
热门标签
热门文章
- 1tkz-euclide作图教程03 | 函数图像作图示例_tkzy03
- 2微信小程序详细介绍
- 3教室预约微信小程序系统设计与实现_预约教室ui设计
- 4Mac命令关闭代理设置_mac 关闭代理
- 5Java语言实现猜数字小游戏_java猜数字游戏代码
- 6Foxit PDF SDK 5.9.6 for ActiveX Crack_foxit reader sdk activex
- 7android 读取assets指定文件_获取assets getexternalfilesdir
- 8【JavaSE】多线程_flag{qohlfitiptbyvxux}
- 9Unity利用SMSSDK实现短信验证码(附源代码)_unity发送短信验证码验证
- 10GG哥亲测:GPT-4.0对比GPT-3.5。面对复杂任务GPT-3.5简直弱爆了!
当前位置: article > 正文
机器学习-Rain-in-Australia_机器学习 rain in australia
作者:盐析白兔 | 2024-03-20 07:25:48
赞
踩
机器学习 rain in australia
Rain-in-Australia
Machine learing by xgboost
项目旨在通过机器学习算法寻找一个有效而健壮的天气预测模型。
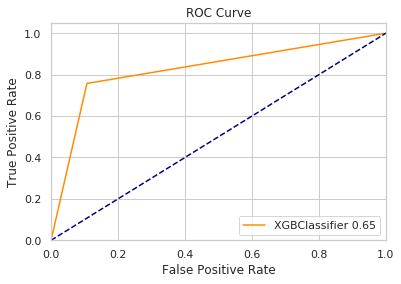
针对训练集及测试集中大量缺省值,项目使用具体城市具体特征median进行填充,从而避免对整体数据产生重大影响。针对数字项异常值,项目采用Winsorizing,将(0.25,0.75)外的值使用最值代替。项目对所给训练集的不同天气特征进行特征工程,以最大限度地从原始数据中提取特征以供算法和模型使用。地点特征工程是项目难点,而项目采用的是基于opencage API,将地点转为对应浮点型经纬度进行处理。对于模型参数,项目采用gridSearchCV网格搜索,指标设定为机器学习f1值,在优秀的GPU算力下进行长时间针对不同模型的调参工作。其结果表明XGBClassifier是最合适的模型。通过实际数据与预测数据进行比较,XGBClassifier在达到较高准确率时获得更好的召回率,进而实现f1值得提高。
#引入包 import time,json,joblib import pandas as pd import numpy as np from sklearn import metrics from sklearn.linear_model import LinearRegression,LogisticRegression from sklearn.ensemble import RandomForestClassifier from sklearn.svm import SVR from sklearn.preprocessing import StandardScaler from xgboost import XGBClassifier from sklearn.metrics import confusion_matrix, accuracy_score, f1_score, roc_auc_score, roc_curve from sklearn.model_selection import train_test_split,StratifiedKFold, GridSearchCV, cross_val_score import matplotlib.pyplot as plt import seaborn as sns sns.set(style="whitegrid") path = 'work/home/aistudio/data/data74989/'

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
#函数 将地点城市名称转为对应的经纬度 from opencage.geocoder import OpenCageGeocode def getGeCode(pot): key = 'xxxxxxxxxxxxxxxxxxxxxxx' #可从opencage官网获取 geocoder = OpenCageGeocode(key) query = pot + ',Australian' res = geocoder.geocode(query) if len(res) > 0: results = dict(res[0]) results = results['annotations'] results = results['DMS'] lat = str(results['lat']) lng = str(results['lng']) lat = lat.replace(lat[-1], '').replace(' ', '').replace('°', ' ').replace('\'', ' ').split(' ') lng = lng.replace(lng[-1], '').replace(' ', '').replace('°', ' ').replace('\'', ' ').split(' ') lat = (float(lat[0]) * 3600 + float(lat[1]) * 60 + float(lat[2])) lng = (float(lng[0]) * 3600 + float(lng[1]) * 60 + float(lng[2])) else: lat = None lng = None return ({ "lat": lat, "lng": lng })
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
导入数据集
# 导入数据集
train = pd.read_csv(path+'train.csv')
test = pd.read_csv(path+'test.csv')
len(train)
- 1
- 2
- 3
- 4
116368
- 1
查看一共多少个城市监测站
# 将不同的Location转为经纬度
list_Location = train['Location'].unique()
dic_Location = {}
for city in list_Location:
dic_Location[city] = getGeCode(city)
dic_Location
- 1
- 2
- 3
- 4
- 5
- 6
# 储存为json数据
with open(path+'city.json','w') as file_obj:
json.dump(dic_Location,file_obj)
- 1
- 2
- 3
# 从json数据读取
with open(path+'city.json','r') as file_obj:
dic_Location = json.load(file_obj)
dic_Location
- 1
- 2
- 3
- 4
{'Dartmoor': {'lat': 136489.6692, 'lng': 508280.13288}, 'Newcastle': {'lat': 135811.2276, 'lng': 521636.06376}, 'Albany': {'lat': 129916.49652, 'lng': 528874.47792}, 'Ballarat': {'lat': 135224.83836, 'lng': 517908.20796}, 'Uluru': {'lat': 135811.2276, 'lng': 521636.06376}, 'Bendigo': {'lat': 132282.31824, 'lng': 519328.575}, 'Cairns': {'lat': 119746.71576, 'lng': 416631.02688}, 'Townsville': {'lat': 69340.1058, 'lng': 528553.49112}, 'GoldCoast': {'lat': 100930.30272, 'lng': 552265.83936}, 'Sale': {'lat': 135160.70112, 'lng': 517657.9842}, 'PerthAirport': {'lat': 114960.18996, 'lng': 417483.31464}, 'NorahHead': {'lat': 135811.2276, 'lng': 521636.06376}, 'Watsonia': {'lat': 135656.98344, 'lng': 522255.68532}, 'Woomera': {'lat': 135811.2276, 'lng': 521636.06376}, 'NorfolkIsland': {'lat': 135811.2276, 'lng': 521636.06376}, 'Richmond': {'lat': 74630.54592, 'lng': 515315.13912}, 'Brisbane': {'lat': 98912.33316, 'lng': 550873.269}, 'Wollongong': {'lat': 123936.37956, 'lng': 543204.67248}, 'SydneyAirport': {'lat': 135811.2276, 'lng': 521636.06376}, 'Melbourne': {'lat': 136156.97952, 'lng': 521791.3098}, 'MelbourneAirport': {'lat': 135636.20388, 'lng': 521463.12156}, 'Nhil': {'lat': 135811.2276, 'lng': 521636.06376}, 'Sydney': {'lat': 121947.55164, 'lng': 544368.48012}, 'MountGinini': {'lat': 135811.2276, 'lng': 521636.06376}, 'Adelaide': {'lat': 125672.391, 'lng': 498935.76984}, 'MountGambier': {'lat': 136144.63764, 'lng': 506899.19592}, 'Mildura': {'lat': 127154.37096, 'lng': 536934.78}, 'Portland': {'lat': 137951.20116, 'lng': 509748.57288}, 'PearceRAAF': {'lat': 135811.2276, 'lng': 521636.06376}, 'Moree': {'lat': 106451.91, 'lng': 534761.98164}, 'Witchcliffe': {'lat': 122278.89672, 'lng': 414126.42732}, 'Walpole': {'lat': 135811.2276, 'lng': 521636.06376}, 'Cobar': {'lat': 119828.71908, 'lng': 416656.17684}, 'AliceSprings': {'lat': 135811.2276, 'lng': 521636.06376}, 'Albury': {'lat': 129916.49652, 'lng': 528874.47792}, 'Darwin': {'lat': 135811.2276, 'lng': 521636.06376}, 'BadgerysCreek': {'lat': 135811.2276, 'lng': 521636.06376}, 'Penrith': {'lat': 121567.60332, 'lng': 542466.62136}, 'CoffsHarbour': {'lat': 135811.2276, 'lng': 521636.06376}, 'Tuggeranong': {'lat': 127405.4454, 'lng': 537011.99568}, 'Hobart': {'lat': 154390.11624, 'lng': 530367.69132}, 'SalmonGums': {'lat': 135811.2276, 'lng': 521636.06376}, 'WaggaWagga': {'lat': 126384.91092, 'lng': 530530.12008}, 'Launceston': {'lat': 149157.42984, 'lng': 529685.52228}, 'Williamtown': {'lat': 136194.38496, 'lng': 521785.3284}, 'Nuriootpa': {'lat': 135811.2276, 'lng': 521636.06376}, 'Canberra': {'lat': 126937.6704, 'lng': 536880.28248}, 'Katherine': {'lat': 126595.97244, 'lng': 536862.31308}, 'Perth': {'lat': 115018.79832, 'lng': 417102.99876}}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
使用当前城市的中值填充其数字列
def drew_Histogram_of_fata(df,tag):
numerical = df._get_numeric_data().columns
# 绘图
fig, ax =plt.subplots(5,3, figsize=(30,35))
i=0;j=0;k=0
while i<=4:
while j<=2:
sns.distplot(df[numerical[k]], ax=ax[i, j])
j+=1;k+=1
j=0;i+=1;
plt.savefig(path+'处理缺省值'+tag+'分布.png')
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
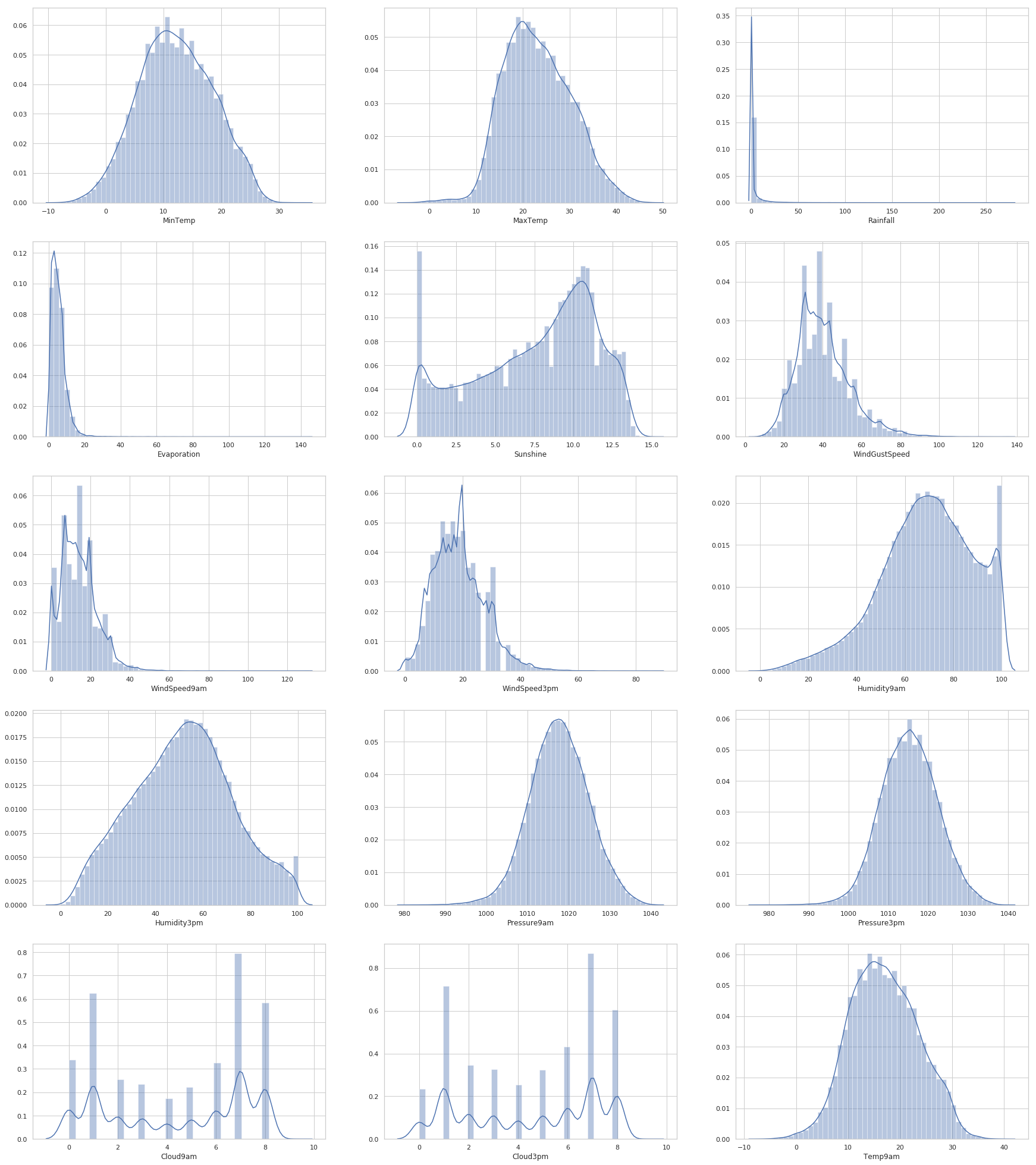
处理前分布
drew_Histogram_of_fata(df=train,tag='前')
- 1
def median_fill_null(df): # 获取是数字的列 numerical = df._get_numeric_data().columns # 不是数字的列 categorical = set(df.columns) - set(numerical) # 不同Location的序列 loc_for_miss = df["Location"].unique().tolist() # 储存中值的数据结构 ls = [] j=0 while j<=len(numerical)-1: for i in range(len(loc_for_miss)): #大量异常值使用中值.median() ls.append(str(df.loc[df["Location"] == loc_for_miss[i], numerical[j]].median())) for i in range(len(loc_for_miss)): df.loc[df["Location"] == loc_for_miss[i], numerical[j]] = df.loc[df["Location"] == \ loc_for_miss[i], numerical[j]].fillna(ls[i]) j+=1 df[numerical] = df[numerical].astype(float) return { 'df':df, 'numerical':numerical, 'categorical':categorical, 'loc_for_miss':loc_for_miss }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
# 使用字典保存全局数据结构
dict_train = median_fill_null(train)
- 1
- 2
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/numpy/lib/nanfunctions.py:1111: RuntimeWarning: Mean of empty slice
return np.nanmean(a, axis, out=out, keepdims=keepdims)
- 1
- 2
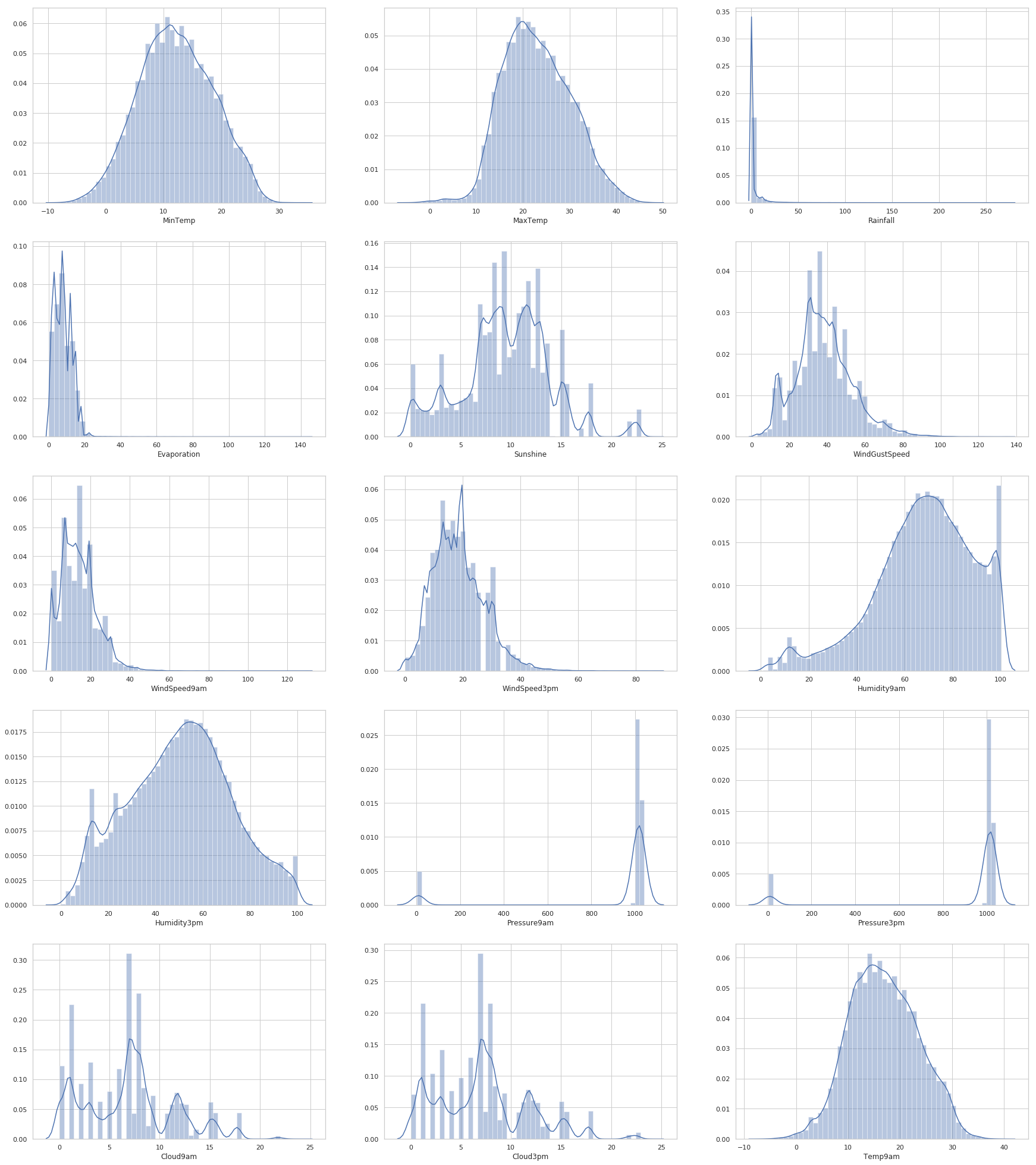
处理空值后分布
drew_Histogram_of_fata(df=dict_train['df'],tag='后')
- 1
检查数字列异常值
箱型图特征分析

def drow_box_of_numerical(dict_data,isAfter=False): num_of_rows = 4 num_of_cols = 4 df = dict_data['df'] numerical = dict_data['numerical'] fig, ax = plt.subplots(4, 4, figsize=(15,15)) i=0;j=0;k=0; while i<num_of_rows: while j<num_of_cols: sns.boxplot(df[numerical[k]], ax=ax[i, j]) k+=1;j+=1 j=0;i+=1 if isAfter: title = '去除数字列异常值后' else: title = '去除数字列异常值前' plt.savefig(path+title+'.png') plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
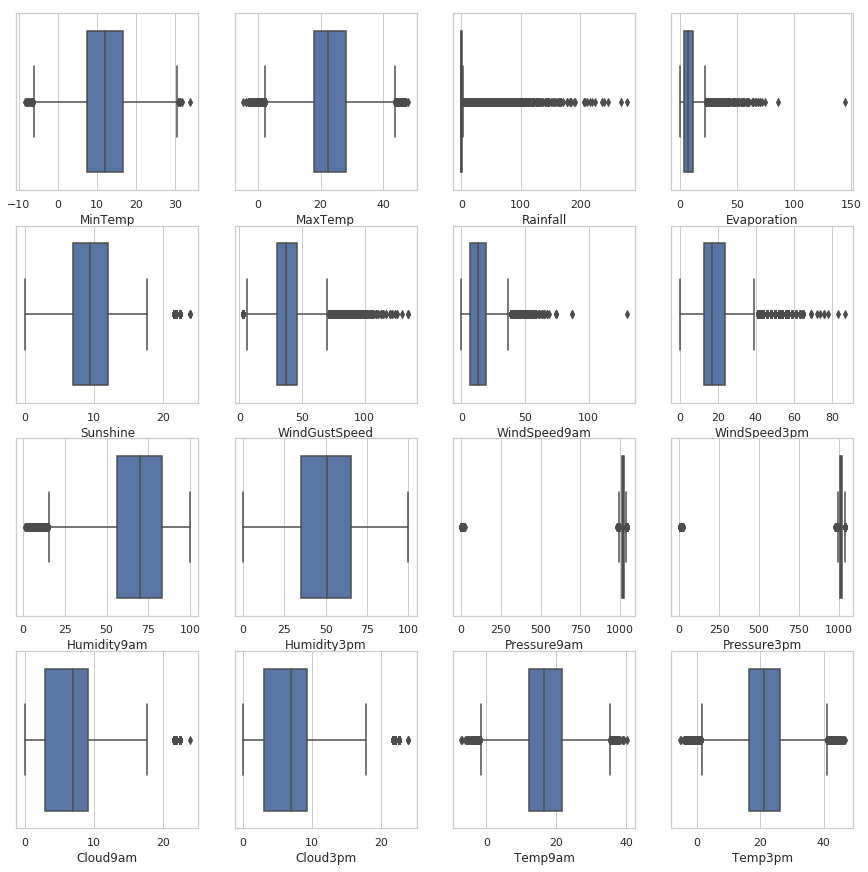
处理前
drow_box_of_numerical(dict_data=dict_train,isAfter=False)
- 1
def removeOutliers(dict_data): lsUpper = [] lsLower = [] df = dict_data['df'] numerical = dict_data['numerical'] for i in range(len(numerical)): # .quantile(0.25)分布数 q1 = df[numerical[i]].quantile(0.25) q3 = df[numerical[i]].quantile(0.75) IQR = q3-q1 minimum = q1 - 1.5 * IQR maximum = q3 + 1.5 * IQR df.loc[(df[numerical[i]] <= minimum), numerical[i]] = minimum df.loc[(df[numerical[i]] >= maximum), numerical[i]] = maximum dict_data['df'] = df return dict_data
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
dict_train = removeOutliers(dict_train)
- 1
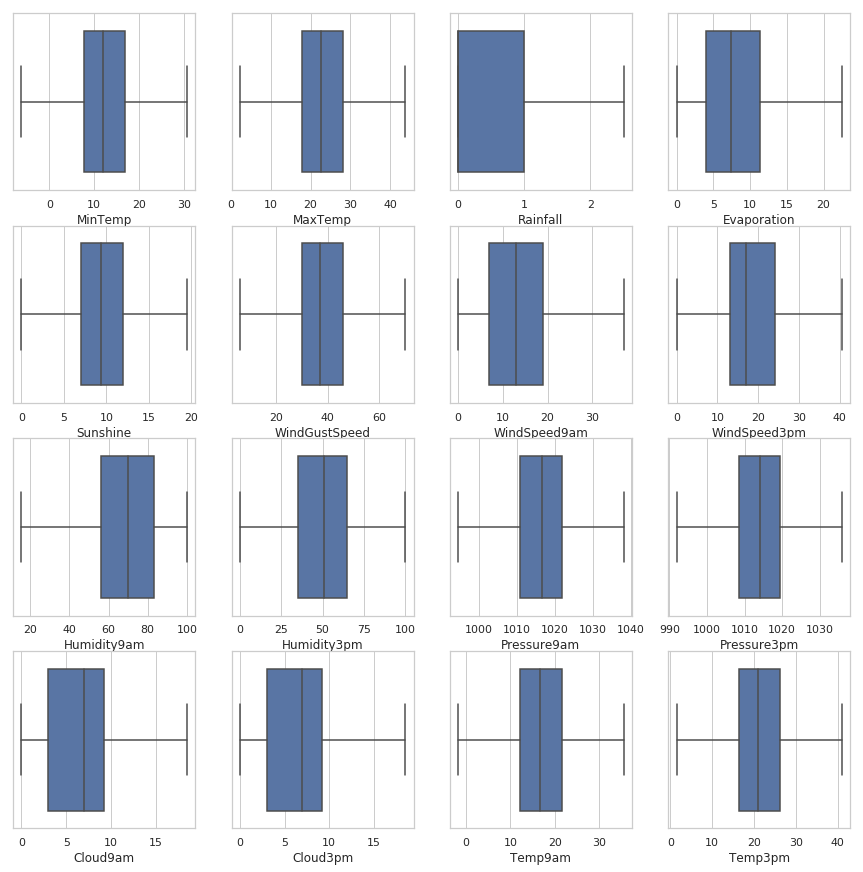
处理后
len(dict_train['df'])
- 1
116368
- 1
drow_box_of_numerical(dict_data=dict_train,isAfter=True)
- 1
特征工程
#函数 特征工程 def feature_engineering(data): # 将日期转换为年,月,日 data.insert(1, 'Year', 1, allow_duplicates=False) data.insert(1, 'Month', 1, allow_duplicates=False) data.insert(1, 'Day', 1, allow_duplicates=False) for i in range(len(data['Date'])): # 先转换为时间数组 try: timeArray = time.strptime(data['Date'].iloc[i], "%Y-%m-%d") except ValueError as e: timeArray = time.strptime(data['Date'].iloc[i], "%Y/%m/%d") data['Year'].iloc[i] =timeArray.tm_year data['Month'].iloc[i] =timeArray.tm_mon data['Day'].iloc[i] =timeArray.tm_mday #将地点城市名称转为对应的经纬度 # 从json数据读取 with open(path+'city.json','r') as file_obj: dic_Location = json.load(file_obj) data.insert(1, 'lat', 1, allow_duplicates=False) data.insert(1, 'lng', 1, allow_duplicates=False) for i in range(len(data['Location'])): item = data['Location'].iloc[i] data['lat'].iloc[i] = dic_Location[item]['lat'] data['lng'].iloc[i] = dic_Location[item]['lng'] # 列补充与列删除 data = data.drop(columns=["WindGustDir", "WindDir9am", "WindDir3pm", "Location", "Date"]) data["AveTemp"] = (data["MinTemp"] + data["MaxTemp"]) / 2 data["WindSpeed12pm"] = (data["WindSpeed3pm"] + data["WindSpeed9am"]) / 2 data["Humidity12pm"] = (data["Humidity3pm"] + data["Humidity9am"]) / 2 data["Pressure12pm"] = (data["Pressure3pm"] + data["Pressure9am"]) / 2 data["Cloud12pm"] = (data["Cloud3pm"] + data["Cloud9am"]) / 2 data["Temp12am"] = (data["Temp3pm"] + data["Temp9am"]) / 2 # 将天气转化成int 填充空值为0 try: data['RainTomorrow'].fillna('No', inplace = True) data['RainTomorrow'] = data['RainTomorrow'].map({'No':0, 'Yes':1}) # 调整列序 df_RainTomorrow = data['RainTomorrow'] data = data.drop('RainTomorrow', axis=1) data.insert(len(data.columns), 'RainTomorrow', df_RainTomorrow) except: pass data['RainToday'].fillna('No', inplace = True) data['RainToday'] = data['RainToday'].map({'No':0, 'Yes':1}) data.info() # 返回值pandas类型 return data
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
# 将第一次处理后的数据存储
train = feature_engineering(dict_train['df'])
train.to_csv(path+"temp_train_1.csv",index=False)
- 1
- 2
- 3
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/pandas/core/indexing.py:670: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy iloc._setitem_with_indexer(indexer, value) <class 'pandas.core.frame.DataFrame'> RangeIndex: 116368 entries, 0 to 116367 Data columns (total 29 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 lng 116368 non-null float64 1 lat 116368 non-null float64 2 Day 116368 non-null int64 3 Month 116368 non-null int64 4 Year 116368 non-null int64 5 MinTemp 116368 non-null float64 6 MaxTemp 116368 non-null float64 7 Rainfall 116368 non-null float64 8 Evaporation 116368 non-null float64 9 Sunshine 116368 non-null float64 10 WindGustSpeed 116368 non-null float64 11 WindSpeed9am 116368 non-null float64 12 WindSpeed3pm 116368 non-null float64 13 Humidity9am 116368 non-null float64 14 Humidity3pm 116368 non-null float64 15 Pressure9am 116368 non-null float64 16 Pressure3pm 116368 non-null float64 17 Cloud9am 116368 non-null float64 18 Cloud3pm 116368 non-null float64 19 Temp9am 116368 non-null float64 20 Temp3pm 116368 non-null float64 21 RainToday 116368 non-null int64 22 AveTemp 116368 non-null float64 23 WindSpeed12pm 116368 non-null float64 24 Humidity12pm 116368 non-null float64 25 Pressure12pm 116368 non-null float64 26 Cloud12pm 116368 non-null float64 27 Temp12am 116368 non-null float64 28 RainTomorrow 116368 non-null int64 dtypes: float64(24), int64(5) memory usage: 25.7 MB
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
train = pd.read_csv(path+"temp_train_1.csv")
train.info()
- 1
- 2
<class 'pandas.core.frame.DataFrame'> RangeIndex: 116368 entries, 0 to 116367 Data columns (total 29 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 lng 116368 non-null float64 1 lat 116368 non-null float64 2 Day 116368 non-null int64 3 Month 116368 non-null int64 4 Year 116368 non-null int64 5 MinTemp 116368 non-null float64 6 MaxTemp 116368 non-null float64 7 Rainfall 116368 non-null float64 8 Evaporation 116368 non-null float64 9 Sunshine 116368 non-null float64 10 WindGustSpeed 116368 non-null float64 11 WindSpeed9am 116368 non-null float64 12 WindSpeed3pm 116368 non-null float64 13 Humidity9am 116368 non-null float64 14 Humidity3pm 116368 non-null float64 15 Pressure9am 116368 non-null float64 16 Pressure3pm 116368 non-null float64 17 Cloud9am 116368 non-null float64 18 Cloud3pm 116368 non-null float64 19 Temp9am 116368 non-null float64 20 Temp3pm 116368 non-null float64 21 RainToday 116368 non-null int64 22 AveTemp 116368 non-null float64 23 WindSpeed12pm 116368 non-null float64 24 Humidity12pm 116368 non-null float64 25 Pressure12pm 116368 non-null float64 26 Cloud12pm 116368 non-null float64 27 Temp12am 116368 non-null float64 28 RainTomorrow 116368 non-null int64 dtypes: float64(24), int64(5) memory usage: 25.7 MB
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
找出效果最好的模型
# 分割测试集和训练集
train_n = np.asarray(train)
train_X = train_n[:,:-1].astype(float)
train_y = train_n[:,-1].astype(int)
train_X, test_X, train_y, test_y = train_test_split(train_X, train_y, train_size=0.7, random_state=0)
- 1
- 2
- 3
- 4
- 5
train_y
- 1
array([1, 0, 0, ..., 1, 0, 0])
- 1
得到f1
def get_f1(y_hat, y_true, THRESHOLD=0.5): # ''' # y_hat是未经过sigmoid函数激活的 # 输出的f1为Marco-F1 # ''' epsilon = 1e-7 y_hat = y_hat>THRESHOLD y_hat = np.int8(y_hat) tp = np.sum(y_hat*y_true, axis=0) fp = np.sum(y_hat*(1-y_true), axis=0) fn = np.sum((1-y_hat)*y_true, axis=0) p = tp/(tp+fp+epsilon)#epsilon的意义在于防止分母为0,否则当分母为0时python会报错 r = tp/(tp+fn+epsilon) f1 = 2*p*r/(p+r+epsilon) f1 = np.where(np.isnan(f1), np.zeros_like(f1), f1) return np.mean(f1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
绘制ROC曲线
def plot_curve(y_hat, y_true, name):
fpr,tpr, threshold = roc_curve(y_hat, y_true)
f1 = get_f1(y_hat, y_true)
plt.figure()
lw = 2
plt.plot(fpr, tpr, color='darkorange', label='{} {}'.format(name,np.round(f1,2)))
plt.plot([0, 1], [0, 1], color='navy', linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve')
plt.legend(loc="lower right")
plt.savefig(path+'roc__'+name+'.png')
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
XGBClassifier
start = time.time() model = XGBClassifier( learning_rate =0.01, n_estimators=346, gamma=1.1345, subsample=0.8, reg_alpha=0.005, objective= 'binary:logistic', nthread=4, scale_pos_weight=1, seed=27 ) parameters={ 'max_depth':range(2,10,1), 'min_child_weight':range(5, 21, 1), 'subsample':[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1], 'colsample_bytree':[0.5, 0.6, 0.7, 0.8, 0.9, 1], 'colsample_bylevel':[0.5, 0.6, 0.7, 0.8, 0.9, 1] } # 使用gpu parameters['tree_method'] = ['gpu_hist'] method=GridSearchCV(estimator= model,param_grid=parameters, cv=5,refit= True,scoring='f1_micro') # method = XGBC(n_estimators=346,gamma=1.1345) method.fit(train_X,train_y) res = method.predict(test_X) precision = 1-(np.sum(np.abs(res-test_y)) / len(res)) f1 = get_f1(res,test_y) end = time.time() print("运行时间 %.2f" %(end-start)) print("f1值 %.5f" %(f1))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
# 保存模型
joblib.dump(method, path+'XGBClassifier.model')
- 1
- 2
['work/home/aistudio/data/data74989/XGBClassifier.model']
- 1
# 模型加载
method = joblib.load(path+'XGBClassifier.model')
res = method.predict(test_X)
precision = 1-(np.sum(np.abs(res-test_y)) / len(res))
f1 = get_f1(res,test_y)
print("f1值 %.5f" %(f1))
- 1
- 2
- 3
- 4
- 5
- 6
f1值 0.83815
- 1
plot_curve(res,test_y,'XGBClassifier')
- 1
随机森林回归
# 随机森林回归
method = RandomForestClassifier(bootstrap= False, criterion= 'entropy', min_samples_split= 4, n_estimators= 200, random_state=0)
start = time.time()
method.fit(train_X,train_y)
res = method.predict(test_X)
precision = 1-(np.sum(np.abs(res-test_y)) / len(res))
f1 = get_f1(res,test_y)
end = time.time()
print("运行时间 %.2f" %(end-start))
print("f1值 %.5f" %(f1))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
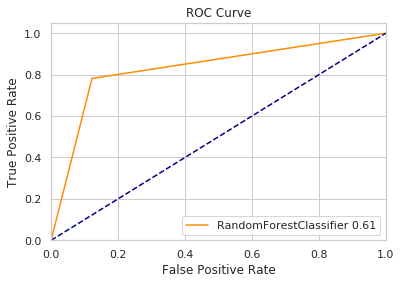
运行时间 39.72
f1值 0.61063
- 1
- 2
plot_curve(res,test_y,'RandomForestClassifier')
- 1
线性回归
# 线性回归
method = LinearRegression()
start = time.time()
method.fit(train_X,train_y)
res = method.predict(test_X).astype('int')
precision = 1-(np.sum(np.abs(res-test_y)) / len(res))
f1 = get_f1(res,test_y)
end = time.time()
print("运行时间 %.2f" %(end-start))
print("f1值 %.5f" %(f1))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
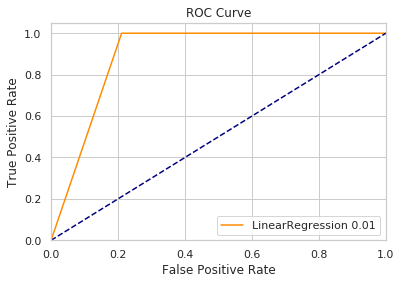
运行时间 0.12
f1值 0.01210
- 1
- 2
plot_curve(res,test_y,'LinearRegression')
- 1
SVC
# SVC from sklearn.svm import SVC # for kernel in ["linear","poly","rbf","sigmoid"]: for kernel in ["linear"]: method = SVC(kernel = kernel ,gamma="auto" ,degree = 1 ,cache_size = 5000 ,class_weight = {1:10} # "1"类的样本权重为10,隐含"0"类的样本权重为1 ) start = time.time() method.fit(train_X,train_y) res = method.predict(test_X) precision = 1-(np.sum(np.abs(res-test_y)) / len(res)) f1 = get_f1(res,test_y) end = time.time() print("运行时间 %.2f" %(end-start)) print("f1值 %.5f" %(f1))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
test_y
- 1
array([0, 0, 0, ..., 0, 1, 0])
- 1
逻辑斯蒂回归
# 逻辑斯蒂回归
method = LogisticRegression(max_iter=5000)
start = time.time()
method.fit(train_X,train_y)
res = method.predict(test_X).astype(int)
precision = 1-(np.sum(np.abs(res-test_y)) / len(res))
f1 = get_f1(res,test_y)
end = time.time()
print("运行时间 %.2f" %(end-start))
print("f1值 %.5f" %(f1))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
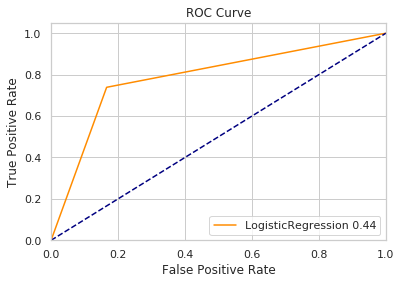
运行时间 4.99
f1值 0.43874
- 1
- 2
plot_curve(res,test_y,'LogisticRegression')
- 1
梯度提升算法
# 梯度提升算法
from sklearn.ensemble import GradientBoostingRegressor
start = time.time()
method = GradientBoostingRegressor(n_estimators=100, warm_start=True,learning_rate=0.01, max_depth=10, random_state=0, loss='ls')
method.fit(train_X,train_y)
res = method.predict(test_X)
precision = 1-(np.sum(np.abs(res-test_y)) / len(res))
f1 = get_f1(res,test_y)
end = time.time()
print("运行时间 %.2f" %(end-start))
print("f1值 %.5f" %(f1))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
运行时间 151.53
f1值 0.48708
- 1
- 2
plot_curve(res,test_y,'GradientBoostingRegressor')
- 1
使用决策树解决回归问题
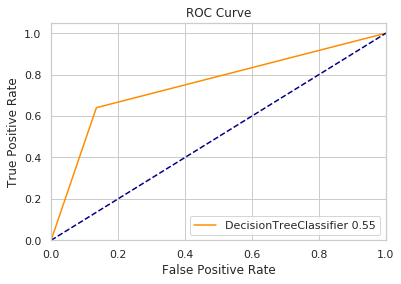
#使用决策树解决回归问题 from sklearn.tree import DecisionTreeClassifier # 找出f1值最大的 f1 = 0 ind = 0 start = time.time() for i in range(1,15): method=DecisionTreeClassifier(max_depth=i) method.fit(train_X,train_y) res = method.predict(test_X) precision = 1-(np.sum(np.abs(res-test_y)) / len(res)) if get_f1(res,test_y) > f1: f1 = get_f1(res,test_y) ind = i end = time.time() print("运行时间 %.2f" %(end-start)) print('最大的'+"f1值 %.5f max_depth=%d" %(f1,ind))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
运行时间 16.08
最大的f1值 0.57431 max_depth=9
- 1
- 2
plot_curve(res,test_y,'DecisionTreeClassifier')
- 1
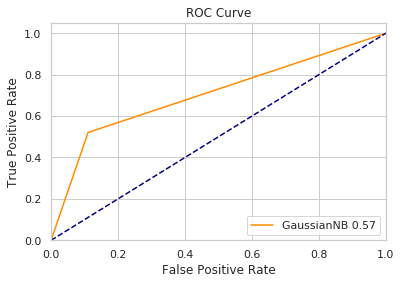
贝叶斯
# 贝叶斯
from sklearn.naive_bayes import GaussianNB
method = GaussianNB()
start = time.time()
method.fit(train_X,train_y)
res = method.predict(test_X).astype(int)
precision = 1-(np.sum(np.abs(res-test_y)) / len(res))
f1 = get_f1(res,test_y)
end = time.time()
print("运行时间 %.2f" %(end-start))
print("f1值 %.5f" %(f1))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
运行时间 0.06
f1值 0.56476
- 1
- 2
plot_curve(res,test_y,'GaussianNB')
- 1
使用效果最好的模型进行预测
# 数据集准备
test = pd.read_csv(path+'test.csv')
dict_test = median_fill_null(df=test)
dict_test = removeOutliers(dict_data=dict_test)
temp_test = dict_test['df'].copy()
ntest = feature_engineering(temp_test)
ntest.to_csv(path+"new_test.csv",index=False)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/numpy/lib/nanfunctions.py:1111: RuntimeWarning: Mean of empty slice
return np.nanmean(a, axis, out=out, keepdims=keepdims)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/pandas/core/indexing.py:670: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
iloc._setitem_with_indexer(indexer, value)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
ntest = pd.read_csv(path+'new_test.csv')
ntest.info()
- 1
- 2
<class 'pandas.core.frame.DataFrame'> RangeIndex: 29092 entries, 0 to 29091 Data columns (total 28 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 lng 29092 non-null float64 1 lat 29092 non-null float64 2 Day 29092 non-null int64 3 Month 29092 non-null int64 4 Year 29092 non-null int64 5 MinTemp 29092 non-null float64 6 MaxTemp 29092 non-null float64 7 Rainfall 29092 non-null float64 8 Evaporation 29092 non-null float64 9 Sunshine 29092 non-null float64 10 WindGustSpeed 29092 non-null float64 11 WindSpeed9am 29092 non-null float64 12 WindSpeed3pm 29092 non-null float64 13 Humidity9am 29092 non-null float64 14 Humidity3pm 29092 non-null float64 15 Pressure9am 29092 non-null float64 16 Pressure3pm 29092 non-null float64 17 Cloud9am 29092 non-null float64 18 Cloud3pm 29092 non-null float64 19 Temp9am 29092 non-null float64 20 Temp3pm 29092 non-null float64 21 RainToday 29092 non-null int64 22 AveTemp 29092 non-null float64 23 WindSpeed12pm 29092 non-null float64 24 Humidity12pm 29092 non-null float64 25 Pressure12pm 29092 non-null float64 26 Cloud12pm 29092 non-null float64 27 Temp12am 29092 non-null float64 dtypes: float64(24), int64(4) memory usage: 6.2 MB
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
nntest = np.asarray(ntest)
res = method.predict(nntest).astype(int)
res
- 1
- 2
- 3
array([0, 0, 0, ..., 0, 0, 0])
- 1
len(res)
- 1
29092
- 1
生成结果并保存
# 生成结果并保存
import datetime
last_res = pd.read_csv(path+'test.csv')
last_res = pd.DataFrame(last_res['Date'])
last_res.insert(1, 'RainTomorrow', res, allow_duplicates=False)
last_res['RainTomorrow'] = last_res['RainTomorrow'].astype(int)
last_res['RainTomorrow'] = last_res['RainTomorrow'].map({1:'Yes',0:'No'})
last_res.to_csv(path+"0423.csv",index=False)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
github仓库
声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

