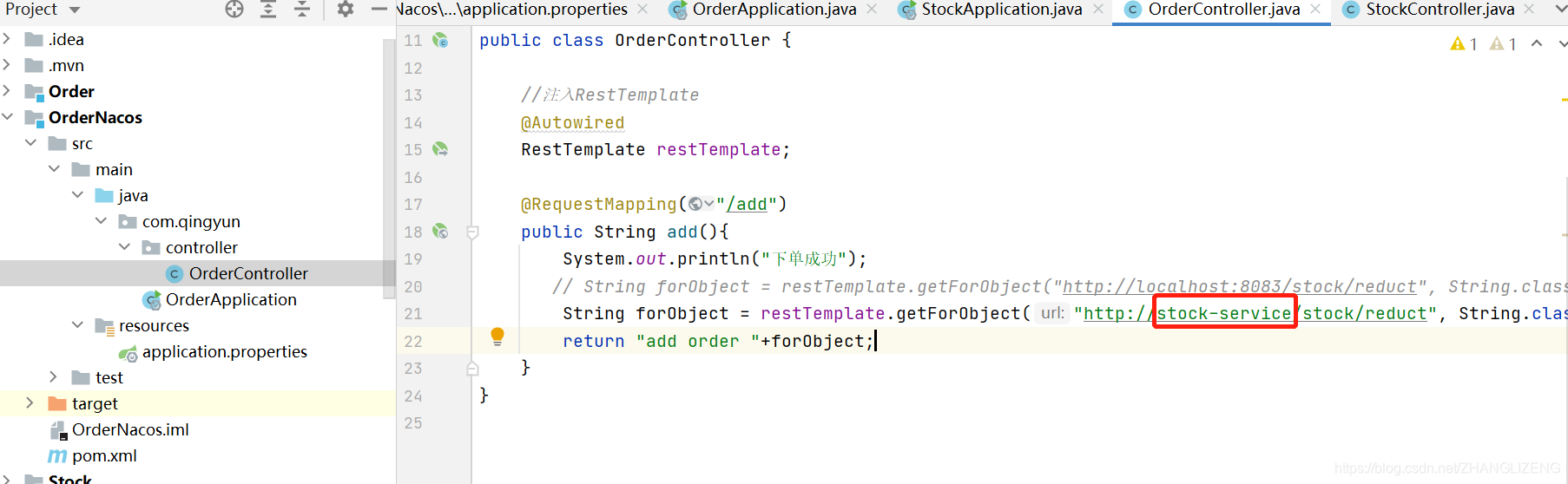
(4)创建调用的RestTemplate需要使用负载均衡的注解@LoadBalanced
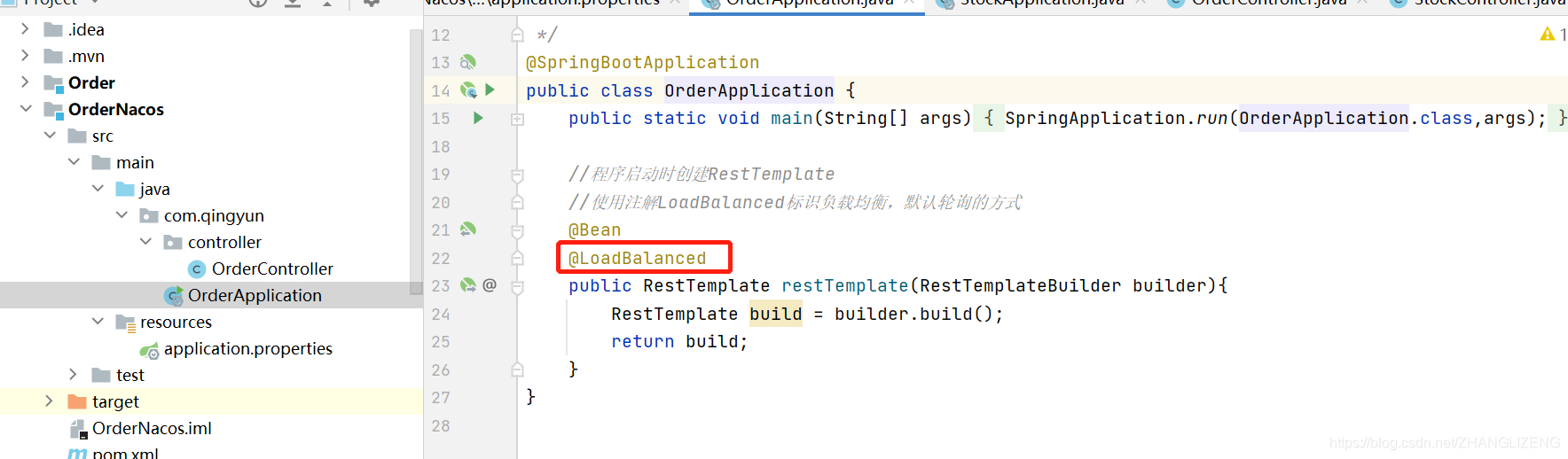
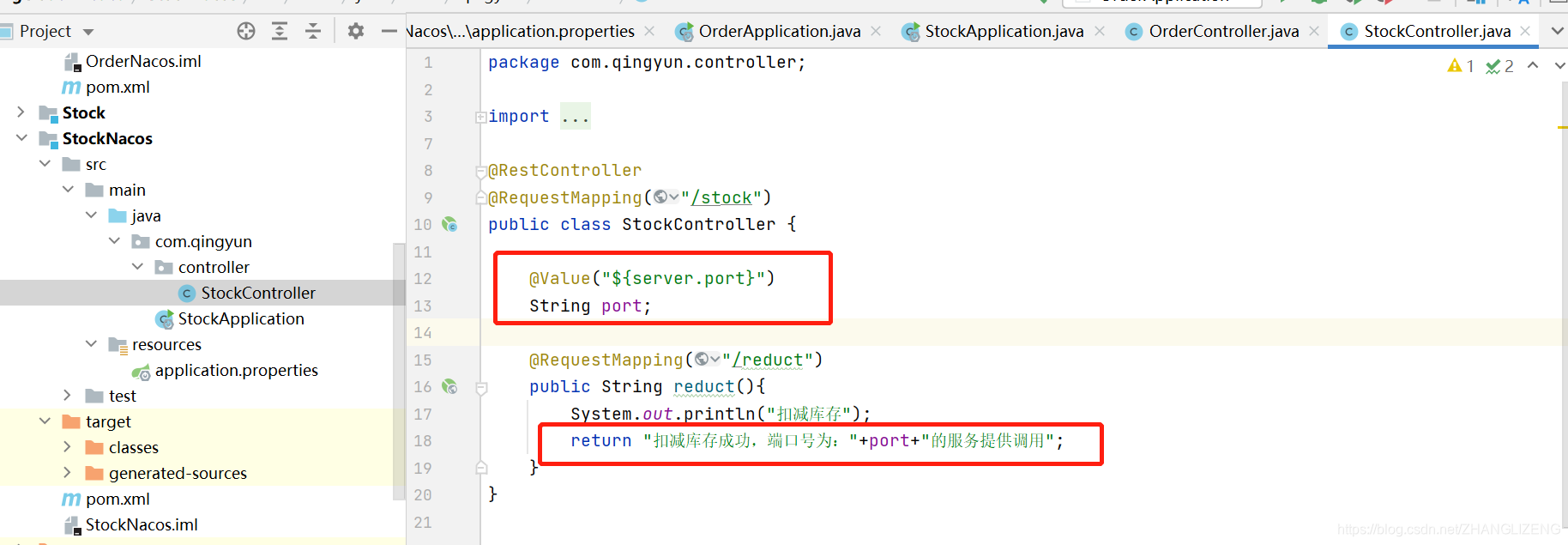
(5)被调用的类中添加此系统的端口号,用于区分调用时哪个系统响应的
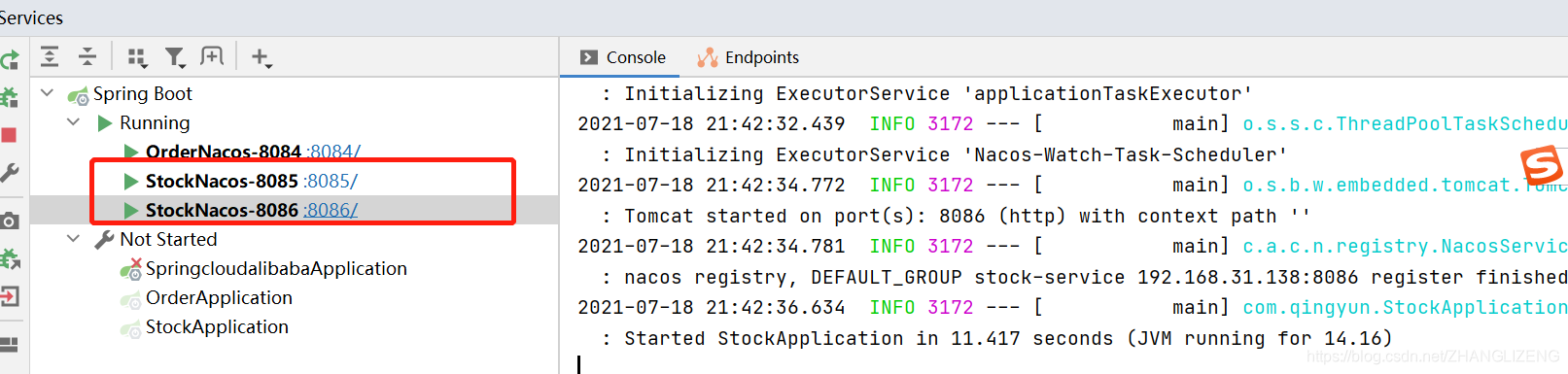
(6)启动这两个不同端口的提供者(库存项目)
(7)页面访问系统,使用负载均衡,轮询处理请求
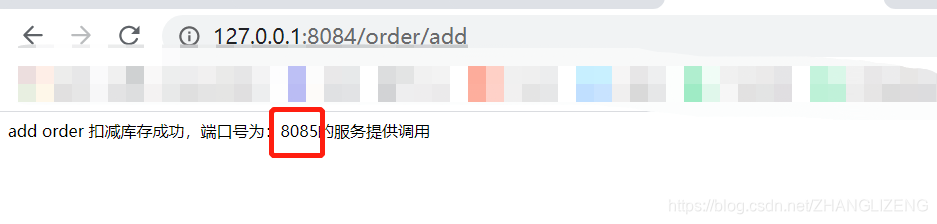

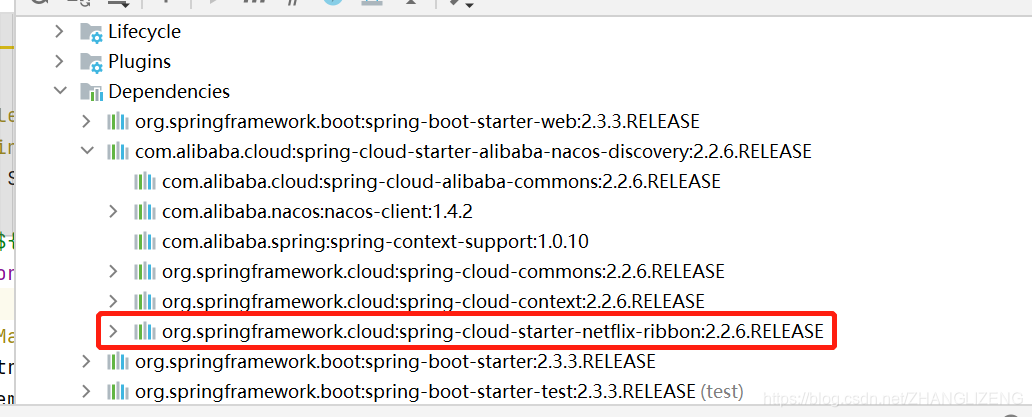
(8)通过依赖的jar可以看出,使用的负载均衡为ribbon
10.服务永久实例、保护阈值、雪崩保护
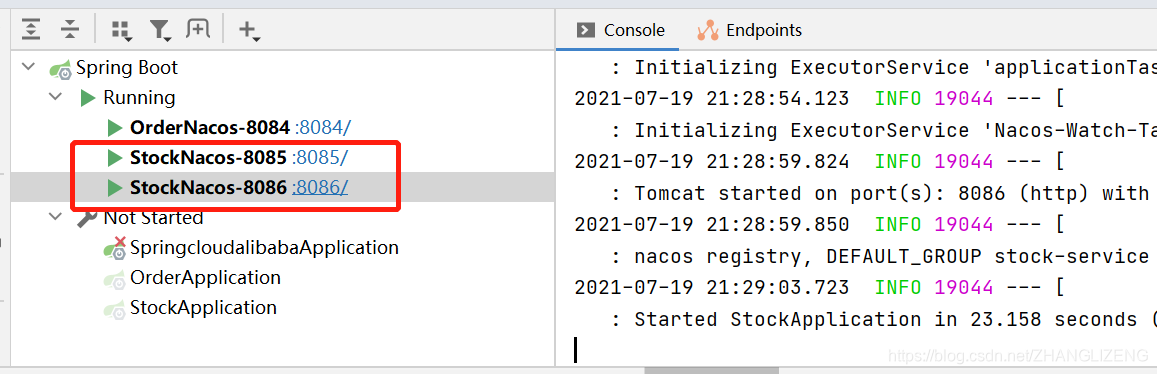
(1)启动服务名称相同端口不同的两个服务,从控制台可以看到实例数为2

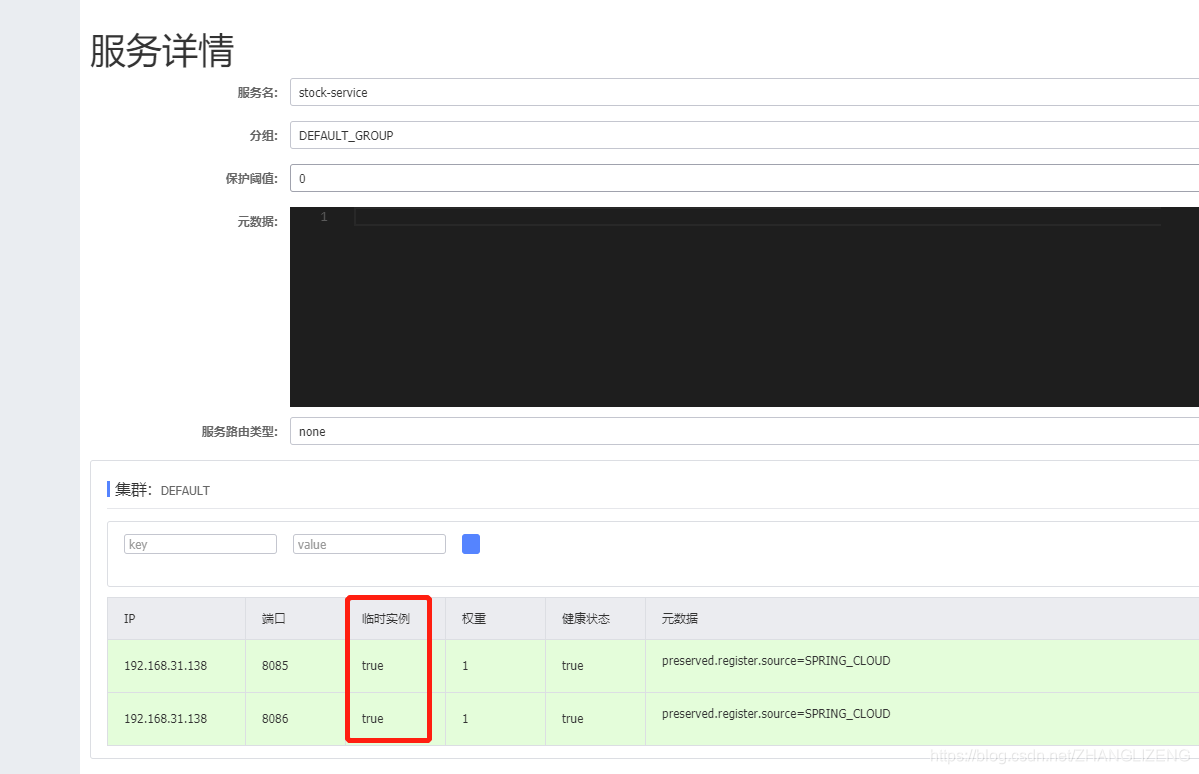
(2)目前Nacos注册的服务都是临时实例,当服务宕机后有心跳检测和剔除服务的操作;
在application.properties中配置服务为永久实例,添加配置
- #永久实例,服务宕机后也不会被剔除,默认是true临时实例
- spring.cloud.nacos.discovery.ephemeral=false
重启服务后:属于永久实例,心跳检测机制也不会把服务从服务列表中剔除
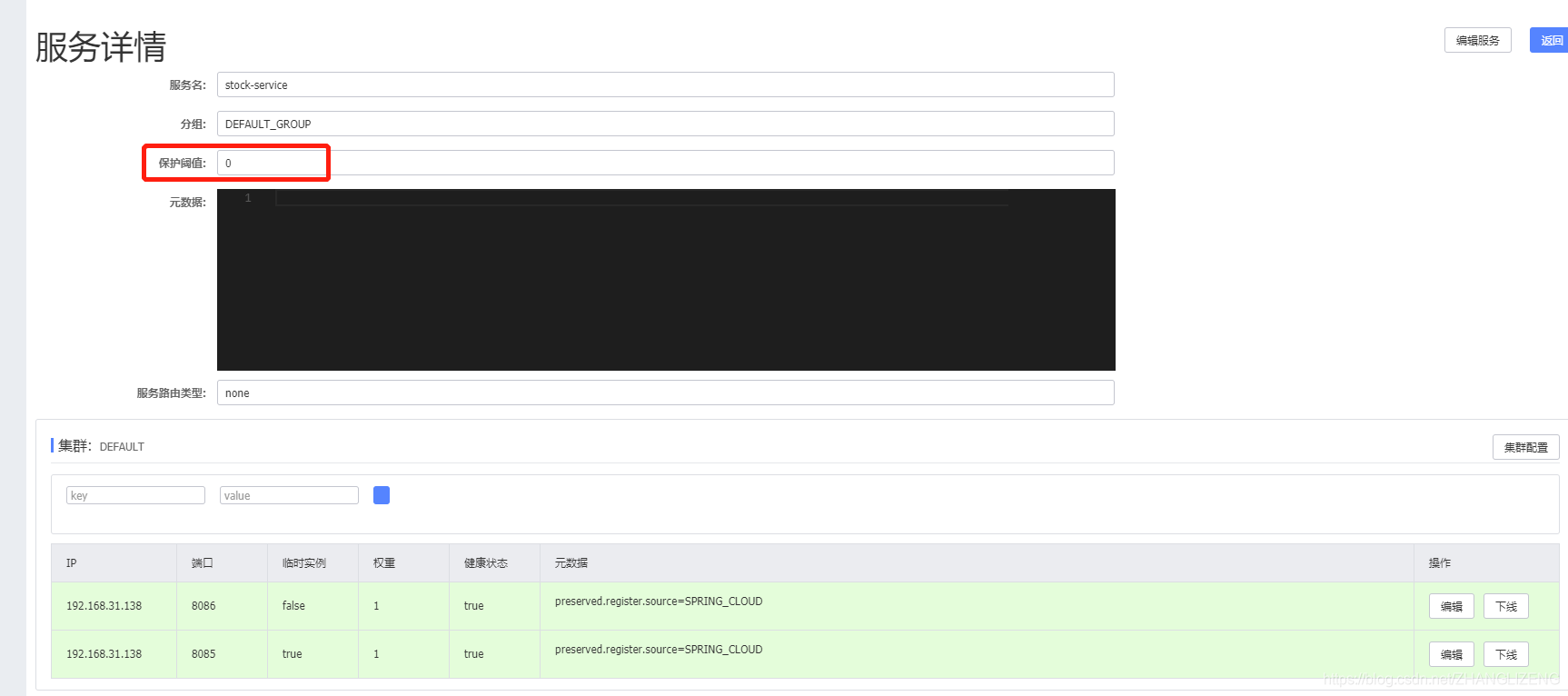
 (3)我们可以设置服务保护阈值,用于防止服务雪崩。
(3)我们可以设置服务保护阈值,用于防止服务雪崩。
例:当我们设置保护阈值为0.6,当健康实例/总实例数 < 保护阈值时,为了防止服务雪崩,服务全部不能使用,就算宕机的服务也会对外提供服务。服务雪崩:请求的数量大于服务器处理的能力,会导致但服务器处理不过来集群架构才能处理的洪峰。
11.Nacos更多配置项
地址:Nacos discovery · alibaba/spring-cloud-alibaba Wiki · GitHub
| 配置项 | Key | 默认值 | 说明 |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
12.Nacos集群部署
(1)单机环境下部署伪集群,复制nacos,分别命名为nacos8849、nacos8850、nacos8851
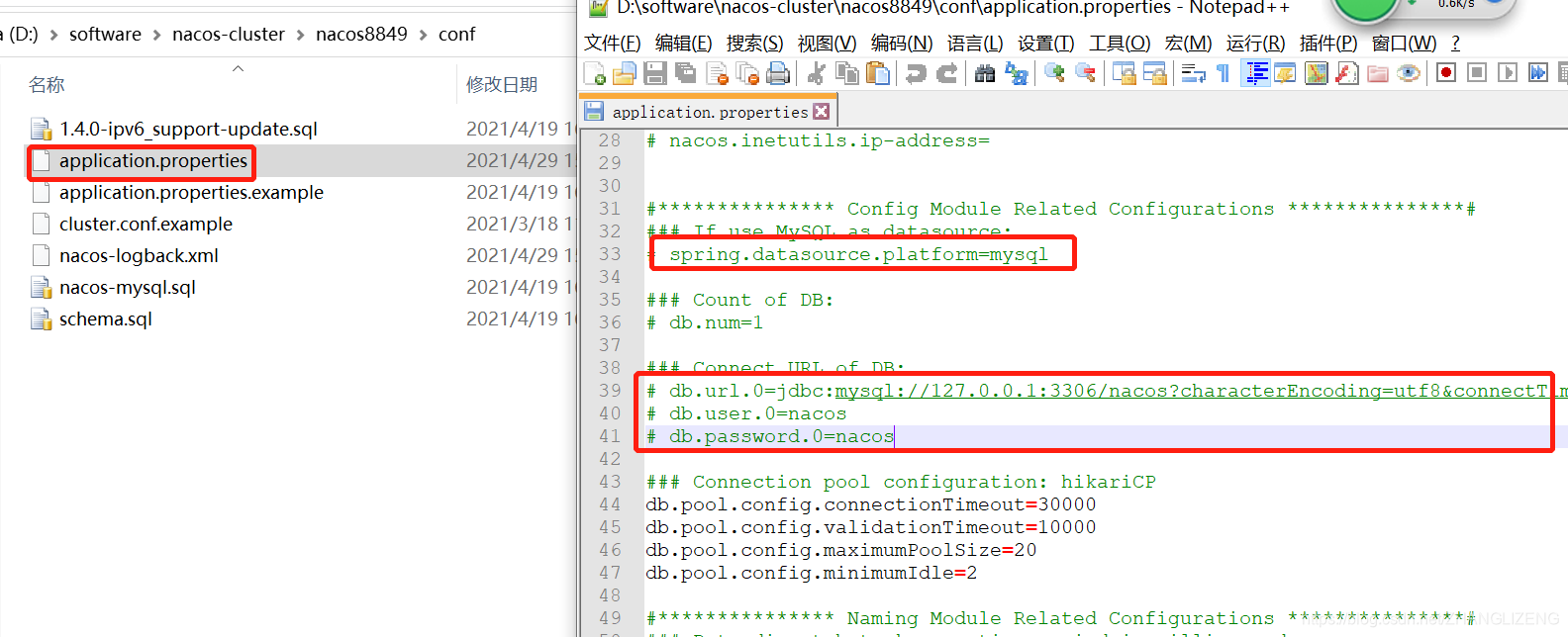
(2)配置mysql数据源(版本要求,5.7及以上),若是不配置数据源,nacos所有的操作都在内存中进行,没法进行集群方式管理。在目录conf/application.properties中配置数据源,默认使用mysql,修改位置:
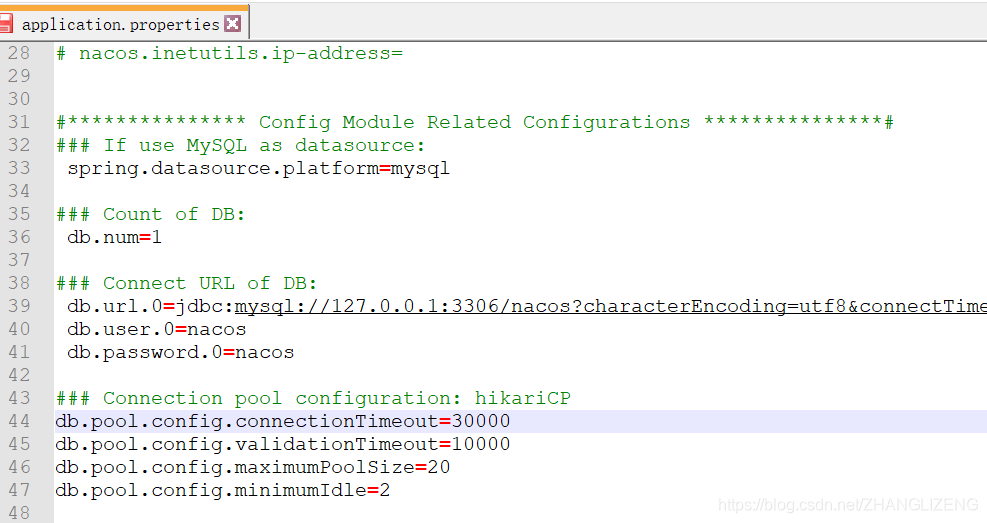
修改情况:放开注释,配置mysql的连接信息(用户名密码等信息),三个集群的nacos都修改
(3)在连接的数据库中创建nacos数据库,执行命令
CREATE DATABASE nacos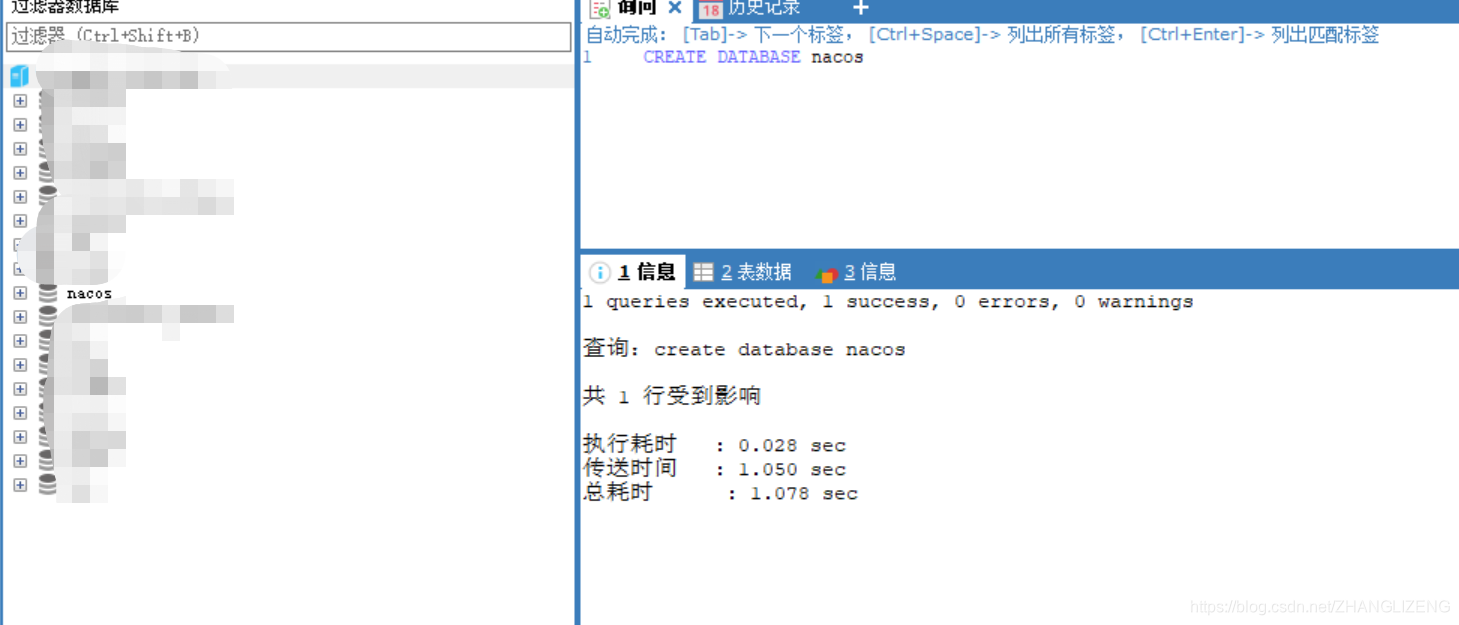
(4)执行nacos初始sql语句,在目录conf/nacos-mysql.sql
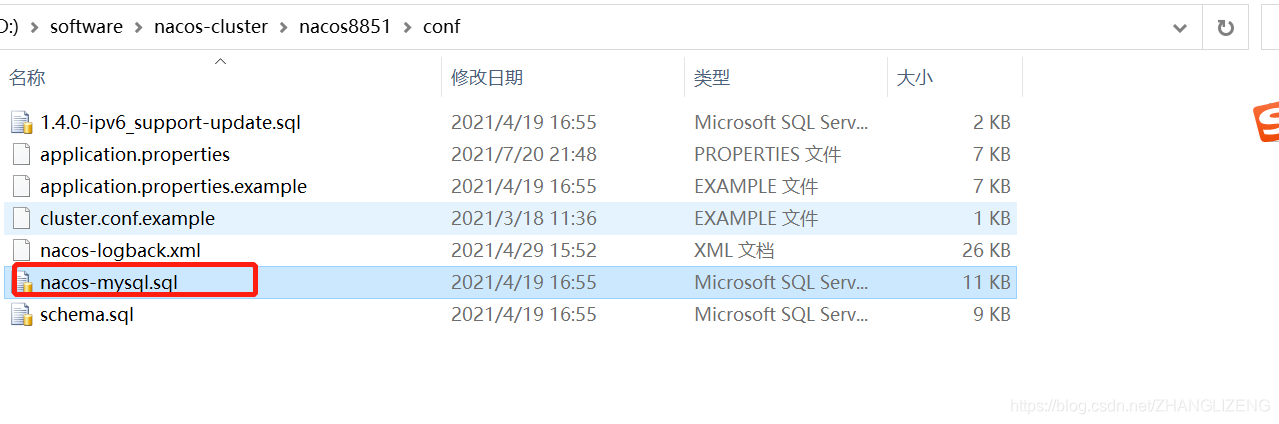
选择刚才建好的nacos数据库,执行SQL语句
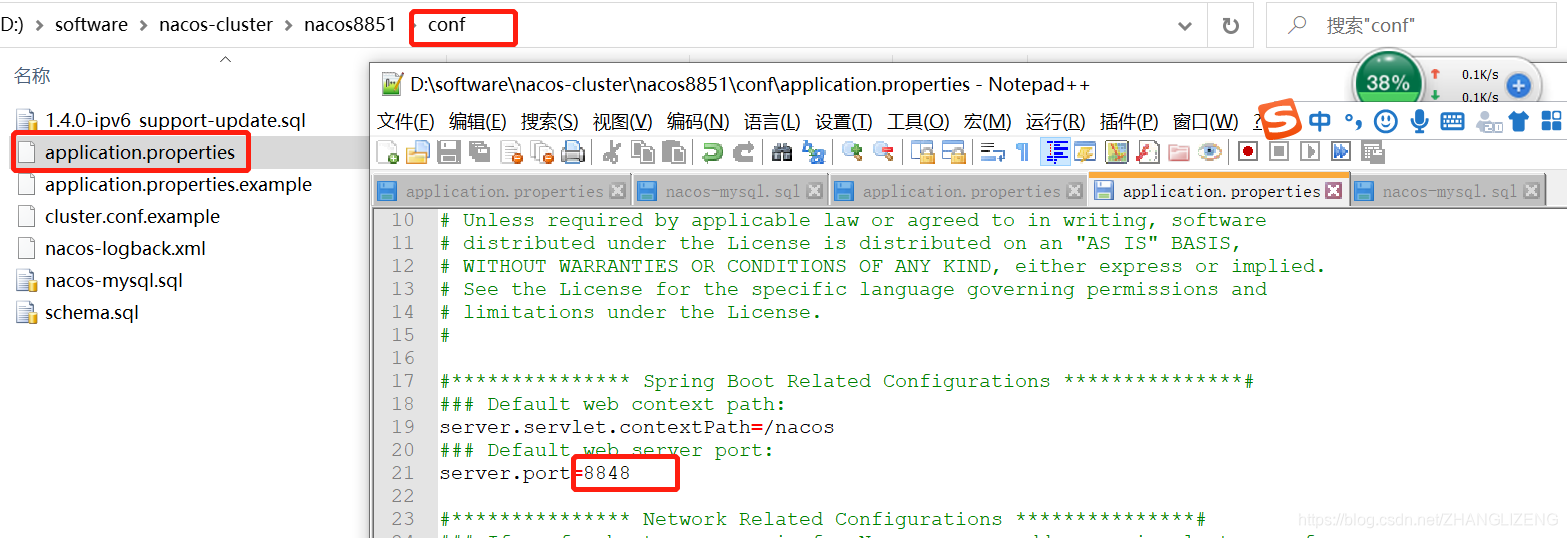
(5)在目录conf/application.properties下,修改三个nacos的端口分别为8849、8850、8851
(6)在目录conf下,把集群实例配置文件cluster.conf.example重命名为cluster.conf,三个文件都需要重命名
(7)把这三台nacos服务器的访问信息(ip+端口)配置到conf/cluster.conf文件中,三个文件都需要配置,配置内容:
- 127.0.0.1:8849
- 127.0.0.1:8850
- 127.0.0.1:8851
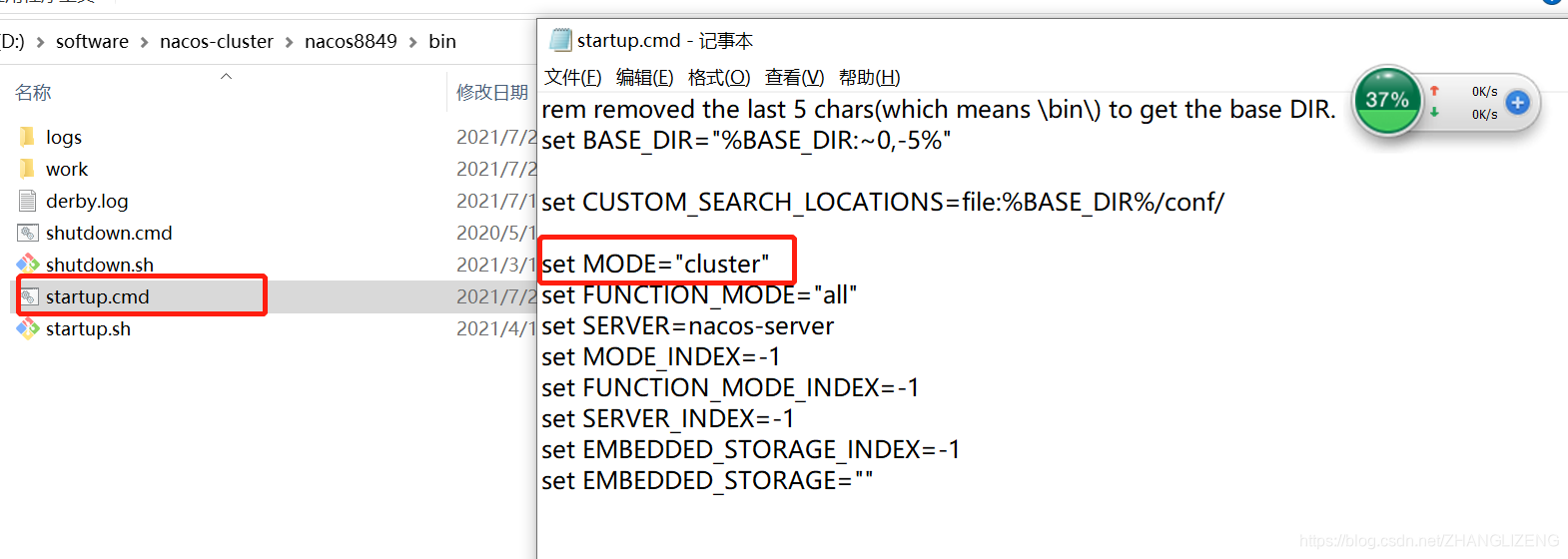
 (8)确保启动的模式为集群方式,在目录bin/startup.cmd中,使用编辑器打开,默认的启动方式为集群cluster。
(8)确保启动的模式为集群方式,在目录bin/startup.cmd中,使用编辑器打开,默认的启动方式为集群cluster。
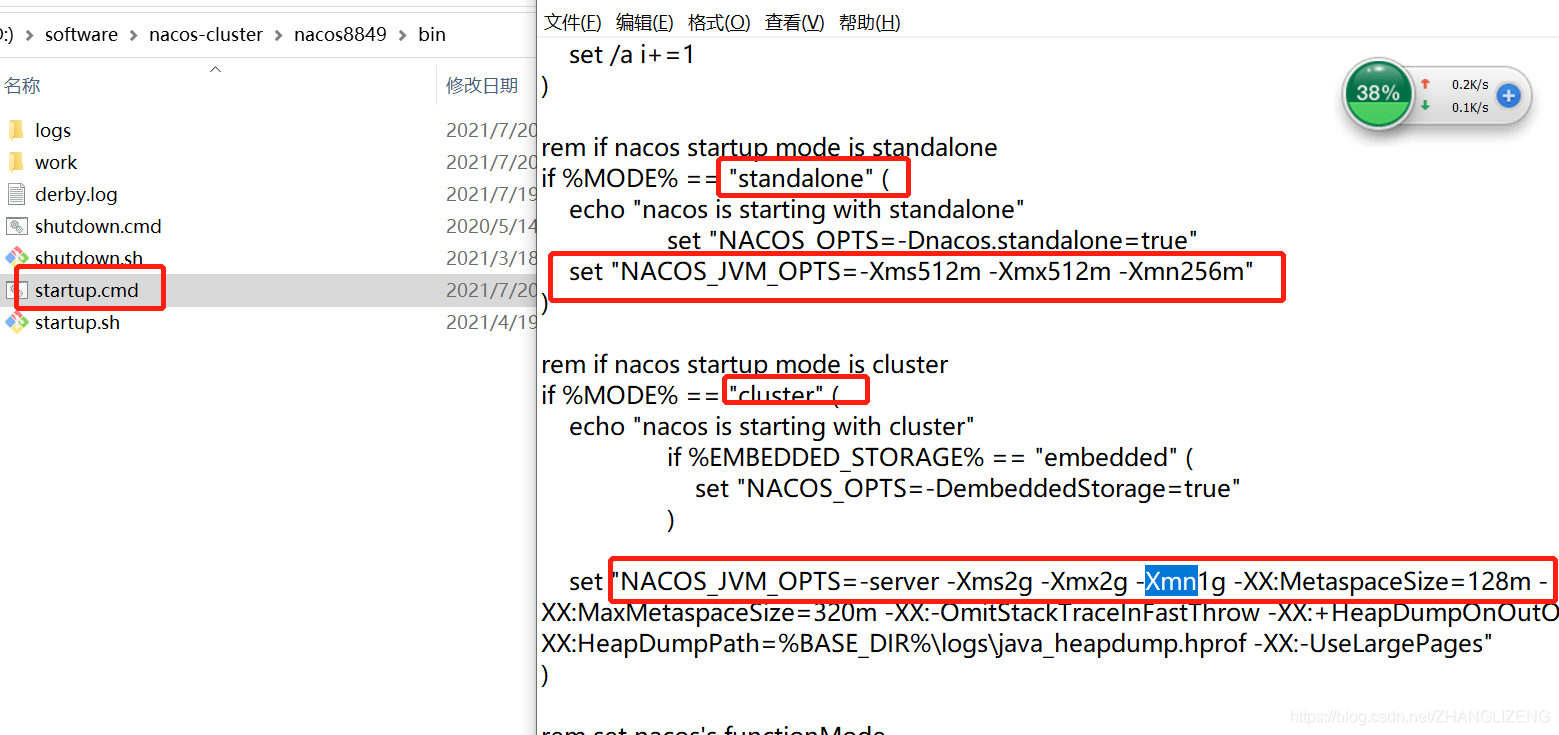
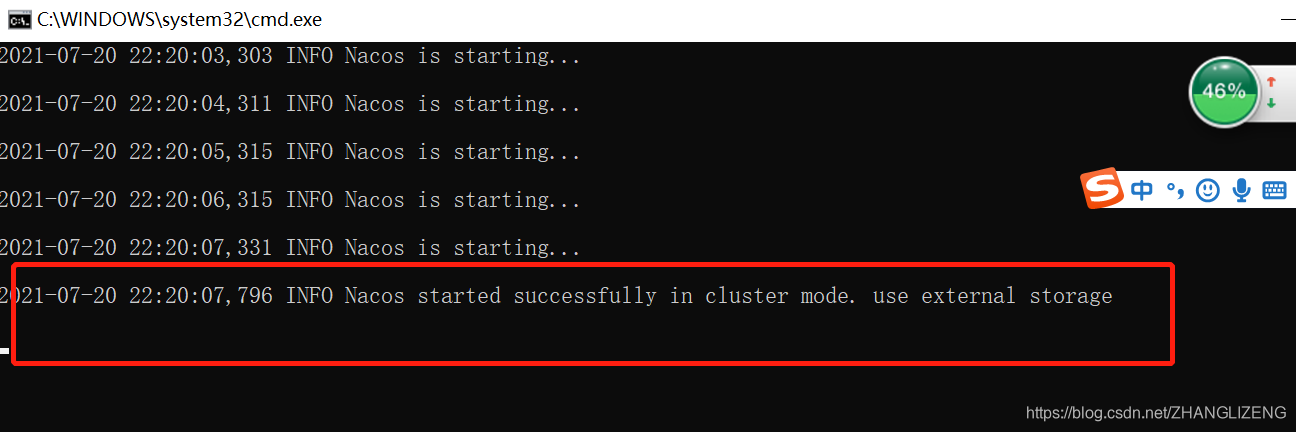
(9)启动时若是出现内存不足的情况,在bin/startup.cmd中修改启动jvm参数,分为单机standalone和集群cluster的启动方式,可以配置初始内存、最大内存、年轻代大小。
(10)双击bin/startup.bat,启动nacos8849服务,控制台输出集群模式cluster启动成功,使用外部数据源
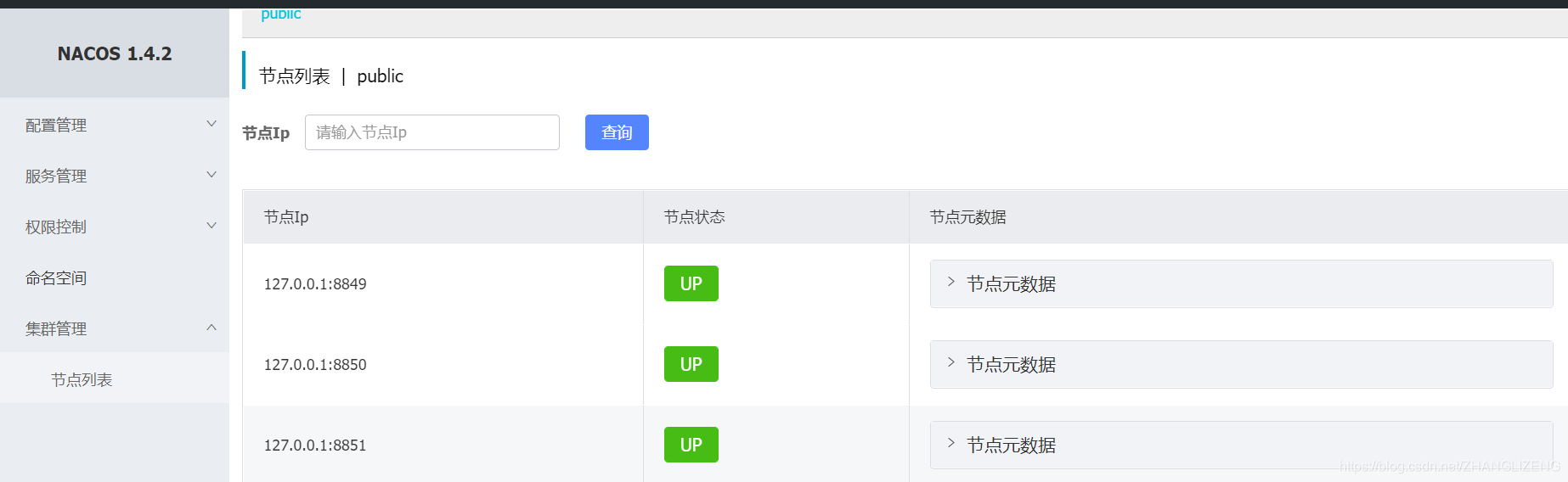
(11)登陆nacos控制台界面,查看集群情况,目前只有8849启动,其它两台服务状态为down

(12)启动8850和8851两台服务器,集群界面都显示上线
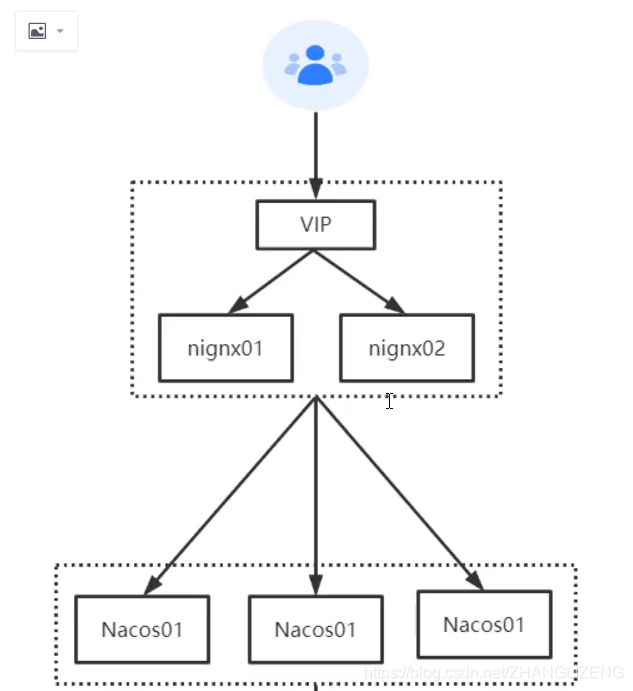
13.Nacos集群架构、nginx代理
(1)集群部署架构图
(2)nginx反向代理
①nginx安装:下载地址:http://nginx.org/en/download.html ,下载后解压
②在conf/nginx.conf配置文件中配置服务启动端口,默认是80
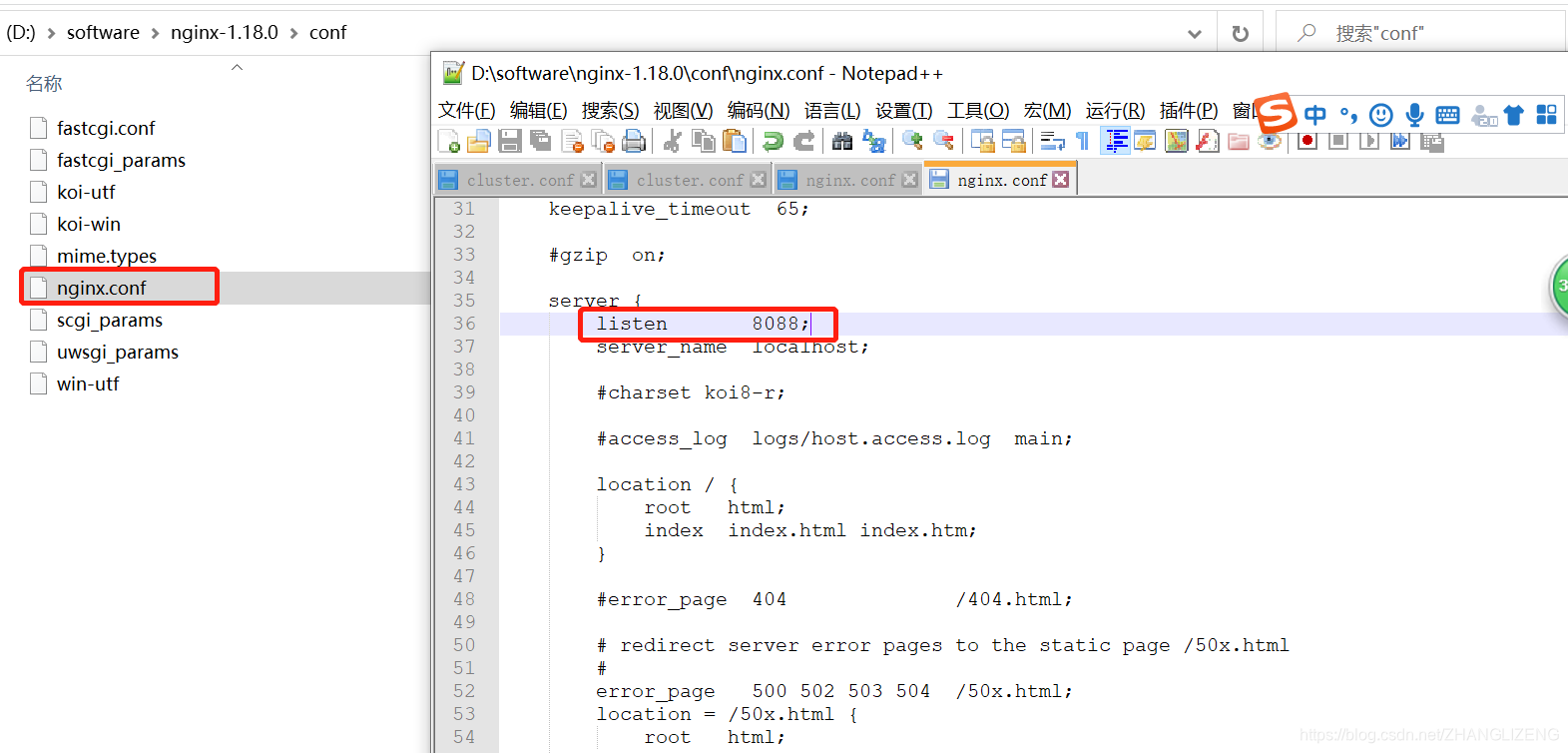
③启动nginx服务,方式有:
--直接双击nginx.exe,双击后一个黑色的弹窗一闪而过
--打开cmd命令窗口,切换到nginx解压目录下,输入命令 nginx.exe 或者 start nginx ,回车即可
④启动之后,输入地址和配置的端口访问nginx,看到此界面说明启动成功
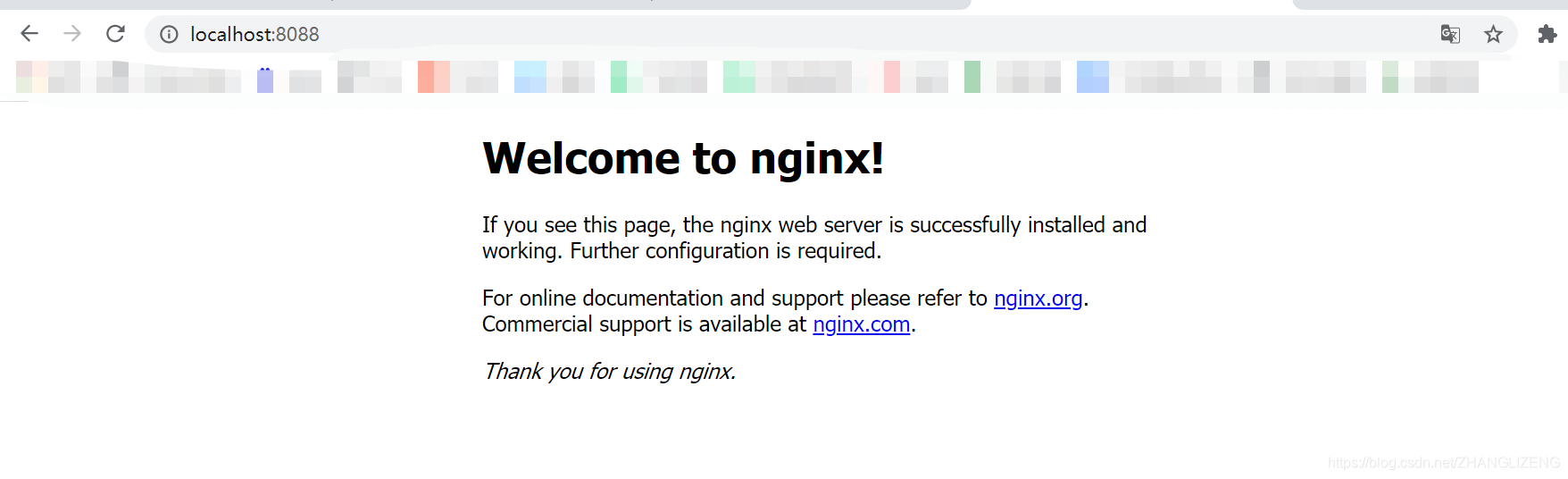
⑤关闭nginx
如果使用cmd命令窗口启动nginx,关闭cmd窗口是不能结束nginx进程的,可使用两种方法关闭nginx
--输入nginx命令 nginx -s stop(快速停止nginx) 或 nginx -s quit(完整有序的停止nginx)
--使用taskkill taskkill /f /t /im nginx.exe
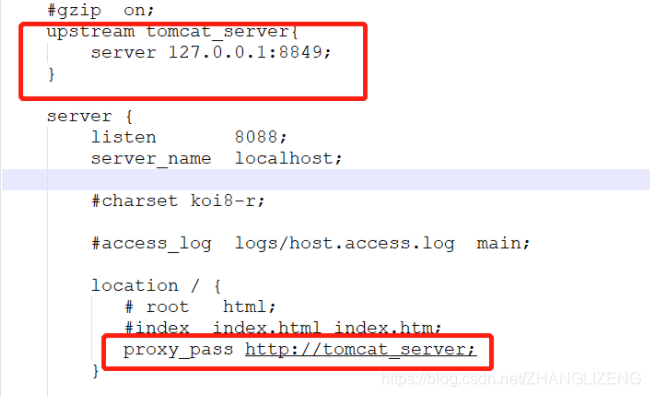
⑥使用nginx代理服务器做负载均衡
我们可以修改nginx的配置文件nginx.conf 达到访问nginx代理服务器时跳转到指定服务器的目的,即通过proxy_pass 配置请求转发地址,即当我们依然输入http://localhost:8088 时,请求会跳转到我们配置的服务器
同理,我们可以配置多个目标服务器,当一台服务器出现故障时,nginx能将请求自动转向另一台服务器,例如配置如下:
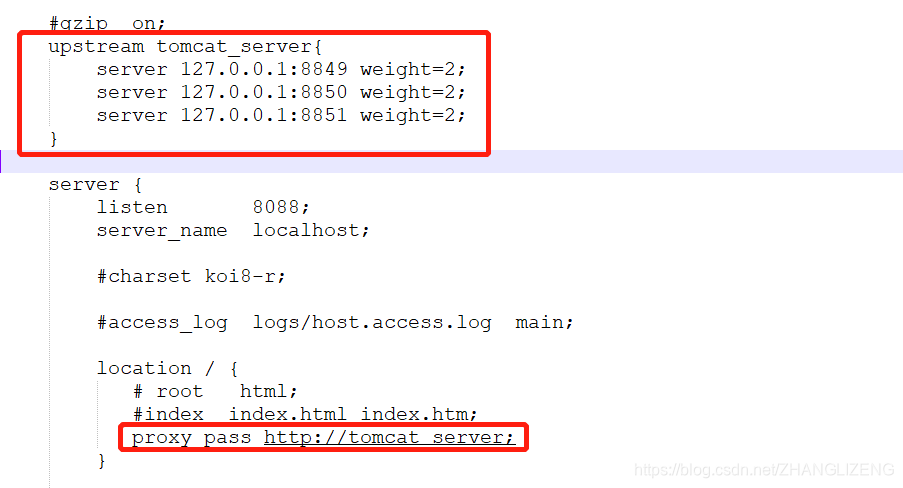
当服务器127.0.0.1:8849 挂掉时,nginx能将请求自动转向服务器 127.0.0.1:8850 。上面还加了一个weight属性,此属性表示各服务器被访问到的权重,weight越高被访问到的几率越高。
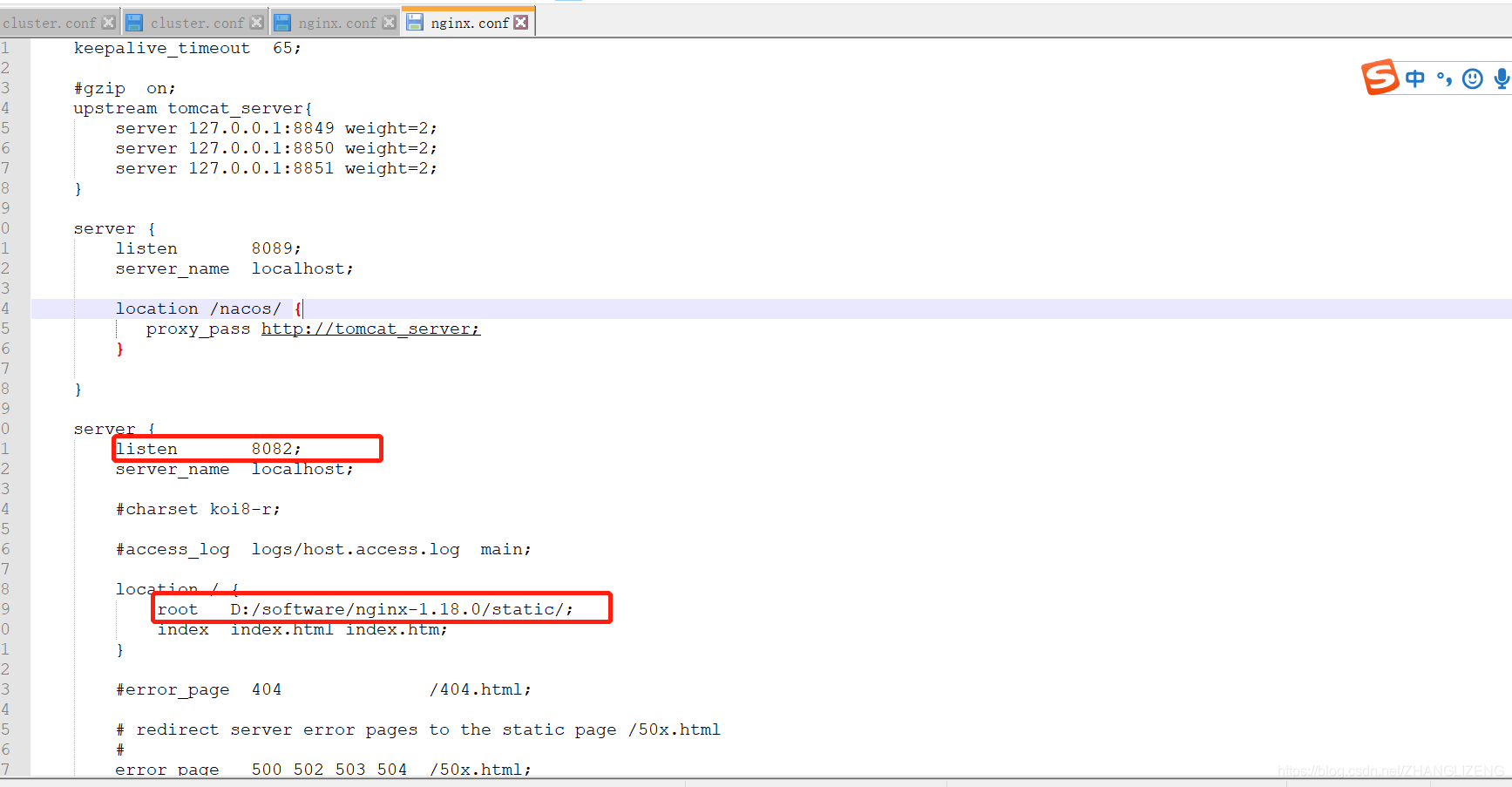
⑦nginx配置静态资源
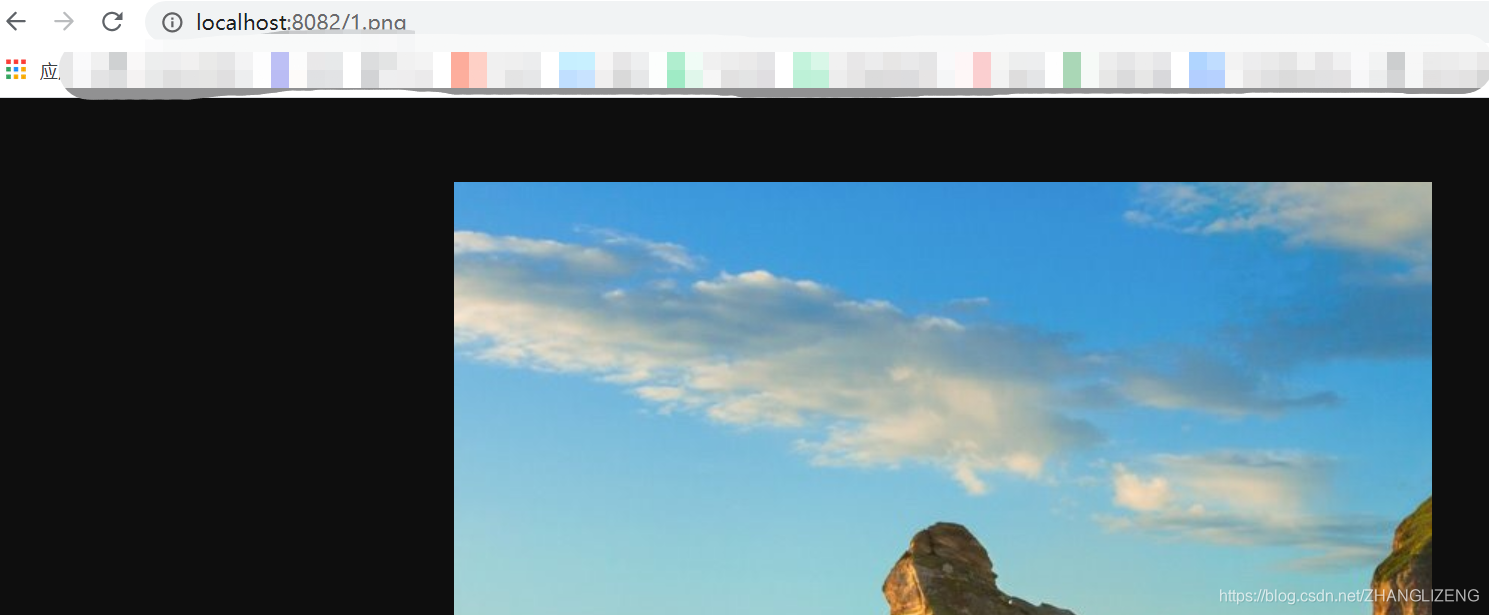
将静态资源(如jpg|png|css|js等)放在如下配置的d:/software/nginx-1.18.0/static目录下,然后在nginx配置文件中做如下配置(注意:静态资源配置只能放在 location / 中),浏览器中访问 http://localhost:8082/1.png 即可访问到 d:/software/nginx-1.18.0/static目录下的 1.png图片
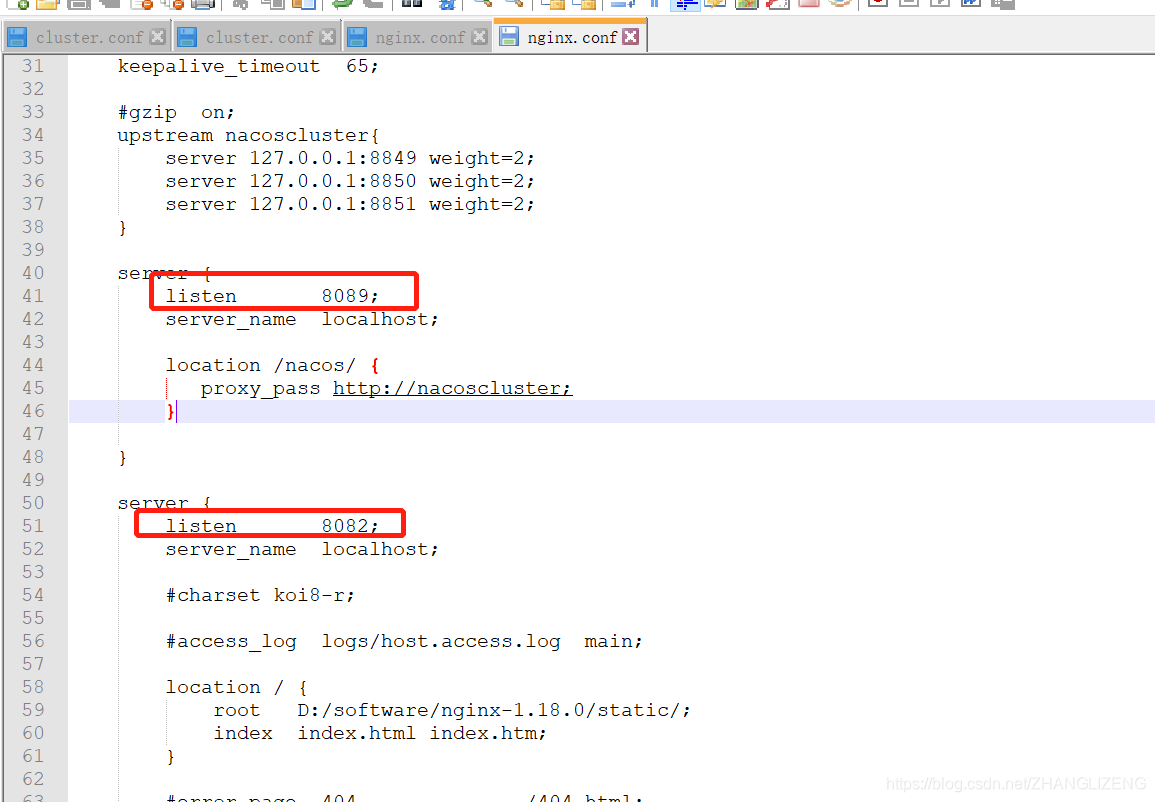
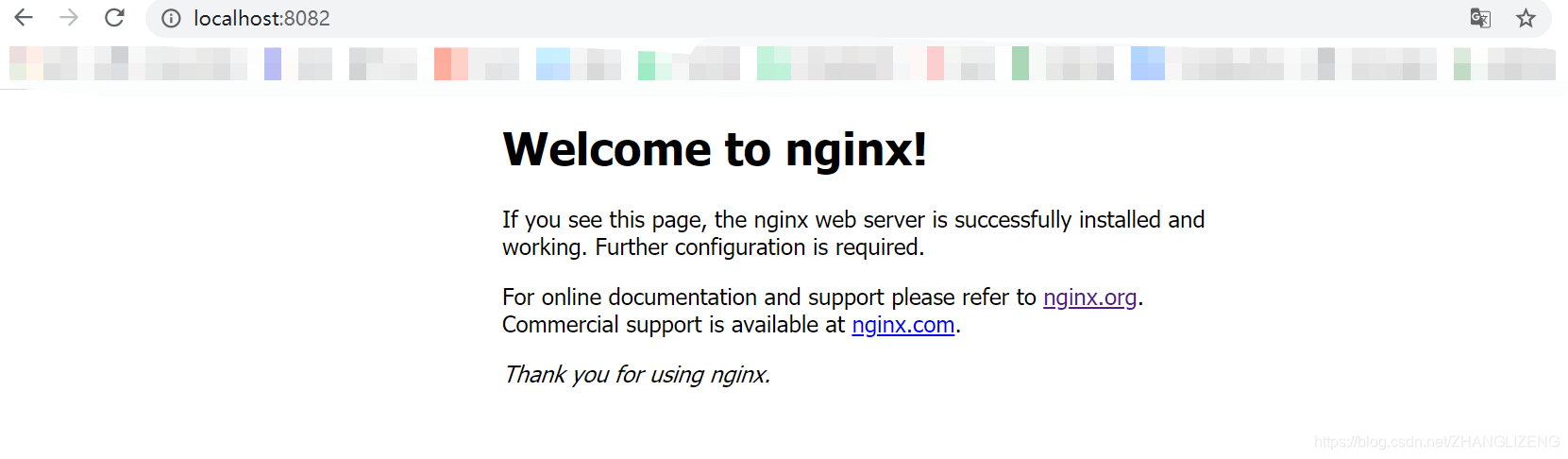
⑧nginx可以配置多个服务端口,ip+端口访问时,nginx默认会去找到nginx的html下面的index.html页面

(3)使用nginx代理分析
在conf/nginx.conf中配置了三台nacos集群的服务
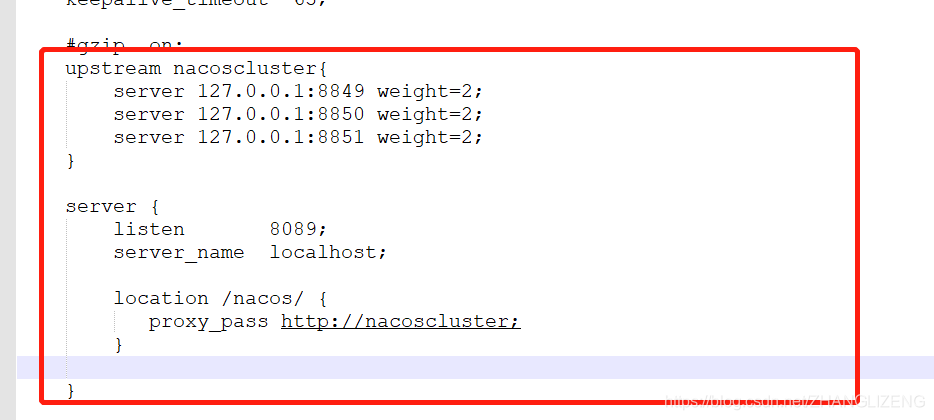
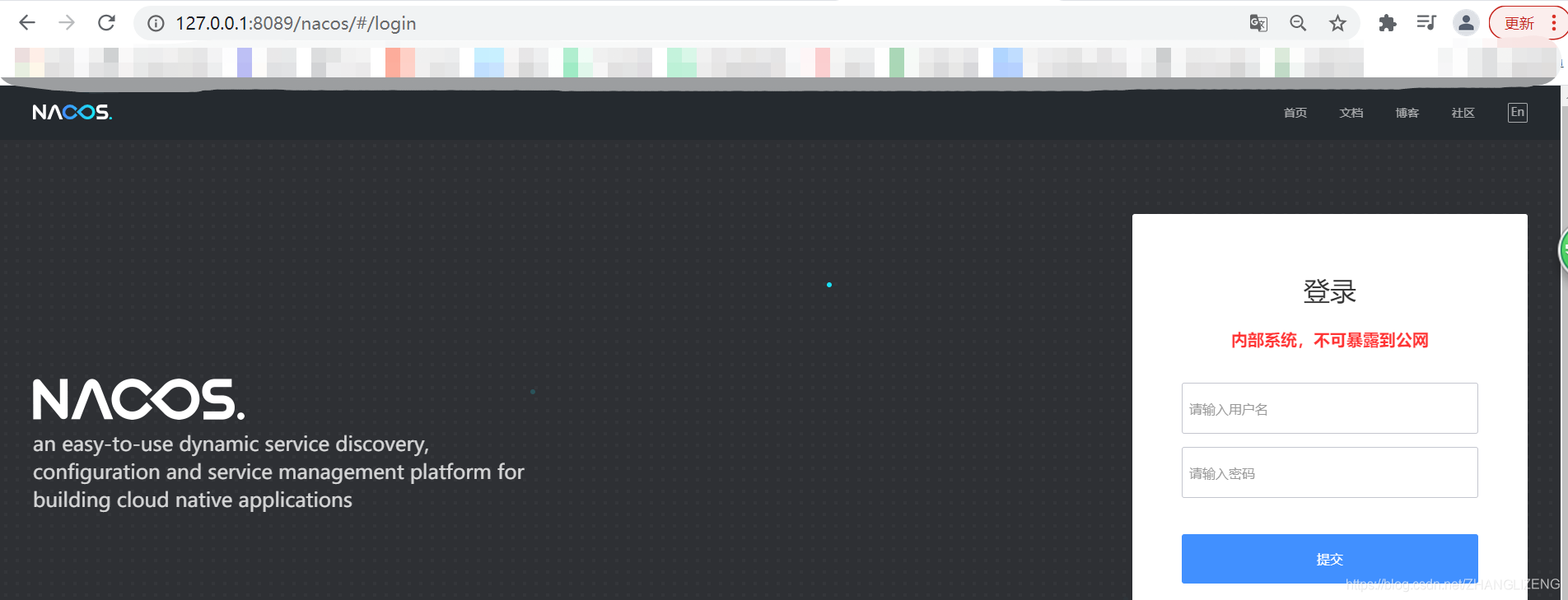
(4)通过nginx代理访问nacos服务,输入nginxip+端口+前缀即可使用代理访问到nacos系统
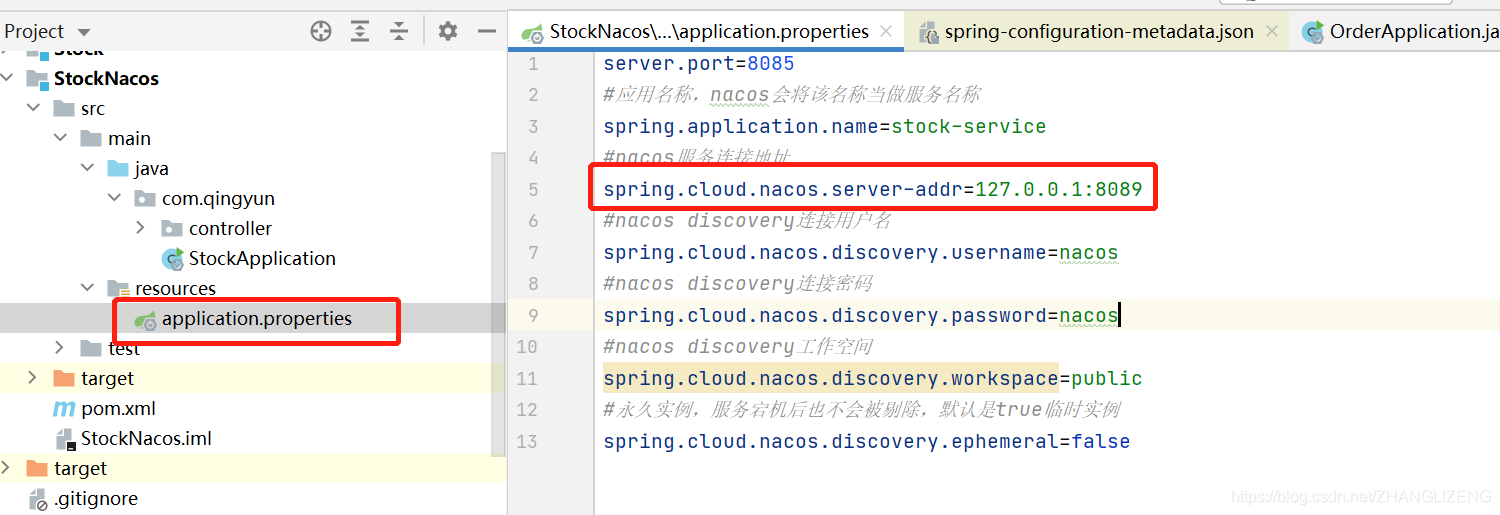
(5)把系统中访问nacos的地址改成nginx代理的地址
(6)启动系统,发现控制台报错com.alibaba.nacos.api.exception.NacosException: failed to req API:/nacos/v1/ns/instance after all servers

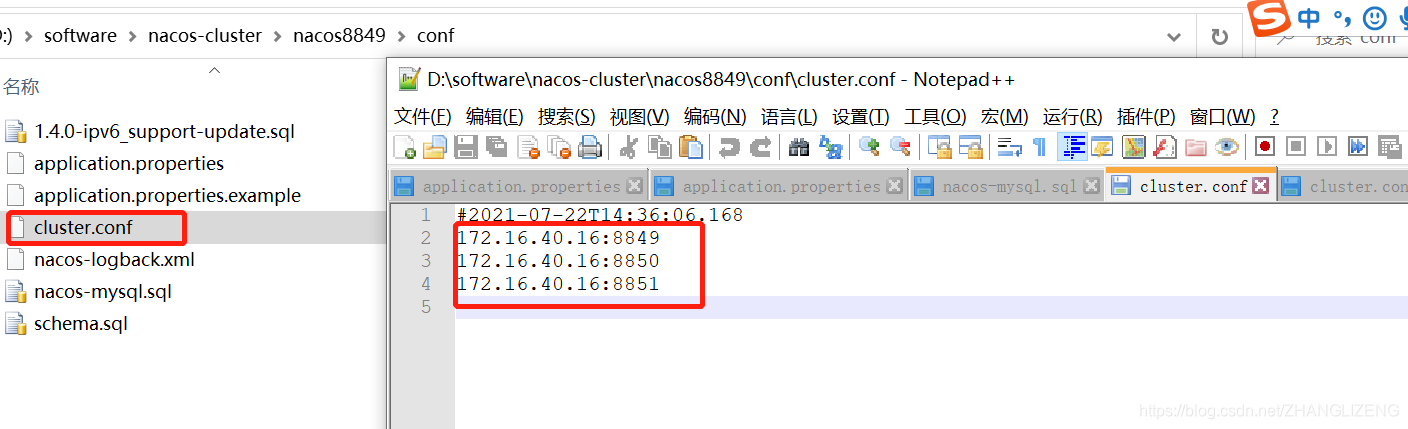
(7)解决启动连接不到nginx代理的nacos服务器:我们配置的所有ip都不能使用127.0.0.1来代替本地,需要使用真实ip地址,否则ngin路由不到地址;涉及到的配置为nacos的集群文件cluster.conf、nginx的nginx.conf、项目的application.properties,都修改为服务器自己的ip地址。
三个nacos集群配置cluster.conf修改:
nginx的nginx.conf:
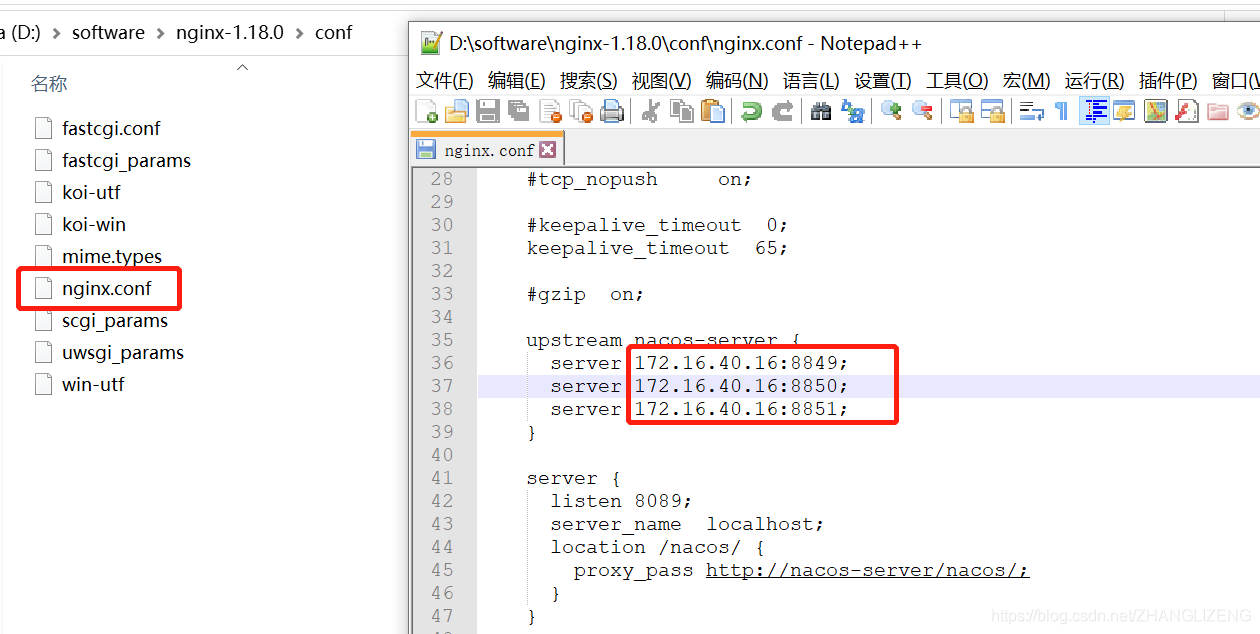
项目的application.properties:
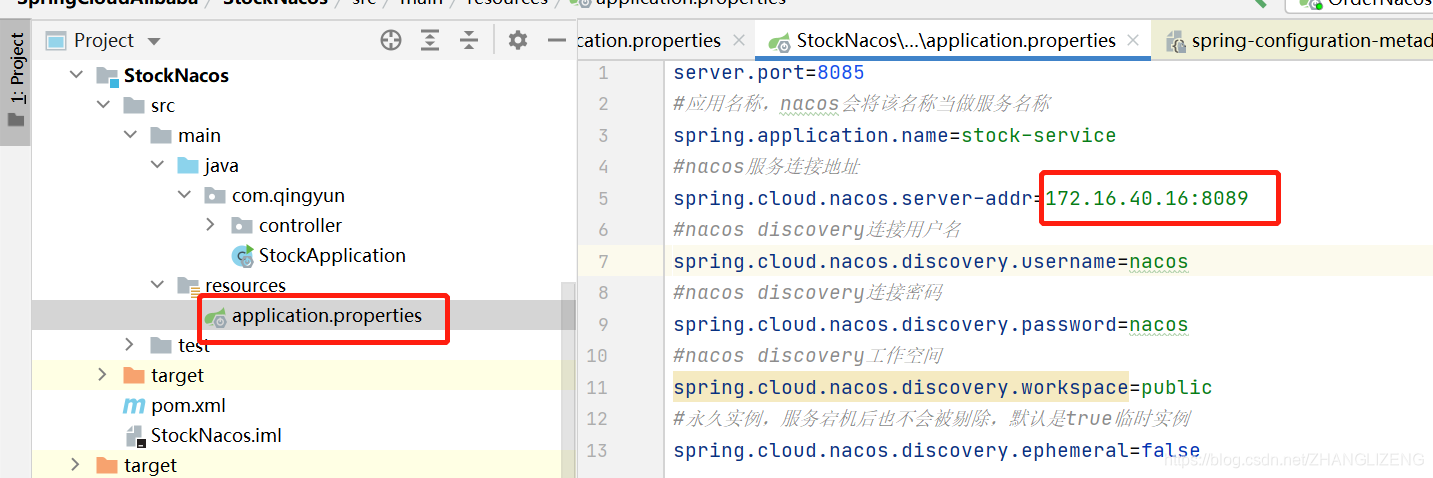
(8)启动服务,访问系统,验证是否通过nginx代理成功
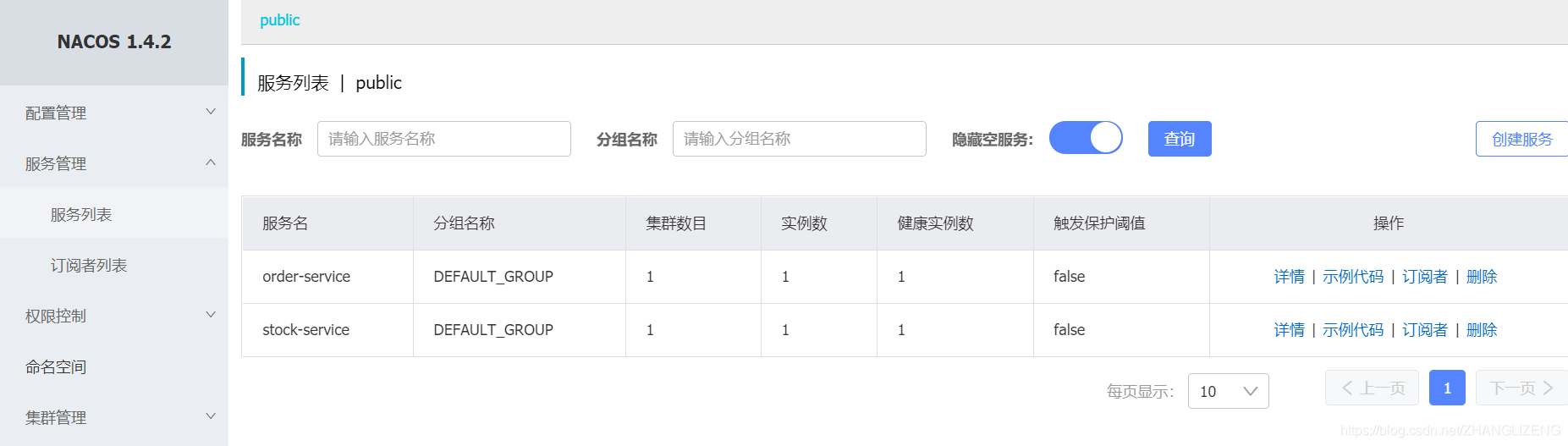
访问服务正常,nginx代理服务正常
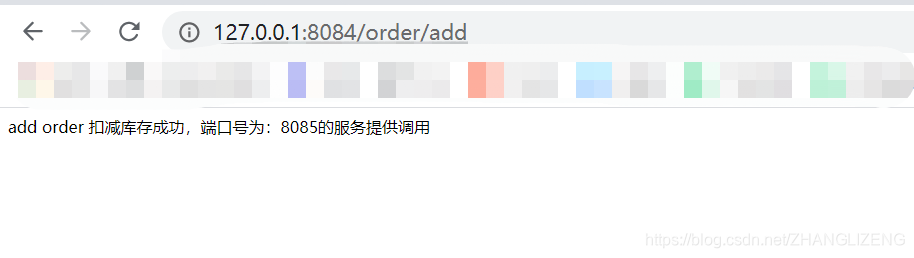
14.CAP理论
- 一致性(Consistency) (所有节点在同一时间具有相同的数据)
- 可用性(Availability) (保证每个请求不管成功或者失败都有响应)
- 分隔容忍--分区容错性(Partition tolerance) (系统中任意信息的丢失或失败不会影响系统的继续运作)
nacos支持CP+AP,zookeeper支持CP。
CAP是在分布式环境下出现的问题,P是一定要保证的,分布式环境下不管是否有节点异常,都要对外提供服务;一致性就是说node1和node2,不管访问哪个节点都要能拿到最新的数据;可用性就是说不管访问node1还是node2都要能够拿到数据。例如当调用node1更新数据,此时node1和node2之间网络有故障,没法把变更后的数据同步到node2,此时新的线程来访问node2获取数据,若是要保证一致性,那就让请求一直等待,等到node1和node2的网络通畅数据同步过来后再响应,这样可能就会导致超时;若要保证可用性,直接把node2中存放的原数据返回,就会导致从node2获取到的不是最新的数据。


