- 1【项目实战】ASP.NET度假村景区订票系统-.net度假村酒店预约系统-源码-调试-文档报告
- 2【node】nvm安装node失败,使用淘宝镜像!_nvm node mirror
- 3ImageNet图像数据集介绍_imagenet数据集包含了多少幅图片
- 4软件质量评价指标_常用软件质量指标
- 5linux搭建mc服务器-linux搭建minecraft服务器-linux搭建我的世界服务器
- 6python分布式(scrapy-redis)实现对房天下全国二手房与新房的信息爬取(偏小白,有源码有分析)_爬取房天下数据
- 7【计算机开题报告】基于互联网的音乐电影分享系统的设计与实现(前端)
- 8自己搭建远程桌面服务器-RustDesk(小白版)
- 9Quake4多人def_人 def
- 10一招搞定nas 的远程访问问题_群晖电脑网页远程访问不了手机能远程访问
如何在本地部署运行ChatGLM-6B_chatglm-6b本地部署
赞
踩
在本篇技术博客中,将展示如何在本地获取运行代码和模型,并配置环境以及 Web GUI,最后通过 Gradio 的网页版 Demo 进行聊天。
官方介绍
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答,更多信息请参考我们的博客。
为了方便下游开发者针对自己的应用场景定制模型,我们同时实现了基于 P-Tuning v2 的高效参数微调方法 (使用指南) ,INT4 量化级别下最低只需 7GB 显存即可启动微调。
不过,由于 ChatGLM-6B 的规模较小,目前已知其具有相当多的局限性,如事实性/数学逻辑错误,可能生成有害/有偏见内容,较弱的上下文能力,自我认知混乱,以及对英文指示生成与中文指示完全矛盾的内容。请大家在使用前了解这些问题,以免产生误解。更大的基于 1300 亿参数 GLM-130B 的 ChatGLM 正在内测开发中。
获取运行代码
首先,您需要从 GitHub 仓库下载 ChatGLM-6B 的代码。您可以使用以下链接进行下载:GitHub - THUDM/ChatGLM-6B: ChatGLM-6B: An Open Bilingual Dialogue Language Model | 开源双语对话语言模型。
将仓库下载到本地任意位置(例如 D:/codehub/ChatGLM-6B)。
获取模型
接下来,您需要从 Hugging Face 下载 ChatGLM-6B 模型。您可以使用以下链接进行下载:
- chatglm-6b:THUDM/chatglm-6b · Hugging Face
- chatglm-6b-int8:THUDM/chatglm-6b-int8 · Hugging Face
- chatglm-6b-int4:THUDM/chatglm-6b-int4 · Hugging Face
将模型下载到本地任意位置(例如 D:/codehub/models)。
硬件需求
| 量化等级 | 最低 GPU 显存 (推理) | 最低 GPU 显存 (高效参数微调) |
| FP16(无量化) | 13 GB | 14 GB |
| INT8 | 8 GB | 9 GB |
| INT4 | 6 GB | 7 GB |
环境配置
在开始使用 ChatGLM-6B 进行聊天之前,您需要进行环境配置。下面是必要的步骤:
- 安装 Python3。
- 安装 ChatGLM-6B 运行所需要的 Python 组件依赖。在命令行中进入 ChatGLM-6B 文件夹(例如 cd D:/codehub/ChatGLM-6B),并运行以下命令:
pip install -r requirements.txt- 安装 GPU 版本的 PyTorch。由于通过 requirements.txt 中的 PyTorch 默认下载的是 CPU 版本,如果您想使用 GPU 运行模型,您需要先卸载并安装 GPU 版本的 PyTorch。您可以从 PyTorch 官网(PyTorch)下载本地环境对应的 PyTorch。
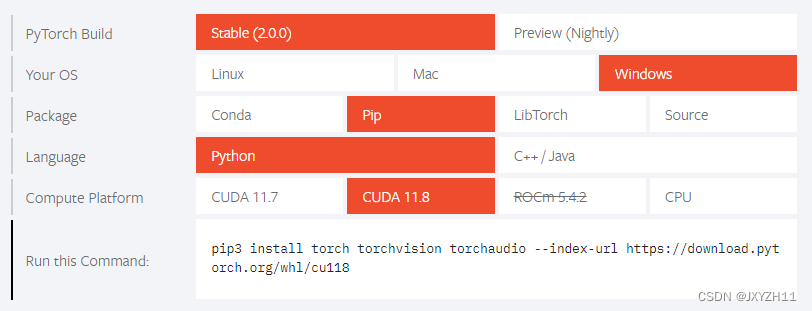
例如,在 Windows 10 上安装 CUDA 版本为 11.8 的 PyTorch,可以运行以下命令:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118- 安装 NVIDIA CUDA 工具包。您可以从 CUDA 官方下载地址(CUDA Toolkit Archive | NVIDIA Developer)下载本地环境对应的CUDA版本。请注意确保选择和 PyTorch 对应的 CUDA 版本,否则 PyTorch 将无法正常运行。

配置 WebUI 并运行
最后,我们需要配置 WebUI 并运行 Gradio 的网页版 Demo。请按照以下步骤操作:
- 安装 Gradio 依赖。在命令行中输入以下命令:
pip install gradio- 指定本地的模型文件夹路径
编辑 ChatGLM-6B 仓库中的 web_demo.py 文件,并将以下代码中的 "THUDM/chatglm-6b" 修改为本地模型所在文件夹的路径(例如:这里使用chatglm-6b-int4量化模型,路径则填D:\\codehub\models\chatglm-6b-int4)
- tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
- model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
如果不进行修改,程序会自动从 Hugging Face 下载模型并加载到 C 盘。
- 运行 WebUI。在命令行中进入 ChatGLM-6B 文件夹,并运行以下命令:
python web_demo.py至此,您已经成功配置了环境,并准备好使用 ChatGLM-6B 进行聊天了!