
- 1[Kafka集群] 配置支持Brokers内部SSL认证\外部客户端支持SASL_SSL认证并集成spring-cloud-starter-bus-kafka_kafka_2.13-3.5.0.tgz下载
- 2【Python之Git使用教程001】Git简介与安装_python安装git
- 3hadoop在linux上启动成功了,但是浏览器访问不了_hadoop启动但是打不开网页
- 4左手医生:医疗 AI 企业的云原生提效降本之路
- 5SpringCloud - Eureka Server的数据同步过程?_eureka集群同步数据的过程
- 6xcode扩展_如何将Xcode插件转换为Xcode扩展名
- 7在服务器上进行深度学习的入门教程_用服务器跑深度学习
- 8【开启报名】大模型研讨会 | 聚焦 LLMs 技术前沿、待解问题、未来趋势
- 9 docker下使用centos6.6 安装vasp5.4步骤
- 10javaweb农产品网络交易平台设计springboot+ssm_java农交网
【nlp学习】中文命名实体识别(待补充)
赞
踩
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
参考资料:零基础入门–中文命名实体识别
提示:以下是本篇文章正文内容,下面案例可供参考
一、中文分词
首先了解一下基于字标注的中文分词,比如一句话:
我爱北京天安门。
分词的结果可以是:
我/爱/北京/天安门。
基于字标注的中文分词:
我/O 爱/O 北/B 京/E 天/B 安/M 门/E。
就是这样,给每一个字都进行标注。我们可以发现这句话中的中文字标注一共有四种,他们分别代表的含义如下:
B | 词首
M | 词中
E | 词尾
O | 单字
B 表示一个词的开始,E 表示一个词的结尾,M 表示词中间的字。如果这个词只有一个字的话,用 O 表示。
二、命名实体识别
1.数据处理
了解了中文分词,那么实体识别也差不多。就是把不属于实体的字用 O 标注,把实体用 BME 规则标注,最后按照 BME 规则把实体提取出来就 ok 了。
数据可以自己标注,也可以找个公开的数据集先练练手。我是用的是玻森数据提供的命名实体识别数据。(官网:https://bosonnlp.com)
这个数据集一共包含了6个类别:
time: 时间
location: 地点
personname: 人名
orgname: 组织名
companyname: 公司名
productname: 产品名
例如:
{productname:浙江在线杭州}{time:4 月 25 日}讯(记者{personname: 施宇翔} 通讯员 {personname:方英})毒贩很“时髦”,用{productname:微信}交易毒品。没料想警方也很“潮”,将计就计,一举将其擒获。
每个实体用都用大括号括了起来,并标明实体类别。当然自己标注的时候也不一定要这么标,只要能提取出来就可以。
然后我们要做的就是把原始数据按照 BMEO 规则变成字标注的形式,以便模型训练。按字标注后的结果如下:
浙/Bproductname 江/Mproductname 在/Mproductname 线/Mproductname 杭/Mproductname 州/Eproductname 4/Btime 月/Mtime 2/Mtime 5/Mtime 日/Etime 讯/O (/O 记/O 者/O /Bpersonname 施/Mpersonname 宇/Mpersonname 翔/Epersonname /O 通/O 讯/O 员/O /O 方/Bpersonname 英/Epersonname )/O 毒/O 贩/O 很/O “/O 时/O 髦/O ”/O ,/O 用/O 微/Bproductname 信/Eproduct_name 交/O 易/O 毒/O 品/O 。/O 没/O 料/O 想/O 警/O 方/O 也/O 很/O “/O 潮/O ”/O ,/O 将/O 计/O 就/O 计/O ,/O 一/O 举/O 将/O 其/O 擒/O 获/O 。
然后我们习惯按照标点符号把一个长句分成几个短句:
浙/Bproductname 江/Mproductname 在/Mproductname 线/Mproductname 杭/Mproductname 州/Eproductname 4/Btime 月/Mtime 2/Mtime 5/Mtime 日/Etime 讯/O
记/O 者/O /Bpersonname 施/Mpersonname 宇/Mpersonname 翔/Epersonname /O 通/O 讯/O 员/O /O 方/Bpersonname 英/Epersonname
毒/O 贩/O 很/O
时/O 髦/O
用/O 微/Bproductname 信/Eproduct_name 交/O 易/O 毒/O 品/O
没/O 料/O 想/O 警/O 方/O 也/O 很/O
潮/O
将/O 计/O 就/O 计/O
一/O 举/O 将/O 其/O 擒/O 获/O
然后的思路就是建立一个 word2id 词典,把每个汉字转换成 id。这里习惯性按照数据集中每个汉字出现的次数排序,id 从 1 开始。

再建立一个 tag2id 词典,把每一个字标注的类型转换成 id。
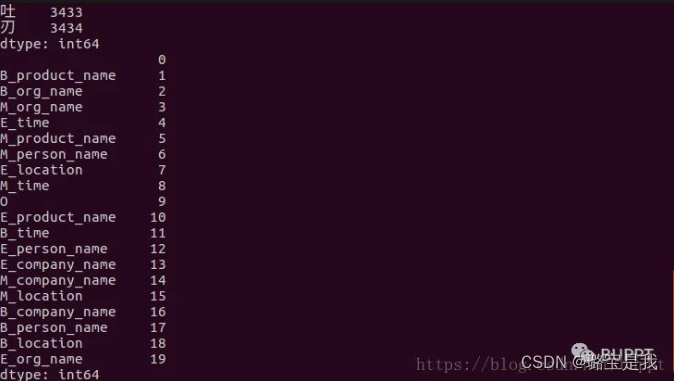
之后就把刚按标点分开的数据,按照一一对应的顺序,把汉字和每个字的标签转换成 id,分别存到两个数组里面,一起保存到一个 pkl 文件中,这样模型使用时候就可以直接读取,不用每次都处理数据了。这里习惯把每一句话都转换成一样的长度。这个长度当然是自己设置的,比它长的就把后面舍弃,比它短的就在后面补零。

这里第一个数组里是这句话汉字转换成的 id,第二个数组里存的是这句话每个字的标注转换成的 id。
2.训练
本项目基于pytorch,使用的是pytorch tutorial里的Bilstm+crf模型。
使用 python train.py 开始训练,训练的模型会存到 model 文件夹中。
3.使用预训练的词向量
使用 python train.py pretrained 会使用预训练的词向量开始训练,vec.txt 是在网上找的一个比较小的预训练词向量,可以参照我的代码修改使用其他更好的预训练词向量。
4.测试训练好的模型
使用 python train.py test 进行测试,会自动读取 model 文件夹中最新的模型,输入中文测试即可,测试结果好坏根据模型的准确度而定。
5.准确度判断
命名实体识别的准确度判断有三个值。准确率、召回率和 f 值。
这里需要先定义一个交集,是经过模型抽取出来的实体,与数据集中的所有实体,取交集。
准确率=交集/模型抽取出的实体
召回率=交集/数据集中的所有实体
f 值=2×(准确率 × 召回率) / (准确率+召回率)
Result
(待补充)

