
- 1内网穿透,解决vue项目中的“Invalid Host header”_invalid host header uniapp frpn内网穿透
- 2自己动手开发一个 Web 服务器(一)_在线开发1服务器
- 3Windows 系统中 hosts 文件无法修改的问题_host不能修改
- 4MFC中文件读写操作_mfc中读取文件数据时如何去掉回车和换行再把数据保存到变量中
- 5查看局域网某个IP地址是否可以连接?或确定某个(互联网)网址是否能访问?使用DOS的"ping"命令_如何测试内网中的一个ip地址能否访问互联网
- 62023年前端技术盘点与2024年技术展望
- 7vscode远程连接不上:Cannot find module minimist_cannot find module 'minimist
- 8New Online Judge 1008_public class main { public static void main(string
- 9Git 切换分支并下载代码_git乌龟 切换分支下载
- 10常用的电脑显示器接口有哪几种?_电脑高清头接口
飞桨模型保存_性能领先,即训即用,快速部署,飞桨首次揭秘服务器端推理库...
赞
踩
允中 发自 凹非寺
量子位 编辑 | 公众号 QbitAI
假如问在深度学习实践中,最难的部分是什么?猜测80%的开发者都会说:
“当然是调参啊。”
为什么难呢?因为调参就像厨师根据食材找到了料理配方,药剂师根据药材找到了药方,充满了玄幻色彩。
但是,掌握了调参,顶多算深度学习的绝学掌握了一半。而另一半就是“模型部署”。
模型部署有什么难的?举个例子:前面这位大厨在培训学校,经过各种训练掌握了很多料理配方,终于要到酒店上任了,却发现酒店的厨房环境和训练时不一样,就餐高峰时手忙脚乱,客户等了1个小时还没上菜,结果第一天上岗就被投诉了。
虽然比喻略有夸张,却也道出了深度学习模型训练和推理部署的关系。
我们知道,深度学习一般分为训练和推理两个部分,训练是神经网络“学习”的过程,主要关注如何搜索和求解模型参数,发现训练数据中的规律。
有了训练好的模型之后,就要在线上环境中应用模型,实现对未知数据做出预测,这个过程在AI领域叫做推理。
在实际应用中,推理阶段可能会面临和训练时完全不一样的硬件环境,当然也对应着不一样的计算性能要求。我们训练得到的模型,需要能在具体生产环境中正确、高效地实现推理功能,完成上线部署。
所以,当我们千辛万苦训练好模型,终于要上线了,但这个时候可能会遇到各种问题,比如:
- 线上部署的硬件环境和训练时不同
- 推理计算耗时太高, 可能造成服务不可用
- 模型上的内存占用过高无法上线
对工业级部署而言,要求的条件往往非常繁多而且苛刻,不是每个深度学习框架都对实际生产部署上能有良好的支持。一款对推理支持完善的的框架,会让你的模型上线工作事半功倍。
飞桨作为源于产业实践的深度学习框架,在推理部署能力上有特别深厚的积累和打磨,提供了性能强劲、上手简单的服务器端推理库Paddle Inference,帮助用户摆脱各种上线部署的烦恼。

Paddle Inference是什么
飞桨框架的推理部署能力经过多个版本的升级迭代,形成了完善的推理库Paddle Inference。Paddle Inference功能特性丰富,性能优异,针对不同平台不同的应用场景进行了深度的适配优化,做到高吞吐、低时延,保证了飞桨模型在服务器端即训即用,快速部署。
Paddle Inference的高性能实现
内存/显存复用提升服务吞吐量
在推理初始化阶段,对模型中的OP输出Tensor 进行依赖分析,将两两互不依赖的Tensor在内存/显存空间上进行复用,进而增大计算并行量,提升服务吞吐量。
细粒度OP横向纵向融合减少计算量
在推理初始化阶段,按照已有的融合模式将模型中的多个OP融合成一个OP,减少了模型的计算量的同时,也减少了 Kernel Launch的次数,从而能提升推理性能。目前Paddle Inference支持的融合模式多达几十个。
内置高性能的CPU/GPU Kernel
内置同Intel、Nvidia共同打造的高性能kernel,保证了模型推理高性能的执行。
子图集成TensorRT加快GPU推理速度
Paddle Inference采用子图的形式集成TensorRT,针对GPU推理场景,TensorRT可对一些子图进行优化,包括OP的横向和纵向融合,过滤冗余的OP,并为OP自动选择最优的kernel,加快推理速度。
子图集成Paddle Lite轻量化推理引擎
Paddle Lite 是飞桨深度学习框架的一款轻量级、低框架开销的推理引擎,除了在移动端应用外,还可以使用服务器进行 Paddle Lite 推理。Paddle Inference采用子图的形式集成 Paddle Lite,以方便用户在服务器推理原有方式上稍加改动,即可开启 Paddle Lite 的推理能力,得到更快的推理速度。并且,使用 Paddle Lite 可支持在百度昆仑等高性能AI芯片上执行推理计算。
支持加载PaddleSlim量化压缩后的模型
PaddleSlim是飞桨深度学习模型压缩工具,Paddle Inference可联动PaddleSlim,支持加载量化、裁剪和蒸馏后的模型并部署,由此减小模型存储空间、减少计算占用内存、加快模型推理速度。其中在模型量化方面,Paddle Inference在X86 CPU上做了深度优化,常见分类模型的单线程性能可提升近3倍,ERNIE模型的单线程性能可提升2.68倍。
【性能测一测】通过比较resnet50和bert模型的训练前向耗时和推理耗时,可以观测到Paddle Inference有显著的加速效果。
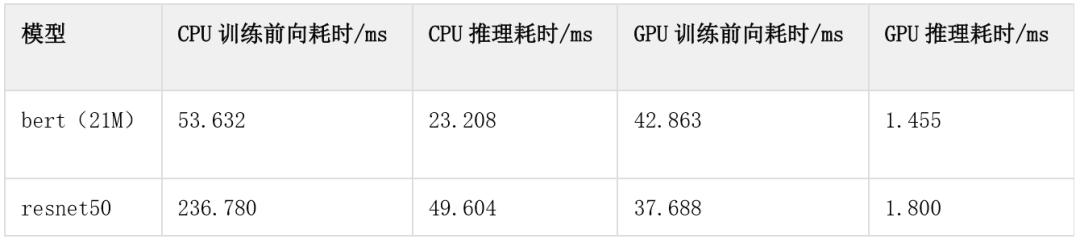
说明:测试耗时的方法,使用相同的输入数据先空跑1000次,循环运行1000次,每次记录模型运行的耗时,最后计算出模型运行的平均耗时。
Paddle Inference的通用性
主流软硬件环境兼容适配
支持服务器端X86 CPU、NVIDIA GPU芯片,兼容Linux/Mac/Windows系统。支持所有飞桨训练产出的模型,完全做到即训即用。
多语言环境丰富接口可灵活调用
支持C++, Python, C, Go和R语言API, 接口简单灵活,20行代码即可完成部署。对于其他语言,提供了ABI稳定的C API, 用户可以很方便地扩展。
Paddle Inference怎么用
下面我们一起来看看如何使用飞桨完成服务器端推理部署。
“一个函数”搞定模型保存
飞桨框架提供了一个内置函数 save_inference_model, 将模型保存为推理用的模型格式。save_inference_model可以根据推理需要的输入和输出, 对训练模型进行剪枝, 去除和推理无关部分, 得到的模型相比训练时更加精简, 适合进一步优化和部署。
from paddle import fluidplace = fluid.CPUPlace()executor = fluid.Executor(place)image = fluid.data(name="image", shape=[None, 28, 28], dtype="float32")label = fluid.data(name="label", shape=[None, 1], dtype="int64")feeder = fluid.DataFeeder(feed_list=[image, label], place=place)predict = fluid.layers.fc(input=image, size=10, act='softmax')loss = fluid.layers.cross_entropy(input=predict, label=label)avg_loss = fluid.layers.mean(loss)executor.run(fluid.default_startup_program())# 保存模型到model目录中, 只保存与输入image和输出与推理相关的部分网络fluid.io.save_inference_model("model", feed_var_names=["image"], target_vars=[predict]. executor=executor)“一个配置管理器”搞定部署设置
保存推理模型之后, 就可以使用推理库了, Paddle Inference提供了 AnalysisConfig 用于管理推理部署的各种设置,比如设置在CPU还是GPU部署、加载模型路径、开启/关闭计算图分析优化、使用MKLDNN/TensorRT进行部署的加速等,用户可以根据自己的上线环境, 打开所需优化配置。同时,可配置采用zero copy的方式管理输入和输出, 推理执行时可跳过feed op和fetch op,减少多余的数据拷贝,提高推理性能。
from paddle.fluid.core import AnalysisConfig# 创建配置对象config = AnalysisConfig("./model")# 配置采用zero copy的方式config.switch_use_feed_fetch_ops(False)config.switch_specify_input_names(True)“一个预测器”搞定高性能推理
定义好部署的配置后,就可以创建预测器了。Paddle Inference提供了多项图优化的方式,创建预测器时将会加载推理模型并自动进行图优化,以增强推理性能。
# 创建预测器from paddle.fluid.core import create_paddle_predictorpredictor = create_paddle_predictor(config)创建好预测器之后,只需要传入数据就可以运行推理计算预测结果了。这里假设我们已经将输入数据读入了一个numpy.ndarray数组中,飞桨提供了简单易用的API来管理输入和输出。
# 获取并传入数据input_names = predictor.get_input_names()input_tensor = predictor.get_input_tensor(input_names[0])input_tensor.copy_from_cpu(input_data.reshape([1, 28, 28]).astype("float32"))# 运行预测器, 这里将会执行真正的预测predictor.zero_copy_run()# 输出预测结果ouput_names = predictor.get_output_names()output_tensor = predictor.get_output_tensor(output_names[0])output_data = output_tensor.copy_to_cpu()接下来以一个完整的Python API的实例,来实践一下使用飞桨部署模型的全流程。我们以在P4 GPU服务器上部署resnet模型为例。
- (1)安装PaddlePaddle。
可以参考官网下载并安装PaddlePaddle。
- (2)获取模型。
wget http://paddle-inference-dist.bj.bcebos.com/resnet50_model.tar.gz && tar -xzf resnet50_model.tar.gz- (3)准备模型部署代码,并将代码保存到infer_resnet.py文件中。
import argparseimport argparseimport numpy as npfrom paddle.fluid.core import AnalysisConfigfrom paddle.fluid.core import create_paddle_predictordef main(): args = parse_args() # 设置AnalysisConfig config = set_config(args) # 创建PaddlePredictor predictor = create_paddle_predictor(config) # 获取输入的名称 input_names = predictor.get_input_names() input_tensor = predictor.get_input_tensor(input_names[0]) # 设置输入 fake_input = np.random.randn(args.batch_size, 3, 318, 318).astype("float32") input_tensor.reshape([args.batch_size, 3, 318, 318]) input_tensor.copy_from_cpu(fake_input) # 运行predictor predictor.zero_copy_run() # 获取输出 output_names = predictor.get_output_names() output_tensor = predictor.get_output_tensor(output_names[0]) output_data = output_tensor.copy_to_cpu() # numpy.ndarray类型 for i in range(args.batch_size): print(np.argmax(output_data[i]))def parse_args(): # 模型路径配置 parser = argparse.ArgumentParser() parser.add_argument("--model_file", type=str, help="model filename") parser.add_argument("--params_file", type=str, help="parameter filename") parser.add_argument("--batch_size", type=int, default=1, help="batch size") return parser.parse_args()def set_config(args): config = AnalysisConfig(args.model_file, args.params_file) config.enable_use_gpu(100, 0) config.switch_use_feed_fetch_ops(False) config.switch_specify_input_names(True) return configif __name__ == "__main__":main()- (4)执行推理任务。
# model为模型存储路径python3 infer_resnet.py --model_file=model/model --params_file=model/params以上就是使用Paddle Inference的Python API进行模型部署的完整流程,可从官网获取代码。如果想了解C++部署,可以参考官网提供的C++示例。
Python示例:https://www.paddlepaddle.org.cn/documentation/docs/zh/advanced_guide/inference_deployment/inference/python_infer_cn.html#id6
C++示例:https://www.paddlepaddle.org.cn/documentation/docs/zh/advanced_guide/inference_deployment/inference/native_infer.html#a-name-c-c-a
Paddle Inference如何进一步优化性能?
到这里已经完成一个基本的推理服务,是否可以交差了?对于精益求精的开发者们来说显然还不够,飞桨还可通过下面这些方法,帮助用户进一步提高推理性能:
启用MKLDNN加速CPU推理
在X86 CPU上, 若硬件支持, 可以打开DNNL (Deep Neural Network Library, 原名MKLDNN) 优化, 这是一个Intel开源的高性能计算库, 用于Intel架构的处理器和图形处理器上的神经网络优化, 飞桨可自动调用,只需要在配置选项中打开即可。
config.enable_mkldnn()切换到GPU推理
若需要使用NVIDIA GPU,只需一行配置,就可自动切换到GPU上。
# 在 GPU 0 上初始化 100 MB 显存。这只是一个初始值,实际显存可能会动态变化。config.enable_use_gpu(100, 0)启动TensorRT加快GPU推理速度
TensorRT是一个高性能的深度学习推理加速库,可为GPU上的深度学习推理应用程序提供低延迟和高吞吐量的优化服务。Paddle Inference采用子图的形式对TensorRT 进行了集成。在已经配置使用 GPU 推理的基础上, 只需要一行配置就可以开启 Paddle TensorRT加速推理:
config.enable_tensorrt_engine(workspace_size=1 <开启Paddle Lite轻量化推理引擎
针对一些计算量较小,实际推理耗时很少的小模型,如果直接使用Paddle Inference,框架耗时可能与模型耗时在同一量级,此时可选用Paddle Lite子图的方式来运行以减少框架耗时。Paddle Inference采用子图的形式集成 Paddle Lite,只需要添加一行配置即可开启 Paddle Lite 的推理加速引擎。
config.enable_lite_engine(precision_mode=AnalysisConfig.Precision.Float32)飞桨在工业部署领域覆盖哪些场景?
工业级部署可能面临多样化的部署环境,针对不同应用场景,飞桨提供了三种推理部署方案:
- Paddle Inference作为飞桨深度学习框架原生的高性能推理库,可应用于本地服务器端部署场景,做到即训即用。
- 针对服务化部署场景,飞桨提供Paddle Serving部署方案。该场景将推理模块作为远程调用服务,客户端发出请求,服务端返回推理结果。是云端部署必不可少的方案。
- 针对移动端、嵌入式芯片等端侧硬件部署的场景,飞桨提供Paddle Lite部署方案,满足高性能、轻量化的部署需求。
更多介绍可访问如下飞桨项目地址,一起探索飞桨强大的工业部署实践能力。
相关资料
飞桨Paddle Inference项目地址:https://github.com/PaddlePaddle/Paddle/tree/develop/paddle/fluid/inference
飞桨Paddle Lite项目地址:https://github.com/PaddlePaddle/Paddle-Lite
飞桨Paddle Serving项目地址:https://github.com/PaddlePaddle/Serving
飞桨PaddleSlim项目地址:https://github.com/PaddlePaddle/PaddleSlim
如果您加入官方QQ群,您将遇上大批志同道合的深度学习同学。
官方QQ群:703252161。
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
官网地址:https://www.paddlepaddle.org.cn
飞桨核心框架项目地址:
GitHub: https://github.com/PaddlePaddle/Paddle
Gitee: https://gitee.com/paddlepaddle/Paddle
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态

