
计算机视觉方向简介 | 三维重建技术概述
赞
踩
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达本文作者吴一达。
https://www.cnblogs.com/wuyida/p/6301262.html
基于视觉的三维重建,指的是通过摄像机获取场景物体的数据图像,并对此图像进行分析处理,再结合计算机视觉知识推导出现实环境中物体的三维信息。
(1)彩色图像与深度图像
彩色图像也叫作RGB图像,R、G、B三个分量对应于红、绿、蓝三个通道的颜色,它们的叠加组成了图像像素的不同灰度级。RGB颜色空间是构成多彩现实世界的基础。深度图像又被称为距离图像,与灰度图像中像素点存储亮度值不同,其像素点存储的是该点到相机的距离,即深度值。图2-1表示深度图像与灰度图像之间的关系。

图2-1 深度图像与灰度图像
Fig.2-1 The depth image and gray image
深度值指的目标物体与测量器材之间的距离。由于深度值的大小只与距离有关,而与环境、光线、方向等因素无关,所以深度图像能够真实准确的体现景物的几何深度信息。通过建立物体的空间模型,能够为深层次的计算机视觉应用提供更坚实的基础。
 图2-2 人物的彩色图像与深度图像
图2-2 人物的彩色图像与深度图像
Fig.2-2 Color image and depth image of the characters
(2)PCL
PCL(Point Cloud Library,点云库)是由斯坦福大学的Dr.Radu等学者基于ROS(Robot Operating System,机器人操作系统)下开发与维护的开源项目,最初被用来辅助机器人传感、认知和驱动等领域的开发。2011年PCL正式向公众开放。随着对三维点云算法的加入与扩充,PCL逐步发展为免费、开源、大规模、跨平台的C++编程库。
PCL框架包括很多先进的算法和典型的数据结构,如滤波、分割、配准、识别、追踪、可视化、模型拟合、表面重建等诸多功能。能够在各种操作系统和大部分嵌入式系统上运行,具有较强的软件可移植性。鉴于PCL的应用范围非常广,专家学者们对点云库的更新维护也非常及时。PCL的发展时至今日,已经来到了1.7.0版本。相较于早期的版本,加入了更多新鲜、实用、有趣的功能,为点云数据的利用提供了模块化、标准化的解决方案。再通过诸如图形处理器、共享存储并行编程、统一计算设备架构等领先的高性能技术,提升PCL相关进程的速率,实现实时性的应用开发。
在算法方面,PCL是一套包括数据滤波、点云配准、表面生成、图像分割和定位搜索等一系列处理点云数据的算法。基于不同类型区分每一套算法,以此把整合所有三维重建流水线功能,保证每套算法的紧凑性、可重用性与可执行性。例如PCL中实现管道运算的接口流程:
①创建处理对象,例如滤波、特征估计、图像分割等;
②通过setInputCloud输入初始点云数据,进入处理模块;
③设置算法相关参数;
④调用不同功能的函数实现运算,并输出结果。
为了实现模块化的应用与开发,PCL被细分成多组独立的代码集合。因此便可方便快捷的应用于嵌入式系统中,实现可移植的单独编译。如下列举了部分常用的算法模块:
libpcl I/O:完成数据的输入、输出过程,如点云数据的读写;
libpcl filters:完成数据采样、特征提取、参数拟合等过程;
libpcl register:完成深度图像的配准过程,例如迭代最近点算法;
libpcl surface:完成三维模型的表面生成过程,包括三角网格化、表面平滑等。
此类常用的算法模块均具有回归测试功能,以确保使用过程中没有引进错误。测试一般由专门的机构负责编写用例库。检测到回归错误时,会立即将消息反馈给相应的作者。因此能提升PCL和整个系统的安全稳定性。
(3)点云数据
如图2-3所示,展示了典型的点云数据(Point Cloud Data,PCD)模型。
 图2-3 点云数据及其放大效果
图2-3 点云数据及其放大效果
点云数据通常出现在逆向工程中,是由测距设备获取的物体表面的信息集合。其扫描资料以点的形式进行记录,这些点既可以是三维坐标,也可以是颜色或者光照强度等信息。通常所使用的点云数据一般包括点坐标精度、空间分辨率和表面法向量等内容。点云一般以PCD格式进行保存,这种格式的点云数据可操作性较强,同时能够提高点云配准融合的速度。本文研究的点云数据为非结构化的散乱点云,属于三维重建特有的点云特点。
(4)坐标系
在三维空间中,所有的点必须以坐标的形式来表示,并且可以在不同的坐标系之间进行转换。首先介绍基本坐标系的概念、计算及相互关系。
①图像坐标系
图像坐标系分为像素和物理两个坐标系种类。数字图像的信息以矩阵形式存储,即一副像素的图像数据存储在维矩阵中。图像像素坐标系以为原点、以像素为基本单位,U、V分别为水平、垂直方向轴。图像物理坐标系以摄像机光轴与图像平面的交点作为原点、以米或毫米为基本单位,其X、Y轴分别与U、V轴平行。图2-4展示的是两种坐标系之间的位置关系:
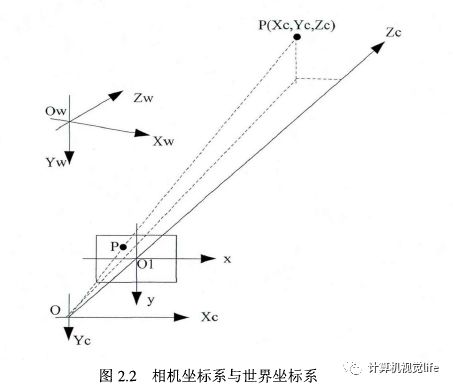 图2-4 图像像素坐标系与物理坐标系
图2-4 图像像素坐标系与物理坐标系
Fig.2-4 Image pixel coordinate system and physical coordinate system
令U-V坐标系下的坐标点(u0,v0),与代表像素点在X轴与Y轴上的物理尺寸。那么图像中的所有像素点在U-V坐标系与在X-Y坐标系下的坐标间有着如式(2-1)表示的关系: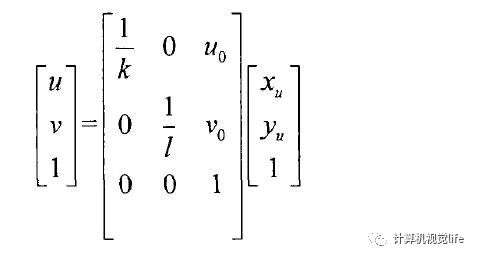
其中指的是图像坐标系的坐标轴倾斜相交而形成的倾斜因子(Skew Factor)。
②摄像机坐标系
摄像机坐标系由摄像机的光心及三条、、轴所构成。它的、轴对应平行于图像物理坐标系中的、轴,轴为摄像机的光轴,并与由原点、、轴所组成的平面垂直。如图2-5所示:
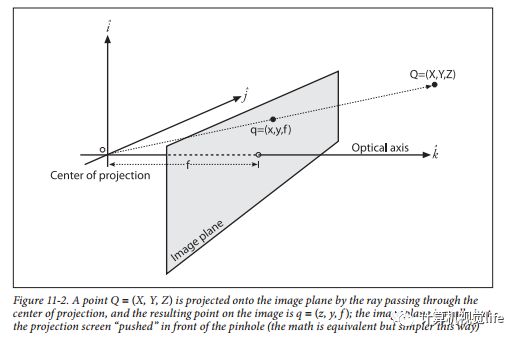 图2-5摄像机坐标系
图2-5摄像机坐标系
令摄像机的焦距是f,则图像物理坐标系中的点与摄像机坐标系中的点的关系为:
③世界坐标系
考虑到摄像机位置具有不确定性,因此有必要采用世界坐标系来统一摄像机和物体的坐标关系。世界坐标系由原点及、、三条轴组成。世界坐标与摄像机坐标间有着(2-3)所表达的转换关系:


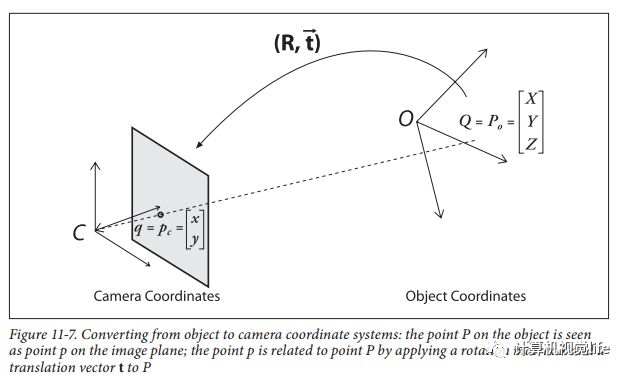
( 23 )
其中,是旋转矩阵,代表摄像机在世界坐标系下的指向;是平移向量,代表了摄像机的位置。
本文使用Kinect采集景物的点云数据,经过深度图像增强、点云计算与配准、数据融合、表面生成等步骤,完成对景物的三维重建。
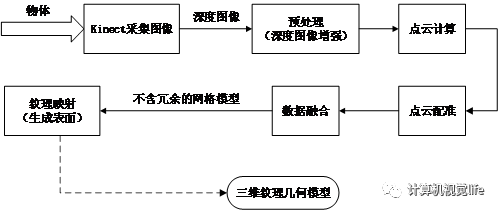 图2-6 基于深度传感器的三维重建流程图
图2-6 基于深度传感器的三维重建流程图
Fig.2-6 Flow chart of 3D reconstruction based on depth sensor
图2-6显示的流程表明,对获取到的每一帧深度图像均进行前六步操作,直到处理完若干帧。最后完成纹理映射。下面对每个步骤作详细的说明。
2.1 深度图像的获取
景物的深度图像由Kinect在Windows平台下拍摄获取,同时可以获取其对应的彩色图像。为了获取足够多的图像,需要变换不同的角度来拍摄同一景物,以保证包含景物的全部信息。具体方案既可以是固定Kinect传感器来拍摄旋转平台上的物体;也可以是旋转Kinect传感器来拍摄固定的物体。价格低廉、操作简单的深度传感器设备能够获取实时的景物深度图像,极大的方便了人们的应用。
2.2 预处理
受到设备分辨率等限制,它的深度信息也存在着许多缺点。为了更好的促进后续基于深度图像的应用,必须对深度图像进行去噪和修复等图像增强过程。作为本文的重点问题,具体的处理方法将在第四章进行详细的解释说明。
2.3 点云计算
经过预处理后的深度图像具有二维信息,像素点的值是深度信息,表示物体表面到Kinect传感器之间的直线距离,以毫米为单位。以摄像机成像原理为基础,可以计算出世界坐标系与图像像素坐标系之间具有下式的转换关系:
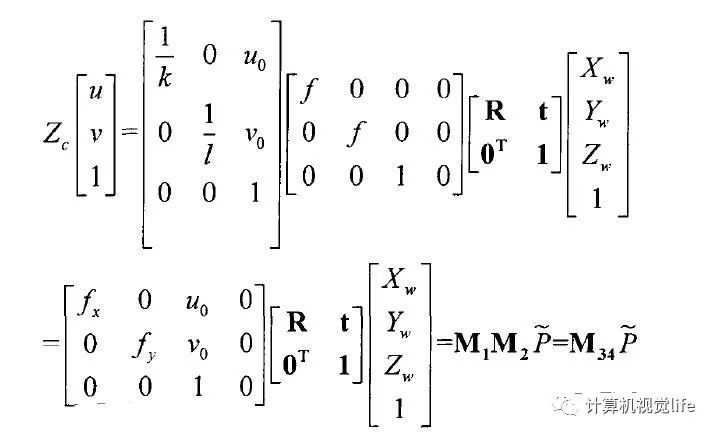

则k值只与有关,而等参数只与摄像机的内部构造有关,所以称为像机的内参数矩阵。以摄像机作为世界坐标系,即,则深度值即为世界坐标系中的值,与之对应的图像坐标就是图像平面的点。
2.4 点云配准
对于多帧通过不同角度拍摄的景物图像,各帧之间包含一定的公共部分。为了利用深度图像进行三维重建,需要对图像进行分析,求解各帧之间的变换参数。深度图像的配准是以场景的公共部分为基准,把不同时间、角度、照度获取的多帧图像叠加匹配到统一的坐标系中。计算出相应的平移向量与旋转矩阵,同时消除冗余信息。点云配准除了会制约三维重建的速度,也会影响到最终模型的精细程度和全局效果。因此必须提升点云配准算法的性能。
三维深度信息的配准按不同的图像输入条件与重建输出需求被分为:粗糙配准、精细配准和全局配准等三类方法。
(1)粗糙配准(Coarse Registration)
粗糙配准研究的是多帧从不同角度采集的深度图像。首先提取两帧图像之间的特征点,这种特征点可以是直线、拐点、曲线曲率等显式特征,也可以是自定义的符号、旋转图形、轴心等类型的特征。
随后根据特征方程实现初步的配准。粗糙配准后的点云和目标点云将处于同一尺度(像素采样间隔)与参考坐标系内,通过自动记录坐标,得到粗匹配初始值。
(2)精细配准(Fine Registration)
精细配准是一种更深层次的配准方法。经过前一步粗配准,得到了变换估计值。将此值作为初始值,在经过不断收敛与迭代的精细配准后,达到更加精准的效果。以经典的由Besl和Mckay[49]提出的ICP(Iterative Closest Point,迭代最近点)算法为例,该算法首先计算初始点云上所有点与目标点云的距离,保证这些点和目标点云的最近点相互对应,同时构造残差平方和的目标函数。
基于最小二乘法对误差函数进行最小化处理,经过反复迭代,直到均方误差小于设定的阈值。ICP算法能够获得精正确无误的配准结果,对自由形态曲面配准问题具有重要意义。另外还有如SAA(Simulate Anneal Arithmetic,模拟退火)算法、GA(Genetic Algorithm,遗传)算法等也有各自的特点与使用范畴。
(3)全局配准(Global Registration)
全局配准是使用整幅图像直接计算转换矩阵。通过对两帧精细配准结果,按照一定的顺序或一次性的进行多帧图像的配准。这两种配准方式分别称为序列配准(Sequential Registration)和同步配准(Simultaneous Registration)。
配准过程中,匹配误差被均匀的分散到各个视角的多帧图像中,达到削减多次迭代引起的累积误差的效果。值得注意的是,虽然全局配准可以减小误差,但是其消耗了较大的内存存储空间,大幅度提升了算法的时间复杂度。
2.5 数据融合
经过配准后的深度信息仍为空间中散乱无序的点云数据,仅能展现景物的部分信息。因此必须对点云数据进行融合处理,以获得更加精细的重建模型。以Kinect传感器的初始位置为原点构造体积网格,网格把点云空间分割成极多的细小立方体,这种立方体叫做体素(Voxel)。通过为所有体素赋予SDF(Signed Distance Field,有效距离场)值,来隐式的模拟表面。
SDF值等于此体素到重建表面的最小距离值。当SDF值大于零,表示该体素在表面前;当SDF小于零时,表示该体素在表面后;当SDF值越接近于零,表示该体素越贴近于场景的真实表面。KinectFusion技术虽然对场景的重建具有高效实时的性能,但是其可重建的空间范围却较小,主要体现在消耗了极大的空间用来存取数目繁多的体素。
为了解决体素占用大量空间的问题,Curless[50]等人提出了TSDF (Truncated Signed Distance Field,截断符号距离场)算法,该方法只存储距真实表面较近的数层体素,而非所有体素。因此能够大幅降低KinectFusion的内存消耗,减少模型冗余点。
 图2-7 基于空间体的点云融合
图2-7 基于空间体的点云融合
TSDF算法采用栅格立方体代表三维空间,每个栅格中存放的是其到物体表面的距离。TSDF值的正负分别代表被遮挡面与可见面,而表面上的点则经过零点,如图2-7中左侧展示的是栅格立方体中的某个模型。若有另外的模型进入立方体,则按照下式(2-9)与(2-10)实现融合处理。
其中,指的是此时点云到栅格的距离,是栅格的初始距离,是用来对同一个栅格距离值进行融合的权重。如图2-7中右侧所示,两个权重之和为新的权重。对于KinectFusion算法而言,当前点云的权重值设置为1。
鉴于TSDF算法采用了最小二乘法进行了优化,点云融合时又利用了权重值,所有该算法对点云数据有着明显的降噪功能。
2.6 表面生成
表面生成的目的是为了构造物体的可视等值面,常用体素级方法直接处理原始灰度体数据。Lorensen[51]提出了经典体素级重建算法:MC(Marching Cube,移动立方体)法。移动立方体法首先将数据场中八个位置相邻的数据分别存放在一个四面体体元的八个顶点处。对于一个边界体素上一条棱边的两个端点而言,当其值一个大于给定的常数T,另一个小于T时,则这条棱边上一定有等值面的一个顶点。
然后计算该体元中十二条棱和等值面的交点,并构造体元中的三角面片,所有的三角面片把体元分成了等值面内与等值面外两块区域。最后连接此数据场中的所有体元的三角面片,构成等值面。合并所有立方体的等值面便可生成完整的三维表面。
Kinect等深度传感器的出现,不仅给娱乐应用带来了变革,同样对科学研究提供了新的方向。尤其是在三维重建领域。然而由于三维重建过程涉及到大量密集的点云数据处理,计算量巨大,所以对系统进行相应的性能优化显得非常的重要。本文采用基于GPU(Graphic Processing Unit,图形处理器)并行运算功能,以提高整体的运行效率。
NVIDIA公司于1999年提出了GPU概念。在这十几年间,依靠硬件行业的改革创新,芯片上晶体管数量持续增多,GPU性能以半年翻一番的速度成倍提升。GPU的浮点运算能力远超CPU上百倍,却具有非常低的能耗,极具性价比。因GPU不仅广泛应用于图形图像处理中,也在如视频处理、石油勘探、生物化学、卫星遥感数据分析、气象预报、数据挖掘等方面崭露头角。
作为GPU的提出者,NVIDIA公司一直致力于GPU性能提升的研究工作,并在2007年推出了CUDA架构。CUDA(Compute Unified Device Architecture,统一计算设备架构)是一种并行计算程序架构。在CUDA的支持下,使用者可以编写程序以利用NVIDIA系列GPU完成大规模并行计算。GPU在CUDA中被用作通用计算设备,而不只是处理图像。在CUDA中,将计算机CPU称为主机(Host),GPU称为设备(Device)。
主机端和设备端都有程序运行,主机端主要完成程序的流程与串行计算模块,而设备端则专门处理并行计算。其中,设备端的并行计算过程被记录在Kernel内核函数中,主机端可以从Kernel函数入口执行并行计算的调用功能。在此过程中,虽然Kernel函数执行同一代码,但却处理着不同的数据内容。
Kernel函数采用扩展的C语言来编程,称为CUDAC语言。需要注意的是,并不是所有的运算都可以采用CUDA并行计算。只有独立性的计算,如矩阵的加减,因为只涉及到对应下标的元素的加减,不同下标元素毫无关联,所以适用于并行计算;而对于如阶乘的计算则必须对所有数累积相乘,故无法采用并行计算。
CUDA具有线程(Thread)、程序块(Block)、网格(Grid)三级架构,计算过程一般由单一的网格完成,网格被平均分成多个程序块,每个程序块又由多个线程组成,最终由单个线程完成每个基本运算,如图2-8所示。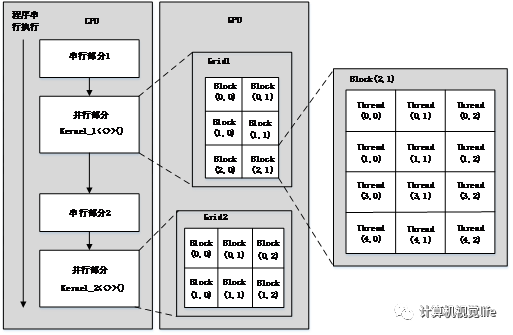 图2-8 CUDA模型
图2-8 CUDA模型
为了更深入的理解CUDA模型的计算过程,这里以前一章中提到的公式(2-11)为例,计算某点的深度值与三维坐标之间的转换: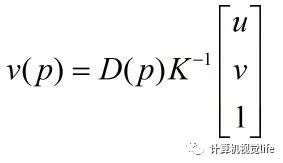 上式中的表示深度值,内参数矩阵是已知量,是该点的坐标。可以发现这个点的转换过程与其他点转换过程是相互独立的,所以整幅图像中各点的坐标转换能够并行执行。这种并行计算可以大幅提升整体计算的速率。例如,利用一个网格来计算一幅像素的深度图像到三维坐标的转换,只需要将此网格均分成块,每块包括个线程,每个线程分别操作一个像素点,便可以便捷的完成所有的坐标转换运算。
上式中的表示深度值,内参数矩阵是已知量,是该点的坐标。可以发现这个点的转换过程与其他点转换过程是相互独立的,所以整幅图像中各点的坐标转换能够并行执行。这种并行计算可以大幅提升整体计算的速率。例如,利用一个网格来计算一幅像素的深度图像到三维坐标的转换,只需要将此网格均分成块,每块包括个线程,每个线程分别操作一个像素点,便可以便捷的完成所有的坐标转换运算。
通过GPU的并行计算,三维重建性能得到了大幅的提升,实现了实时的输入输出。对于Kinect在实际生产生活中的应用奠定了基础。
首先介绍了与三维重建相关的基本概念,包括深度图像、点云数据、四种坐标系及其之间的转换关系等。
好消息!
小白学视觉知识星球
开始面向外开放啦 本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/238670
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

