- 1让Sora和ChatGPT更可靠!只需这个知识价值定量评估新框架
- 2maven打包自定义包名_assembly打包 包名
- 3burpsuite安装HTTPS证书_burp证书
- 4Android 编译系统(Build System)剖析_system_ext_specific
- 5学点Java打小工_Day2Day3_一点作业
- 6快手匿名直播间提取工具,可采集匿名用户信息,UID评论内容都可以,源码分享仅供学_获取快手用户头像api
- 7算法的学习-基础篇_算法主要学什么
- 8网上租房售房管理系统/二手房智能选取与推荐系统/房屋租赁管理系统/中原房产中介登记系统的设计与实现(源码+论文)_java_312_作为网络房屋租赁销售求租系统,在系统中有注册会员和各类的房屋信息要管理员
- 9wazuh agent功能详解
- 10TCPIP协议总结
Pytorch BERT
赞
踩
Pytorch BERT
0. 环境介绍
小技巧:当遇到函数看不懂的时候可以按 Shift+Tab 查看函数详解。
1. BERT
1.1 NLP 中的迁移学习
- 使用预训练好的模型来抽取词、句子的特征
- 例如 word2vec 或语言模型
- 不更新预训练好的模型
- 需要构建新的网络来抓取新任务需要的信息
- word2vec 忽略了时序信息,语言模型只看一个方向
1.2 BERT 的动机
- 基于微调的 NLP 模型
- 预训练的模型抽取了足够多的信息
- 新的任务只需要增加一个简单的输出层
1.3 BERT 架构
- 只有编码器的 Transformer
- 两个版本
- Base:#blocks = 12,hidden size = 768,#heads = 12,#parameters = 110M
- Large:#blocks = 24,hidden size = 1024,#heads = 16,#parameters = 340M
- 在大规模数据上训练 (>3Billion 个词)
1.4 对输入的修改
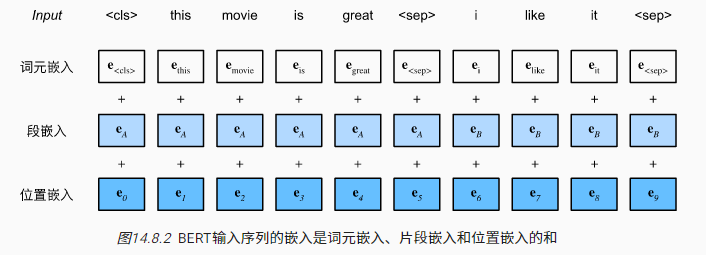
- 每个样本是一个句子对
- 加入额外的片段嵌入
- 位置编码可学习
1.5 预训练任务1:带掩码的语言模型
- Transformer 的编码器是双向的,标准语言模型要求单向
- 带掩码的语言模型每次随机(15%概率)将一些词元换成 <mask>
- 因为微调任务中不出现 <mask>
- 80% 概率下,将选中的词元变成 <mask>
- 10% 概率下,换成一个随即词元
- 10% 概率下,保持原有的词元
原本的 Transformer 编码器是双向的,解码器才是单向的,BERT 只使用其编码器,使编码器进行改进,变成了完形填空。
1.6 预训练任务2:下一句子预测
- 预测一个句子对中两个句子是不是相邻
- 训练样本中:
- 50% 概率选择相邻句子对:<cls> this movie is great <sep> i like it <sep>
- 50% 概率选择随机句子对:<cls> this movie is great <sep> hello world <sep>
- 将 <cls> 对应的输出放到一个全连接层来预测
1.7 BERT 改进总结
- BERT 针对微调设计
- 基于 Transformer 的编码器做了修改
- 模型更大,训练数据更多
- 输入句子对,片段嵌入,可学习的位置编码
- 训练时使用两个任务
- 带掩码的语言模型(完形填空)
- 下一个句子预测
2. BERT 微调
- BERT 对每一个词元返回抽取了上下文信息的特征向量
- 不同的任务使用不同的特征
2.1 单文本分类任务
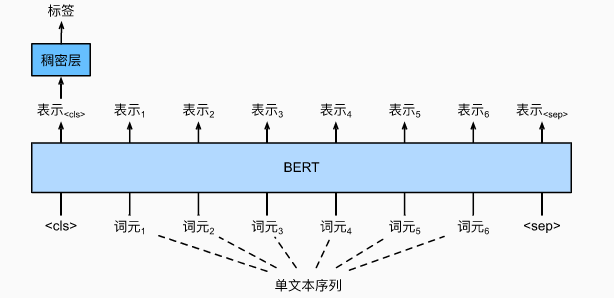
特殊分类标记 “<cls>” 的 BERT 表示对整个输入文本序列的信息进行编码。作为输入单个文本的表示,它将被送入到由全连接(稠密)层组成的小多层感知机中,以输出所有离散标签值的分布。
2.2 命名实体识别任务
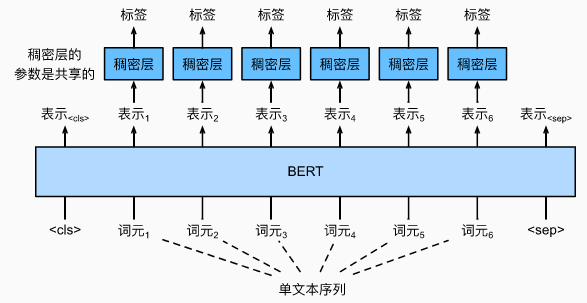
- 识别一个词元是不是命名实体,例如人名、机构、位置
- 将非特殊词元放进全连接层分类
2.3 问题问答任务
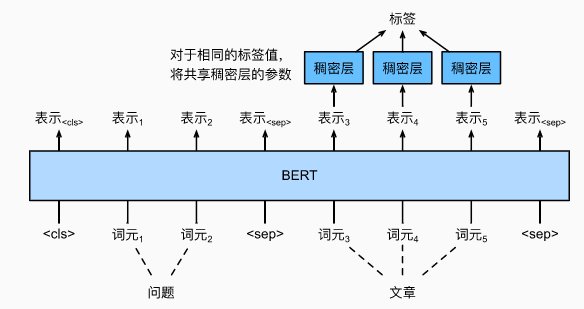
- 给定一个问题和描述文字,找出一个片段作为回答
- 对片段中的每个词元预测它是不是回答的开头或结束
2.4 总结
- 即使下游任务各有不同,使用 BERT 微调时均只需要增加输出层
- 根据任务的不同,输入的表示,和使用的 BERT 的特征也会不一样
3. BERT 代码
3.0 导包
!pip install -U d2l
import torch
from torch import nn
from d2l import torch as d2l
- 1
- 2
- 3
- 4
3.1 输入表示
在自然语言处理中,有些任务(如情感分析)以单个文本作为输入,而有些任务(如自然语言推断)以一对文本序列作为输入。BERT 输入序列明确地表示单个文本和文本对。当输入为单个文本时,BERT 输入序列是特殊类别词元“<cls>”、文本序列的标记、以及特殊分隔词元“<sep>”的连结。当输入为文本对时,BERT 输入序列是“<cls>”、第一个文本序列的标记、“<sep>”、第二个文本序列标记、以及“”的连结。我们将始终如一地将术语“BERT 输入序列”与其他类型的“序列”区分开来。例如,一个 BERT 输入序列可以包括一个文本序列或两个文本序列。
下面的 get_tokens_and_segments 将一个句子或两个句子作为输入,然后返回BERT输入序列的标记及其相应的片段索引:
def get_tokens_and_segments(tokens_a, tokens_b=None):
"""获取输入序列的词元及其片段索引"""
tokens = ['<cls>'] + tokens_a + ['<sep>']
# 0和1分别标记片段A和B
segments = [0] * (len(tokens_a) + 2)
if tokens_b is not None:
tokens += tokens_b + ['<sep>']
segments += [1] * (len(tokens_b) + 1)
return tokens, segments
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3.2 BERTEncoder
BERT 选择 Transformer 编码器作为其双向架构。在Transformer 编码器中常见是,位置嵌入被加入到输入序列的每个位置。然而,与原始的 Transformer 编码器不同,BERT 使用可学习的位置嵌入。
BERT 输入序列的嵌入是词元嵌入、片段嵌入和位置嵌入的和,与 TransformerEncoder 不同,BERTEncoder 使用片段嵌入和可学习的位置嵌入。:
class BERTEncoder(nn.Module): """BERT编码器""" def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, num_layers, dropout, max_len=1000, key_size=768, query_size=768, value_size=768, **kwargs): super(BERTEncoder, self).__init__(**kwargs) self.token_embedding = nn.Embedding(vocab_size, num_hiddens) self.segment_embedding = nn.Embedding(2, num_hiddens) self.blks = nn.Sequential() for i in range(num_layers): self.blks.add_module(f"{i}", d2l.EncoderBlock( key_size, query_size, value_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, dropout, True)) # 在BERT中,位置嵌入是可学习的,因此我们创建一个足够长的位置嵌入参数 self.pos_embedding = nn.Parameter(torch.randn(1, max_len, num_hiddens)) def forward(self, tokens, segments, valid_lens): # 在以下代码段中,X的形状保持不变:(批量大小,最大序列长度,num_hiddens) X = self.token_embedding(tokens) + self.segment_embedding(segments) X = X + self.pos_embedding.data[:, :X.shape[1], :] for blk in self.blks: X = blk(X, valid_lens) return X

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
假设词表大小为 10000,为了演示 BERTEncoder 的前向推断,让我们创建一个实例并初始化它的参数:
vocab_size, num_hiddens, ffn_num_hiddens, num_heads = 10000, 768, 1024, 4
norm_shape, ffn_num_input, num_layers, dropout = [768], 768, 2, 0.2
encoder = BERTEncoder(vocab_size, num_hiddens, norm_shape, ffn_num_input,
ffn_num_hiddens, num_heads, num_layers, dropout)
- 1
- 2
- 3
- 4
我们将 tokens 定义为长度为 8 的 2 个输入序列,其中每个词元是词表的索引。使用输入 tokens 的 BERTEncoder 的前向推断返回编码结果,其中每个词元由向量表示,其长度由超参数 num_hiddens 定义。此超参数通常称为 Transformer 编码器的隐藏大小(隐藏单元数):
tokens = torch.randint(0, vocab_size, (2, 8))
segments = torch.tensor([[0, 0, 0, 0, 1, 1, 1, 1], [0, 0, 0, 1, 1, 1, 1, 1]])
encoded_X = encoder(tokens, segments, None)
encoded_X.shape
- 1
- 2
- 3
- 4
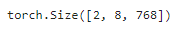
3.3 掩蔽语言模型
语言模型使用左侧的上下文预测词元。为了双向编码上下文以表示每个词元,BERT随机掩蔽词元并使用来自双向上下文的词元以自监督的方式预测掩蔽词元。此任务称为掩蔽语言模型。
在这个预训练任务中,将随机选择 15% 的词元作为预测的掩蔽词元。要预测一个掩蔽词元而不使用标签作弊,一个简单的方法是总是用一个特殊的 “<mask>” 替换输入序列中的词元。然而,人造特殊词元 “<mask>” 不会出现在微调中。为了避免预训练和微调之间的这种不匹配,如果为预测而屏蔽词元(例如,在 “this movie is great” 中选择掩蔽和预测“great”),则在输入中将其替换为:
- 80% 时间为特殊的“<mask>“词元(例如,“this movie is great”变为“this movie is <mask>”;
- 10% 时间为随机词元(例如,“this movie is great” 变为 “this movie is drink”);
- 10% 时间内为不变的标签词元(例如,“this movie is great” 变为 “this movie is great”)。
请注意,在 15% 的时间中,有 10% 的时间插入了随机词元。这种偶然的噪声鼓励 BERT 在其双向上下文编码中不那么偏向于掩蔽词元(尤其是当标签词元保持不变时)。
预测使用单隐藏层的多层感知机(self.mlp)。在前向推断中,它需要两个输入:BERTEncoder 的编码结果和用于预测的词元位置。输出是这些位置的预测结果:
class MaskLM(nn.Module): """BERT的掩蔽语言模型任务""" def __init__(self, vocab_size, num_hiddens, num_inputs=768, **kwargs): super(MaskLM, self).__init__(**kwargs) self.mlp = nn.Sequential(nn.Linear(num_inputs, num_hiddens), nn.ReLU(), nn.LayerNorm(num_hiddens), nn.Linear(num_hiddens, vocab_size)) def forward(self, X, pred_positions): num_pred_positions = pred_positions.shape[1] pred_positions = pred_positions.reshape(-1) batch_size = X.shape[0] batch_idx = torch.arange(0, batch_size) # 假设batch_size=2,num_pred_positions=3 # 那么batch_idx是np.array([0,0,0,1,1]) batch_idx = torch.repeat_interleave(batch_idx, num_pred_positions) masked_X = X[batch_idx, pred_positions] masked_X = masked_X.reshape((batch_size, num_pred_positions, -1)) mlm_Y_hat = self.mlp(masked_X) return mlm_Y_hat
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
来自 BERTEncoder 的正向推断 encoded_X 表示 2 个 BERT 输入序列。我们将 mlm_positions 定义为在 encoded_X 的任一输入序列中预测的 3 个指示(需要去进行预测的位置)。mlm 的前向推断返回 encoded_X 的所有掩蔽位置 mlm_positions 处的预测结果 mlm_Y_hat。对于每个预测,结果的大小等于词表的大小:
mlm = MaskLM(vocab_size, num_hiddens)
mlm_positions = torch.tensor([[1, 5, 2], [6, 1, 5]])
mlm_Y_hat = mlm(encoded_X, mlm_positions)
mlm_Y_hat.shape
- 1
- 2
- 3
- 4
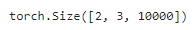
通过掩码下的预测词元 mlm_Y 的真实标签 mlm_Y_hat,我们可以计算在 BERT 预训练中的遮蔽语言模型任务的交叉熵损失:
mlm_Y = torch.tensor([[7, 8, 9], [10, 20, 30]])
loss = nn.CrossEntropyLoss(reduction='none')
mlm_l = loss(mlm_Y_hat.reshape((-1, vocab_size)), mlm_Y.reshape(-1))
mlm_l.shape
- 1
- 2
- 3
- 4

3.4 下一句预测
尽管掩蔽语言建模能够编码双向上下文来表示单词,但它不能显式地建模文本对之间的逻辑关系。为了帮助理解两个文本序列之间的关系,BERT 在预训练中考虑了一个二元分类任务——下一句预测。在为预训练生成句子对时,有一半的时间它们确实是标签为“真”的连续句子;在另一半的时间里,第二个句子是从语料库中随机抽取的,标记为“假”。
下面的 NextSentencePred 类使用单隐藏层的多层感知机来预测第二个句子是否是 BERT 输入序列中第一个句子的下一个句子。由于 Transformer 编码器中的自注意力,特殊词元 “<cls>” 的 BERT 表示已经对输入的两个句子进行了编码。
因此,多层感知机分类器的输出层(self.output)以 X 作为输入,其中 X 是多层感知机隐藏层的输出,而 MLP 隐藏层的输入是编码后的 “<cls>” 词元:
class NextSentencePred(nn.Module):
"""BERT的下一句预测任务"""
def __init__(self, num_inputs, **kwargs):
super(NextSentencePred, self).__init__(**kwargs)
self.output = nn.Linear(num_inputs, 2)
def forward(self, X):
# X的形状:(batchsize,num_hiddens)
return self.output(X)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
NextSentencePred 实例的前向推断返回每个 BERT 输入序列的二分类预测:
encoded_X = torch.flatten(encoded_X, start_dim=1)
# NSP的输入形状:(batchsize,num_hiddens)
nsp = NextSentencePred(encoded_X.shape[-1])
nsp_Y_hat = nsp(encoded_X)
nsp_Y_hat.shape
- 1
- 2
- 3
- 4
- 5
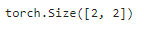
计算两个二元分类的交叉熵损失:
nsp_y = torch.tensor([0, 1])
nsp_l = loss(nsp_Y_hat, nsp_y)
nsp_l.shape
- 1
- 2
- 3

上述两个预训练任务中的所有标签都可以从预训练语料库中获得,而无需人工标注。原始的 BERT 已经在图书语料库 和英文维基百科的连接上进行了预训练。这两个文本语料库非常庞大:它们分别有 8 亿个单词和 25 亿个单词。
3.5 整合代码
在预训练 BERT 时,最终的损失函数是掩蔽语言模型损失函数和下一句预测损失函数的线性组合。现在我们可以通过实例化三个类 BERTEncoder、MaskLM 和 NextSentencePred 来定义 BERTModel 类。前向推断返回编码后的 BERT 表示encoded_X、掩蔽语言模型预测 mlm_Y_hat 和下一句预测 nsp_Y_hat:
class BERTModel(nn.Module): """BERT模型""" def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, num_layers, dropout, max_len=1000, key_size=768, query_size=768, value_size=768, hid_in_features=768, mlm_in_features=768, nsp_in_features=768): super(BERTModel, self).__init__() self.encoder = BERTEncoder(vocab_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, num_layers, dropout, max_len=max_len, key_size=key_size, query_size=query_size, value_size=value_size) self.mlm = MaskLM(vocab_size, num_hiddens, mlm_in_features) self.nsp = NextSentencePred(nsp_in_features) self.hidden = nn.Sequential(nn.Linear(hid_in_features, num_hiddens), nn.Tanh()) def forward(self, tokens, segments, valid_lens=None, pred_positions=None): encoded_X = self.encoder(tokens, segments, valid_lens) if pred_positions is not None: mlm_Y_hat = self.mlm(encoded_X, pred_positions) else: mlm_Y_hat = None # 用于下一句预测的多层感知机分类器的隐藏层,0是“<cls>”标记的索引 nsp_Y_hat = self.nsp(self.hidden(encoded_X[:, 0, :])) return encoded_X, mlm_Y_hat, nsp_Y_hat
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
4. BERT 预训练数据集
4.0 导入 3.0 之外的包
import os
import random
- 1
- 2
4.1 加载数据集
为了方便 BERT 预训练的演示,我们使用了较小的语料库 WikiText-2。
在 WikiText-2 数据集中,每行代表一个段落,其中在任意标点符号及其前面的词元之间插入空格。保留至少有两句话的段落。为了简单起见,我们仅使用句号作为分隔符来拆分句子:
d2l.DATA_HUB['wikitext-2'] = (
'https://s3.amazonaws.com/research.metamind.io/wikitext/'
'wikitext-2-v1.zip', '3c914d17d80b1459be871a5039ac23e752a53cbe')
def _read_wiki(data_dir):
file_name = os.path.join(data_dir, 'wiki.train.tokens')
with open(file_name, 'r') as f:
lines = f.readlines()
# 大写字母转换为小写字母
paragraphs = [line.strip().lower().split(' . ')
for line in lines if len(line.split(' . ')) >= 2]
random.shuffle(paragraphs)
return paragraphs
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
4.2 生成下一句预测任务的数据
_get_next_sentence 函数生成二分类任务的训练样本:
def _get_next_sentence(sentence, next_sentence, paragraphs):
if random.random() < 0.5:
is_next = True
else:
# paragraphs是三重列表的嵌套
next_sentence = random.choice(random.choice(paragraphs))
is_next = False
return sentence, next_sentence, is_next
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
下面的函数通过调用 _get_next_sentence 函数从输入 paragraph 生成用于下一句预测的训练样本。这里 paragraph 是句子列表,其中每个句子都是词元列表。自变量 max_len 指定预训练期间的BERT输入序列的最大长度:
def _get_nsp_data_from_paragraph(paragraph, paragraphs, vocab, max_len):
nsp_data_from_paragraph = []
for i in range(len(paragraph) - 1):
tokens_a, tokens_b, is_next = _get_next_sentence(
paragraph[i], paragraph[i + 1], paragraphs)
# 考虑1个'<cls>'词元和2个'<sep>'词元
if len(tokens_a) + len(tokens_b) + 3 > max_len:
continue
tokens, segments = d2l.get_tokens_and_segments(tokens_a, tokens_b)
nsp_data_from_paragraph.append((tokens, segments, is_next))
return nsp_data_from_paragraph
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
4.3 生成遮蔽语言模型任务的数据
为了从 BERT 输入序列生成遮蔽语言模型的训练样本,我们定义了以下 _replace_mlm_tokens 函数。在其输入中,tokens 是表示 BERT 输入序列的词元的列表,candidate_pred_positions 是不包括特殊词元的BERT输入序列的词元索引的列表(特殊词元在遮蔽语言模型任务中不被预测),以及 num_mlm_preds 指示预测的数量(选择 15% 要预测的随机词元)。
在每个预测位置,输入可以由特殊的 “掩码” 词元或随机词元替换,或者保持不变。最后,该函数返回可能替换后的输入词元、发生预测的词元索引和这些预测的标签:
def _replace_mlm_tokens(tokens, candidate_pred_positions, num_mlm_preds, vocab): # 为遮蔽语言模型的输入创建新的词元副本,其中输入可能包含替换的“<mask>”或随机词元 mlm_input_tokens = [token for token in tokens] pred_positions_and_labels = [] # 打乱后用于在遮蔽语言模型任务中获取15%的随机词元进行预测 random.shuffle(candidate_pred_positions) for mlm_pred_position in candidate_pred_positions: if len(pred_positions_and_labels) >= num_mlm_preds: break masked_token = None # 80%的时间:将词替换为“<mask>”词元 if random.random() < 0.8: masked_token = '<mask>' else: # 10%的时间:保持词不变 if random.random() < 0.5: masked_token = tokens[mlm_pred_position] # 10%的时间:用随机词替换该词 else: masked_token = random.choice(vocab.idx_to_token) mlm_input_tokens[mlm_pred_position] = masked_token pred_positions_and_labels.append( (mlm_pred_position, tokens[mlm_pred_position])) return mlm_input_tokens, pred_positions_and_labels
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
通过调用前述的 _replace_mlm_tokens 函数,以下函数将 BERT 输入序列(tokens)作为输入,并返回输入词元的索引(可能的词元替换之后)、发生预测的词元索引以及这些预测的标签索引:
def _get_mlm_data_from_tokens(tokens, vocab): candidate_pred_positions = [] # tokens是一个字符串列表 for i, token in enumerate(tokens): # 在遮蔽语言模型任务中不会预测特殊词元 if token in ['<cls>', '<sep>']: continue candidate_pred_positions.append(i) # 遮蔽语言模型任务中预测15%的随机词元 num_mlm_preds = max(1, round(len(tokens) * 0.15)) mlm_input_tokens, pred_positions_and_labels = _replace_mlm_tokens( tokens, candidate_pred_positions, num_mlm_preds, vocab) pred_positions_and_labels = sorted(pred_positions_and_labels, key=lambda x: x[0]) pred_positions = [v[0] for v in pred_positions_and_labels] mlm_pred_labels = [v[1] for v in pred_positions_and_labels] return vocab[mlm_input_tokens], pred_positions, vocab[mlm_pred_labels]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
4.4 将文本转换为预训练数据集
现在我们几乎准备好为 BERT 预训练定制一个 Dataset 类。在此之前,我们仍然需要定义辅助函数 _pad_bert_inputs 来将特殊的 “<mask>” 词元附加到输入。它的参数 examples 包含来自两个预训练任务的辅助函数 _get_nsp_data_from_paragraph 和 _get_mlm_data_from_tokens 的输出:
def _pad_bert_inputs(examples, max_len, vocab): max_num_mlm_preds = round(max_len * 0.15) all_token_ids, all_segments, valid_lens, = [], [], [] all_pred_positions, all_mlm_weights, all_mlm_labels = [], [], [] nsp_labels = [] for (token_ids, pred_positions, mlm_pred_label_ids, segments, is_next) in examples: all_token_ids.append(torch.tensor(token_ids + [vocab['<pad>']] * ( max_len - len(token_ids)), dtype=torch.long)) all_segments.append(torch.tensor(segments + [0] * ( max_len - len(segments)), dtype=torch.long)) # valid_lens不包括'<pad>'的计数 valid_lens.append(torch.tensor(len(token_ids), dtype=torch.float32)) all_pred_positions.append(torch.tensor(pred_positions + [0] * ( max_num_mlm_preds - len(pred_positions)), dtype=torch.long)) # 填充词元的预测将通过乘以0权重在损失中过滤掉 all_mlm_weights.append( torch.tensor([1.0] * len(mlm_pred_label_ids) + [0.0] * ( max_num_mlm_preds - len(pred_positions)), dtype=torch.float32)) all_mlm_labels.append(torch.tensor(mlm_pred_label_ids + [0] * ( max_num_mlm_preds - len(mlm_pred_label_ids)), dtype=torch.long)) nsp_labels.append(torch.tensor(is_next, dtype=torch.long)) return (all_token_ids, all_segments, valid_lens, all_pred_positions, all_mlm_weights, all_mlm_labels, nsp_labels)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
将用于生成两个预训练任务的训练样本的辅助函数和用于填充输入的辅助函数放在一起,我们定义以下 _WikiTextDataset 类为用于预训练 BERT 的 WikiText-2 数据集。通过实现 __getitem__ 函数,我们可以任意访问 WikiText-2 语料库的一对句子生成的预训练样本(遮蔽语言模型和下一句预测)样本:
class _WikiTextDataset(torch.utils.data.Dataset): def __init__(self, paragraphs, max_len): # 输入paragraphs[i]是代表段落的句子字符串列表; # 而输出paragraphs[i]是代表段落的句子列表,其中每个句子都是词元列表 paragraphs = [d2l.tokenize( paragraph, token='word') for paragraph in paragraphs] sentences = [sentence for paragraph in paragraphs for sentence in paragraph] self.vocab = d2l.Vocab(sentences, min_freq=5, reserved_tokens=[ '<pad>', '<mask>', '<cls>', '<sep>']) # 获取下一句子预测任务的数据 examples = [] for paragraph in paragraphs: examples.extend(_get_nsp_data_from_paragraph( paragraph, paragraphs, self.vocab, max_len)) # 获取遮蔽语言模型任务的数据 examples = [(_get_mlm_data_from_tokens(tokens, self.vocab) + (segments, is_next)) for tokens, segments, is_next in examples] # 填充输入 (self.all_token_ids, self.all_segments, self.valid_lens, self.all_pred_positions, self.all_mlm_weights, self.all_mlm_labels, self.nsp_labels) = _pad_bert_inputs( examples, max_len, self.vocab) def __getitem__(self, idx): return (self.all_token_ids[idx], self.all_segments[idx], self.valid_lens[idx], self.all_pred_positions[idx], self.all_mlm_weights[idx], self.all_mlm_labels[idx], self.nsp_labels[idx]) def __len__(self): return len(self.all_token_ids)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
通过使用 _read_wiki 函数和 _WikiTextDataset 类,我们定义了下面的 load_data_wiki 来下载并生成 WikiText-2 数据集,并从中生成预训练样本:
def load_data_wiki(batch_size, max_len):
"""加载WikiText-2数据集"""
num_workers = d2l.get_dataloader_workers()
data_dir = d2l.download_extract('wikitext-2', 'wikitext-2')
paragraphs = _read_wiki(data_dir)
train_set = _WikiTextDataset(paragraphs, max_len)
train_iter = torch.utils.data.DataLoader(train_set, batch_size,
shuffle=True, num_workers=num_workers)
return train_iter, train_set.vocab
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
将批量大小设置为 512,将 BERT 输入序列的最大长度设置为 64,我们打印出小批量的 BERT 预训练样本的形状:
batch_size, max_len = 512, 64
train_iter, vocab = load_data_wiki(batch_size, max_len)
for (tokens_X, segments_X, valid_lens_x, pred_positions_X, mlm_weights_X,
mlm_Y, nsp_y) in train_iter:
print(tokens_X.shape, segments_X.shape, valid_lens_x.shape,
pred_positions_X.shape, mlm_weights_X.shape, mlm_Y.shape,
nsp_y.shape)
break
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

5. 预训练 BERT
5.1 加载数据集
首先,我们加载 WikiText-2 数据集作为小批量的预训练样本,用于遮蔽语言模型和下一句预测。批量大小是 512, BERT 输入序列的最大长度是 64。注意,在原始 BERT 模型中,最大长度是 512:
batch_size, max_len = 512, 64
train_iter, vocab = d2l.load_data_wiki(batch_size, max_len)
- 1
- 2
5.2 定义 BERT 模型
我们定义了一个小的 BERT,使用了 2 层编码器、128 个隐藏单元和 2 个自注意头:
net = d2l.BERTModel(len(vocab), num_hiddens=128, norm_shape=[128],
ffn_num_input=128, ffn_num_hiddens=256, num_heads=2,
num_layers=2, dropout=0.2, key_size=128, query_size=128,
value_size=128, hid_in_features=128, mlm_in_features=128,
nsp_in_features=128)
devices = d2l.try_all_gpus()
loss = nn.CrossEntropyLoss()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
5.3 计算损失
定义了一个辅助函数 _get_batch_loss_bert。给定训练样本,该函数计算遮蔽语言模型和下一句子预测任务的损失。请注意,BERT 预训练的最终损失是遮蔽语言模型损失和下一句预测损失的和:
def _get_batch_loss_bert(net, loss, vocab_size, tokens_X, segments_X, valid_lens_x, pred_positions_X, mlm_weights_X, mlm_Y, nsp_y): # 前向传播 _, mlm_Y_hat, nsp_Y_hat = net(tokens_X, segments_X, valid_lens_x.reshape(-1), pred_positions_X) # 计算遮蔽语言模型损失 mlm_l = loss(mlm_Y_hat.reshape(-1, vocab_size), mlm_Y.reshape(-1)) *\ mlm_weights_X.reshape(-1, 1) mlm_l = mlm_l.sum() / (mlm_weights_X.sum() + 1e-8) # 计算下一句子预测任务的损失 nsp_l = loss(nsp_Y_hat, nsp_y) l = mlm_l + nsp_l return mlm_l, nsp_l, l
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
5.4 定义预训练函数
下面的 train_bert 函数定义了在 WikiText-2(train_iter)数据集上预训练 BERT(net)的过程。训练 BERT 可能需要很长时间。以下函数的输入 num_steps 指定了训练的迭代步数,而不是像 train_ch13 函数那样指定训练的轮数:
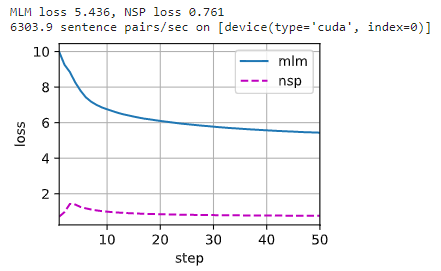
def train_bert(train_iter, net, loss, vocab_size, devices, num_steps): net = nn.DataParallel(net, device_ids=devices).to(devices[0]) trainer = torch.optim.Adam(net.parameters(), lr=0.01) step, timer = 0, d2l.Timer() animator = d2l.Animator(xlabel='step', ylabel='loss', xlim=[1, num_steps], legend=['mlm', 'nsp']) # 遮蔽语言模型损失的和,下一句预测任务损失的和,句子对的数量,计数 metric = d2l.Accumulator(4) num_steps_reached = False while step < num_steps and not num_steps_reached: for tokens_X, segments_X, valid_lens_x, pred_positions_X,\ mlm_weights_X, mlm_Y, nsp_y in train_iter: tokens_X = tokens_X.to(devices[0]) segments_X = segments_X.to(devices[0]) valid_lens_x = valid_lens_x.to(devices[0]) pred_positions_X = pred_positions_X.to(devices[0]) mlm_weights_X = mlm_weights_X.to(devices[0]) mlm_Y, nsp_y = mlm_Y.to(devices[0]), nsp_y.to(devices[0]) trainer.zero_grad() timer.start() mlm_l, nsp_l, l = _get_batch_loss_bert( net, loss, vocab_size, tokens_X, segments_X, valid_lens_x, pred_positions_X, mlm_weights_X, mlm_Y, nsp_y) l.backward() trainer.step() metric.add(mlm_l, nsp_l, tokens_X.shape[0], 1) timer.stop() animator.add(step + 1, (metric[0] / metric[3], metric[1] / metric[3])) step += 1 if step == num_steps: num_steps_reached = True break print(f'MLM loss {metric[0] / metric[3]:.3f}, ' f'NSP loss {metric[1] / metric[3]:.3f}') print(f'{metric[2] / timer.sum():.1f} sentence pairs/sec on ' f'{str(devices)}')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
5.5 预训练
预训练过程中,我们可以绘制出遮蔽语言模型损失和下一句预测损失:
train_bert(train_iter, net, loss, len(vocab), devices, 50)
- 1
5.6 用 BERT 表示文本
在预训练 BERT 之后,我们可以用它来表示单个文本、文本对或其中的任何词元。下面的函数返回 tokens_a 和 tokens_b 中所有词元的 BERT(net)表示:
def get_bert_encoding(net, tokens_a, tokens_b=None):
tokens, segments = d2l.get_tokens_and_segments(tokens_a, tokens_b)
token_ids = torch.tensor(vocab[tokens], device=devices[0]).unsqueeze(0)
segments = torch.tensor(segments, device=devices[0]).unsqueeze(0)
valid_len = torch.tensor(len(tokens), device=devices[0]).unsqueeze(0)
encoded_X, _, _ = net(token_ids, segments, valid_len)
return encoded_X
- 1
- 2
- 3
- 4
- 5
- 6
- 7
考虑 “a crane is flying” 这句话。插入特殊标记 “<cls>”(用于分类)和 “<sep>”(用于分隔)后,BERT 输入序列的长度为 6。因为 0 是 “<cls>”词元,encoded_text[:, 0, :] 是整个输入语句的 BERT 表示。为了评估一词多义词元 “crane”,我们还打印出了该词元的 BERT 表示的前三个元素:
tokens_a = ['a', 'crane', 'is', 'flying']
encoded_text = get_bert_encoding(net, tokens_a)
# 词元:'<cls>','a','crane','is','flying','<sep>'
encoded_text_cls = encoded_text[:, 0, :]
encoded_text_crane = encoded_text[:, 2, :]
encoded_text.shape, encoded_text_cls.shape, encoded_text_crane[0][:3]
- 1
- 2
- 3
- 4
- 5
- 6

现在考虑一个句子 “a crane driver came” 和 “he just left”。类似地,encoded_pair[:, 0, :] 是来自预训练 BERT 的整个句子对的编码结果。注意,多义词元 “crane” 的前三个元素与上下文不同时的元素不同。这支持了BERT表示是上下文敏感的:
tokens_a, tokens_b = ['a', 'crane', 'driver', 'came'], ['he', 'just', 'left']
encoded_pair = get_bert_encoding(net, tokens_a, tokens_b)
# 词元:'<cls>','a','crane','driver','came','<sep>','he','just',
# 'left','<sep>'
encoded_pair_cls = encoded_pair[:, 0, :]
encoded_pair_crane = encoded_pair[:, 2, :]
encoded_pair.shape, encoded_pair_cls.shape, encoded_pair_crane[0][:3]
- 1
- 2
- 3
- 4
- 5
- 6
- 7

6. 自然语言推断数据集
6.1 自然语言推断任务
自然语言推断(natural language inference)主要研究假设(hypothesis)是否可以从前提(premise)中推断出来, 其中两者都是文本序列。 换言之,自然语言推断决定了一对文本序列之间的逻辑关系。这类关系通常分为三种类型:
- 蕴涵(entailment):假设可以从前提中推断出来。
- 矛盾(contradiction):假设的否定可以从前提中推断出来。
- 中性(neutral):所有其他情况。
例如,下面的一个文本对将被贴上“蕴涵”的标签,因为假设中的“表白”可以从前提中的“拥抱”中推断出来:
- 前提:两个女人拥抱在一起。
- 假设:两个女人在示爱。
下面是一个“矛盾”的例子,因为“运行编码示例”表示“不睡觉”,而不是“睡觉”。
- 前提:一名男子正在运行Dive Into Deep Learning的编码示例。
- 假设:该男子正在睡觉。
第三个例子显示了一种“中性”关系,因为“正在为我们表演”这一事实无法推断出“出名”或“不出名”。
- 前提:音乐家们正在为我们表演。
- 假设:音乐家很有名。
6.2 导入 SNLI 数据集
斯坦福自然语言推断语料库(Stanford Natural Language Inference,SNLI)是由500000多个带标签的英语句子对组成的集合:
!pip install -U d2l
import os
import re
import torch
from torch import nn
from d2l import torch as d2l
d2l.DATA_HUB['SNLI'] = (
'https://nlp.stanford.edu/projects/snli/snli_1.0.zip',
'9fcde07509c7e87ec61c640c1b2753d9041758e4')
data_dir = d2l.download_extract('SNLI')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
我们定义函数read_snli以仅提取数据集的一部分,然后返回前提、假设及其标签的列表:
def read_snli(data_dir, is_train): """将SNLI数据集解析为前提、假设和标签""" def extract_text(s): # 删除我们不会使用的信息 s = re.sub('\\(', '', s) s = re.sub('\\)', '', s) # 用一个空格替换两个或多个连续的空格 s = re.sub('\\s{2,}', ' ', s) return s.strip() label_set = {'entailment': 0, 'contradiction': 1, 'neutral': 2} file_name = os.path.join(data_dir, 'snli_1.0_train.txt' if is_train else 'snli_1.0_test.txt') with open(file_name, 'r') as f: rows = [row.split('\t') for row in f.readlines()[1:]] premises = [extract_text(row[1]) for row in rows if row[0] in label_set] hypotheses = [extract_text(row[2]) for row in rows if row[0] \ in label_set] labels = [label_set[row[0]] for row in rows if row[0] in label_set] return premises, hypotheses, labels
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
打印前3对前提和假设,以及它们的标签(“0”、“1”和“2”分别对应于“蕴涵”、“矛盾”和“中性”):
train_data = read_snli(data_dir, is_train=True)
for x0, x1, y in zip(train_data[0][:3], train_data[1][:3], train_data[2][:3]):
print('前提:', x0)
print('假设:', x1)
print('标签:', y)
- 1
- 2
- 3
- 4
- 5

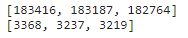
训练集约有550000对,测试集约有10000对。下面显示了训练集和测试集中的三个标签“蕴涵”、“矛盾”和“中性”是平衡的:
test_data = read_snli(data_dir, is_train=False)
for data in [train_data, test_data]:
print([[row for row in data[2]].count(i) for i in range(3)])
- 1
- 2
- 3
6.3 定义用于加载数据集的类
下面我们来定义一个用于加载 SNLI 数据集的类。类构造函数中的变量 num_steps 指定文本序列的长度,使得每个小批量序列将具有相同的形状。换句话说,在较长序列中的前 num_steps 个标记之后的标记被截断,而特殊标记 “<pad>” 将被附加到较短的序列后,直到它们的长度变为 num_steps。通过实现 __getitem__ 功能,我们可以任意访问带有索引 idx 的前提、假设和标签:
class SNLIDataset(torch.utils.data.Dataset): """用于加载SNLI数据集的自定义数据集""" def __init__(self, dataset, num_steps, vocab=None): self.num_steps = num_steps all_premise_tokens = d2l.tokenize(dataset[0]) all_hypothesis_tokens = d2l.tokenize(dataset[1]) if vocab is None: self.vocab = d2l.Vocab(all_premise_tokens + \ all_hypothesis_tokens, min_freq=5, reserved_tokens=['<pad>']) else: self.vocab = vocab self.premises = self._pad(all_premise_tokens) self.hypotheses = self._pad(all_hypothesis_tokens) self.labels = torch.tensor(dataset[2]) print('read ' + str(len(self.premises)) + ' examples') def _pad(self, lines): return torch.tensor([d2l.truncate_pad( self.vocab[line], self.num_steps, self.vocab['<pad>']) for line in lines]) def __getitem__(self, idx): return (self.premises[idx], self.hypotheses[idx]), self.labels[idx] def __len__(self): return len(self.premises)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
6.4 整合代码
我们可以调用 read_snli 函数和 SNLIDataset 类来下载 SNLI 数据集,并返回训练集和测试集的 DataLoader 实例,以及训练集的词表。值得注意的是,我们必须使用从训练集构造的词表作为测试集的词表。因此,在训练集中训练的模型将不知道来自测试集的任何新词元:
def load_data_snli(batch_size, num_steps=50):
"""下载SNLI数据集并返回数据迭代器和词表"""
num_workers = d2l.get_dataloader_workers()
data_dir = d2l.download_extract('SNLI')
train_data = read_snli(data_dir, True)
test_data = read_snli(data_dir, False)
train_set = SNLIDataset(train_data, num_steps)
test_set = SNLIDataset(test_data, num_steps, train_set.vocab)
train_iter = torch.utils.data.DataLoader(train_set, batch_size,
shuffle=True,
num_workers=num_workers)
test_iter = torch.utils.data.DataLoader(test_set, batch_size,
shuffle=False,
num_workers=num_workers)
return train_iter, test_iter, train_set.vocab
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
将批量大小设置为 128 时,将序列长度设置为 50,并调用 load_data_snli 函数来获取数据迭代器和词表。然后我们打印词表大小:
train_iter, test_iter, vocab = load_data_snli(128, 50)
len(vocab)
- 1
- 2

打印第一个小批量的形状,两个输入 X[0] 和 X[1] 分别表示前提和假设:
for X, Y in train_iter:
print(X[0].shape)
print(X[1].shape)
print(Y.shape)
break
- 1
- 2
- 3
- 4
- 5

7. BERT 微调代码
7.0 导包
import json
import multiprocessing
import os
import torch
from torch import nn
from d2l import torch as d2l
- 1
- 2
- 3
- 4
- 5
- 6
7.1 加载预训练的 BERT
这里有两个模型,一个是 BERT 的基本版本,一个是小的版本:
d2l.DATA_HUB['bert.base'] = (d2l.DATA_URL + 'bert.base.torch.zip',
'225d66f04cae318b841a13d32af3acc165f253ac')
d2l.DATA_HUB['bert.small'] = (d2l.DATA_URL + 'bert.small.torch.zip',
'c72329e68a732bef0452e4b96a1c341c8910f81f')
- 1
- 2
- 3
- 4
两个预训练好的 BERT 模型都包含一个定义词表的 “vocab.json” 文件和一个预训练参数的 “pretrained.params” 文件。实现了以下 load_pretrained_model 函数来加载预先训练好的 BERT 参数:
def load_pretrained_model(pretrained_model, num_hiddens, ffn_num_hiddens, num_heads, num_layers, dropout, max_len, devices): data_dir = d2l.download_extract(pretrained_model) # 定义空词表以加载预定义词表 vocab = d2l.Vocab() vocab.idx_to_token = json.load(open(os.path.join(data_dir, 'vocab.json'))) vocab.token_to_idx = {token: idx for idx, token in enumerate( vocab.idx_to_token)} bert = d2l.BERTModel(len(vocab), num_hiddens, norm_shape=[256], ffn_num_input=256, ffn_num_hiddens=ffn_num_hiddens, num_heads=4, num_layers=2, dropout=0.2, max_len=max_len, key_size=256, query_size=256, value_size=256, hid_in_features=256, mlm_in_features=256, nsp_in_features=256) # 加载预训练BERT参数 bert.load_state_dict(torch.load(os.path.join(data_dir, 'pretrained.params'))) return bert, vocab
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
使用 samll 版本的 BERT:
devices = d2l.try_all_gpus()
bert, vocab = load_pretrained_model(
'bert.small', num_hiddens=256, ffn_num_hiddens=512, num_heads=4,
num_layers=2, dropout=0.1, max_len=512, devices=devices)
- 1
- 2
- 3
- 4
7.2 微调 BERT 的数据集
对于 SNLI 数据集的下游任务自然语言推断,定义一个定制的数据集类 SNLIBERTDataset。在每个样本中,前提和假设形成一对文本序列,并被打包成一个 BERT 输入序列。片段索引用于区分 BERT 输入序列中的前提和假设。利用预定义的 BERT 输入序列的最大长度(max_len),持续移除输入文本对中较长文本的最后一个标记,直到满足 max_len。为了加速生成用于微调 BERT 的 SNLI 数据集,我们使用 4 个工作进程并行生成训练或测试样本:
class SNLIBERTDataset(torch.utils.data.Dataset): def __init__(self, dataset, max_len, vocab=None): all_premise_hypothesis_tokens = [[ p_tokens, h_tokens] for p_tokens, h_tokens in zip( *[d2l.tokenize([s.lower() for s in sentences]) for sentences in dataset[:2]])] self.labels = torch.tensor(dataset[2]) self.vocab = vocab self.max_len = max_len (self.all_token_ids, self.all_segments, self.valid_lens) = self._preprocess(all_premise_hypothesis_tokens) print('read ' + str(len(self.all_token_ids)) + ' examples') def _preprocess(self, all_premise_hypothesis_tokens): pool = multiprocessing.Pool(4) # 使用4个进程 out = pool.map(self._mp_worker, all_premise_hypothesis_tokens) all_token_ids = [ token_ids for token_ids, segments, valid_len in out] all_segments = [segments for token_ids, segments, valid_len in out] valid_lens = [valid_len for token_ids, segments, valid_len in out] return (torch.tensor(all_token_ids, dtype=torch.long), torch.tensor(all_segments, dtype=torch.long), torch.tensor(valid_lens)) def _mp_worker(self, premise_hypothesis_tokens): p_tokens, h_tokens = premise_hypothesis_tokens self._truncate_pair_of_tokens(p_tokens, h_tokens) tokens, segments = d2l.get_tokens_and_segments(p_tokens, h_tokens) token_ids = self.vocab[tokens] + [self.vocab['<pad>']] \ * (self.max_len - len(tokens)) segments = segments + [0] * (self.max_len - len(segments)) valid_len = len(tokens) return token_ids, segments, valid_len def _truncate_pair_of_tokens(self, p_tokens, h_tokens): # 为BERT输入中的'<CLS>'、'<SEP>'和'<SEP>'词元保留位置 while len(p_tokens) + len(h_tokens) > self.max_len - 3: if len(p_tokens) > len(h_tokens): p_tokens.pop() else: h_tokens.pop() def __getitem__(self, idx): return (self.all_token_ids[idx], self.all_segments[idx], self.valid_lens[idx]), self.labels[idx] def __len__(self): return len(self.all_token_ids)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
# 如果出现显存不足错误,请减少“batch_size”。在原始的BERT模型中,max_len=512
batch_size, max_len, num_workers = 512, 128, d2l.get_dataloader_workers()
data_dir = d2l.download_extract('SNLI')
train_set = SNLIBERTDataset(d2l.read_snli(data_dir, True), max_len, vocab)
test_set = SNLIBERTDataset(d2l.read_snli(data_dir, False), max_len, vocab)
train_iter = torch.utils.data.DataLoader(train_set, batch_size, shuffle=True,
num_workers=num_workers)
test_iter = torch.utils.data.DataLoader(test_set, batch_size,
num_workers=num_workers)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
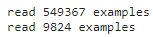
7.3 微调 BERT
class BERTClassifier(nn.Module):
def __init__(self, bert):
super(BERTClassifier, self).__init__()
self.encoder = bert.encoder
self.hidden = bert.hidden
self.output = nn.Linear(256, 3)
def forward(self, inputs):
tokens_X, segments_X, valid_lens_x = inputs
encoded_X = self.encoder(tokens_X, segments_X, valid_lens_x)
return self.output(self.hidden(encoded_X[:, 0, :]))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
net = BERTClassifier(bert)
- 1
lr, num_epochs = 1e-4, 5
trainer = torch.optim.Adam(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss(reduction='none')
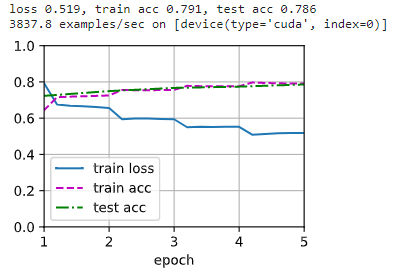
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,
devices)
- 1
- 2
- 3
- 4
- 5