
- 1SpringBoot集成自然语言处理hanlp工具包_springboot 集成hanlp
- 2【GlobalMapper精品教程】022:根据一个字段属性值批量计算另一个字段属性值(地类名称求地类编码)_arcgis 计算 不同编码
- 3【AcWing】蓝桥杯集训每日一题Day14|Flood Fill|洪水灌溉算法|DFS|并查集|687.扫雷(C++)
- 4【Hadoop】Hadoop车辆数据存储_基于hadoop的公共自行车数据分布式存储和计算
- 5Django高级扩展之中间件
- 6头歌 实验六 java输入输出_本关任务:从文件读取一篇英语文章,然后统计26个英文字母出现的次数。
- 7【无标题】嘻嘻嘻嘻嘻嘻嘻_max_energy_0 = torch.max(energy, -1, keepdim=true)
- 8机器翻译评测----BLEU算法_bleu机器翻译
- 9【python】flask模板渲染引擎Jinja2,流程控制语句与过滤器的用法剖析与实战应用
- 10测试人员前期参与设计方案时需要注意什么?
大模型Tuning分类_大模型各种 tunning
赞
踩
类型总结
微调(Fine-tunning)
语言模型的参数需要一起参与梯度更新
轻量微调(lightweight fine-tunning)
冻结了大部分预训练参数,仅添加任务层,语言模型层参数不变
适配器微调 (Adapter-tunning)
Adapter在预训练模型每层中插入用于下游任务的参数,在微调时将模型主体冻结,仅训练特定于任务的参数,减少训练时算力开销
提示学习(Prompting)
任务输入前添加一个自然语言任务指令和一些示例,直接在预训练语言模型中统一建模,比如GPT2/GPT3
前缀微调(Prefix-tuning)
将prompt方式扩展到连续空间,在每层输入序列前面添加prompt连续向量【随机初始化,并不对应到具体的token】目前是将语言模型freeze后,仅微调prompt参数,在实验中是增加了一个MLP重参数化,确保效果,使用MLP后的结果做预测
提示微调(Prompt-tuning)
将prompt扩展到连续空间,但是仅在输入层加入prompt连续向量,且不固定,同时使用LSTM建模prompt向量之间的关联性
【P-tuning与Prefix-tuning】:
- Prefix-tuning仅针对NLG任务生效,服务于GPT架构;P-tuning考虑所有类型的语言模型
- Prefix-tuning限定了在输入前面添加,P-tuning则可以在任意位置添加
- Prefix-tuning为了保证效果在每一层都添加,但p-tuning可以只在输入层添加
【P-tuning与fine-tuning】
P-tuning不改变预训练阶段模型参数,而是通过微调寻找更好的连续prompt提示,来引导已学习到的知识的使用;Fine-tuning可能在调整模型参数过程中,可能带来了灾难性遗忘问题
提示微调v2(Prompt-tuning)
在第一版基础上,将每层输入都添加上prompt连续向量,同时探索了prompt长度在不同规模的模型上的效果;去掉MLP层重参数化
指令微调(Instruct-tuning)
指令微调是会直接通过自然语言形式给出人类指令,是基于一组NLP任务集合上直接tuning的过程,它可以提高语言模型在未知任务上的效果,即zero-shot learning能力
【instruct-tuning 与 prompt-tuning】
- 提示微调:"我带女朋友去桂林旅游" 的英文翻译是___
- 指令微调:翻译这句话:输入:我带女朋友去桂林旅游,输出:_______
二者目的都是挖掘语言模型本身已掌握的知识,prompt是激发语言模型补全能力,是针对某特定任务而言,不同的任务需要给出不同的表达形式;instruct则是激发语言模型的理解能力,是针对任务集合而形成的指令,它能通过理解做什么任务,在未可见任务上泛化能力更强【zero-shot learning】
指令提示微调(Instruction Prompt tuning)
语境提示微调是指结合LLM的ICL能力和prompt-tuning结合到指令提示微调中,将检索到的上下文演示示例和可微调的prompt嵌入式表征进行拼接,能够让LLM在医学领域方面获得不错的应用效果
Large Language Models Encode Clinical Knowledge![]() https://arxiv.org/abs/2212.13138
https://arxiv.org/abs/2212.13138
Lora微调
- 前人研究发现模型是过参数化的,存在更小的内在维度,可以低秩分解的
- 固定预训练语言模型的参数,额外增加新的参数,增加低秩分解的矩阵可以适配下游任务
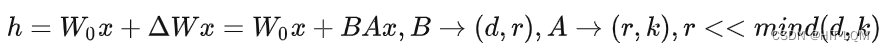
- 效果:训练参数量显著降低,显存需求减少(GPT-3 模型上能够把参数量降低到普通fine-tune的万分之一)
- 相比Adapters, LoRA不增加推理延迟

