
- 1Bert应用_bert的应用
- 2caused by: java.lang.ClassNotFoundException: org.springframework.transaction.ReactiveTransactionMana
- 3QT5 下UDP 编程实例:客户端,服务器端_qt5 udp客户端
- 4Docker中安装Redis_dockerhub redis
- 5Gateway服务的搭建_gateway安装
- 6RK3588 camera资源介绍
- 7android安装 mysql数据库,android 上安装 mysql 数据库 rk3188测试平台
- 8tick timer 间隔_adjtimex修改tick值用法举例
- 9ubuntu 16.04 LTS - PyQt5_ubuntu16.04 pyqt5
- 10Android Flutter配置及出现的问题解决_模块没有源根配置
Transformer作为特征提取器_transformer特征提取
赞
踩
Transformer之前

上图是经典的双向RNN模型,我们知道该模型是通过递归的方式运行,虽然适合对序列数据建模,但是缺点也很明显“它无法并行执行”也就无法利用GPU强大的并行能力,再加上各种门控机制,运行速度很慢。一般而言,编码器输出编码向量C作为解码器输入,但是由于编码向量C中所有的编码器输入值贡献相同,导致序列数据越长信息丢失越多。

CNN网络相比RNN网络,它虽然可以并行执行,但是无法一次捕获全局信息,通过上图可得我们需要多次遍历,多个卷积层叠加增大感受野。
谷歌的做法是Attention is All You Need !
Transformer

如图所示是Transformer的整体结构,我们将详细介绍每一部分,先从左边的编码器开始。

A: 这一步,我想大家已经非常熟悉了,将词汇表转为embedding维度的向量(onehot和embedding区别)。
B: 仅仅使用attention有一个致命短板,它对序列数据的顺序免疫,即:无法捕获序列的顺序。比如对翻译任务,我们知道顺序非常重要,单词顺序变动甚至会产生完全不同的意思。因此增加Position Embedding给每个位置编号,每个编号对应一个向量,这样每个词向量都会有一个位置向量,以此来定位。

如图所示,Position Embedding计算公式,将id为p的位置映射为一个dpos维的位置向量,这个向量的第i个元素的数值就是PEi§,位置编码算法当然不止一种,但是不同算法必须要解决的的问题就是能够处理未知长度的序列。假设位置向量有4维,实际位置向量可能如下所示:

结合位置向量和词向量我们有两种方式,一种是将两者拼接成一个新向量,另一种是使两者维度相同然后相加得到新向量。

C:残差连接,随后是D: layer-normalization。

E:Multi-head注意力机制

上图是attention计算过程,我们分解步骤,依次来看。
1.生成“q”,“k”,“v”向量,由输入embedding向量与图示右侧对应权重矩阵相乘。需要注意的是,此处的三个权重矩阵为所有输入共享。如果每个词独享一个权重矩阵,个人认为并不会提升性能,有可能还会降低。

2.计算attention score,计算方式如图所示:

3.使用softmax归一化数值,softmax上面的相除操作主要是调解内积不要太大。

4.将softmax归一化后的值与“v”向量矩阵相乘,将所有加权向量加和,产生该位置的self-attention的输出结果。

multi-headed attention:就是有多组上面那样的attention,最后将结果拼接起来,其中,每组attention权重不共享。

计算公式如下:

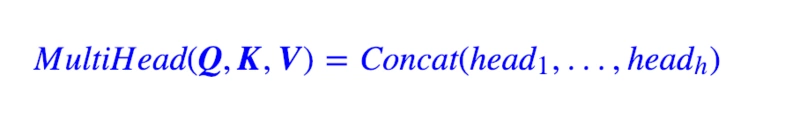
整体计算过程如下图所示:

F:全连接网络,两个线性函数,一个非线性函数(Relu):
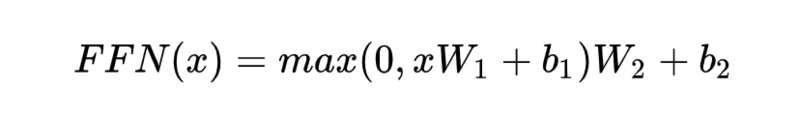
解码器:
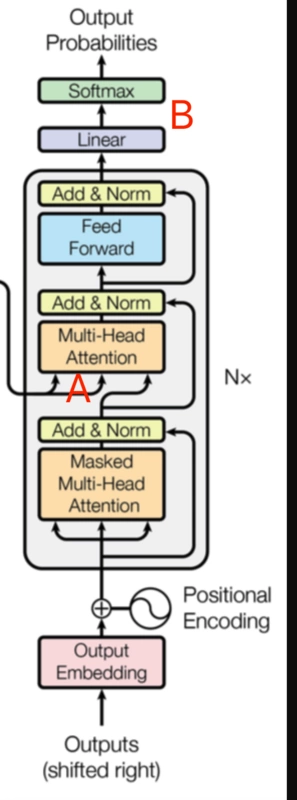
A:解码器attention计算的内部向量和编码器的输出向量,计算源句和目标句之间的关系,在Transformer之前,attention机制就应用在这里。
B:线性层是一个全连接层,神经元数量和词表长度相等,然后添加softmax层,将概率最高值对应的词作为输出。

代码实现(tensorflow实现)
Position_embedding:
def Position_Embedding(inputs,position_size): """ :param inputs: shape=(batch_size,timestep,word_size) :param position_size: int_ :return: shape=(1,seq_len.size,position_size) """ # inputs: shape=(batch_size,timestep,word_size) batch_size,seq_len=tf.shape(inputs)[0],tf.shape(inputs)[1] # shape=(position_size,) position_j=1./tf.pow(10000.,2*tf.range(position_size,dtype=tf.float32)/position_size) # shape=(1,position_size) position_j=tf.expand_dims(position_j,axis=0) # shape=(seq_len.size,) position_i=tf.range(tf.cast(seq_len,tf.float32),dtype=tf.float32) # shape=(seq_len.size,1) position_i=tf.expand_dims(position_i,axis=1) # 这是上面维度扩展的原因 position_ij=tf.matmul(position_i,position_j) # shape=(seq_len.size,position_size) # 在axis=1,即:seq_len.size 拼接 position_ij=tf.concat([tf.cos(position_ij),tf.sin(position_ij)],axis=1) # shape=(1,seq_len.size,position_size) position_embedding=tf.expand_dims(position_ij,axis=0)+tf.zeros((batch_size,seq_len,position_size)) return position_embedding

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
Mask
def Mask(inputs,seq_len,mode='mul'): """ :param mode: 'mul':将多余部分置零,用于全连接层之前 'add':将多余部分减去一个大的常数,用于softmax之前 """ if seq_len == None: return inputs else: # shape=(seq_len.size,seq_len.size) mask=tf.cast(tf.sequence_mask(seq_len,dtype=tf.float32)) for _ in range(len(inputs.shape)-2): # shape=(seq_len.size,seq_len.size,1) mask=tf.expand_dims(mask,2) if mode == 'mul': return inputs*mask if mode == 'add': return inputs-(1-mask)*1e12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
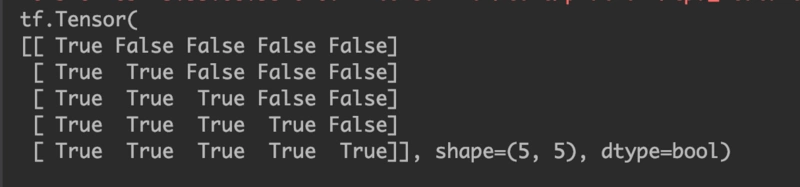
tf.sequence_mask 使用示例:
mask=tf.sequence_mask([1,2,3,4,5],maxlen=5)
print(mask)
- 1
- 2
Dens
def Dense(inputs,output_size,bias=True,seq_len=None): input_size=int(inputs.shape[-1]) # shape=(input_size,output_size)均匀分布,取值区间(-0.005,0.005) W=tf.Variable(tf.random_uniform([input_size,output_size],minval=-0.005,maxval=0.005)) # 是否使用'b' # (我们在使用BN的时候,'b'可以不使用。原因是,BN改变数据分布,'b'的调解会被BN覆盖) if bias == True: b=tf.Variable(tf.random_uniform([output_size],minval=-0.005,maxval=0.005)) else: b=0 # reshape 到2维 outputs=tf.matmul(tf.reshape(inputs,(-1,input_size)),W)+b # reshape 到3维 outputs=tf.reshape(outputs,tf.concat([tf.shape(inputs)[:-1],[output_size]],axis=0)) if seq_len != None: outputs=Mask(outputs,seq_len,'mul') return outputs
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
Attention
def Attention(Q,K,V,nb_head,size_per_head,Q_len=None,V_len=None): # 对Q、K、V分别作线性映射 Q = Dense(Q, nb_head * size_per_head, False) Q = tf.reshape(Q, (-1, tf.shape(Q)[1], nb_head, size_per_head)) Q = tf.transpose(Q, [0, 2, 1, 3]) K = Dense(K, nb_head * size_per_head, False) K = tf.reshape(K, (-1, tf.shape(K)[1], nb_head, size_per_head)) K = tf.transpose(K, [0, 2, 1, 3]) V = Dense(V, nb_head * size_per_head, False) V = tf.reshape(V, (-1, tf.shape(V)[1], nb_head, size_per_head)) V = tf.transpose(V, [0, 2, 1, 3]) # 计算内积,然后mask,然后softmax A = tf.matmul(Q, K, transpose_b=True) / tf.sqrt(float(size_per_head)) A = tf.transpose(A, [0, 3, 2, 1]) A = Mask(A, V_len, mode='add') A = tf.transpose(A, [0, 3, 2, 1]) A = tf.nn.softmax(A) # 输出并mask O = tf.matmul(A, V) O = tf.transpose(O, [0, 2, 1, 3]) O = tf.reshape(O, (-1, tf.shape(O)[1], nb_head * size_per_head)) O = Mask(O, Q_len, 'mul') return O
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
总结
Transformer现在大有取代RNN之势,但依然存在一些缺点。首先,Transformer虽然使用到了位置向量,但是对序列位置要求很高的项目做的并不好。

