
- 1A Tour of C++笔记
- 25、双亲委派机制
- 3Python项目开发:Django基于Python的班级管理系统的设计与实现_数据结构项目管理系统python
- 4python基础学习-元组_python tuple 倒序
- 5Python之GUI自动化---selenium基础_gui自动化测试
- 6知识增强系列 ERNIE: Enhanced Representation through Knowledge Integration,论文解读_ernie的论文
- 7【深度剖析HMM(附Python代码)】4.HMM代码测试及hmmlearn介绍_hmm相关库
- 8AIGC——ComfyUI使用SDXL双模型的工作流(附件SDXL模型下载)_comfyui sdxl base模型下载
- 92033: [蓝桥杯2022初赛] 刷题统计_刷题统计蓝桥杯
- 10还在用MathType编写数学公式吗,markdown纯手撸复杂数学公式
MLC LLM - 大模型本地部署解决方案_mlc-llm部署
赞
踩
MLC LLM 是一种通用解决方案,它允许将任何语言模型本地部署在各种硬件后端和本地应用程序上,此外还提供了一个高效的框架,供每个人根据自己的用例进一步优化模型性能。

推荐:用 NSDT设计器 快速搭建可编程3D场景。
我们的使命是让每个人都能在每个人的设备上本地开发、优化和部署 AI 模型。
一切都在本地运行,无需服务器支持,并通过手机和笔记本电脑上的本地 GPU 加速。 支持的平台包括:
- 苹果手机、iPad
- 金属 GPU 和 Intel/ARM MacBook;
- AMD、Intel 和 NVIDIA GPU,通过 Windows 和 Linux 上的 Vulkan;
- 在 Windows 和 Linux 上通过 CUDA 的 NVIDIA GPU;
- 浏览器上的 WebGPU(通过配套项目 WebLLM)。
1、什么是 MLC LLM?
近年来,生成式人工智能 (AI) 和大型语言模型 (LLM) 取得了显着进步,并变得越来越普遍。 由于开源计划,现在可以使用开源模型开发个人AI助手。 但是,LLM 往往是资源密集型和计算要求高的。 要创建可扩展的服务,开发人员可能需要依赖强大的集群和昂贵的硬件来运行模型推理。 此外,部署 LLM 还面临一些挑战,例如不断发展的模型创新、内存限制以及对潜在优化技术的需求。
该项目的目标是支持开发、优化和部署 AI 模型,以便跨各种设备进行推理,不仅包括服务器级硬件,还包括用户的浏览器、笔记本电脑和移动应用程序。 为实现这一目标,我们需要解决计算设备和部署环境的多样性问题。 一些主要挑战包括:
- 支持不同型号的 CPU、GPU 以及可能的其他协处理器和加速器。
- 部署在用户设备的本地环境中,这些环境可能没有 python 或其他可用的必要依赖项。
- 通过仔细规划分配和积极压缩模型参数来解决内存限制。
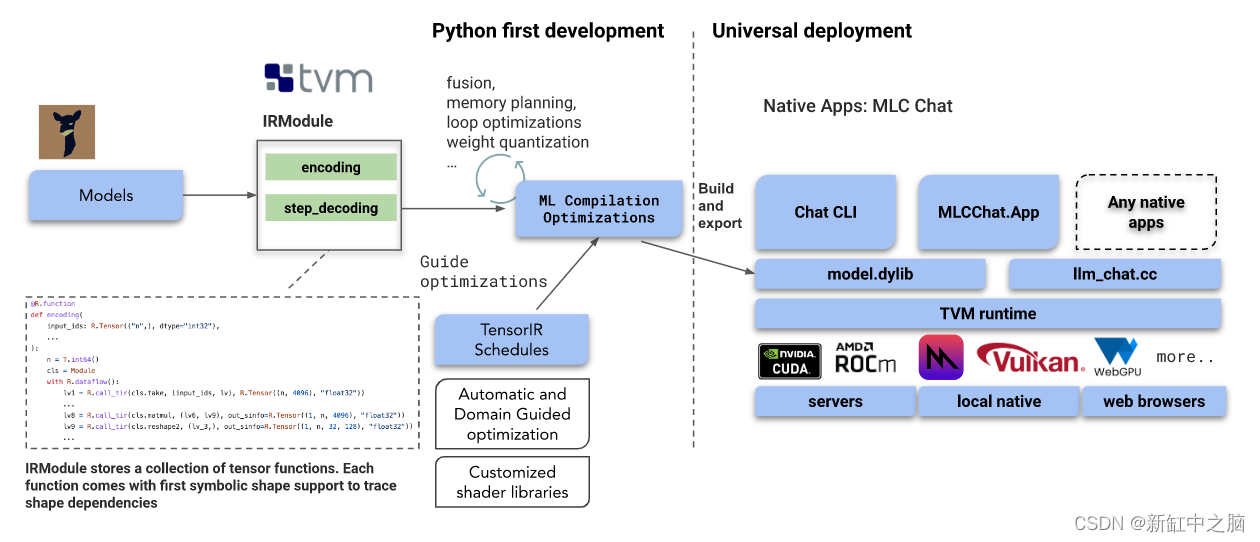
MLC LLM 提供可重复、系统化和可定制的工作流程,使开发人员和 AI 系统研究人员能够以以生产力为中心、Python 优先的方法实施模型和优化。 这种方法可以快速试验新模型、新想法和新编译器通道,然后本地部署到所需目标。 此外,我们通过扩展 TVM 后端不断扩展 LLM 加速,使模型编译更加透明和高效。
2、MLC 如何实现通用原生部署?
我们解决方案的基石是机器学习编译 (MLC:Machine Learning Compilation),我们利用它来高效部署 AI 模型。 我们建立在开源生态系统的基础上,包括来自 HuggingFace 和 Google 的分词器,以及 Llama、Vicuna、Dolly、MOSS 等开源 LLM。 我们的主要工作流基于 Apache TVM Unity,这是 Apache TVM 社区中一项令人兴奋的持续开发。
- 动态形状:我们将语言模型烘焙为具有原生动态形状支持的 TVM IRModule,避免了对最大长度进行额外填充的需要,并减少了计算量和内存使用量。
- 可组合的 ML 编译优化:我们执行许多模型部署优化,例如更好的编译代码转换、融合、内存规划、库卸载和手动代码优化可以很容易地合并为 TVM 的 IRModule 转换,作为 Python API 公开。
- 量化:我们利用低位量化来压缩模型权重,并利用 TVM 的循环级 TensorIR 为不同的压缩编码方案快速定制代码生成。
- 运行时:最终生成的库在原生环境中运行,TVM 运行时具有最小的依赖性,支持各种 GPU 驱动程序 API 和原生语言绑定(C、JavaScript 等)。
此外,我们还提供了一个基于 C++ 的轻量级示例 CLI 应用程序,展示了如何包装已编译的工件和必要的预处理/后处理,这有望阐明将它们嵌入本机应用程序的工作流程。
作为起点,MLC 为 CUDA、Vulkan 和 Metal 生成 GPU 着色器。 通过改进 TVM 编译器和运行时,可以添加更多支持,例如 OpenCL、sycl、webgpu-native。 MLC 还通过 LLVM 支持各种 CPU 目标,包括 ARM 和 x86。
我们严重依赖开源生态系统,更具体地说,TVM Unity,这是 TVM 项目中令人兴奋的最新开发,它支持 python 优先的交互式 MLC 开发体验,使我们能够轻松地在 Python 中编写新的优化,并逐步将我们的应用程序带到 感兴趣的环境。 我们还利用了融合量化内核、一流动态形状支持和多样化 GPU 后端等优化。


