
- 1ModelSim小技巧,10.5_modelsim怎么变宽
- 2论文浅尝 | 基于统一学习方法的预训练语言模型的知识图谱扩展
- 3HTML中img路径问题_img标签图片路径去掉服务器
- 4Canny算法实现车道线检测_canny算子车道线检测
- 5RNN知识点复习_双向rnn和rnn比有哪些优势
- 6Transformer作为特征提取器_transformer特征提取
- 7sh脚本报错“eval: line 1: syntax error: unterminated quoted string”
- 8深度学习-数据归一化与Batch Normalization
- 9set、env、export——Linux中的环境变量命令_export setenv
- 10Retrieve-Rewrite-Answer: A KG-to-Text Enhanced LLMsFramework for Knowledge Graph Question Answering_kgqa for llm
基于多玩家博弈的用户可控推荐算法
赞
踩
省时查报告-专业、及时、全面的行研报告库
省时查方案-专业、及时、全面的营销策划方案库
【免费下载】2024年1月份热门报告合集
推荐技术在vivo互联网商业化业务中的实践.pdf
推荐系统基本问题及系统优化路径.pdf
大规模推荐类深度学习系统的设计实践.pdf
荣耀推荐算法架构演进实践.pdf
推荐系统在腾讯游戏中的应用实践.pdf
微信视频号实时推荐技术架构分享
推荐系统的变与不变
TLDR: 本文提出一种基于影响函数的模型IFRQE,用以近似不同决策下的推荐性能,而无需重新优化模型。此外,引入了一种利用多个锚点决策来提高影响函数近似准确性的方法IFRQE++。

摘要
传统的推荐模型旨在收集广泛的用户信息以准确估计用户偏好。然而,在实际场景中,用户可能不希望所有行为都被纳入模型训练过程。本文介绍了一种新的推荐范式,允许用户主动表明他们对使用个人数据用于模型训练的“意愿”。我们将这个推荐场景建模为一个多人博弈,每个用户作为一个参与者,模型通过平衡推荐质量和用户意愿最大化整体效用。为了高效的寻找纳什均衡,我们提出了一种基于影响函数的模型IFRQE,用以近似不同决策下的推荐性能,而无需重新优化模型。此外,引入了一种利用多个锚点决策来提高影响函数近似准确性的方法IFRQE++。我们在模拟和真实世界数据集上进行了大量的实验验证了所提出模型在平衡推荐质量和用户意愿方面的有效性,并对算法的收敛性给出了理论证明。
ChatGPT4国内可以直接访问的链接,无需注册,无需翻墙,支持编程等多个垂直模型,点开即用:https://ai.zntjxt.com(复制链接电脑浏览器或微信中点开即可,也可扫描下方二维码直达)
本文动机
传统的推荐算法:用户处于被动状态,系统处于主动状态。系统通过搜集用户数据来理解用户,训练模型以及在线推断。
我们提出的方法:用户和系统同处于主动状态,双方共同决定哪些数据需要最后用于训练。用户预先指定对不同数据的训练意愿,例如:当训练数据可能泄漏个人隐私,或者当训练数据不能反映用户兴趣时,用户使用这些数据训练的意愿会降低,系统考虑这些意愿构建推荐训练数据。
意义:从系统主导的推荐范式转化为系统-用户协商的推荐范式,允许用户更多的参与推荐系统决策过程,允许用户对其个人偏好,隐私等有更灵活、主动的处理机制。
问题形式化
为什么是博弈问题?
我们考虑用户的两方面utility:(1)用户收到的推荐质量(2)用户意愿的违背程度。
使用数据多:用户收到的推荐质量好,但也更有可能违背用户意愿
使用数据少:用户收到的推荐质量差,但可能违背用户意愿的程度弱
因此,使用多少数据是一个策略性的选择问题。同时我们考虑到对用户A的推荐性能实际上是由所有用户的训练数据决定的,因此,对A来讲,其他用户的策略会影响他的utility,所以整个问题是一个多玩家博弈问题。
具体定义如下:
目标:为每个用户的交互数据 选取一个子集来训练推荐模型,从而平衡推荐质量和用户意愿。
参与者:所有用户。
奖励:
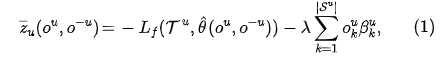
第一项是推荐模型在验证集上负的loss值,反映了推荐质量,第二项反映了对于用户意愿的违反程度。
纳什均衡:
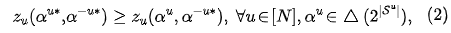
其中 和分别表示用户 和除了用户 之外的用户的策略。
问题求解
朴素方法。求解这个博弈问题最优解的朴素的方法就是用户每行动一次,就根据用户选择公开的数据训练一次模型,然后计算奖励并优化,但是这样每次都要重新训练模型,时间上是不能接受的。
IFRQE。借助影响函数,可以估计出每个训练样本对于模型效果的影响。在此基础上我们提出了IFRQE框架,首先基于公开的数据计算每个数据对应的影响函数值,我们称此时对应的用户公开动作为锚点选择向量。使用影响函数可以快速估计当前用户行动下的模型表现,进而计算用户奖励,避免了重新训练模型。结合影响函数的奖励计算方式为 :
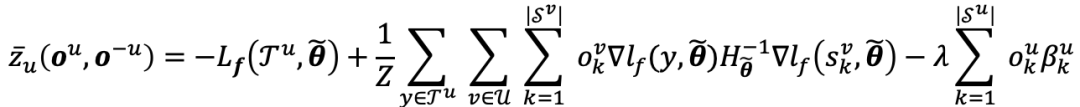
IFRQE++。如果当前的锚点选择向量和实际的用户动作差距较大,会导致近似结果和实际值的误差较大。因此我们提出改进的方法IFRQE++来缓解这个问题。在初始化锚点选择向量的时候初始化多个锚点向量,在每次用影响值近似计算的时候选择距离当前用户动作最近的锚点向量对应的影响值,这样可以从理论上证明它的误差上界。令 表示当前距离最近的锚点选择向量,此时的奖励计算方式为:
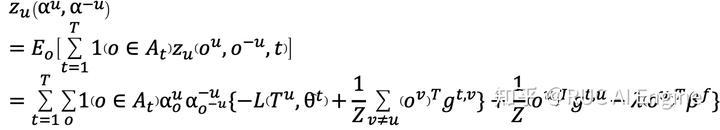
我们使用投影梯度下降法来交替优化每个用户的决策分布。
实验结果
数据集。我们在Diginetica,Steam,Amazon Video和基于RecSim生成的模拟数据上验证了我们所提出方法的有效性。
基础模型。我们采用MF,NeuMF和LightGCN三个经典的推荐模型作为基础模型。
Baseline。Random: 随机公开部分物品,Threshold: 根据用户的意愿设置阈值进行公开,Proactive不使用影响函数的强化学习方法。
主要实验
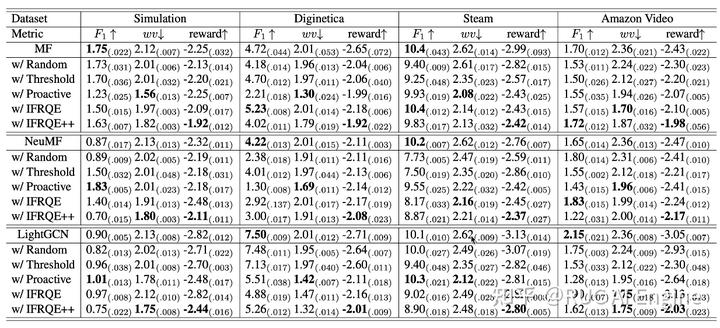
可以看到我们的方法Reward一般是最高的,有的时候甚至推荐指标也能超过基础模型,这说明一个有意思的问题:数据中可能存在部分数据是噪声,会干扰推荐系统对用户喜好的建模。
对验证集损失的近似
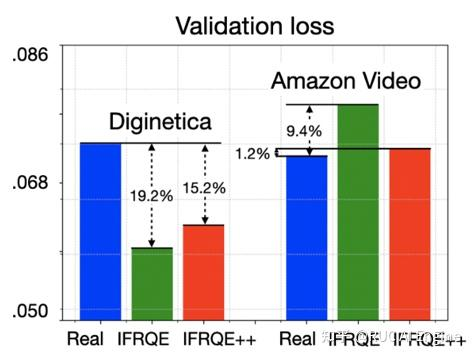
使用影响函数的关键在于对验证集上loss的近似要是准确的,我们比较了我们提出的两种方法对loss的近似情况,可以看到IFRQE++相比于IFRQE可以更准确的近似验证集上的损失。
锚点选择向量数量的影响
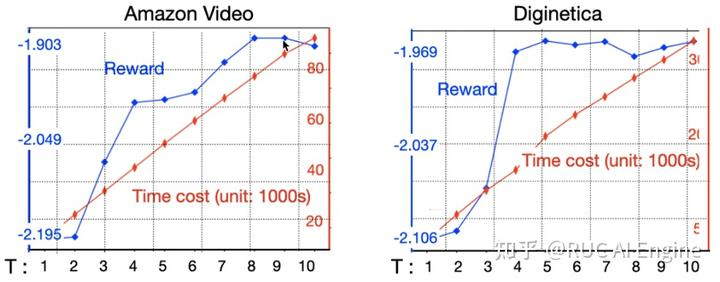
IFRQE++相比于IFRQE的改进就是使用了更多的锚点选择向量,我们比较了不同锚点数量下的模型表现。可以看到锚点数量越多,最后的奖励越高,但是相应的需要重新训练模型的次数也越多,时间花费成倍增长,在实现上需要从模型效果和时间花费上找到平衡。
不同用户意愿特征的影响
由于没有相关数据,我们在真实数据集中的用户意愿是赋予的随机值,为了证明我们方法的有效性我们构建了模拟数据集来研究我们的方法对于不同意愿特征的用户的效果。令用户 对公开物品 的不愿意程度为 ,通过控制参数 和 我们模拟了四种不同意愿特征的数据集。可以看到IFRQE++在不同的数据集上都有超过Baseline的效果。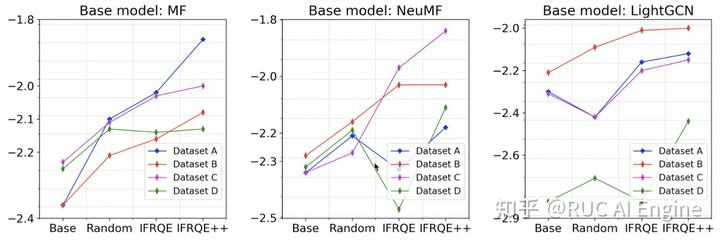 ChatGPT4国内可以直接访问的链接,无需注册,无需翻墙,支持编程等多个垂直模型,点开即用:https://ai.zntjxt.com(复制链接电脑浏览器或微信中点开即可,也可扫描下方二维码直达)
ChatGPT4国内可以直接访问的链接,无需注册,无需翻墙,支持编程等多个垂直模型,点开即用:https://ai.zntjxt.com(复制链接电脑浏览器或微信中点开即可,也可扫描下方二维码直达)

「 更多干货,更多收获 」

【免费下载】2023年12月份热门报告合集
ChatGPT的发展历程、原理、技术架构及未来方向
《ChatGPT:真格基金分享.pdf》
2023年AIGC发展趋势报告:人工智能的下一时代
推荐系统在腾讯游戏中的应用实践.pdf
推荐技术在vivo互联网商业化业务中的实践.pdf
2023年,如何科学制定年度规划?
《底层逻辑》高清配图
推荐技术在vivo互联网商业化业务中的实践.pdf
推荐系统基本问题及系统优化路径.pdf
荣耀推荐算法架构演进实践.pdf
大规模推荐类深度学习系统的设计实践.pdf
某视频APP推荐策略详细拆解(万字长文)关注我们
智能推荐 个性化推荐技术与产品社区 | 长按并识别关注
|

一个「在看」,一段时光
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

