
- 1ccs 移植创建新工程_LiteOS裸机驱动移植05 | E53_SF1智慧消防扩展板驱动及使用
- 2Android性能测试用例_高通 android设备的性能测试用例
- 3关于微信小程序的相关接口以及问题_微信小程序内部接口设计
- 4[Quant][Note] Empirical Asset Pricing via Machine Learning
- 5HarmonyOS ArkTS List组件和Grid组件的使用(五)_arkts的grid列表
- 6【NLP】第 18 章从零开始训练 Transformer_nlp transformer 从0开始
- 7Android 串口开发遇到的问题整合
- 8【深度学习】GPT-3_gpt-3 模型
- 9【小程序教程】微信小程序之条件渲染_微信小程序开发的条件渲染
- 10View&五大布局介绍_view布局
RNNoise原理部分(1)_rnnoise算法原理
赞
踩
论文:https://arxiv.org/pdf/1709.08243.pdf
官方博客链接:https://people.xiph.org/~jm/demo/rnnoise/?__s=sgkgganpatrhthvch4js
github:https://github.com/xiph/rnnoise
改进github:https://github.com/GregorR/rnnoise-nu
Introduce for RNNoise
Rnnoise是一种实时(低复杂度)全频带的语音增强(噪声抑制)方法,A hybrid DSP(signal process + Deep learning)
主要包含两部分:
-
信号处理
噪声抑制在信号处理技术中已经很成熟,但同时存在一些问题,信号处理中某些estimator算法的调参非常麻烦。
-
RNN
RNN的关键在R(recurrent,循环),R决定了它非常适合处理序列数据,而语音数据是一种时间序列数据。
RNNoise弥补了信号处理中调参的问题,采用学习参数的方式,总结如下:
-
keep all the basic signal processing that's needed anyway (not have a neural network attempt to emulate it)(保留基本信号处理的部分,而不是使用网络去模拟它)
-
let the neural network learn all the tricky parts that require endless tweaking next to the signal processing. (让神经网络去学习应该怎么微调其他难以调整的部分,如estimator)
-
RNNoise相比于直接使用RNN的端到端(直接输入语音,全部由网络计算得到降噪结果)方法计算复杂度小,所以多用于视频会议(video-conference)。
Architecture for RNNoise
系统框图
系统框架图如下所示:

其中最主要的两个部分为A和B,主要的噪声抑制在A部分完成。
噪声抑制原理(RNN模拟部分) 原声 - 噪声 = 降噪
常规的噪声抑制可概括为以下三步:
-
检测出信号包含的语音和噪声部分。
-
噪声部分通过噪声谱评估器计算出一个噪声谱特征(每个频域上的功率)。
-
噪声抑制 = 语音谱 - 噪声谱
为了避免产生过多神经元的问题,RNNoise使用RNN估算理想临界带增益,而非直接估算谱的大小,论文中说法为ideal critical band gains。采用22个频带的模式:
如上图,使用Opus 图中的第二个频带(因为低频时频带更宽,容易获得足够的数据)
对于每个频带来说,估算可用于信号的一个增益。(相当于一个22段的均衡器,改变每个的值来达到降低噪声,保留信号的一个功能)
RNN

-
其中的三部分便是噪声抑制的三步,将计算增益的三个部分全部由神经网络模拟,最关键的部分是图中的三个GRU(门控循环单元)。
-
GRU的作用是保证RNN的长期记忆性(序列中靠后的数据单元结果依赖靠前的数据单元,由于网络的传播性质,没有GRU时前层传到后层会有信息丢失)。
-
RNNoise使用GRU而非LSTM(也是一种记忆单元) 因为此实验中GRU性能好,且需要更少的资源。
关于增益
对于22个频带每一个估算的增益值都在[0, 1]中。对于增益的详细使用,论文中做如下解释:
对于每一个频带b在频率k下对于一个转换后的信号X可以估算一个能量E,
而增益便是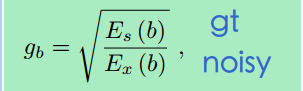
其中gt是标记数据的能量,noisy是噪声的能量。
概括的来说就是:RNN则是学习到最好的gb从而使得噪声的能量小。换一种理解方法,可以认为增益就是一个值,如果是噪声,就乘一个小的增益。如果不是,就乘一个大的增益。
关于架构中B部分pitch filter
由于我们采用22频带,频带分辨率过于粗糙,对于音调谐波( pitch harmonics)的噪声很难消除, 所以便有了这么一个滤波器。(非RNN部分,使用固定数学公式进行滤波,没有学习功能)
Dataset for RNNoise
-
数据至关重要,可以决定效果的好坏。
-
数据要求:
-
不能只收集 干净的语音/嘈杂的语音 两部分,因为很难获得具有相同内容的两部分。(需要从干净的语音和噪音的单独记录中人为的创建数据,难点在于获得各种各样的噪音来增加语音。)
-
还需要覆盖各种录制条件。(如,只是基于全带(0-20kHz)音频训练的版本在处理低频滤波产生的0-8kHz的音频是会出现错误。)
-
-
输入网络的是22个频段的频谱信息,因为音频有很大的动态范围,所以最好可以计算能量的对数值。
原理部分大概罗列如上,数据集具体格式接下来继续调研
一个开源语音数据集:

