
- 1Redis面试题-先更新数据库还是先更新缓存_先更新数据库,再更新缓存
- 2自然语言处理(NLP)实验——比较各大翻译系统_自然语言机器翻译实验结果
- 3“抖音”命名是靠它?解码字节跳动如何做A/B测试
- 4运算放大器工作原理
- 5机器学习---LDA代码(在二维平面上对数据进行分类,并通过可视化展示分类结果)_lda模型代码
- 6NLP考点_symbolic approach
- 7Stable Video Diffusion(SVD)安装和测试_stable video diffusion 安装
- 8解决mac pro 装 win10以后 蓝牙 卡顿的问题_双系统电脑蓝牙听歌一顿一顿的
- 9pytong之语音环境:edge-tts and edge-playback
- 10使用纹理对比度检测检测AI生成的图像_ai 对比度
大模型参数高效微调技术实战(四)-Prefix Tuning / P-Tuning v2_prefix_projection
赞
踩
大模型参数高效微调技术实战(四)-Prefix Tuning / P-Tuning v2
原创 吃果冻不吐果冻皮 吃果冻不吐果冻皮 2023-08-07 13:07 发表于浙江
收录于合集
#PEFT15个
#大模型40个
【点击】加入大模型技术交流群
随着,ChatGPT 迅速爆火,引发了大模型的时代变革。然而对于普通大众来说,进行大模型的预训练或者全量微调遥不可及。由此,催生了各种参数高效微调技术,让科研人员或者普通开发者有机会尝试微调大模型。
因此,该技术值得我们进行深入分析其背后的机理,之前分享了大模型参数高效微调技术原理综述的文章。下面给大家分享大模型参数高效微调技术实战系列文章,该系列共六篇文章,相关代码均放置在GitHub:llm-action。
-
大模型参数高效微调技术实战(一)-PEFT概述及环境搭建
-
大模型参数高效微调技术实战(四)-Prefix Tuning / P-Tuning v2
-
大模型参数高效微调技术实战(五)-LoRA
-
大模型参数高效微调技术实战(六)-IA3
本文为大模型参数高效微调技术实战的第四篇。由于,P-Tuning v2 为针对 Prefix Tuning 的改进;因此,在 PEFT 库中,两种实现基本一致(在prefix_tuning.py中)。
Prefix Tuning 简述
Prefix Tuning(论文:Prefix-Tuning: Optimizing Continuous Prompts for Generation),在输入token之前构造一段任务相关的virtual tokens作为Prefix;然后,在训练的时候只更新Prefix部分的参数,而 PLM 中的其他部分参数固定。
针对不同的模型结构,需要构造不同的 Prefix。
-
针对自回归架构模型:在句子前面添加前缀,得到
z = [PREFIX; x; y],合适的上文能够在固定 LM 的情况下去引导生成下文(比如:GPT3的上下文学习)。 -
针对编码器-解码器架构模型:Encoder和Decoder都增加了前缀,得到
z = [PREFIX; x; PREFIX0; y]。Encoder端增加前缀是为了引导输入部分的编码,Decoder 端增加前缀是为了引导后续token的生成。
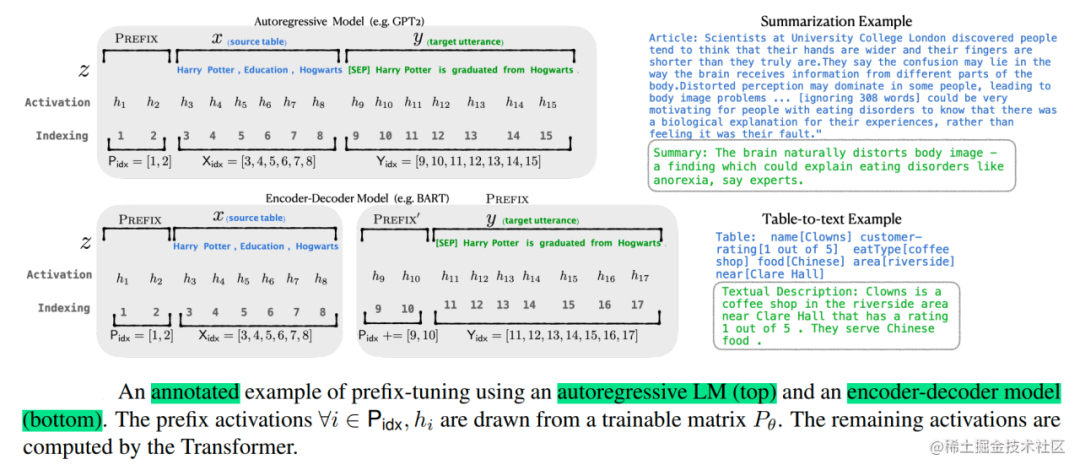
image.png
同时,为了防止直接更新 Prefix 的参数导致训练不稳定和性能下降的情况,在 Prefix 层前面加了 MLP 结构,训练完成后,只保留 Prefix 的参数。
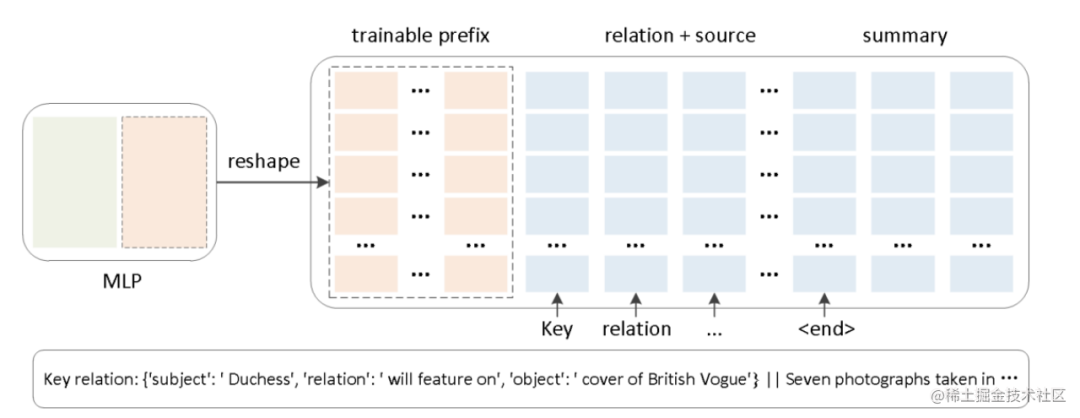
image.png
除此之外,通过消融实验证实,只调整embedding层的表现力不够,将导致性能显著下降,因此,在每层都加了prompt的参数,改动较大。
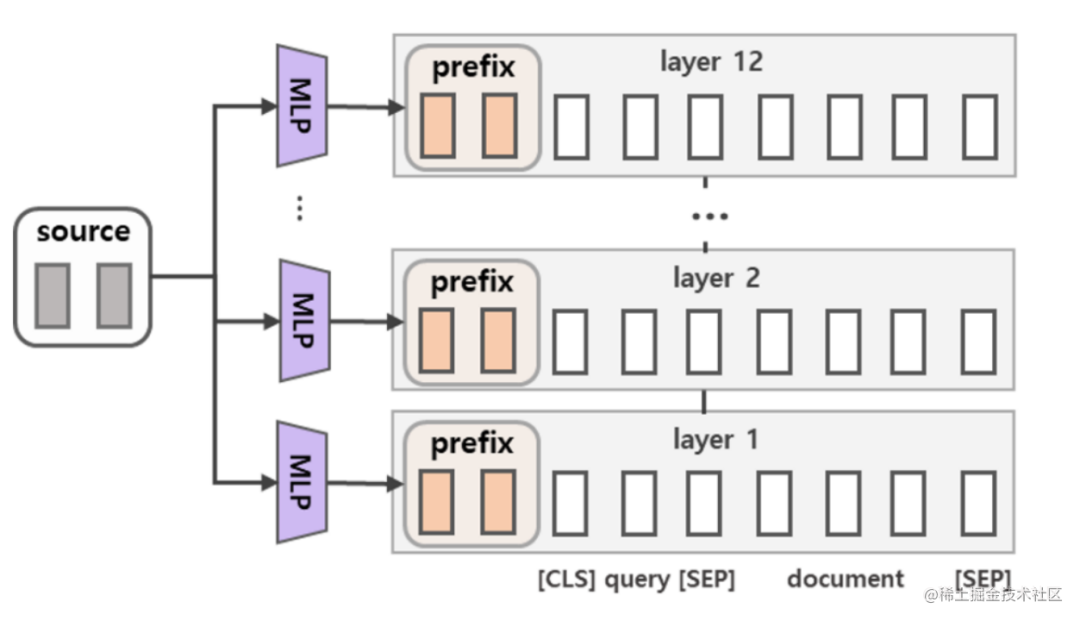
image.png
更加详细的介绍可参考之前的文章:大模型参数高效微调技术原理综述(二)-BitFit、Prefix Tuning、Prompt Tuning
P-Tuning v2 简述
P-Tuning v2(论文: P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks),该方法在每一层都加入了Prompts tokens作为输入,而不是仅仅加在输入层,这带来两个方面的好处:
-
更多可学习的参数(从P-tuning和Prompt Tuning的0.01%增加到0.1%-3%);同时,也足够参数高效。
-
加入到更深层结构中的Prompt能给模型预测带来更直接的影响。
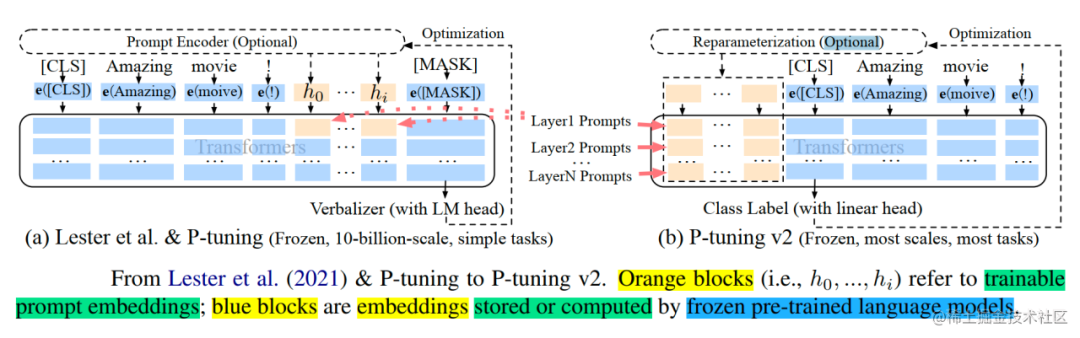
image.png
具体做法基本同Prefix Tuning,可以看作是将文本生成的Prefix Tuning技术适配到NLU任务中,然后做了一些改进:
-
移除重参数化的编码器。以前的方法利用重参数化功能来提高训练速度和鲁棒性(如:Prefix Tuning 中的 MLP 、P-Tuning 中的 LSTM)。在 P-tuning v2 中,作者发现重参数化的改进很小,尤其是对于较小的模型,同时还会影响模型的表现。
-
针对不同任务采用不同的提示长度。提示长度在提示优化方法的超参数搜索中起着核心作用。在实验中,发现不同的理解任务通常用不同的提示长度来实现其最佳性能,这与 Prefix-Tuning 中的发现一致,不同的文本生成任务可能有不同的最佳提示长度。
-
引入多任务学习。先在多任务的Prompt上进行预训练,然后再适配下游任务。多任务学习对我们的方法来说是可选的,但可能是相当有帮助的。一方面,连续提示的随机性给优化带来了困难,这可以通过更多的训练数据或与任务相关的无监督预训练来缓解;另一方面,连续提示是跨任务和数据集的特定任务知识的完美载体。我们的实验表明,在一些困难的序列任务中,多任务学习可以作为P-tuning v2的有益补充。
-
回归传统的分类标签范式,而不是映射器。标签词映射器(Label Word Verbalizer)一直是提示优化的核心组成部分,它将one-hot类标签变成有意义的词,以利用预训练语言模型头。尽管它在few-shot设置中具有潜在的必要性,但在全数据监督设置中,Verbalizer并不是必须的,它阻碍了提示调优在我们需要无实际意义的标签和句子嵌入的场景中的应用。因此,P-Tuning v2回归传统的CLS标签分类范式,采用随机初始化的分类头(Classification Head)应用于tokens之上,以增强通用性,可以适配到序列标注任务。
更加详细的介绍可参考之前的文章:大模型参数高效微调技术原理综述(三)-P-Tuning、P-Tuning v2。
Prefix Tuning / P-Tuning v2 实战
为了不影响阅读体验,详细的代码放置在GitHub:llm-action 项目中 peft_prefix_tuning_clm.ipynb 和peft_p_tuning_v2_clm.ipynb文件,这里仅列出关键步骤。
第一步,引进必要的库,如:Prefix Tuning / P-Tuning v2 配置类 PrefixTuningConfig。
from peft import get_peft_config, get_peft_model, PrefixTuningConfig, TaskType, PeftType
第二步,创建 Prefix Tuning / P-Tuning v2 微调方法对应的配置。
peft_config = PrefixTuningConfig(task_type=TaskType.CAUSAL_LM, num_virtual_tokens=30)
PrefixTuningConfig 配置类参数说明:
-
task_type:指定任务类型。如:条件生成任务(SEQ_2_SEQ_LM),因果语言建模(CAUSAL_LM)等。
-
num_virtual_tokens:虚拟token的数量,换句话说就是提示(prompt)。
-
inference_mode:是否在推理模式下使用Peft模型。
-
prefix_projection:是否投影前缀嵌入(token),默认值为false,表示使用P-Tuning v2, 如果为true,则表示使用 Prefix Tuning。
第三步,通过调用 get_peft_model 方法包装基础的 Transformer 模型。
- model = AutoModelForCausalLM.from_pretrained(model_name_or_path)
- model = get_peft_model(model, peft_config)
- model.print_trainable_parameters()
通过 print_trainable_parameters 方法可以查看到 P-Tuning v2 可训练参数的数量(仅为1,474,560)以及占比(仅为0.2629%)。
trainable params: 1,474,560 || all params: 560,689,152 || trainable%: 0.26299064191632515
PEFT 中 Prefix Tuning 相关的代码是基于清华开源的P-tuning-v2 进行的重构;同时,我们可以在chatglm-6b和chatglm2-6b中看到类似的代码。PEFT 中源码如下所示。
- class PrefixEncoder(torch.nn.Module):
- def __init__(self, config):
- super().__init__()
- self.prefix_projection = config.prefix_projection
- token_dim = config.token_dim
- num_layers = config.num_layers
- encoder_hidden_size = config.encoder_hidden_size
- num_virtual_tokens = config.num_virtual_tokens
- if self.prefix_projection andnot config.inference_mode:
- # Use a two-layer MLP to encode the prefix
- # 初始化重参数化的编码器
- self.embedding = torch.nn.Embedding(num_virtual_tokens, token_dim)
- self.transform = torch.nn.Sequential(
- torch.nn.Linear(token_dim, encoder_hidden_size),
- torch.nn.Tanh(),
- torch.nn.Linear(encoder_hidden_size, num_layers * 2 * token_dim),
- )
- else:
- self.embedding = torch.nn.Embedding(num_virtual_tokens, num_layers * 2 * token_dim)
-
- def forward(self, prefix: torch.Tensor):
- if self.prefix_projection:
- prefix_tokens = self.embedding(prefix)
- past_key_values = self.transform(prefix_tokens)
- else:
- past_key_values = self.embedding(prefix)
- return past_key_values

从上面的源码也可以看到 Prefix Tuning 与 P-Tuning v2 最主要的差别就是是否进行重新参数化编码。
第四步,模型训练的其余部分均无需更改,当模型训练完成之后,保存高效微调部分的模型权重以供模型推理即可。
- peft_model_id = f"{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}"
- model.save_pretrained(peft_model_id)
输出的模型权重文件如下所示:
- /data/nfs/llm/model/bloomz-560m_PREFIX_TUNING_CAUSAL_LM
- ├── [ 390] adapter_config.json
- ├── [5.6M] adapter_model.bin
- └── [ 93] README.md
-
- 0 directories, 3 files
注意:这里只会保存经过训练的增量 PEFT 权重。其中,adapter_config.json 为 P-Tuning v2 / Prefix Tuning 配置文件;adapter_model.bin 为 P-Tuning v2 / Prefix Tuning 权重文件。
第五步,加载微调后的权重文件进行推理。
- from peft import PeftModel, PeftConfig
-
- peft_model_id = f"{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}"
- config = PeftConfig.from_pretrained(peft_model_id)
- # 加载基础模型
- model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path)
- # 加载PEFT模型
- model = PeftModel.from_pretrained(model, peft_model_id)
-
- # 编码
- inputs = tokenizer(f'{text_column} : {dataset["test"][i]["Tweet text"]} Label : ', return_tensors="pt")
-
- # 模型推理
- outputs = model.generate(
- input_ids=inputs["input_ids"],
- attention_mask=inputs["attention_mask"],
- max_new_tokens=10,
- eos_token_id=3
- )
-
- # 解码
- print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))
至此,我们完成了 Prefix Tuning / P-Tuning v2 的训练及推理。
结语
本文对 Prefix Tuning / P-Tuning v2 的基本原理进行了简述;同时,讲解了使用 Prefix Tuning / P-Tuning v2 技术进行模型训练及推理。下文将对 LoRA 微调技术进行实战讲解。
如果觉得我的文章能够能够给您带来帮助,期待您的点赞收藏加关注~~

