
- 1Linux命令 - /etc/passwd文件详解_cat /etc/passwd
- 2如何在Flatter中以正确的方式存储登录凭证_flutter_secure_storage
- 3基于 LangChain 的优秀项目资源库_anything-llm
- 4在哪里能看鸿蒙审核进度,鸿蒙开源第三方组件——进度轮ProgressWheel
- 5TypeScript 与 JavaScript 的区别(TypeScript万字基础入门,了解TS,看这一篇就够了)_typescript和javascript
- 6【老鸟进阶】deepfacelab合成参数详解_deepfacelab 合成模式参数
- 7关于51单片机中的C语言使用及总结_51单片机c语言
- 8STM32——SysTick timer(STK)----系统定时器_stm32 systemcoreclock
- 9微信小程序隐私指引完整填写范本_小程序隐私保护指引填写模板
- 10C++函数重载实现的原理以及为什么在C++中调用C语言编译的函数时要加上extern "C"声明_c调用c++函数时,需要给c++函数声明加上
Hadoop中单词统计案例_hadoop统计字母出现的个数
赞
踩
需要的软件和工程代码下载地址:
Hadoop中单词统计案例(访问密码:7567):
一、搭建本地环境
1、下载准备两个工具
Hadoop-2.7.3.tar.gz
Hadoop-2.7.3-winutils.exe.rar

2、将Hadoop-2.7.3-winutils.exe.rar解压后,其中的两个文件进行拷贝
Hadoop.dll
Wintuils.exe

3、将Hadoop-2.7.3.tar.gz解压后,找到bin目录,把上面的两个文件Hadoop.dll、Wintuils.exe拷贝到当前位置

4、配置Hadoop的环境变量

5、找到Hadoop中的日志文件log4j.properties拷贝到我们新建的Eclipse中的Maven项目中,这个日志文件是方便我们使用的,不需要写太多的配置,直接借用Hadoop中文件内容,也可以自己创建该日志文件,编写里面的内容。
(1)Hadoop中日志文件的位置

(2)拷贝到Eclipse中项目的位置

二、代码编写
1、编写Mapper

2、编写Reduce

3、编写主类

4、运行测试,首先我们先打一个JAR包


5、我导出到本地项目中了

6、将包上传到我们的虚拟机中

7、上传我们的测试文件,测试文件的文本结构如下,可以自己编写,中间使用空格隔开的。
hello everyone
hello hadoop
hello hadoop
hello hive
go home
come on

8、我们运行一下


9、我们查看一下浏览器,运行后的结果

10、在虚拟机查看一下文本内容

三、单词统计理解
(一)概念
1、单词统计的是统计一个文件中单词出现的次数,比如下面的数据源

2、其中,最终出现的次数结果应该是下面的显示

(二)那么在MapReduce中该如何编写代码并出现最终结果?
首先我们把文件上传到HDFS中(hdfs dfs –put …)
数据名称:data.txt,大小是size是2G
(三)进一步理解
1、红黄绿三个块表示的是数据存放的块

2、然后数据data.txt进入map阶段,会以<K,V>(KV对)的形式进入,K表示的是:每行首字母相对于文件头的字节偏移量,V表示的是每一行的文本。

3、那么我可以用图表示:蓝色的椭圆球表示一个map,红黄绿数据块在进入map阶段的时候,数据的形式为左边红色的<K,V>(KV对)的形式

4、经过map处理,比如String.split(“”),做一次处理,数据会在不同的红黄绿数据块中变为下面的KV形式


5、我们在配置Hadoop的时候或设置reduce的数量,假如有两个reduce
Map执行完的数据会放到对应的reduce中,如下图

6、这个地方有一个简单的原理就是
Job.setNumReduce会设置reduce的数量
而HashPartioner类可以利用 key.hashcode % reduce的结果,将不同的map结果输入到不同的reduce中,比如a-e开头的放到一个地方,e-z开头的放到一个地方,那么


7、这样的数据结果就会变成


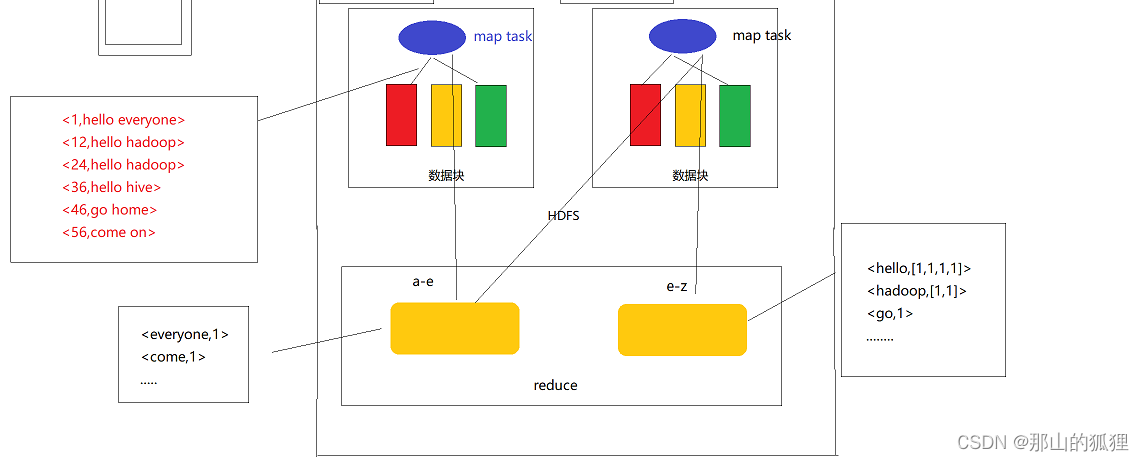
最终出现我们想要的结果,统计完成
四、练习
1、准备的数据:data.txt。文本内容:
hello everyone
hello hadoop
hello hadoop
hello hive
go home
come on
2、项目配置的pom文件
- <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
-
- xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
-
- <modelVersion>4.0.0</modelVersion>
-
-
-
- <groupId>com.xlglvc.xx.mapredece</groupId>
-
- <artifactId>wordcount-client</artifactId>
-
- <version>0.0.1-SNAPSHOT</version>
-
- <packaging>jar</packaging>
-
-
-
- <name>wordcount-client</name>
-
- <url>http://maven.apache.org</url>
-
-
-
- <properties>
-
- <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
-
- <maven.compiler.source>1.7</maven.compiler.source>
-
- <maven.compiler.target>1.7</maven.compiler.target>
-
- </properties>
-
-
-
- <dependencies>
-
- <dependency>
-
- <groupId>junit</groupId>
-
- <artifactId>junit</artifactId>
-
- <version>4.11</version>
-
- <scope>test</scope>
-
- </dependency>
-
-
-
- <dependency>
-
- <groupId>org.apache.hadoop</groupId>
-
- <artifactId>hadoop-client</artifactId>
-
- <version>2.7.3</version>
-
- </dependency>
-
- </dependencies>
-
-
-
- <build>
-
- <pluginManagement><!-- lock down plugins versions to avoid using Maven defaults (may be moved to parent pom) -->
-
- <plugins>
-
- <plugin>
-
- <artifactId>maven-clean-plugin</artifactId>
-
- <version>3.0.0</version>
-
- </plugin>
-
- <!-- see http://maven.apache.org/ref/current/maven-core/default-bindings.html#Plugin_bindings_for_jar_packaging -->
-
- <plugin>
-
- <artifactId>maven-resources-plugin</artifactId>
-
- <version>3.0.2</version>
-
- </plugin>
-
- <plugin>
-
- <artifactId>maven-compiler-plugin</artifactId>
-
- <version>3.7.0</version>
-
- </plugin>
-
- <plugin>
-
- <artifactId>maven-surefire-plugin</artifactId>
-
- <version>2.20.1</version>
-
- </plugin>
-
- <plugin>
-
- <artifactId>maven-jar-plugin</artifactId>
-
- <version>3.0.2</version>
-
- </plugin>
-
- <plugin>
-
- <artifactId>maven-install-plugin</artifactId>
-
- <version>2.5.2</version>
-
- </plugin>
-
- <plugin>
-
- <artifactId>maven-deploy-plugin</artifactId>
-
- <version>2.8.2</version>
-
- </plugin>
-
- </plugins>
-
- </pluginManagement>
-
- </build>
-
- </project>

3、Mapper文件
- package com.xlglvc.xx.mapredece.wordcount_client;
-
-
-
- import java.io.IOException;
-
- import org.apache.hadoop.io.IntWritable;
-
- import org.apache.hadoop.io.LongWritable;
-
- import org.apache.hadoop.io.Text;
-
- import org.apache.hadoop.mapreduce.Mapper;
-
- import org.apache.hadoop.mapreduce.Mapper.Context;
-
-
-
- public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>
-
- {
-
- protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
-
- throws IOException, InterruptedException
-
- {
-
- Text keyout = new Text();
-
- IntWritable valueout = new IntWritable(1);
-
-
-
- String line = value.toString();
-
-
-
- String[] words = line.split(" ");
-
-
-
- for (String word : words) {
-
- keyout.set(word);
-
- context.write(keyout, valueout);
-
- }
-
- }
-
- }
4、Reducer文件:
- package com.xlglvc.xx.mapredece.wordcount_client;
-
-
-
- import java.io.IOException;
-
- import org.apache.hadoop.io.IntWritable;
-
- import org.apache.hadoop.io.Text;
-
- import org.apache.hadoop.mapreduce.Reducer;
-
- import org.apache.hadoop.mapreduce.Reducer.Context;
-
-
-
- public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>
-
- {
-
- protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context)
-
- throws IOException, InterruptedException
-
- {
-
- IntWritable valueout = new IntWritable();
-
-
-
- int count = 0;
-
-
-
- for (IntWritable value : values)
-
- {
-
- count += value.get();
-
- }
-
-
-
- valueout.set(count);
-
-
-
- context.write(key, valueout);
-
- }
-
- }
5、主方法类WordCountDriver
- package com.xlglvc.xx.mapredece.wordcount_client;
-
-
-
- import java.io.IOException;
-
- import org.apache.hadoop.conf.Configuration;
-
- import org.apache.hadoop.fs.Path;
-
- import org.apache.hadoop.io.IntWritable;
-
- import org.apache.hadoop.io.Text;
-
- import org.apache.hadoop.mapreduce.Job;
-
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
-
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
-
-
-
- public class WordCountDriver
-
- {
-
- public static void main(String[] args)
-
- throws IOException, ClassNotFoundException, InterruptedException
-
- {
-
- Configuration conf = new Configuration();
-
-
-
- Job job = Job.getInstance(conf);
-
-
-
- job.setJarByClass(WordCountDriver.class);
-
-
-
- FileInputFormat.addInputPath(job, new Path(args[0]));
-
- FileOutputFormat.setOutputPath(job, new Path(args[1]));
-
-
-
- job.setMapperClass(WordCountMapper.class);
-
- job.setReducerClass(WordCountReducer.class);
-
-
-
- job.setMapOutputKeyClass(Text.class);
-
- job.setMapOutputValueClass(IntWritable.class);
-
-
-
- job.setOutputKeyClass(Text.class);
-
- job.setOutputValueClass(IntWritable.class);
-
-
-
- boolean result = job.waitForCompletion(true);
-
- System.exit(result ? 0 : 1);
-
- }
-
- }
6、打包到虚拟机运行,方法和之前相同。

