

检测并归类图像中的物体是最广为人知的一个计算机视觉任务,随着ImageNet数据集挑战 而更加流行。不过还有一个令人恼火的问题有待解决:视频理解。视频理解指的是对视频片段进行分析并进行解读。虽然有一些最新的进展,现代算法还远远达不到人类的理解层次。
Facebook的AI研究团队新发表的一篇论文,SlowFast,提出了一种新颖的方法来分析视频 片段的内容,可以在两个应用最广的视频理解基准测试中获得了当前最好的结果:Kinetics-400和AVA。该方法的核心是对同一个视频片段应用两个平行的卷积神经网络(CNN)—— 一个慢(Slow)通道,一个快(Fast)通道。
作者观察到视频场景中的帧通常包含两个不同的部分 —— 不怎么变化或者缓慢变化的静态区域和正在发生变化的动态区域,这通常意味着有些重要的事情发生了。例如,飞机起飞的视频会包含相对静态的机场和一个在场景中快速移动的动态物体(飞机)。在日常生活中,当两个 人见面时,握手通常会比较快而场景中的其他部分则相对静态。
根据这一洞察,SlowFast使用了一个慢速高分辨率CNN(Slow通道)来分析视频中的静态内容,同时使用一个快速低分辨率CNN(Fast通道)来分析视频中的动态内容。这一技术部分源于灵长类动物的视网膜神经节的启发,在视网膜神经节中,大约80%的细胞(P-cells)以低频运作,可以识别细节,而大约20%的细胞(M-cells)则以高频运作,负责响应快速变化。类似的,在SlowFast中,Slow通道的计算成本要比Fast通道高4倍。
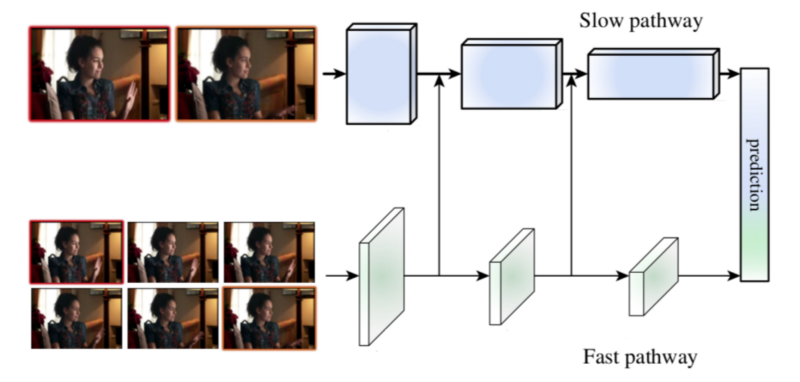
SlowFast工作原理
Slow通道和Fast通道都使用3D RestNet模型,捕捉若干帧之后立即运行3D卷积操作。
Slow通道使用一个较大的时序跨度(即每秒跳过的帧数),通常设置为16,这意味着大约1秒可以采集2帧。Fast通道使用一个非常小的时序跨度τ/α,其中α通常设置为8,以便1秒可以采集15帧。Fast通道通过使用小得多的卷积宽度(使用的滤波器数量)来保持轻量化,通常设置为慢通道卷积宽度的⅛,这个值被标记为β。使用小一些的卷积宽度的原因是Fast通道需要的计算量要比Slow通道小4倍,虽然它的时序频率更高。
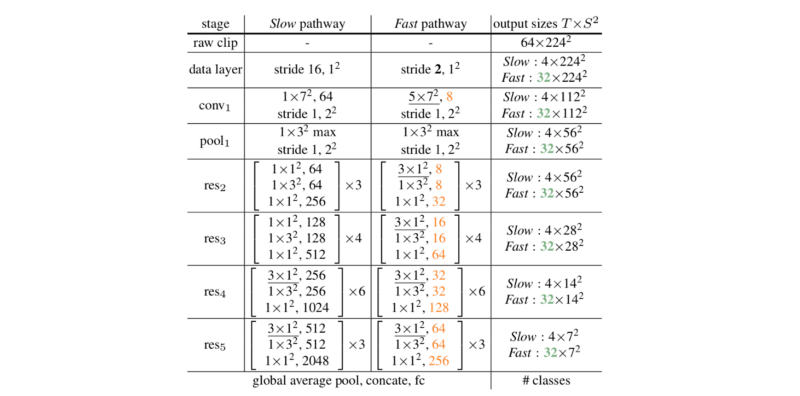
上图是一个SlowFast网络的实例。卷积核的尺寸记作{T×S², C} ,其中T、S和C分别表示时序temporal, 空间spatial和频道Channel的尺寸。跨度记作{temporal stride, spatial stride ^ 2}。速度比率(跳帧率) 为 α = 8 ,频道比率为1/β = 1/8。τ 设置为 16。绿色表示高一些的时序分辨率,Fast通道中的橙色表示较少的频道。
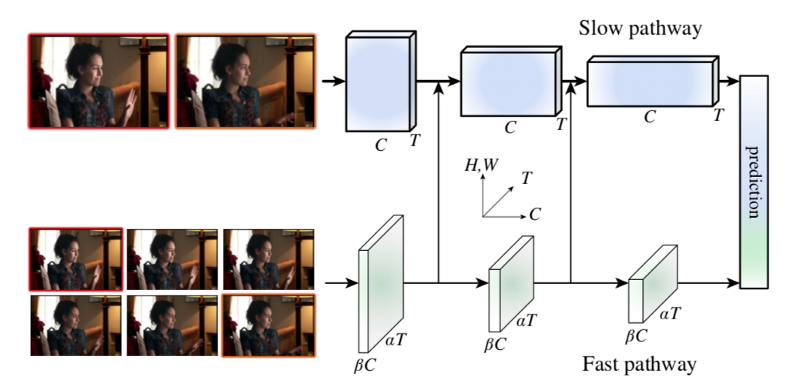
侧向连接
如图中所示,来自Fast通道的数据通过侧向连接被送入Slow通道,这使得Slow通道可以了解Fast通道的处理结果。单一数据样本的形状在两个通道间是不同的(Fast通道是{αT, S², βC} 而Slow通道是 {T, S², αβC}),这要求SlowFast对Fast通道的结果进行数据变换,然后融入Slow通道。论文给出了三种进行数据变换的技术思路,其中第三个思路在实践中最有效。
- Time-to-channel:将{αT, S², βC} 变形转置为 {T , S², αβC},就是说把α帧压入一帧
- Time-strided采样:简单地每隔α帧进行采样,{αT , S², βC} 就变换为 {T , S², βC}
- Time-strided卷积: 用一个5×12的核进行3d卷积, 2βC输出频道,跨度= α.
有趣的是,研究人员发现双向侧链接,即将Slow通道结果也送入Fast通道,对性能没有改善。
在每个通道的末端,SlowFast执行全局平均池化,一个用来降维的标准操作,然后组合两个通道的结果并送入一个全连接分类层,该层使用softmax来识别图像中发生的动作。
数据集
SlowFast在两个主要的数据集 —— DeepMind的Kinetics-400和Google的AVA上进行了测试。虽然两个数据集都包含了场景的标注,它们之间还是有些差异:
Kinetics-400包含成千上万个Youtube视频的10秒片段,将人的动作归为400类(例如:握手、跑、跳舞等),其中每一类至少包含400个视频。
AVA包含430个15分钟的标注过的Youtube视频,有80个原子化可视动作。每个动作的标注即包含描述文本,也包含在画面中的定位框。
结果
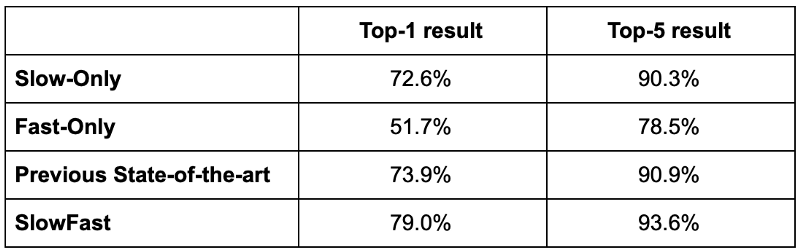
SlowFast在两个数据集上都达到了迄今为止最好的结果,在Kinetics-400上它超过最好top-1得分5.1% (79.0% vs 73.9%) ,超过最好的top-5得分2.7% (93.6% vs 90.9%)。在 Kinetics-600 数据集上它也达到了最好的结果。Kinetics-600数据集与Kinetics-400类似,不过它将动作分为600类,每一类包含600个视频。
在AVA测试中,SlowFast研究人员首先使用的版本,是一个较快速R-CNN目标识别算法和现成的行人检测器的整合,利用这个行人检测器获取感兴趣区域。研究人员随后对SlowFast网络进行了预训练,最后在ROI上运行网络。结果是28.3 mAP (median average precision) ,比之前的最好结果21.9 mAP有大幅改进。值得指出的是在Kinetics-400和Kinetics-600上的预训练没有获得显著的性能提升。
有趣的是,论文比较了只使用Slow通道、只使用Fast通道、同时使用Slow和Fast通道的结,在Kinetics-400上,只使用Slow通道的网络其top-1结果为72.6%,top-5为90.3%。只使用Fast通道的网络,top-1和top-5分别为51.7% 和 78.5%。
原文链接:slowfast解读:用于视频理解的双模CNN - 汇智网

