
- 1python小波包分解_小波包获得某个节点信号的几个细节问题
- 2【毕业设计选题】基于深度学习的学生课堂行为检测算法系统 YOLO python 卷积神经网络 人工智能_基于深度学习的学生课堂行为检测系统设计与实现
- 3云计算_不能干预 云计算
- 4软件杯 深度学习LSTM新冠数据预测
- 5mysql的功能是什么_数据库的作用是什么
- 6【板栗糖GIS】supermap—如何将数据集合并为GDB格式导出_gis如何保存为gdb格式
- 72021前端面试题_,如果是在原生js空间,则会同步执行,修改三次state的值,调用三次render函数
- 8回溯法解决01背包问题_回溯算法与动态规划基于背包问题的浅析
- 9 一文读懂人工智能、机器学习、深度学习、强化学习的关系(必看) ...
- 10macOS Monterey 12.6.5 (21G531) 正式版发布,ISO、IPSW、PKG 下载_macos ipsw怎么在苹果服务器上下载
NLP-文本向量化:Word Embedding 一般步骤【字符串->分词->词汇序列化->词汇向量化】
赞
踩
一、字符串文本的序列化
在word embedding的时候,不会直接把文本转化为向量,而是先转化为数字,再把数字转化为向量,那么这个过程该如何实现呢?
这里我们可以考虑把文本中的每个词语和其对应的数字,使用字典保存,同时实现方法把句子通过字典映射为包含数字的列表。
实现文本序列化之前,考虑以下几点:
- 如何使用字典把词语和数字进行对应
- 不同的词语出现的次数不尽相同,是否需要对高频或者低频词语进行过滤,以及总的词语数量是否需要进行限制
- 得到词典之后,如何把句子转化为数字序列,如何把数字序列转化为句子
- 不同句子长度不相同,每个batch的句子如何构造成相同的长度(可以对短句子进行填充,填充特殊字符)
- 对于新出现的词语在词典中没有出现怎么办(可以使用特殊字符代理)
思路分析:
- 对所有句子进行分词
- 词语存入字典,根据次数对词语进行过滤,并统计次数
- 实现文本转数字序列的方法
- 实现数字序列转文本方法
文本序列化功能类WordSequence的构建
import numpy as np import pickle # =======================================文本序列化:开始======================================= class WordSequence: UNK_TAG = "<UNK>" # 表示未在词典库里出现的未知词汇 PAD_TAG = "<PAD>" # 句子长度不够时的填充符 SOS_TAG = "<SOS>" # 表示一句文本的开始 EOS_TAG = "<EOS>" # 表示一句文本的结束 UNK = 0 PAD = 1 SOS = 2 EOS = 3 def __init__(self): self.word_index_dict = { self.UNK_TAG: self.UNK, self.PAD_TAG: self.PAD, self.SOS_TAG: self.SOS, self.EOS_TAG: self.EOS} # 初始化词语-数字映射字典 self.index_word_dict = {} # 初始化数字-词语映射字典 self.word_count_dict = {} # 初始化词语-词频统计字典 self.fited = False def __len__(self): return len(self.word_index_dict) # 接受句子,统计词频得到 def fit(self,sentence,min_count=1,max_count=None,max_features=None): # 【min_count:最小词频; max_count: 最大词频; max_features: 最大词语数(词典容量大小)】 """ :param sentence:[word1,word2,word3] :param min_count: 最小出现的次数 :param max_count: 最大出现的次数 :param max_feature: 总词语的最大数量 :return: """ for word in sentence: self.word_count_dict[word] = self.word_count_dict.get(word,0) + 1 #所有的句子fit之后,self.word_count_dict就有了所有词语的词频 if min_count is not None: # 根据条件统计词频 self.word_count_dict = {word:count for word,count in self.word_count_dict.items() if count >= min_count} if max_count is not None:# 根据条件统计词频 self.word_count_dict = {word:count for word,count in self.word_count_dict.items() if count <= max_count} # 根据条件构造词典 if max_features is not None: # 根据条件保留高词频词语 self.word_count_dict = dict(sorted(self.word_count_dict.items(),key=lambda x:x[-1],reverse=True)[:max_features]) # 保留词频排名靠前的词汇【self.word_count_dict.items()为待排序的对象,key表示排序指标,reverse=True表示降序排列】 for word in self.word_count_dict: # 根据word_count_dict字典构造词语-数字映射字典 if word not in self.word_index_dict.keys(): # 如果当前词语word还没有添加到word_index_dict字典,则添加 self.word_index_dict[word] = len(self.word_index_dict) # 每次word对应一个数字【使用self.word_index_dict添加当前word前已有词汇的数量作为其value】 self.fited = True self.index_word_dict = dict(zip(self.word_index_dict.values(),self.word_index_dict.keys())) #把word_index_dict进行翻转【准备一个index->word的字典】 # word -> index def to_index(self,word): assert self.fited == True,"必须先进行fit操作" return self.word_index_dict.get(word,self.UNK) # 把句子转化为数字数组(向量)【输入:[str,str,str];输出:[int,int,int]】 def transform(self,sentence,max_len=None,add_eos=False): if len(sentence) > max_len: # 句子过长,截取句子 if add_eos: # 如果每句文本需要添加<EOS>结束标记 sentence = sentence[:max_len-1] + [self.EOS] else: sentence = sentence[:max_len] else: # 句子过短,填充句子 if add_eos: # 如果每句文本需要添加<EOS>结束标记 sentence = sentence + [self.EOS] + [self.PAD_TAG] *(max_len - len(sentence) - 1) else: sentence = sentence + [self.PAD_TAG] *(max_len - len(sentence)) index_sequence = [self.to_index(word) for word in sentence] return index_sequence # index -> word def to_word(self,index): assert self.fited , "必须先进行fit操作" if index in self.inversed_dict: return self.inversed_dict[index] return self.UNK_TAG # 把数字数组(向量)转化为句子【输入:[int,int,int];输出:[str,str,str]】 def inverse_transform(self,indexes): sentence = [self.index_word_dict.get(index,"<UNK>") for index in indexes] return sentence # =======================================文本序列化:结束======================================= if __name__ == '__main__': sentences = [["今天","天气","很","好"],["今天","去","吃","什么"]] ws = WordSequence() for sentence in sentences: ws.fit(sentence) print("ws.word_index_dict = {0}".format(ws.word_index_dict)) print("ws.fited = {0}".format(ws.fited)) pickle.dump(ws, open("./models/ws.pkl", "wb")) # 保存文本序列化对象 ws = pickle.load(open("./models/ws.pkl", "rb")) # 加载文本序列化对象 index_sequence = ws.transform(["今天","很","热"],max_len=10) print("index_sequence = {0}".format(index_sequence))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
输出结果:
ws.word_index_dict = {'<UNK>': 1, '<PAD>': 0, '今天': 2, '天气': 3, '很': 4, '好': 5, '去': 6, '吃': 7, '什么': 8}
ws.fited = True
index_sequence = [2, 4, 1, 0, 0, 0, 0, 0, 0, 0]
- 1
- 2
- 3
二、“序列化后的字符串文本” 进行向量化
因为文本不能够直接被模型计算,所以需要将其转化为向量。
将一段文本使用张量进行表示,其中一般将词汇为表示成向量,称作词向量,再由各个词向量按顺序组成矩阵形成文本表示.
举个栗子:
["人生", "该", "如何", "起头"]
==>
# 每个词对应矩阵中的一个向量
[[1.32, 4,32, 0,32, 5.2],
[3.1, 5.43, 0.34, 3.2],
[3.21, 5.32, 2, 4.32],
[2.54, 7.32, 5.12, 9.54]]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
文本张量表示的作用:将文本表示成张量(矩阵)形式,能够使语言文本可以作为计算机处理程序的输入,进行接下来一系列的解析工作。
文本张量表示的方法:
- one-hot编码
- Word Embedding
1、one-hot编码
在one-hot编码中,每一个token使用一个长度为N的向量表示,N表示词典的数量。
one-hot编码又称独热编码,将每个词表示成具有n个元素的向量,这个词向量中只有一个元素是1,其他元素都是0,不同词汇元素为0的位置不同,其中n的大小是整个语料中不同词汇的总数.
即:把待处理的文档进行分词或者是N-gram处理,然后进行去重得到词典,假设我们有一个文档:深度学习,那么进行one-hot处理后的结果如下:
| token | one-hot encoding |
|---|---|
| 深 | 1000 |
| 度 | 0100 |
| 学 | 0010 |
| 习 | 0001 |
手工进行one-hot编码:
from sklearn.externals import joblib # 导入用于对象保存与加载的joblib
from keras.preprocessing.text import Tokenizer # 导入keras中的词汇映射器Tokenizer
vocab = {"周杰伦", "陈奕迅", "王力宏", "李宗盛", "周华健", "鹿晗"} # 假定vocab为语料集所有不同词汇集合
t = Tokenizer(num_words=None, char_level=False) # 实例化一个词汇映射器对象
t.fit_on_texts(vocab) # 使用映射器拟合现有文本数据
for token in vocab:
zero_list = [0]*len(vocab)
token_index = t.texts_to_sequences([token])[0][0] - 1 # 使用映射器转化现有文本数据, 每个词汇对应从1开始的自然数;返回样式如: [[2]], 取出其中的数字需要使用[0][0]
zero_list[token_index] = 1
print(token, "的one-hot编码为:", zero_list)
tokenizer_path = "./Tokenizer" # 使用joblib工具保存映射器, 以便之后使用
joblib.dump(t, tokenizer_path)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
打印结果:
鹿晗 的one-hot编码为: [1, 0, 0, 0, 0, 0]
王力宏 的one-hot编码为: [0, 1, 0, 0, 0, 0]
李宗盛 的one-hot编码为: [0, 0, 1, 0, 0, 0]
陈奕迅 的one-hot编码为: [0, 0, 0, 1, 0, 0]
周杰伦 的one-hot编码为: [0, 0, 0, 0, 1, 0]
周华健 的one-hot编码为: [0, 0, 0, 0, 0, 1]
- 1
- 2
- 3
- 4
- 5
- 6
one-hot编码的优劣势:
- 优势:操作简单,容易理解.
- 劣势:完全割裂了词与词之间的联系,而且在大语料集下,每个向量的长度过大,占据大量内存.
正因为one-hot编码明显的劣势,这种编码方式被应用的地方越来越少,取而代之的是稠密向量的表示方法word embedding
2、Word Embedding
word embedding是深度学习中表示文本常用的一种方法。和one-hot编码不同,word embedding使用了浮点型的稠密矩阵来表示token。根据词典的大小,我们的向量通常使用不同的维度,例如100,256,300等。其中向量中的每一个值是一个参数,其初始值是随机生成的,之后会在训练的过程中进行学习而获得。
如果我们文本中有20000个词语,如果使用one-hot编码,那么我们会有20000*20000的矩阵,其中大多数的位置都为0,但是如果我们使用word embedding来表示的话,只需要20000* 维度,比如20000*300
形象的表示就是:
| token | num | vector |
|---|---|---|
| 词1 | 0 | [ w 11 , w 12 , w 13 . . . w 1 N ] [w_{11},w_{12},w_{13}...w_{1N}] [w11,w12,w13...w1N] ,其中 N N N 表示维度(dimension) |
| 词2 | 1 | [ w 21 , w 22 , w 23 . . . w 2 N ] [w_{21},w_{22},w_{23}...w_{2N}] [w21,w22,w23...w2N] |
| 词3 | 2 | [ w 31 , w 23 , w 33 . . . w 3 N ] [w_{31},w_{23},w_{33}...w_{3N}] [w31,w23,w33...w3N] |
| … | …. | … |
| 词m | m | [ w m 1 , w m 2 , w m 3 . . . w m N ] [w_{m1},w_{m2},w_{m3}...w_{mN}] [wm1,wm2,wm3...wmN],其中 m m m 表示词典的大小 |
我们会把所有的文本转化为向量,把句子用向量来表示
但是在这中间,我们会先把token使用数字来表示,再把数字使用向量来表示。
即:token---> num ---->vector
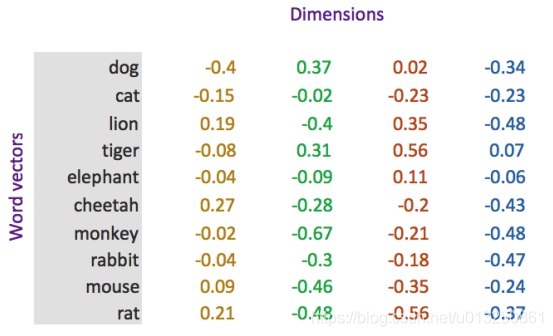
-
文本张量表示方法 ---->参考:人工智能-深度学习-生成模型-预训练方法:Word Embedding【Word2vec -->CBOW、Skip-Gram】、【GloVe】
-
使用fasttext工具实现word2vec的训练和使用:人工智能-自然语言处理(NLP)-第三方库(工具包):fastText【作用:基于深度学习的文本分类、word2vec训练词向量】

