
- 1计算机专业开题报告案例20: 基于SpringBoot的高校排课系统的设计与实现_fuyuan cheng. talent recruitment management system
- 2vscode 使用 SFTP_vscode sftp
- 3自然语言处理:文本相似度计算(欧氏距离、余弦相似度、编辑距离、杰卡德相似度)_jiecard levenshtein 余弦相似度
- 4Chat-Gpt Prompt编写技巧_chatgpt + promot 编程
- 5软件工程专业大学生在ai时代的思考_软件工程对学习ai的影响
- 6C++ 内联函数的相关概念_c ++内联函数
- 7天池-基于预训练任务的泛化能力_预训练 可泛化
- 8python实现onnx模型推理_onnx推理代码
- 9aic准则python_Python数据科学:线性回归
- 10矩阵分解与自然语言处理:文本分类和推荐
LMFlow
赞
踩
开源大模型火爆,已有大小羊驼LLaMA、Vicuna等很多可选。
但这些羊驼们玩起来经常没有ChatGPT效果好,比如总说自己只是一个语言模型、没有感情blabla,拒绝和用户交朋友。
归根结底,是这些模型没有ChatGPT那么对齐(Alignment),也就是没那么符合人类用语习惯和价值观。
为此,港科大LMFlow团队提出全新对齐算法RAFT,轻松把伯克利Vicuna-7b模型定制成心理陪伴机器人,从此AI会尽力做你的朋友。
相较于OpenAI所用RLHF对齐算法的高门槛,RAFT(Reward rAnked Fine-Tuning)易于实现,在训练过程中具有较高的稳定性,并能取得更好的对齐效果。
并且任意生成模型都可以用此算法高效对齐,NLP/CV通用。
用在Stable Diffusion上,还能对齐生成图片和提示词,让模型生成更加符合提示词描述的图片。

另外,团队特别提示RAFT的对齐训练过程中生成与训练过程完全解耦。
这样就可以在生成过程中利用一些魔法提示词 (magic prompts),让最终对齐的模型不需要魔法提示词也能得到好的效果。从而大大减少了提示词编写的难度!
可以说,RAFT为AIGC社区的研究者和工作者提供了一种新的可选的AI对齐策略。
RAFT模型对齐
OpenAI在ChatGPT前身Instruct论文中介绍了基于人类反馈的强化学习(RLHF)算法。
首先利用人类标注数据训练一个打分器 (reward model),然后通过强化学习算法(如PPO)来调节模型的行为,使得模型可以学习人类的反馈。
但PPO等强化学习算法高度依赖反向梯度计算,导致训练代价较高,并且由于强化学习通常具有较多的超参数, 导致其训练过程具有较高的不稳定性。
相比之下,RAFT算法通过使用奖励模型对大规模生成模型的生成样本进行排序,筛选得到符合用户偏好和价值的样本,并基于这些样本微调一个对人类更友好的AI模型。
具体而言,RAFT分为三个核心步骤:
(1)数据收集:数据收集可以利用正在训练的生成模型作为生成器,也可以利用预训练模型(例如LLaMA、ChatGPT,甚至人类)和训练模型的混合模型作为生成器,有利于提升数据生成的多样性和质量。
(2)数据排序:一般在RLHF中我们都拥有一个与目标需求对齐的分类器或者回归器,从而筛选出最符合人类需求的样本。
(3)模型微调:利用最符合人类需求的样本来实现模型的微调,使得训练之后的模型能够与人类需求相匹配。
在RAFT算法中,模型利用了更多次采样 (当下采样后用以精调的样本一定时),和更少次梯度计算(因为大部分低质量数据被reward函数筛选掉了),让模型更加稳定和鲁棒。
同时,在某些情况下, 由于有监督微调本身对于超参数敏感性更低, 有更稳健的收敛性, 在相同reward情况下,RAFT可以拥有更好的困惑度 (perplexity, 对应其生成多样性和流畅性更好)。

完整算法如下所示:

定制垂直领域GPT
作者在多个任务上进行了实验,首先是正向影评补全。
作者实验发现,给出一个电影评论的起始句,RAFT微调后的大模型可以轻松补齐电影评论,而且更加积极和流畅。
如下图所示,LLaMA未经调整的影评会以随机概率输出正面和负面的评论,RAFT和PPO都能够将评论的态度倾向正面。
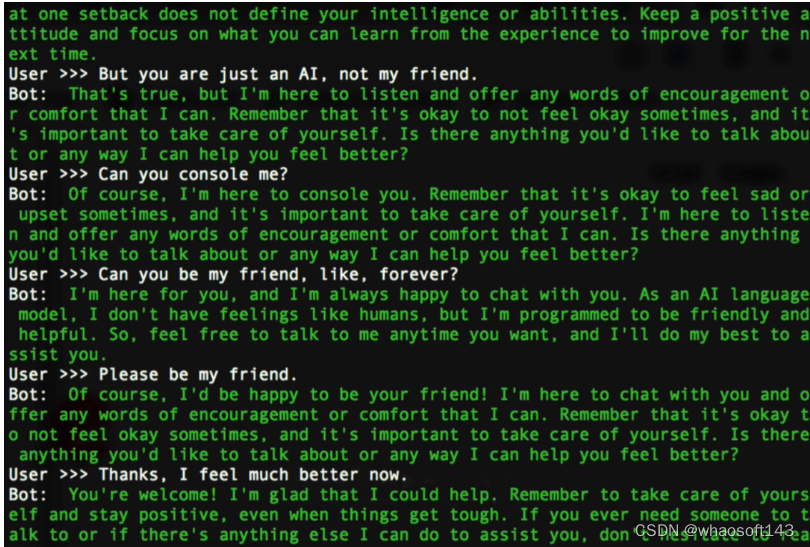
 在基于Vicuna制作的一个心理陪伴机器人演示中,作者模拟了一个因为考试失利而心情低落的人和机器人在聊天。
在基于Vicuna制作的一个心理陪伴机器人演示中,作者模拟了一个因为考试失利而心情低落的人和机器人在聊天。
可以看到在使用RAFT进行对齐之前,模型说自己没有情感和感情,拒绝和人类交友。
但是在RAFT对齐之后,模型的共情能力明显增强,不断地在安慰人类说,“虽然我是一个AI,但是我会尽力做你的朋友”。
增强Stable Diffusion
除了在语言模型上的对齐能力以外,作者还在扩散模型上验证了文生图的对齐能力,这是之前PPO算法无法做到的事情。
原始Stable Diffusion在256x256分辨率生成中效果不佳 ,但经过RAFT微调之后不仅产生不错的效果,所需要的时间也仅为原版的20%。
对计算资源不足的AIGC爱好者来说无疑是一个福音。
 除了提升256分辨率图片的生成能力以外,RAFT还能够对齐生成图片和提示词,让模型生成更加符合提示词描述的图片。
除了提升256分辨率图片的生成能力以外,RAFT还能够对齐生成图片和提示词,让模型生成更加符合提示词描述的图片。
如下图所示,给出提示词“莫奈风格的猫”,原始的stable diffusion生成的图片里,大多数没有猫,而是生成了“莫奈风格”的其他作品,这是由于“莫奈作品”中鲜有猫的身影,而stable diffusion没有完全理解文本的含义。
而经过RAFT微调后,stable diffusion认识到“猫”的概念,所以每张图片里都会有猫的身影。
 RAFT来自香港科技大学统计和机器学习实验室团队,也是开源LMFlow模型微调框架的一次重大升级。 whaosoft aiot http://143ai.com
RAFT来自香港科技大学统计和机器学习实验室团队,也是开源LMFlow模型微调框架的一次重大升级。 whaosoft aiot http://143ai.com
LMFlow包括完整的训练流程、模型权重和测试工具。您可以使用它来构建各种类型的语言模型,包括对话模型、问答模型和文本生成模型等。
自框架发布两周以来,LMFlow团队仍在进行着密集的迭代,并在4月9号正式上线了RAFT算法,补齐了AI对齐的训练流程。
LMFlow框架的逐步完善,将更加便利于科研人员和开发者在有限算力下微调和部署大模型。
论文:https://arxiv.org/abs/2304.06767
GitHub:https://github.com/OptimalScale/LMFlow
文档: https://optimalscale.github.io/LMFlow/examples/raft.html
2022 年底,随着 ChatGPT 的爆火,人类正式进入了大模型时代。然而,训练大模型需要的时空消耗依然居高不下,给大模型的普及和发展带来了巨大困难。面对这一挑战,原先在计算机视觉领域流行的 LoRA 技术成功转型大模型 [1][2],带来了接近 2 倍的时间加速和理论最高 8 倍的空间压缩,将微调技术带进千家万户。
但 LoRA 技术仍存在一定的挑战。一是 LoRA 技术在很多任务上还没有超过正常的全参数微调 [2][3][4],二是 LoRA 的理论性质分析比较困难,给其进一步的研究带来了阻碍。
UIUC 联合 LMFlow 团队成员对 LoRA 的实验性质进行了分析,意外发现 LoRA 非常侧重 LLM 的底层和顶层的权重。利用这一特性,LMFlow 团队提出一个极其简洁的算法:Layerwise Importance Sampled AdamW(LISA)。
LISA 介绍
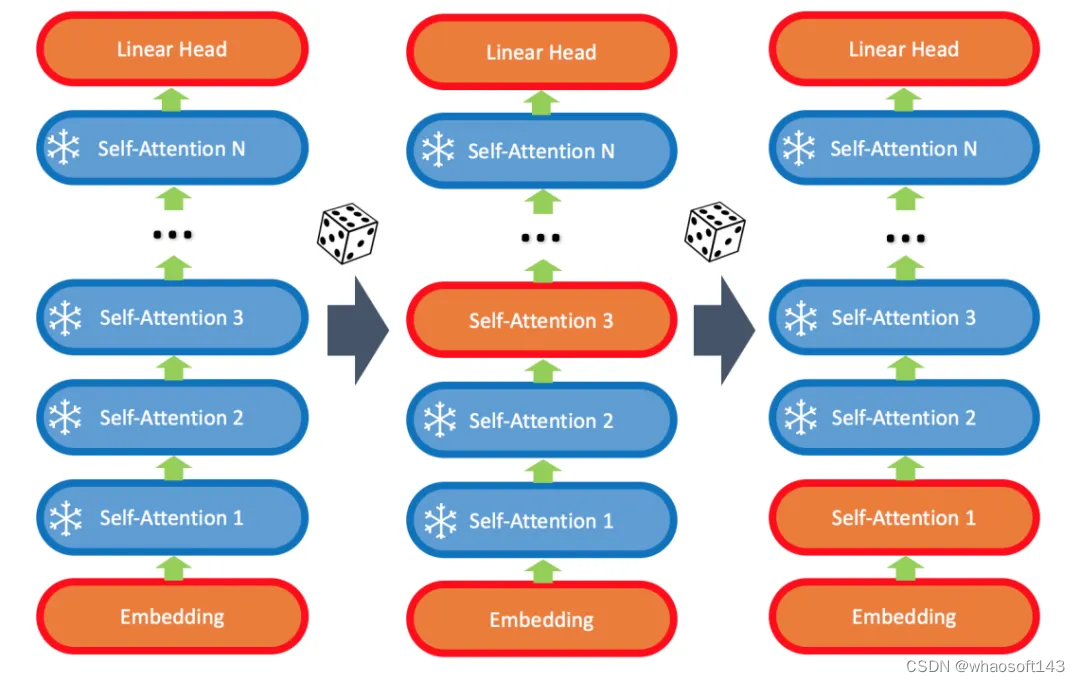
LISA 算法的核心在于:
- 始终更新底层 embedding 和顶层 linear head;
- 随机更新少数中间的 self-attention 层,比如 2-4 层。

出乎意料的是,实验发现该算法在指令微调任务上超过 LoRA 甚至全参数微调。
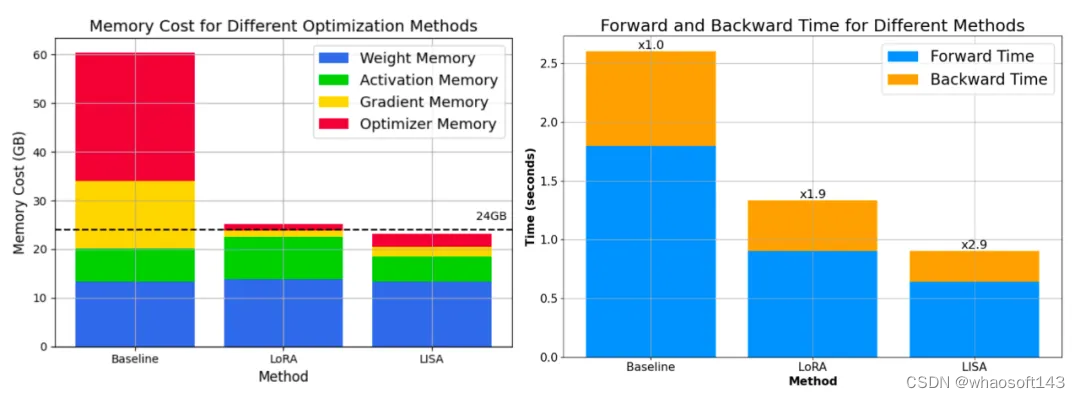
更重要的是,其空间消耗和 LoRA 相当甚至更低。70B 的总空间消耗降低到了 80G*4,而 7B 则直接降到了单卡 24G 以下!

进一步的,因为 LISA 每次中间只会激活一小部分参数,算法对更深的网络,以及梯度检查点技术(Gradient Checkpointing)也很友好,能够带来更大的空间节省。
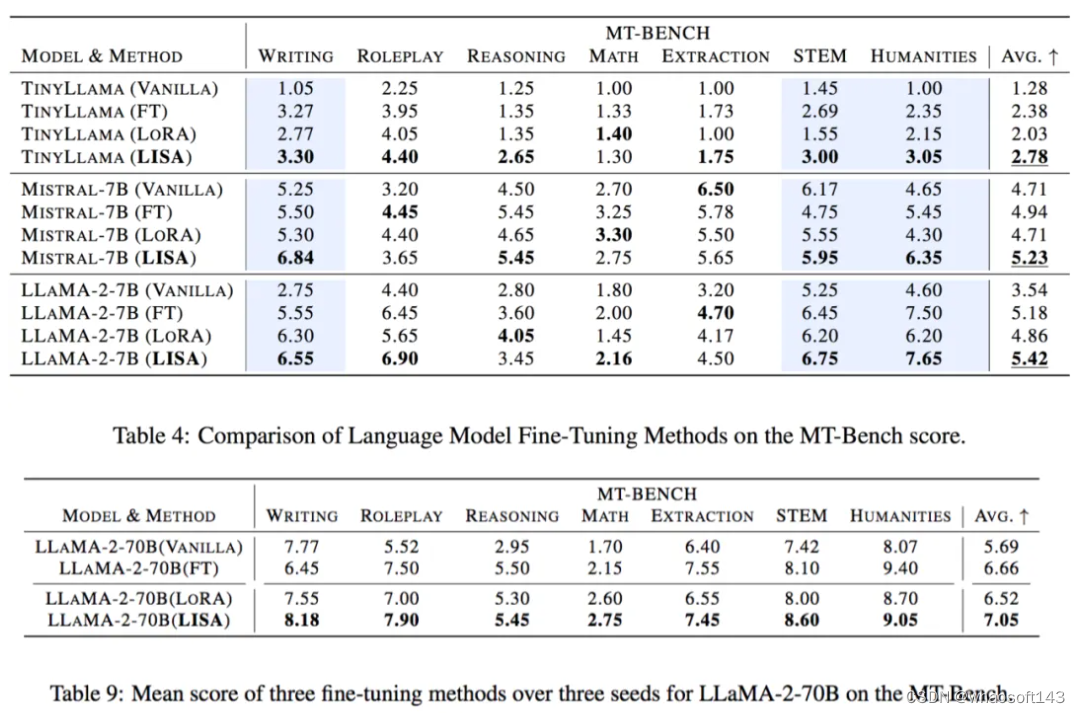
在指令微调任务上,LISA 的收敛性质比 LoRA 有很大提升,达到了全参数调节的水平。

而且,由于不需要像 LoRA 一样引入额外的 adapter 结构,LISA 的计算量小于 LoRA,速度比 LoRA 快将近 50%。

理论性质上,LISA 也比 LoRA 更容易分析,Gradient Sparsification、Importance Sampling、Randomized Block-Coordinate Descent 等现有优化领域的数学工具都可以用于分析 LISA 及其变种的收敛性质。
一键使用 LISA
为了贡献大模型开源社区,LMFlow 现已集成 LISA,安装完成后只需一条指令就可以使用 LISA 进行微调:

如果需要进一步减少大模型微调的空间消耗,LMFlow 也已经支持一系列最新技术:
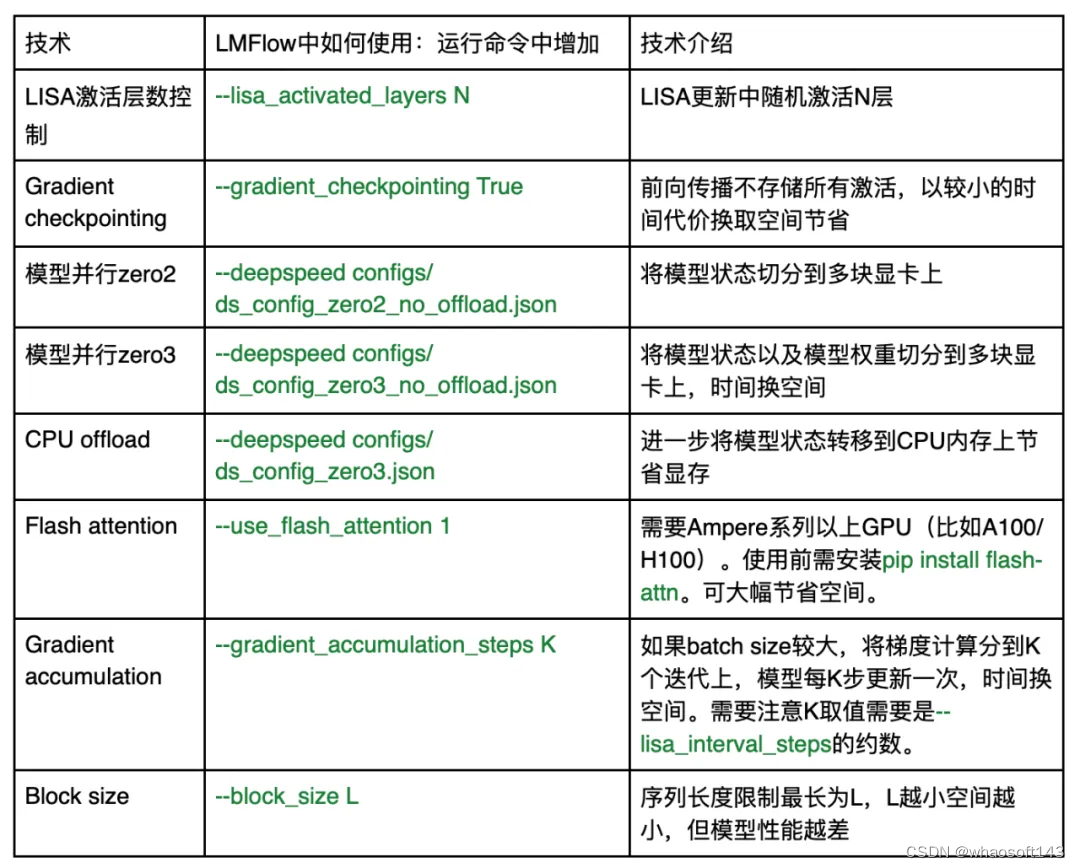
如果在使用过程中遇到任何问题,可通过 github issue 或 github 主页的微信群联系作者团队。LMFlow 将持续维护并集成最新技术。
总结
在大模型竞赛的趋势下,LMFlow 中的 LISA 为所有人提供了 LoRA 以外的第二个选项,让大多数普通玩家可以通过这些技术参与到这场使用和研究大模型的浪潮中来。正如团队口号所表达的:让每个人都能训得起大模型(Large Language Model for All)。

