
- 1简单介绍微信小程序的相关文件类型_1、 微信小程序中一般一个页面由几个文件组成?分别简述这些文件的作用。
- 2Centos下部署开源WAF---ModSecurity_centos waf
- 3js获取指定时间范围内指定间隔天数的所有日期_js通过开始时间和结束时间、间隔时间计算出中间的所有日期
- 4机械臂速成小指南(十四):多项式插值轨迹规划_机械臂三次多项式插值
- 5springboot 最新版本 及特性_springboot最新版本
- 6作为一个回到二线城市程序员,困境下,我的冷思考
- 7springboot+redis+lua脚本进行接口限流,解决高并发计数不准确问题_在高并发下 lua 也不管用
- 8RN环境配置(这里只演示mac版本的android studio的sdk下载失败的解决和ios环境的配置)
- 9C语言文件操作
- 10centos8 执行yum install ntpdate命令,报错未找到匹配的参数: ntpdate_centos8 yum 无法安装ntp
【保姆级教程】YOLOv3图像目标检测:训练自己的数据集
赞
踩
一、YOLOv3图像目标检测原理
二、YOLOv3代码及预训练权重下载
2.1 下载yolov3代码
这里使用的是B站大佬Bubbliiiing复现的yolov3代码
仓库地址: https://github.com/bubbliiiing/yolo3-pytorch
2.2 下载模型预训练权重unet_resnet_medical.pth
链接:https://pan.baidu.com/s/1IhWYvEvIwGL6MrcIvYJroA
提取码:d3ob
将下载的权重文件放到model_data文件夹下。
三、labelimg图像标注及格式转换
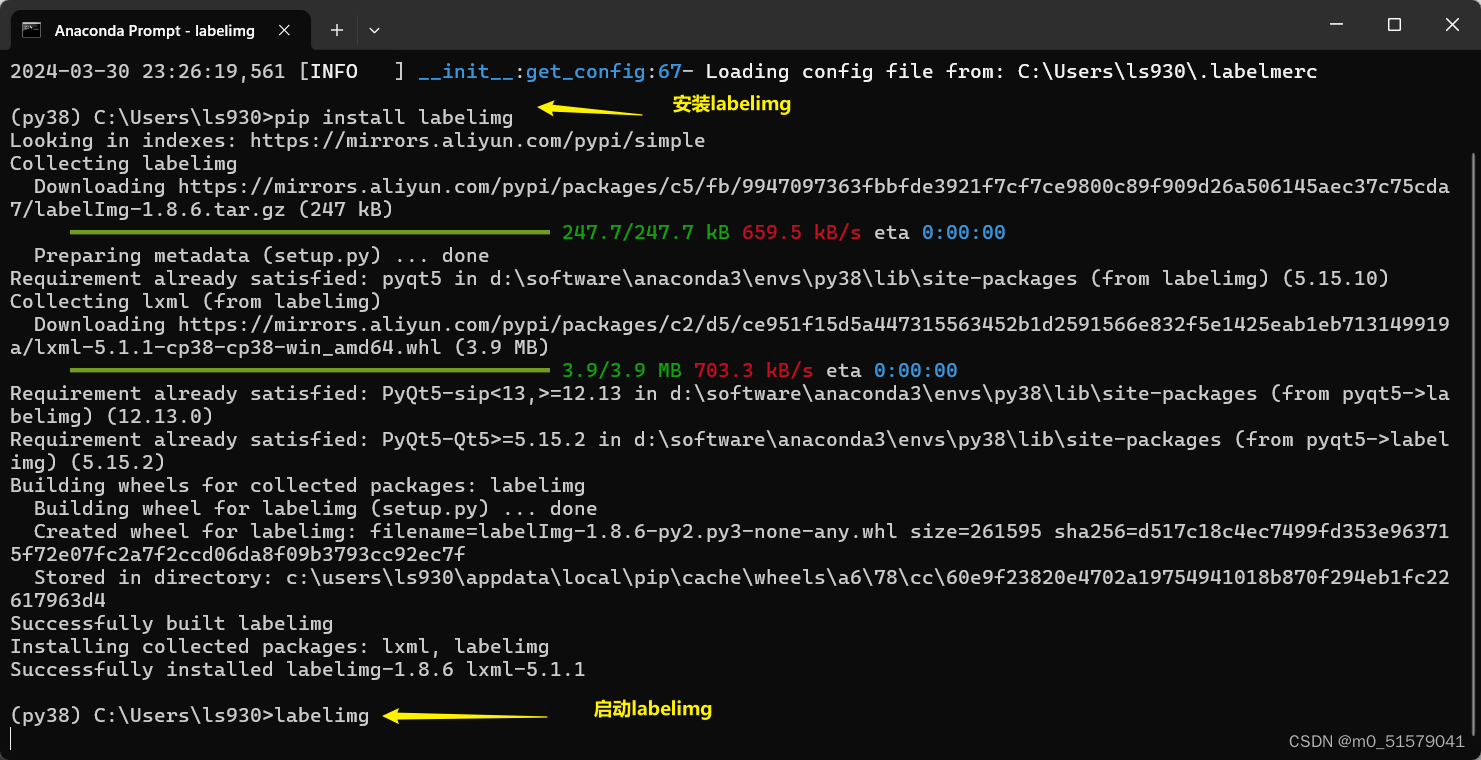
3.1 安装labelimg标注软件
pip install labelimg
- 1
使用Anaconda Prompt启动labeimg标注工具
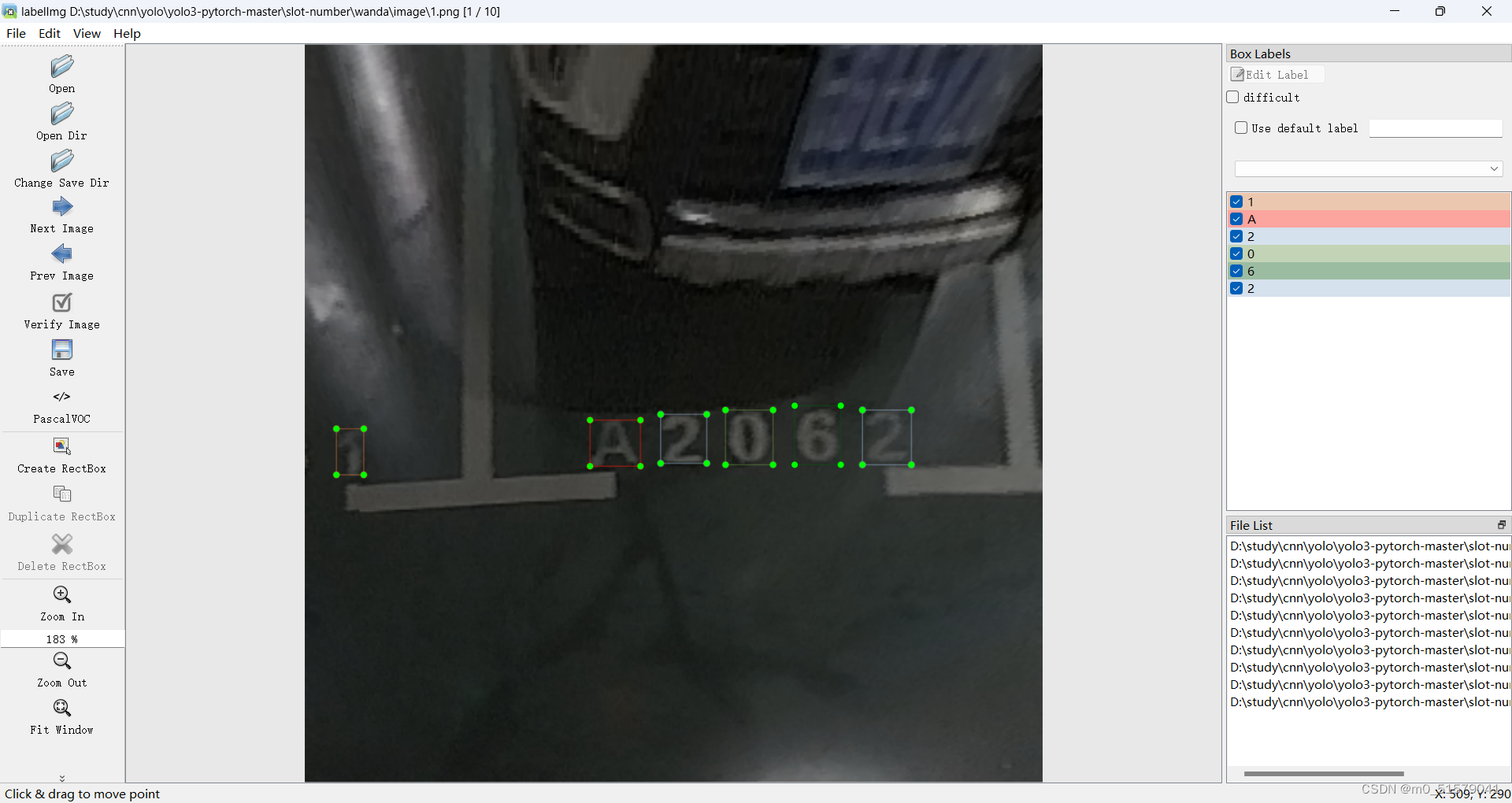
3.2 图像标注
3.3 数据集划分
将xml格式标签文件放在VOCdevkit文件夹下的VOC2007文件夹下的Annotation中。
将图片文件放在VOCdevkit文件夹下的VOC2007文件夹下的JPEGImages中。
修改model_data/voc_classes.txt文件,改为自己使用的类别

修改voc_annotation.py,117行,图片格式改为自己实际用到的图片格式。

运行voc_annotation.py
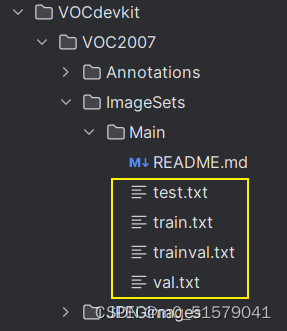
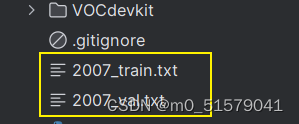
在VOCdevkit\VOC2007\ImageSets\Main路径下会生成划分数据集的txt文件,在项目根目录下会生成2007_train.txt,2007_val.txt文件。
注意这里只支持xml格式的标签,不支持json格式的标签。


四、YOLOv3网络训练和测试
4.1 训练
运行train.py,根据自己的实际情况,修改一下参数。
4.2 测试
修改yolo.py中代码,“model_path” : ‘logs/best_epoch_weights.pth’,和“classes_path” : ‘model_data/voc_classes.txt’,。
运行predict.py文件。
读者需要根据自己的情况修改模型权重和测试图片的地址。
读者可以通过修改mode参数,实现下面5种模式:
# 'predict' 表示单张图片预测,如果想对预测过程进行修改,如保存图片,截取对象等,可以先看下方详细的注释
# 'video' 表示视频检测,可调用摄像头或者视频进行检测,详情查看下方注释。
# 'fps' 表示测试fps,使用的图片是img里面的street.jpg,详情查看下方注释。
# 'dir_predict' 表示遍历文件夹进行检测并保存。默认遍历img文件夹,保存img_out文件夹,详情查看下方注释。
# 'export_onnx' 表示将模型导出为onnx,需要pytorch1.7.1以上。
- 1
- 2
- 3
- 4
- 5
设置mode = “predict”模式,测试一张自己手动输入路径的图像,结果如下

