
- 1jenkins的自动化打包部署_jenkins打包,发布,部署
- 2瞬间“友尽”的五大整蛊代码,快去安排你的小伙伴吧!_整朋友的代码
- 3秋招斩获所有互联网大厂面经之前端_bbzhui.top
- 4使用Jprofiler分析OOM原因
- 5使用Jan下载AI模型失败_download failedmodelundefined downloadfailed:conne
- 6使用canvas绘制圆环进度条
- 7mux & decoder & selector详解
- 8预处理数据的方法总结(使用sklearn-preprocessing)_preprocessing.normalize text2vec-large-chinese
- 9Layout(View)保存为Bitmap或者保存为String_gdspy-layout viewer如何保存
- 10WPF编程,Live Charts使用说明(4)——主题_wpf livechart 画折线图如何去除网格
【Python入门教程】第72篇 读取CSV文件_python csv.reader
赞
踩
本篇我们介绍如何使用 Python 内置的 csv 模块读取 CSV 文件。
CSV 文件
CSV 代表逗号分隔值(comma-separated values),CSV 文件就是使用逗号分隔数据的文本文件。
一个 CSV 文件包含一行或多行数据,每一行数据代表一个记录。每个记录包含一个或多个数值,使用逗号进行分隔。另外,一个 CSV 文件中的所有数据行都包含相同数量的值。
我们通常使用 CSV 文件存储表格数据,很多软件都支持这种文件格式,例如 Microsoft Excel 和 Google Spreadsheet。
读取 CSV 文件
在 Python 代码中读取 CSV 文件的步骤如下:
首先,导入 csv 模块:
import csv
- 1
其次,使用内置的 open() 函数以读取模式打开文件:
f = open('path/to/csv_file')
- 1
如果 CSV 文件中包含 UTF8 编码字符,可以指定 encoding 参数:
f = open('path/to/csv_file', encoding='UTF8')
- 1
然后,将文件对象 f 传递给 csv 模块的 reader() 函数,该函数返回一个 csv reader 对象:
csv_reader = csv.reader(f)
- 1
csv_reader 是一个可遍历对象,由 CSV 文件中的数据行组成。因此,我们可以使用 for 循环遍历 CSV 文件中的数据行:
for line in csv_reader:
print(line)
- 1
- 2
每一行都是一个列表,如果想要访问具体的数据,可以使用方括号([])指定数据的下标。第一个数值的下标为 0,第二个数值的下标为 1,依次类推。
例如,以下代码表示访问一行数据中的第一个值:
line[0]
- 1
最后,调用 close() 方法关闭文件:
f.close()
- 1
或者也可以使用 with 语句自动关闭文件。以下是读取 CSV 文件的完整代码:
import csv
with open('path/to/csv_file', 'r') as f:
csv_reader = csv.reader(f)
for line in csv_reader:
# process each line
print(line)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
示例
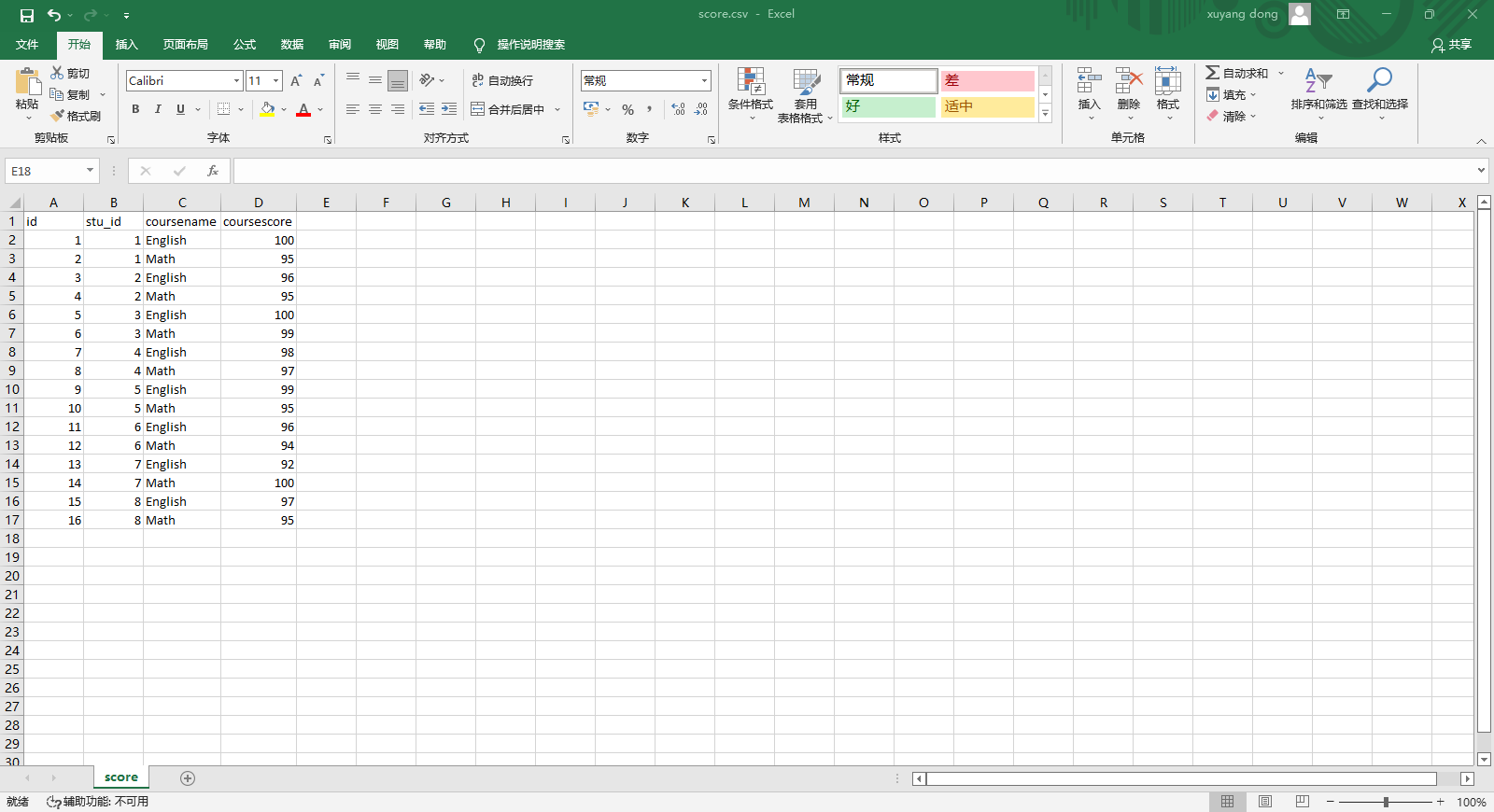
示例文件 score.csv 的内容如下:
id,stu_id,coursename,coursescore 1,1,English,100 2,1,Math,95 3,2,English,96 4,2,Math,95 5,3,English,100 6,3,Math,99 7,4,English,98 8,4,Math,97 9,5,English,99 10,5,Math,95 11,6,English,96 12,6,Math,94 13,7,English,92 14,7,Math,100 15,8,English,97 16,8,Math,95

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
下面的示例读取了该文件并打印文件中的内容:
import csv
with open('score.csv', encoding="utf8") as f:
csv_reader = csv.reader(f)
for line in csv_reader:
print(line)
- 1
- 2
- 3
- 4
- 5
- 6
输出结果如下:
['id', 'stu_id', 'coursename', 'coursescore']
['1', '1', 'English', '100']
['2', '1', 'Math', '95']
['3', '2', 'English', '96']
['4', '2', 'Math', '95']
['5', '3', 'English', '100']
...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
score.csv 文件中的第一行是标题。为了区分标题和数据,我们可以使用 enumerate() 函数获取每一行的下标:
import csv
with open('score.csv', encoding="utf8") as f:
csv_reader = csv.reader(f)
for line_no, line in enumerate(csv_reader, 1):
if line_no == 1:
print('Header:')
print(line) # header
print('Data:')
else:
print(line) # data
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
以上示例中,我们使用了 enumerate() 函数并且将第一行的下标设置为 1。在循环内部,如果 line_no 为 1,表示当前行为标题;否则,当前行是数据。代码输出的结果如下:
Header:
['id', 'stu_id', 'coursename', 'coursescore']
Data:
['1', '1', 'English', '100']
['2', '1', 'Math', '95']
['3', '2', 'English', '96']
['4', '2', 'Math', '95']
['5', '3', 'English', '100']
...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
跳过标题行的另一个方法就是使用 next() 函数,该函数表示读取到下一行。例如:
import csv
with open('score.csv', encoding="utf8") as f:
csv_reader = csv.reader(f)
# skip the first row
next(csv_reader)
# show the data
for line in csv_reader:
print(line)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
以下示例读取 score.csv 文件并计算所有成绩的总和:
import csv
total_score = 0
with open('score.csv', encoding="utf8") as f:
csv_reader = csv.reader(f)
# skip the header
next(csv_reader)
# calculate total
for line in csv_reader:
total_score += int(line[3])
print(total_score)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
输出结果如下:
1548
- 1
DictReader 类
当我们使用 csv.reader() 函数是,可以利用下标访问 CSV 文件中的数据,例如 line[0]、line[1] 等等。不过,使用该函数有两个主要的局限性:
- 首先,访问数据的方式不明显。例如,line[3] 代表了成绩。如果我们能够使用 line[‘coursescore’] 访问数据,显然含义更加清晰。
- 其次,当 CSV 文件中的字段顺序发生了改变,或者增加了新的字段,我们需要修改代码。
DictReader 类可以解决这些问题,而且它也来自 csv 模块。
DictReader 类可以创建一个类似普通 CSV reader 的对象,但是它将每行数据的信息映射成了一个字典(dict),key 的值由第一行数据指定。
通过使用 DictReader 类,我们可以使用 line[‘stu_id’]、line[‘coursename’] 等方式访问 score.csv 文件中的数据,例如:
import csv
with open('score.csv', encoding="utf8") as f:
csv_reader = csv.DictReader(f)
# show the data
for line in csv_reader:
print(f"The {line['coursename']} score of {line['stu_id']} is {line['coursescore']}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
输出结果如下:
The English score of 1 is 100
The Math score of 1 is 95
The English score of 2 is 96
The Math score of 2 is 95
...
- 1
- 2
- 3
- 4
- 5
如果我们想要使用自定义的字段名,而不是 CSV 文件中第一行指定的字段名,可以在 DictReader() 构造函数中指定:
import csv
fieldnames = ['id', '学生编号', '课程', '成绩']
with open('score.csv', encoding="utf8") as f:
csv_reader = csv.DictReader(f, fieldnames)
next(csv_reader)
for line in csv_reader:
print(f"The {line['课程']} score of {line['学生编号']} is {line['成绩']}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
总结
- csv.reader() 函数和 csv.DictReader 类都可以用于读取 CSV 文件。

