
- 1鸿蒙开发过程中(DevEco Studio)使用远程真机连接端口异常的解决办法_hdc: hdc_server_port must be set to a positive num
- 2IOS面试题编程机制 31-35
- 3AI作画的业界天花板被我找到了,AIGC模型揭秘 | 昆仑万维_singularity openapl
- 4分享63个微信小程序源代码总有一个是你想要的_微信小程序开源源代码
- 5Java LinkedList类和Vector类_mybug鞋
- 6HarmonyOS中利用overflow属性实现横向滚动失效的解决方法_横向滚动条失效
- 7vue+element实现树状表格的增删改查;使用el-table树形数据与懒加载实现树状表格增删改查_vue3树形表格添加数据
- 8遇见这些APP,我觉得世界都变得温柔了_devcheck csdn
- 9Python圣诞树_python圣诞树代码源码
- 10【DBeaver】建立连接报驱动问题can‘t load driver class ‘org.postgresql.Driver_dbeaver连接pg数据库缺少驱动
图像处理-特征点(ORB、SIFT)
赞
踩
Reference:
- 高翔,张涛 《视觉SLAM十四讲》
- [ORB-SLAM2] ORB-SLAM中的ORB特征(提取)
- 尺度不变特征转换-SIFT
- Distinctive Image Featuresfrom Scale-Invariant Keypoints
特征点是图像里一些特别的地方。我们可以把图像中的角点、边缘和区块都当成图像中有代表性的地方。不过当两幅图像中出现同一个角点时,会更容易指出;同一个边缘稍微困难一些,因为沿着该边缘前进,图像局部是相似的;同一个区块则是最困难的。所以,一种直观的提取特征的方式是在不同图像间辨认角点,确定它们的对应关系。在这种做法中,角点就是所谓的特征。
 然而很多情况中单纯的角点并不适用。例如,在远处看上去是角点的地方,当相机走近之后,很可能就不再是角点了。或者在旋转相机时,角点外观会发生变化,也就不容易辨认出那是同一个角点,因此设计了许多更加稳定的局部图像特征,如:SIFT, SURF, ORB 等。
然而很多情况中单纯的角点并不适用。例如,在远处看上去是角点的地方,当相机走近之后,很可能就不再是角点了。或者在旋转相机时,角点外观会发生变化,也就不容易辨认出那是同一个角点,因此设计了许多更加稳定的局部图像特征,如:SIFT, SURF, ORB 等。
特征点由关键点(Key-point)和描述子(Descriptor)两部分组成。
关键点是指该特征点在图像里的位置,有些特征点还具有朝向、大小等信息。描述子通常是一个向量,按照某种人为设计的方式,描述了该关键点周围像素的信息。描述子是按照“外观相似的特征应该有相似的描述子”的原则设计的。因此,只要两个特征点的描述子在向量空间上的距离相近,就可以认为它们是相同的特征点。
1. 特征点响应值/描述子的区别
- 响应值:描述的是该特征点的区分度大小。
响应值越大的点越该被留用作特征点。
响应值类似于分数,分数越高的学生越好,越应该被录取。 - 描述子:特征点的一个哈希运算。
其大小无意义,仅用来在数据库中快速找回某特征点。
描述子相当于学生的学号,系统随机运算出的一串数,用于找到学生。
2. ORB 特征
ORB 特征由关键点和描述子两部分组成。它的关键点称为“Oriented Fast”,是一种改进的 FAST 角点,它的描述子称为 BRIEF。因此,提取 ORB 特征步骤如下:
- 1.FAST 角点提取:找出图像中“角点”。相较于原版的 FAST,ORB 中计算了特征点的主方向,为后续的 BRIEF 描述子添加了旋转不变特性;
- 2.BRIEF 描述子:对前一步提取出特征点的周围图像区域进行描述。ORB 对 BRIEF 进行了一些改进,主要是指在 BRIEF 中使用了先前计算的方向信息。
2.1 FAST 关键点
FAST 是一种检点,主要检测局部像素灰度变化明显的地方,以速度快著称。它的思想是:如果一个像素与它领域的像素差别较大(过亮或过暗),那它更可能是角点。相比于其他角点检测算法,FAST 只需比较像素亮度的大小,十分快捷。它的检测过程如下:
- 在图像中选取像素 p p p,假设它的亮度为 I p I_p Ip;
- 设置一个阈值 T T T(比如 I p I_p Ip 的 20%);
- 以像素 p p p 为中心,选取半径为 3 的圆上的 16 个像素点;
- 假如选取的圆上,有连续的 N 个点的亮度大于 I p + T I_p+T Ip+T 或小于 I p − T I_p-T Ip−T,那么像素 p p p 可以被认为是特征点(N 通常取 12,即为 FAST-12。其它常用的 N 取值为 9 和 11,他们分别被称为 FAST-9, FAST-11);
- 循环以上四步,对每一个像素执行相同的操作。
在 FAST-12 算法中,为了更高效,可以添加一项预测试操作,以快速地排除绝大多数不是角点的像素。具体操作为,对于每个像素,直接检测邻域圆上的第 1, 5, 9, 13 个像素的亮度。只有当这四个像素中有三个同时大于 I p + T I_p + T Ip+T 或小于 I p − T I_p − T Ip−T 时,当前像素才有可能是一个角点,否则应该直接排除。这样的预测试操作大大加速了角点检测。此外,原始的 FAST 角点经常出现“扎堆”的现象。所以在第一遍检测之后,还需要用非极大值抑制(Non-maximal suppression),在一定区域内仅保留响应极大值的角点,避免角点集中的问题。

FAST 特征点的计算仅仅是比较像素间亮度的差异,速度非常快,但它也有重复性不强、分布不均匀的缺点。此外,FAST 的角点不具有方向信息。同时,由于它固定取半径为 3 的圆,存在尺度问题:远处看像是角点的地方,接近后看可能就不是角点了。针对 FAST 角点不具有方向性和尺度性的弱点,ORB 添加了尺度和旋转描述。尺度不变性由构建图像金字塔(对图像进行不同层次的降采样,以获得不同分辨率的图像。匹配不同层上的图像就可以实现尺度不变性),并在金字塔的每一层上检测角点来实现;特征的旋转是由灰度质心法实现的。
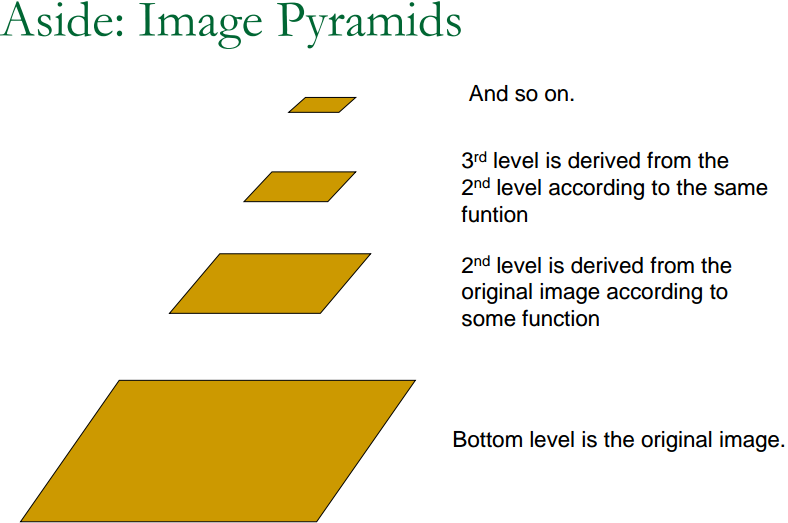
2.1.1 图像金字塔

金字塔是计算图视觉中常用的一种处理方法。金字塔底层是原始图像,每往上一层,就对图像进行一个固定倍率的缩放,这样我们就有了不同分辨率的图像。较小的图像可以看成是远处看过来的场景。在特征匹配算法中,我们可以匹配不同层上的图像,从而实现尺度不变性。例如,如果相机在后退,那么我们应该能够在上一个图像金字塔的上层和下一个图像金字塔的下层中找到匹配。


2.1.2 灰度质心法
在旋转方面,我们计算特征点附近的图像灰度质心。所谓质心是指以图像块灰度值作为权重的中心。其具体操作步骤如下:
- 在一个小的图像块 B 中,定义图像块的矩为:
m p q = ∑ x , y ∈ B x p y q I ( x , y ) , p , q = { 0 , 1 } m_{p q}=\sum_{x, y \in B} x^{p} y^{q} I(x, y), \quad p, q=\{0,1\} mpq=x,y∈B∑xpyqI(x,y),p,q={0,1} - 通过矩可以找到图像块的质心(这玩意就是图像块的亮度均值):
C = ( m 10 m 00 , m 01 m 00 ) C=(\frac{m_{10}}{m_{00}},\frac{m_{01}}{m_{00}}) C=(m00m10,m00m01) - 连接图像块的几何中心
O
O
O 与质心
C
C
C,得到一个方向向量
O
C
→
\overrightarrow{OC}
OC
,于是特征点的方向可以定义为:
θ = a r c t a n ( m 01 / m 10 ) \theta = arctan(m_{01}/m_{10}) θ=arctan(m01/m10)
ORB SLAM 上显示的 ORB 特征点检测结果如下:

从图中可以看出,在旋转方面,假设一个点右边是一片亮而左边是一片暗的,则这个点的旋转会指向右边,即这个点附近的图像梯度指向的一个角度。(圆圈大小看起来是连接图像块的几何中心
O
O
O 与质心
C
C
C 所得到的方向向量
O
C
→
\overrightarrow{OC}
OC
)
通过以上方法,FAST 角点便具有了尺度与旋转的描述,从而大大提升了其在不同图像之间表述的鲁棒性。所以在 ORB 中,把这种改进后的 FAST 称为 Oriented FAST。
2.2 BRIEF 描述子
在提取 Oriented FAST 关键点后,我们对每个点计算其描述子。ORB 使用改进的 BRIEF 特征描述。我们
BRIEF 是一种二进制描述子,它的描述向量由许多个 0 和 1 组成,这里的 0 和 1 编码了关键点附近两个像素(比如说 p p p 和 q q q)的大小关系:如果 p p p 比 q q q 大,则取 1,反之就取 0。如果我们取了 128 个这样的 p p p, q q q,最后就得到 127 维由 0,1 组成的向量。作者原始论文中给出了若干种 p p p 和 q q q 的挑选方法,大体上都是按照某种概率分布,随机地挑选 p p p 和 q q q 的位置。BRIEF 使用了随机选点的比较,速度非常快,而且由于使用了二进制表达,存储起来也十分方便,适用于实时的图像匹配。原始的 BRIEF 描述子不具有旋转不变性的,因此在图像发生旋转时容易丢失。而 ORB 在 FAST 特征点提取阶段计算了关键点的方向,所以可以利用方向信息,计算了旋转之后的“Steer BRIEF"特征,使 ORB 的,描述子具有较好的旋转不变性。
由于考虑到了旋转和缩放,使得 ORB 在平移、旋转、缩放的变换下仍有良好的表现。同时,FAST 和 BRIEF 的组合也非常高效,因此 ORB 特征在实时 SLAM 中非常受欢迎。
2.3 特征匹配
特征匹配是视觉 SLAM 中极为关键的一步,宽泛地说,特征匹配解决了 SLAM 中的数据关联问题(data association),即确定当前看到的路标与之前看到的路标之间的对应关系。通过对图像与图像,或者图像与地图之间的描述子进行准确的匹配,我们可以为后续的姿态估计,优化等操作减轻大量负担。然而,由于图像特征的局部特性,误匹配的情况广泛存在,而且长期以来一直没有得到有效解决,目前已经成为视觉 SLAM 中制约性能提升的一大瓶颈。部分原因是因为场景中经常存在大量的重复纹理,使得特征描述非常相似。在这种情况下,仅利用局部特征解决误匹配是非常困难的。
不过,让我们先来看正确匹配的情况,等做完实验再回头去讨论误匹配问题。考虑两个时刻的图像。如果在图像
I
t
I_t
It 中提取到特征点
x
t
m
x^m_t
xtm ,
m
=
1
,
2
,
.
.
.
,
M
m = 1,2,..., M
m=1,2,...,M,在图像
I
t
+
1
I_{t+1}
It+1 中提取到特征点
x
t
+
1
n
x^n_{t+1}
xt+1n,
n
=
1
,
2
,
.
.
.
,
N
n = 1, 2,... ,N
n=1,2,...,N,如何寻找这两个集合元素的对应关系呢?最简单的特征匹配方法就是暴力匹配(Brute-Force Matcher) 。即对每一个特征点
x
t
m
x^m_t
xtm ,与所有的
x
t
+
1
n
x^n_{t+1}
xt+1n 测量描述子的距离,然后排序,取最近的一个作为匹配点。描述子距离表示了两个特征之间的相似程度,不过在实际运用中还可以取不同的距离度量范数。对于浮点类型的描述子,使用欧氏距离进行度量即可。而对于二进制的描述子(比如 BRIEF 这样的),我们往往使用汉明距离(Hamming distance)做为度量——两个二进制串之间的汉明距离,指的是它们不同位数的个数。
然而,当特征点数量很大时,暴力匹配法的运算量将变得很大,特别是当我们想要匹配一个帧和一张地图的时候。这不符合我们在 SLAM 中的实时性需求。此时快速近似最近邻(FLANN) 算法更加适合于匹配点数量极多的情况。
2.4 ORB-SLAM2对ORB特征的改进
ORB-SLAM2 中并没有使用 OpenCV 的实现,因为 OpenCV 上 API 提取的 ORB 特征过于集中,会出现扎堆的现象—这会降低 SLAM 的精度,对于闭环来说,会降低一副图像上的信息量。ORB-SLAM2 中的实现提高了特征分布的均匀性。
最简单的一种方法是把图像划分成若干个小格子 ,每个小格子里面保留质量最好的 n n n 个特征点。这种方法看似不错,实际上会有一些问题。当有些格子里面能够提取数量不足 n n n 个的时候(无纹理区域),整幅图像上提取的特征总量就达不到我们想要的数量,这样 SLAM 很容就会跟丢。
ORB-SLAM 中的实现就解决了这么一个问题,当一个格子提取不到 FAST 点的时候,会自动降低阈值。ORB-SLAM 主要改进了 FAST 角点提取步骤:
- 1.对于金字塔的每一层;
- 2.划分格子,格子的大小为 30 × 30 30\times30 30×30 pixels;
- 3.单独对每个格子提取 FAST 角点,如果提取不到点,就降低 FAST 阈值。这样保证纹理较弱的区域也能提取到一些 FAST 角点。这一步骤可以提取大量的 FAST 点;
- 4.基于四叉树,均匀的选取 N a N_a Na 个 FAST 点。
上述步骤中,基于四叉树的方法有点复杂,下面分析一下:
- 1.如果图片的宽度比较宽,就先将图像的长和宽分成 w/h 份。一般的 640 × 480 640\times480 640×480 的图像开始的时候只有一个 node;
- 2.如果node里面的点数>1,把每个 node 分成四个 node,如果 node 里面的特征点为空,就删掉;
- 3.新分的 node 的点数>1,就再分裂成4个node。如此,一直分裂;
- 4.终止条件:node 的总数量> N a N_a Na,或者无法再进行分裂。
通过图像可以说明四叉树选点方式:

3. SIFT
SIFT 为 Scale-invariant feature transform,即尺度不变特征变换。
3.1 动机
- Harris 算子对尺度不恒定,相关性对旋转不恒定;
- 为了更好的图像匹配,目标开发一个对尺度和旋转不变的兴趣算子;
- 创建一个描述符,该描述符对与典型的观测条件相对应的变化是鲁棒的。描述子是 SIFT 中最常用的部分。
3.2 SIFT 步骤
SIFT 主要包含以下四个步骤:
3.2.1. Scale-space extrema detection
尺度空间极值检测
通过使用高斯差分函数来计算并搜索所有尺度上的图像位置,用于识别对尺度和方向不变的潜在兴趣点。
这里也是用到了图像金字塔的概念,金字塔就不过多赘述,可见上面讲解。
尺度空间理论:
在图像信息处理模型中引入一个被视为尺度的参数,通过连续变化尺度参数获得多尺度下的尺度空间表示序列,对这些序列进行尺度空间主轮廓提取,并以该主轮廓作为一种特征向量,实现边缘、角点检测和不同分辨率上的特征提取等。
尺度空间方法将传统的单尺度图像信息处理技术纳入尺度不断变化的动态分析框架中,更容易获取图像的本质特征。尺度空间中各尺度图像的模糊程度逐渐变大,能够模拟人在距离目标由近到远时目标在视网膜上的形成过程。

高斯金字塔每个组(octave)有
s
+
3
s+3
s+3 幅图像,
s
s
s 意味着在高斯差分金字塔中求极值点时,我们要在每个octave中求
s
s
s 层点,而每一层的极值点都是在三维空间中比较获得,至于怎么比较的,后边会介绍,因此为了获得
s
s
s 层点,那么高斯差分金字塔就需要
s
+
2
s+2
s+2 幅图像,高斯金字塔就需要
s
+
3
s+3
s+3 幅图像。
由上图可见,
(
σ
,
s
)
(\sigma,s)
(σ,s) 构成了高斯金字塔的尺度空间,
σ
\sigma
σ 控制金字塔中尺寸的尺度,
s
s
s 控制在octave中不同的模糊程度。其中构建高斯差分金字塔所需要的公式如下:
L
(
x
,
y
,
σ
)
=
G
(
x
,
y
,
σ
)
∗
I
(
x
,
y
)
G
(
x
,
y
,
σ
)
=
1
2
π
σ
2
e
−
(
x
2
+
y
2
)
/
2
σ
2
D
(
x
,
y
,
σ
)
=
(
G
(
x
,
y
,
k
σ
)
−
G
(
x
,
y
,
σ
)
)
∗
I
(
x
,
y
)
=
L
(
x
,
y
,
k
σ
)
−
L
(
x
,
y
,
σ
)
上述公式中 L ( x , y , σ ) L(x,y,\sigma) L(x,y,σ) 函数表示的是一个图像的尺度空间(the scale space of an image), I ( x , y ) I(x,y) I(x,y) 表示一张输入的图片(an input image), G ( x , y , σ ) G(x,y,\sigma) G(x,y,σ) 代表尺度变化的高斯函数(a variable-scale Gaussian), D ( x , y , σ ) D(x,y,\sigma) D(x,y,σ) 表示高斯差分尺度空间。
Tony Lindeberg 指出尺度规范化的 LoG(Laplacion of Gaussian) 算子具有真正的尺度不变性,Lowe使用的 高斯差分金字塔 近似LoG算子,用来在尺度空间检测稳定的关键点。下图为 DoG 效果:

1994年Lindeberg研究发现高斯差分函数(difference-of-Gaussian function)和尺度归一化的拉普拉斯高斯函数(scale-normalized Laplacian of Gaussian)—— 非常相似,2002年Mikolajczyk发现,相比于其他的函数,如梯度(the gradient)、黑塞矩阵(Hessian)、Harris corner function等,尺度归一化的拉普拉斯高斯函数的极大值和极小值能够产生最稳定的图像特征(the most stable image features)。
对于为什么能用高斯差分金字塔来近似LoG算子,以及和
σ
2
∇
2
G
\sigma^2\nabla^2G
σ2∇2G 之间的关系,论文中给出了简单的介绍:
对高斯函数求偏导可得:
∂
G
∂
σ
=
−
2
σ
2
+
x
2
+
y
2
2
π
σ
5
e
−
(
x
2
+
y
2
)
/
2
σ
2
\frac{\partial G}{\partial \sigma}=\frac{-2 \sigma^{2}+x^{2}+y^{2}}{2 \pi \sigma^{5}} e^{-\left(x^{2}+y^{2}\right) / 2 \sigma^{2}}
∂σ∂G=2πσ5−2σ2+x2+y2e−(x2+y2)/2σ2
再来看看LoG算子:
L
(
x
,
y
)
=
∇
2
G
(
x
,
y
,
σ
)
=
∂
2
G
∂
x
2
+
∂
2
G
∂
y
2
=
−
2
σ
2
+
x
2
+
y
2
2
π
σ
6
e
−
(
x
2
+
y
2
)
/
2
σ
2
L(x,y)=\nabla^{2} G(x,y,\sigma)=\frac{\partial^{2} G}{\partial x^{2}}+\frac{\partial^{2} G}{\partial y^{2}}=\frac{-2 \sigma^{2}+x^{2}+y^{2}}{2 \pi \sigma^{6}} e^{-\left(x^{2}+y^{2}\right) / 2 \sigma^{2}}
L(x,y)=∇2G(x,y,σ)=∂x2∂2G+∂y2∂2G=2πσ6−2σ2+x2+y2e−(x2+y2)/2σ2
得到
∂
G
∂
σ
=
σ
∇
2
G
\frac{\partial G}{\partial \sigma}=\sigma \nabla^{2} G
∂σ∂G=σ∇2G。
由导数定义:
∂
G
∂
σ
=
lim
Δ
σ
→
0
G
(
x
,
y
,
σ
+
Δ
σ
)
−
G
(
x
,
y
,
σ
)
(
σ
+
Δ
σ
)
−
σ
≈
G
(
x
,
y
,
k
σ
)
−
G
(
x
,
y
,
σ
)
k
σ
−
σ
\frac{\partial G}{\partial \sigma}=\lim _{\Delta \sigma \rightarrow 0} \frac{G(x, y, \sigma+\Delta \sigma)-G(x, y, \sigma)}{(\sigma+\Delta \sigma)-\sigma} \approx \frac{G(x, y, k \sigma)-G(x, y, \sigma)}{k \sigma-\sigma}
∂σ∂G=limΔσ→0(σ+Δσ)−σG(x,y,σ+Δσ)−G(x,y,σ)≈kσ−σG(x,y,kσ)−G(x,y,σ)
代入上面公式,可得到:
G
(
x
,
y
,
k
σ
)
−
G
(
x
,
y
,
σ
)
≈
(
k
−
1
)
σ
2
∇
2
G
G(x, y, k \sigma)-G(x, y, \sigma) \approx(k-1) \sigma^{2} \nabla^{2} G
G(x,y,kσ)−G(x,y,σ)≈(k−1)σ2∇2G
因此上述式子就解释了为什么能够用高斯差分函数来近似拉普拉斯高斯函数,当 k = 2 k=2 k=2 时,就已经是拉普拉斯高斯函数了。公式中的 k − 1 k-1 k−1 并不影响极值点的位置。如下图所示:
 红色曲线表示的是高斯差分算子,而蓝色曲线表示的是高斯拉普拉斯算子,Lowe 使用更高效的高斯差分算子代替拉普拉斯算子进行极值检测。实际上
k
k
k 并不一定很小。
红色曲线表示的是高斯差分算子,而蓝色曲线表示的是高斯拉普拉斯算子,Lowe 使用更高效的高斯差分算子代替拉普拉斯算子进行极值检测。实际上
k
k
k 并不一定很小。
k k k 的值事实上影响不大。我们选择将尺度空间的每个 octave 的尺度空间划分进整数 s s s 个间隔,即 k = 2 1 / s k=2^{1/s} k=21/s,上面图像中已经显示出来了。我们必须在每个 octave 的模糊图像堆栈中产生 s + 3 s+3 s+3 个图像,以便最终的极值检测覆盖一个完整的 octave。
高斯金字塔的构建,除了上面描述的,对图像做不同尺度的高斯模糊,还需要对图像做降采样。
上边所描述的只是进行高斯处理的过程,而我们还要得到金字塔形状。高斯图像使用因素 2 下采样,金字塔组数的计算公式如下:
o
=
log
2
{
min
(
M
,
N
)
}
−
t
,
t
∈
[
0
,
log
2
{
min
(
M
,
N
)
}
]
o=\log _{2}\{\min (M, N)\}-t, t \in\left[0, \log _{2}\{\min (M, N)\}\right]
o=log2{min(M,N)}−t,t∈[0,log2{min(M,N)}]
为了让尺度体现其连续性,高斯金字塔在简单的降采样的基础上加上了高斯滤波,让图像金字塔每组含有多张高斯模糊图像。另外,在进行降采样时,高斯金字塔隔点取点(图像大小减半了),最终会将一个 n ∗ n n*n n∗n 的图像变为 n 2 ∗ n 2 \frac{n}{2}*\frac{n}{2} 2n∗2n 的图像。
而关于尺度空间:
- Octave 1 使用尺度 σ \sigma σ;
- Octave 2 使用尺度 2 σ 2\sigma 2σ;
- …
3.2.2. Keypoint localization
关键点定位
通过一个拟合精细的模型在每个候选位置上确定位置和尺度,关键点的选择依赖于它们的稳定程度。
关键点是由 DoG 空间的局部极值点(maxima and
minima )组成,关键点的初步筛查是通过同一组内各 DoG 相邻两层图像之间比较完成的。需要比较同尺度的 8 个领域点和上下相邻尺度对应的 9*2 个点,共 26 个点。极值点的检测只在同一组中从第 2 层开始至倒数第 2 层为止。(进一步解释了为啥之前是
s
+
2
s+2
s+2 层)

在老哥做了大量的实验后证明,在
S
=
3
S=3
S=3 时,会有最佳效果。
通过上边所述的方法检测到的极值点是离散空间的极值点,这里获得到的极值点并不是十分准确,我们需要来精确确定关键点的位置和尺度,同时去除低对比度的关键点和不稳定的边缘响应点(因为DoG算子会产生较强的边缘相应),依次来增强匹配稳定性以及提高抗噪声能力。
边缘响应个人理解:边缘的对比度较低,因此在极值点检测时很容易被当做候选极值点,此外,低对比度的点很容易受到噪声的影响,作为特征点的边缘点就是不稳定的,这两点加起来就是边缘响应。

在 Brown 和 Lowe 比较新的论文中,通过拟合三维二次函数来精确确定关键点的位置和尺度。为了提高关键点的稳定性,对尺度空间DoG函数进行曲线拟合,用泰勒公式展开得:
D
(
x
)
=
D
+
∂
D
T
∂
x
x
+
1
2
x
T
∂
2
D
∂
x
2
x
x
=
(
x
,
y
,
σ
)
T
已知极值
x
^
\hat{\mathbf{x}}
x^ 位置的导数等于 0,可得极值点的偏移量为:
x
^
=
−
∂
2
D
∂
x
2
−
1
∂
D
∂
x
\hat{\mathbf{x}}=-\frac{\partial^{2} D}{\partial \mathbf{x}^{2}}^{-1} \frac{\partial D}{\partial \mathbf{x}}
x^=−∂x2∂2D−1∂x∂D
当它在任一维度上的偏移量
(
x
,
y
)
>
0.5
(x,y)>0.5
(x,y)>0.5 时,意味着极值离另一采样点更近,所以必须改变当前关键点的位置,同时在新的位置上反复插值直到收敛。
上面两式合并,得:
D
(
x
^
)
=
D
+
1
2
∂
D
T
∂
x
x
^
D(\hat{\mathbf{x}})=D+\frac{1}{2} \frac{\partial D^{T}}{\partial \mathbf{x}} \hat{\mathbf{x}}
D(x^)=D+21∂x∂DTx^
D ( x ^ ) D(\hat{\mathbf{x}}) D(x^) 使用低对比度来筛选不稳定的极值点。在 ∣ D ( x ^ ) ∣ < 0.03 |D(\hat{\mathbf{x}})|<0.03 ∣D(x^)∣<0.03 时抛弃点。
为了稳定性,只抛弃低对比度的关键点是不够的。即使沿着边缘的位置确定的很差,DoG 沿着边缘也会有很强的反应,从而产生噪声。一个被定义但不好的 DoG 函数的极值在横跨边缘的地方有较大主曲率,而在垂直边缘的方向有较小的主曲率。这里使用 Hessian 矩阵来消除边缘响应。Hessian 在SLAM 中应用广泛,也不在此赘述。

3.2.3. Orientation assignment
方向匹配
基于局部图像的梯度方向,为每个关键点位置分配一个或多个方向,后续所有对图像数据的操作都是相对于关键点的方向、尺度和位置进行变换,从而为这些变换提供了不变性。
因为这一步是关键点方向分配,所以需要对我们上一步得到的关键点进行处理。围绕该点选择一个窗口,窗口为圆形区域,以该特征点为中心,半径为 3 作为一个圆域,窗口内各采样点的梯度方向构成一个直方图,根据直方图的峰值确定特征点的主方向。如下图所示:
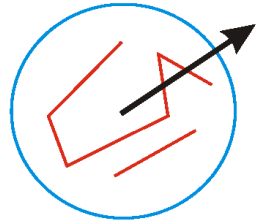
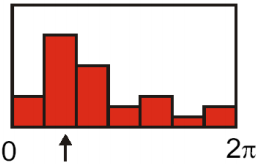
直方图的峰值确定以后,任何大于峰值 80% 的方向创建一个具有该方向的特征点,这个方向认为是特征点的辅方向。因此,对于多峰值的情况,在同一位置和尺度就会产生多个具有不同方向的关键点,就是将该特征点复制成多份特征点,除了方向不同,其他都相同。
4. Keypoint description
关键点描述
这个和HOG算法有点类似之处,在每个关键点周围的区域内以选定的比例计算局部图像梯度,这些梯度被变换成一种表示,这种表示允许比较大的局部形状的变形和光照变化。
通过上面步骤,每个特征点被分配了坐标位置、尺度和方向。在图像局部区域内,这些参数可以重复的用来描述局部二维坐标系统,因为这些参数具有不变性。
 标准化
标准化
- 将窗口旋转到标准方向;
- 根据找到点的尺度缩放窗口大小。
Lowe’s Keypoint Descriptor
- 使用关键点的标准化区域;
- 计算区域中每一个点的梯度大小和方向;
- 用覆盖在圆上的高斯窗口加权它们;
- 在窗口的 4x4 个子区域上创建一个方向直方图;
- 在实践中使用了 16 × 16 样本阵列上的 4 × 4 描述符。4x4 乘以 8 个方向给出了 128 个值的向量。


