
热门标签
热门文章
- 1交换机trunk接口发送数据时,数据帧tag和pvid相同和不相同时的区别_port trunk pvid vlan 10
- 2javaWeb项目发布到linux服务器上以及运行项目_javaweb打包到linux运行
- 3compose--附带效应、传统项目集成、导航_remembercoroutinescope
- 4用卷积神经网络(CNN)中的卷积核(过滤器)提取图像特征_cnn提取图像特征
- 5event trigger php,微信小程序 this.triggerEvent()的具体使用
- 6keras: 用time series时间序列做预测_timeseries_dataset_from_array
- 7电动车进电梯监测报警摄像机助力提升安全管理
- 8ChatGPT 可替代?以下7 种 AI 工具更专注于编码
- 9【手游联运平台搭建】游戏平台的作用
- 10安卓获取APP对应的Android id的原理分析_android_id和应用有关吧
当前位置: article > 正文
lightGBM使用案例_lightgbm示例
作者:盐析白兔 | 2024-03-17 21:27:28
赞
踩
lightgbm示例
xgboost:https://www.analyticsvidhya.com/blog/2016/03/complete-guide-parameter-tuning-xgboost-with-codes-python/
- #!/usr/bin/env python2
- # -*- coding: utf-8 -*-
- """
- Created on Sat Mar 31 21:19:09 2018
- @author: hello4720
- """
- import numpy as np
- import pandas as pd
- import lightgbm as lgb
- from sklearn import metrics
- from sklearn.model_selection import train_test_split
-
- ### 读取数据
- print("载入数据")
- dataset1 = pd.read_csv('G:/ML/ML_match/IJCAI/data3.22/3.22ICJAI/data/7_train_data1.csv')
- dataset2 = pd.read_csv('G:/ML/ML_match/IJCAI/data3.22/3.22ICJAI/data/7_train_data2.csv')
- dataset3 = pd.read_csv('G:/ML/ML_match/IJCAI/data3.22/3.22ICJAI/data/7_train_data3.csv')
- dataset4 = pd.read_csv('G:/ML/ML_match/IJCAI/data3.22/3.22ICJAI/data/7_train_data4.csv')
- dataset5 = pd.read_csv('G:/ML/ML_match/IJCAI/data3.22/3.22ICJAI/data/7_train_data5.csv')
-
- dataset1.drop_duplicates(inplace=True)
- dataset2.drop_duplicates(inplace=True)
- dataset3.drop_duplicates(inplace=True)
- dataset4.drop_duplicates(inplace=True)
- dataset5.drop_duplicates(inplace=True)
-
- ### 数据合并
- print("数据合并")
- trains = pd.concat([dataset1,dataset2],axis=0)
- trains = pd.concat([trains,dataset3],axis=0)
- trains = pd.concat([trains,dataset4],axis=0)
-
- online_test = dataset5
-
- ### 数据拆分
- print("数据拆分")
- train_xy,offline_test = train_test_split(trains, test_size = 0.2,random_state=21)
- train,val = train_test_split(train_xy, test_size = 0.2,random_state=21)
-
- print("训练集")
- y = train.is_trade # 训练集标签
- X = train.drop(['instance_id','is_trade'],axis=1) # 训练集特征矩阵
-
- print("验证集")
- val_y = val.is_trade # 验证集标签
- val_X = val.drop(['instance_id','is_trade'],axis=1) # 验证集特征矩阵
-
- print("测试集")
- offline_test_X=offline_test.drop(['instance_id','is_trade'],axis=1) # 线下测试特征矩阵
- online_test_X=online_test.drop(['instance_id'],axis=1) # 线上测试特征矩阵
-
- ### 数据转换
- lgb_train = lgb.Dataset(X, y, free_raw_data=False)
- lgb_eval = lgb.Dataset(val_X, val_y, reference=lgb_train,free_raw_data=False)
-
- ### 开始训练
- print('设置参数')
- params = {
- 'boosting_type': 'gbdt',
- 'boosting': 'dart',
- 'objective': 'binary',
- 'metric': 'binary_logloss',
-
- 'learning_rate': 0.01,
- 'num_leaves':25,
- 'max_depth':3,
-
- 'max_bin':10,
- 'min_data_in_leaf':8,
-
- 'feature_fraction': 0.6,
- 'bagging_fraction': 1,
- 'bagging_freq':0,
-
- 'lambda_l1': 0,
- 'lambda_l2': 0,
- 'min_split_gain': 0
- }
-
- print("开始训练")
- gbm = lgb.train(params, # 参数字典
- lgb_train, # 训练集
- num_boost_round=2000, # 迭代次数
- valid_sets=lgb_eval, # 验证集
- early_stopping_rounds=30) # 早停系数
- ### 线下预测
- print ("线下预测")
- preds_offline = gbm.predict(offline_test_X, num_iteration=gbm.best_iteration) # 输出概率
- offline=offline_test[['instance_id','is_trade']]
- offline['preds']=preds_offline
- offline.is_trade = offline['is_trade'].astype(np.float64)
- print('log_loss', metrics.log_loss(offline.is_trade, offline.preds))
-
- ### 线上预测
- print("线上预测")
- preds_online = gbm.predict(online_test_X, num_iteration=gbm.best_iteration) # 输出概率
- online=online_test[['instance_id']]
- online['preds']=preds_online
- online.rename(columns={'preds':'predicted_score'},inplace=True)
- online.to_csv("./data/20180405.txt",index=None,sep=' ')
-
- ### 保存模型
- from sklearn.externals import joblib
- joblib.dump(gbm,'gbm.pkl')
-
- ### 特征选择
- df = pd.DataFrame(X.columns.tolist(), columns=['feature'])
- df['importance']=list(gbm.feature_importance())
- df = df.sort_values(by='importance',ascending=False)
- df.to_csv("./data/feature_score_20180405.csv",index=None,encoding='gbk')

调参案例
lightgbm使用leaf_wise tree生长策略,leaf_wise_tree的优点是收敛速度快,缺点是容易过拟合。
# lightgbm关键参数
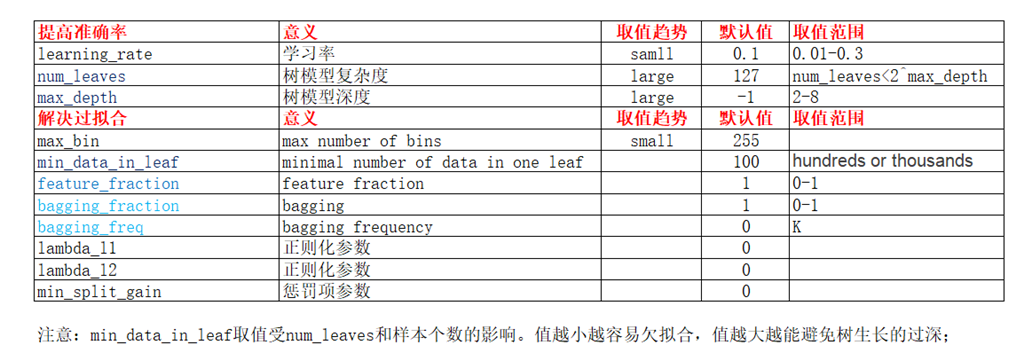
- # -*- coding: utf-8 -*-
- """
- # 作者:wanglei5205
- # 邮箱:wanglei5205@126.com
- # 博客:http://cnblogs.com/wanglei5205
- # github:http://github.com/wanglei5205
- """
- ### 导入模块
- import numpy as np
- import pandas as pd
- import lightgbm as lgb
- from sklearn import metrics
-
- ### 载入数据
- print('载入数据')
- dataset1 = pd.read_csv('G:/ML/ML_match/IJCAI/data3.22/3.22ICJAI/data/7_train_data1.csv')
- dataset2 = pd.read_csv('G:/ML/ML_match/IJCAI/data3.22/3.22ICJAI/data/7_train_data2.csv')
- dataset3 = pd.read_csv('G:/ML/ML_match/IJCAI/data3.22/3.22ICJAI/data/7_train_data3.csv')
- dataset4 = pd.read_csv('G:/ML/ML_match/IJCAI/data3.22/3.22ICJAI/data/7_train_data4.csv')
- dataset5 = pd.read_csv('G:/ML/ML_match/IJCAI/data3.22/3.22ICJAI/data/7_train_data5.csv')
-
- print('数据去重')
- dataset1.drop_duplicates(inplace=True)
- dataset2.drop_duplicates(inplace=True)
- dataset3.drop_duplicates(inplace=True)
- dataset4.drop_duplicates(inplace=True)
- dataset5.drop_duplicates(inplace=True)
-
- print('数据合并')
- trains = pd.concat([dataset1,dataset2],axis=0)
- trains = pd.concat([trains,dataset3],axis=0)
- trains = pd.concat([trains,dataset4],axis=0)
-
- online_test = dataset5
-
- ### 数据拆分(训练集+验证集+测试集)
- print('数据拆分')
- from sklearn.model_selection import train_test_split
- train_xy,offline_test = train_test_split(trains,test_size = 0.2,random_state=21)
- train,val = train_test_split(train_xy,test_size = 0.2,random_state=21)
-
- # 训练集
- y_train = train.is_trade # 训练集标签
- X_train = train.drop(['instance_id','is_trade'],axis=1) # 训练集特征矩阵
-
- # 验证集
- y_val = val.is_trade # 验证集标签
- X_val = val.drop(['instance_id','is_trade'],axis=1) # 验证集特征矩阵
-
- # 测试集
- offline_test_X = offline_test.drop(['instance_id','is_trade'],axis=1) # 线下测试特征矩阵
- online_test_X = online_test.drop(['instance_id'],axis=1) # 线上测试特征矩阵
-
- ### 数据转换
- print('数据转换')
- lgb_train = lgb.Dataset(X_train, y_train, free_raw_data=False)
- lgb_eval = lgb.Dataset(X_val, y_val, reference=lgb_train,free_raw_data=False)
-
- ### 设置初始参数--不含交叉验证参数
- print('设置参数')
- params = {
- 'boosting_type': 'gbdt',
- 'objective': 'binary',
- 'metric': 'binary_logloss',
- }
-
- ### 交叉验证(调参)
- print('交叉验证')
- min_merror = float('Inf')
- best_params = {}
-
- # 准确率
- print("调参1:提高准确率")
- for num_leaves in range(20,200,5):
- for max_depth in range(3,8,1):
- params['num_leaves'] = num_leaves
- params['max_depth'] = max_depth
-
- cv_results = lgb.cv(
- params,
- lgb_train,
- seed=2018,
- nfold=3,
- metrics=['binary_error'],
- early_stopping_rounds=10,
- verbose_eval=True
- )
-
- mean_merror = pd.Series(cv_results['binary_error-mean']).min()
- boost_rounds = pd.Series(cv_results['binary_error-mean']).argmin()
-
- if mean_merror < min_merror:
- min_merror = mean_merror
- best_params['num_leaves'] = num_leaves
- best_params['max_depth'] = max_depth
-
- params['num_leaves'] = best_params['num_leaves']
- params['max_depth'] = best_params['max_depth']
-
- # 过拟合
- print("调参2:降低过拟合")
- for max_bin in range(1,255,5):
- for min_data_in_leaf in range(10,200,5):
- params['max_bin'] = max_bin
- params['min_data_in_leaf'] = min_data_in_leaf
-
- cv_results = lgb.cv(
- params,
- lgb_train,
- seed=42,
- nfold=3,
- metrics=['binary_error'],
- early_stopping_rounds=3,
- verbose_eval=True
- )
-
- mean_merror = pd.Series(cv_results['binary_error-mean']).min()
- boost_rounds = pd.Series(cv_results['binary_error-mean']).argmin()
-
- if mean_merror < min_merror:
- min_merror = mean_merror
- best_params['max_bin']= max_bin
- best_params['min_data_in_leaf'] = min_data_in_leaf
-
- params['min_data_in_leaf'] = best_params['min_data_in_leaf']
- params['max_bin'] = best_params['max_bin']
-
- print("调参3:降低过拟合")
- for feature_fraction in [0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0]:
- for bagging_fraction in [0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0]:
- for bagging_freq in range(0,50,5):
- params['feature_fraction'] = feature_fraction
- params['bagging_fraction'] = bagging_fraction
- params['bagging_freq'] = bagging_freq
-
- cv_results = lgb.cv(
- params,
- lgb_train,
- seed=42,
- nfold=3,
- metrics=['binary_error'],
- early_stopping_rounds=3,
- verbose_eval=True
- )
-
- mean_merror = pd.Series(cv_results['binary_error-mean']).min()
- boost_rounds = pd.Series(cv_results['binary_error-mean']).argmin()
-
- if mean_merror < min_merror:
- min_merror = mean_merror
- best_params['feature_fraction'] = feature_fraction
- best_params['bagging_fraction'] = bagging_fraction
- best_params['bagging_freq'] = bagging_freq
-
- params['feature_fraction'] = best_params['feature_fraction']
- params['bagging_fraction'] = best_params['bagging_fraction']
- params['bagging_freq'] = best_params['bagging_freq']
-
- print("调参4:降低过拟合")
- for lambda_l1 in [0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0]:
- for lambda_l2 in [0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0]:
- for min_split_gain in [0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0]:
- params['lambda_l1'] = lambda_l1
- params['lambda_l2'] = lambda_l2
- params['min_split_gain'] = min_split_gain
-
- cv_results = lgb.cv(
- params,
- lgb_train,
- seed=42,
- nfold=3,
- metrics=['binary_error'],
- early_stopping_rounds=3,
- verbose_eval=True
- )
-
- mean_merror = pd.Series(cv_results['binary_error-mean']).min()
- boost_rounds = pd.Series(cv_results['binary_error-mean']).argmin()
-
- if mean_merror < min_merror:
- min_merror = mean_merror
- best_params['lambda_l1'] = lambda_l1
- best_params['lambda_l2'] = lambda_l2
- best_params['min_split_gain'] = min_split_gain
-
- params['lambda_l1'] = best_params['lambda_l1']
- params['lambda_l2'] = best_params['lambda_l2']
- params['min_split_gain'] = best_params['min_split_gain']
-
-
- print(best_params)
-
- ### 训练
- params['learning_rate']=0.01
- lgb.train(
- params, # 参数字典
- lgb_train, # 训练集
- valid_sets=lgb_eval, # 验证集
- num_boost_round=2000, # 迭代次数
- early_stopping_rounds=50 # 早停次数
- )
-
- ### 线下预测
- print ("线下预测")
- preds_offline = lgb.predict(offline_test_X, num_iteration=lgb.best_iteration) # 输出概率
- offline=offline_test[['instance_id','is_trade']]
- offline['preds']=preds_offline
- offline.is_trade = offline['is_trade'].astype(np.float64)
- print('log_loss', metrics.log_loss(offline.is_trade, offline.preds))
-
- ### 线上预测
- print("线上预测")
- preds_online = lgb.predict(online_test_X, num_iteration=lgb.best_iteration) # 输出概率
- online=online_test[['instance_id']]
- online['preds']=preds_online
- online.rename(columns={'preds':'predicted_score'},inplace=True) # 更改列名
- online.to_csv("./data/20180405.txt",index=None,sep=' ') # 保存结果
-
- ### 保存模型
- from sklearn.externals import joblib
- joblib.dump(lgb,'lgb.pkl')
-
- ### 特征选择
- df = pd.DataFrame(X_train.columns.tolist(), columns=['feature'])
- df['importance']=list(lgb.feature_importance()) # 特征分数
- df = df.sort_values(by='importance',ascending=False) # 特征排序
- df.to_csv("./data/feature_score_20180331.csv",index=None,encoding='gbk') # 保存分数
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/258074
推荐阅读
相关标签

