
- 1C语言积累整理---memset函数详解_memset在c语言中怎么用
- 2并发编程及JUC_juc并发编程与并发编程
- 3汉语言处理工具pyhanlp的拼音转换与字符正则化_正则中文替换拼音
- 4开机Luncher被替换成APP,使用adb命令回到桌面_adb 进入桌面
- 5山西移动创维E900V22C_S905L3(B)_UWE5621DS_安卓9_免拆卡刷固件包_e900v22c固件s905l3b
- 6主题模型LDA教程:一致性得分coherence score方法对比(umass、c_v、uci)_主题一致性 计算公式是什么
- 7光谱颜色转换RGB C#_光谱转换rgb在线
- 8Android 打包aar包含第三方aar 解决方案_android aar中打包第三方aar
- 9文档扫描识别——OpenCV与C++实现OCR文字识别_paddleocr c++和opencv
- 10RabbitMQ Failed to convert message.No method found for class java.lang.String问题解决
《人工智能》机器学习 - 第3章 朴素贝叶斯算法【分类】 (二 算法实战)_ai算法朴素贝叶斯分类算法实例
赞
踩
3.6朴素贝叶斯实践
3.6.1朴素贝叶斯之微博评论筛选
以微博评论为例。为了不影响微博的发展,我们要屏蔽低俗的言论,所以要构建一个快速过滤器,如果某条评论使用了负面或者侮辱性等低俗的语言,那么就将该留言标志为内容不当。过滤这类内容是一个很常见的需求。对此问题建立两个类型:低俗类和非低俗类,使用1和0分别表示。
3.6.1.1朴素贝叶斯之微博评论筛选实现
我们把文本看成单词向量或者词条向量,也就是说将句子转换为向量。考虑出现所有文档中的单词,再决定将哪些单词纳入词汇表或者说所要的词汇集合,然后必须要将每一篇文档转换为词汇表上的向量。简单起见,我们先假设已经将本文切分完毕,存放到列表中,并对词汇向量进行分类标注。编写代码如下:
# -*- coding: utf-8 -*- """ 函数说明:创建实验样本 Parameters: 无 Returns: postingList - 实验样本切分的词条 classVec - 类别标签向量 """ def loadDataSet(): postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], #切分的词条 ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'], ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'], ['stop', 'posting', 'stupid', 'worthless', 'garbage'], ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'], ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']] #类别标签向量,1代表低俗性词汇,0代表不是 classVec = [0,1,0,1,0,1] #返回实验样本切分的词条和类别标签向量 return postingList,classVec if __name__ == '__main__': postingLIst, classVec = loadDataSet() for each in postingLIst: print(each) print(classVec)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
从运行结果可以看出,我们已经将postingList是存放词条列表中,classVec是存放每个词条的所属类别,1代表低俗类 ,0代表非低俗类。
继续编写代码,前面我们已经说过我们要先创建一个词汇表,并将切分好的词条转换为词条向量。

# -*- coding: utf-8 -*- """ 函数说明:创建实验样本 Parameters: 无 Returns: postingList - 实验样本切分的词条 classVec - 类别标签向量 """ def loadDataSet(): postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], #切分的词条 ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'], ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'], ['stop', 'posting', 'stupid', 'worthless', 'garbage'], ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'], ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']] #类别标签向量,1代表低俗性词汇,0代表不是 classVec = [0,1,0,1,0,1] #返回实验样本切分的词条和类别标签向量 return postingList,classVec """ 函数说明:将切分的实验样本词条整理成不重复的词条列表,也就是词汇表 Parameters: dataSet - 整理的样本数据集 Returns: vocabSet - 返回不重复的词条列表,也就是词汇表 """ def createVocabList(dataSet): #创建一个空的不重复列表 vocabSet = set([]) for document in dataSet: vocabSet = vocabSet | set(document) #取并集 return list(vocabSet) """ 函数说明:根据vocabList词汇表,将inputSet向量化,向量的每个元素为1或0 Parameters: vocabList - createVocabList返回的列表 inputSet - 切分的词条列表 Returns: returnVec - 文档向量,词集模型 """ def setOfWords2Vec(vocabList, inputSet): #创建一个其中所含元素都为0的向量 returnVec = [0] * len(vocabList) #遍历每个词条 for word in inputSet: #如果词条存在于词汇表中,则置1 if word in vocabList: returnVec[vocabList.index(word)] = 1 else: print("the word: %s is not in my Vocabulary!" % word) return returnVec #返回文档向量 if __name__ == '__main__': postingList, classVec = loadDataSet() print('postingList:\n',postingList) myVocabList = createVocabList(postingList) print('myVocabList:\n',myVocabList) trainMat = [] for postinDoc in postingList: trainMat.append(setOfWords2Vec(myVocabList, postinDoc)) print('trainMat:\n', trainMat)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
从运行结果可以看出,postingList是原始的词条列表,myVocabList是词汇表。myVocabList是所有单词出现的集合,没有重复的元素。词汇表是用来干什么的?没错,它是用来将词条向量化的,一个单词在词汇表中出现过一次,那么就在相应位置记作1,如果没有出现就在相应位置记作0。trainMat是所有的词条向量组成的列表。它里面存放的是根据myVocabList向量化的词条向量。

我们已经得到了词条向量。接下来,我们就可以通过词条向量训练朴素贝叶斯分类器。
# -*- coding: utf-8 -*- import numpy as np """ 函数说明:创建实验样本 Parameters: 无 Returns: postingList - 实验样本切分的词条 classVec - 类别标签向量 """ def loadDataSet(): postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], #切分的词条 ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'], ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'], ['stop', 'posting', 'stupid', 'worthless', 'garbage'], ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'], ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']] #类别标签向量,1代表低俗性词汇,0代表不是 classVec = [0,1,0,1,0,1] #返回实验样本切分的词条和类别标签向量 return postingList,classVec """ 函数说明:将切分的实验样本词条整理成不重复的词条列表,也就是词汇表 Parameters: dataSet - 整理的样本数据集 Returns: vocabSet - 返回不重复的词条列表,也就是词汇表 """ def createVocabList(dataSet): #创建一个空的不重复列表 vocabSet = set([]) for document in dataSet: vocabSet = vocabSet | set(document) #取并集 return list(vocabSet) """ 函数说明:根据vocabList词汇表,将inputSet向量化,向量的每个元素为1或0 Parameters: vocabList - createVocabList返回的列表 inputSet - 切分的词条列表 Returns: returnVec - 文档向量,词集模型 """ def setOfWords2Vec(vocabList, inputSet): #创建一个其中所含元素都为0的向量 returnVec = [0] * len(vocabList) #遍历每个词条 for word in inputSet: #如果词条存在于词汇表中,则置1 if word in vocabList: returnVec[vocabList.index(word)] = 1 else: print("the word: %s is not in my Vocabulary!" % word) return returnVec #返回文档向量 """ 函数说明:朴素贝叶斯分类器训练函数 Parameters: trainMatrix - 训练文档矩阵,即setOfWords2Vec返回的returnVec构成的矩阵 trainCategory - 训练类别标签向量,即loadDataSet返回的classVec Returns: p0Vect - 非低俗的条件概率数组 p1Vect - 低俗类的条件概率数组 pAbusive - 文档属于低俗类的概率 """ def trainNB0(trainMatrix,trainCategory): #计算训练的文档数目 numTrainDocs = len(trainMatrix) #计算每篇文档的词条数 numWords = len(trainMatrix[0]) #文档属于低俗类的概率 pAbusive = sum(trainCategory)/float(numTrainDocs) #创建numpy.zeros数组, p0Num = np.zeros(numWords); p1Num = np.zeros(numWords) #分母初始化为0.0 p0Denom = 0.0; p1Denom = 0.0 for i in range(numTrainDocs): #统计属于低俗类的条件概率所需的数据,即P(w0|1),P(w1|1),P(w2|1)··· if trainCategory[i] == 1: p1Num += trainMatrix[i] p1Denom += sum(trainMatrix[i]) else: #统计属于非低俗类的条件概率所需的数据,即P(w0|0),P(w1|0),P(w2|0)··· p0Num += trainMatrix[i] p0Denom += sum(trainMatrix[i]) p1Vect = p1Num/p1Denom #相除 p0Vect = p0Num/p0Denom return p0Vect,p1Vect,pAbusive #返回属于低俗类的条件概率数组,属于非低俗类的条件概率数组,文档属于低俗类的概率
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
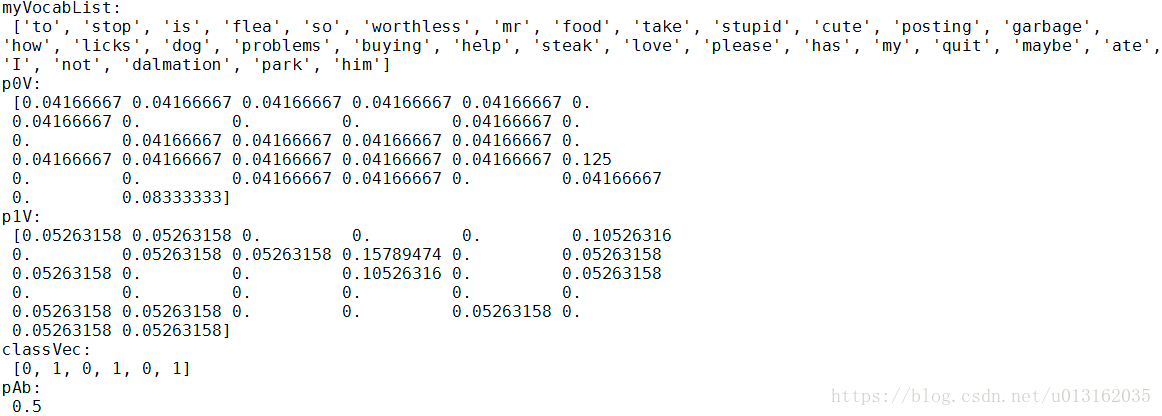
运行结果如下,p0V存放的是每个单词属于类别0,也就是非低俗类词汇的概率。比如p0V的倒数第6个概率,就是stupid这个单词属于非低俗类的概率为0。同理,p1V的倒数第6个概率,就是stupid这个单词属于低俗类的概率为0.15789474,也就是约等于15.79%的概率。我们知道stupid的中文意思是蠢货,难听点的叫法就是傻逼。显而易见,这个单词属于低俗类。pAb是所有低俗类的样本占所有样本的概率,从classVec中可以看出,一用有3个低俗类,3个非低俗类。所以低俗类的概率是0.5。因此p0V存放的就是P(him|非低俗类) = 0.0833、P(is|非低俗类) = 0.0417,一直到P(dog|非低俗类) = 0.0417,这些单词的条件概率。同理,p1V存放的就是各个单词属于低俗类的条件概率。pAb就是先验概率。
已经训练好分类器,接下来,使用分类器进行分类。
# -*- coding: utf-8 -*- import numpy as np from functools import reduce """ 函数说明:创建实验样本 Parameters: 无 Returns: postingList - 实验样本切分的词条 classVec - 类别标签向量 """ def loadDataSet():#实验样本集,返回文档集合和类别标签,人工手动标注 postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], #切分的词条 ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'], ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'], ['stop', 'posting', 'stupid', 'worthless', 'garbage'], ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'], ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']] #类别标签向量,1代表低俗性词汇,0代表不是 classVec = [0,1,0,1,0,1] #返回实验样本切分的词条和类别标签向量 return postingList,classVec """ 函数说明:将切分的实验样本词条整理成不重复的词条列表,也就是词汇表 Parameters: dataSet - 整理的样本数据集 Returns: vocabSet - 返回不重复的词条列表,也就是词汇表 """ #创建一个包含在所有文档中出现的不重复的列表 |用于求两个集合并集,词集 def createVocabList(dataSet): #创建一个空的不重复列表 vocabSet = set([]) #遍历数据集 for document in dataSet: vocabSet = vocabSet | set(document) #取并集 #print(vocabSet) return list(vocabSet)#生成一个包含所有单词的列表 """ 函数说明:根据vocabList词汇表,将inputSet向量化,向量的每个元素为1或0 Parameters: vocabList - createVocabList返回的列表 inputSet - 切分的词条列表 Returns: returnVec - 文档向量,词集模型 """ def setOfWords2Vec(vocabList, inputSet): #创建一个其中所含元素都为0的向量 returnVec = [0] * len(vocabList) #遍历每个词条 for word in inputSet: #如果词条存在于词汇表中,则置1 if word in vocabList: returnVec[vocabList.index(word)] = 1 else: print("the word: %s is not in my Vocabulary!" % word) #print(returnVec) return returnVec #返回文档向量 """ 函数说明:朴素贝叶斯分类器训练函数 Parameters: trainMatrix - 训练文档矩阵,即setOfWords2Vec返回的returnVec构成的矩阵 trainCategory - 训练类别标签向量,即loadDataSet返回的classVec Returns: p0Vect - 非低俗的条件概率数组 p1Vect - 低俗类的条件概率数组 pAbusive - 文档属于低俗类的概率 """ def trainNB(trainMatrix,trainCategory): #计算训练的文档条数 numTrainDocs = len(trainMatrix) #print("numTrainDocs:" + str(numTrainDocs)) #计算每篇文档的词条数 numWords = len(trainMatrix[0]) #print("numWords:" + str(numWords)) #文档属于低俗类的概率 pAbusive = sum(trainCategory)/float(numTrainDocs) #创建numpy.zeros数组, p0Num = np.zeros(numWords); p1Num = np.zeros(numWords) #分母初始化为0.0 p0Denom = 0.0; p1Denom = 0.0 for i in range(numTrainDocs): #统计属于低俗类的条件概率所需的数据,即P(w0|1),P(w1|1),P(w2|1)··· if trainCategory[i] == 1: p1Num += trainMatrix[i] p1Denom += sum(trainMatrix[i]) else: #统计属于非低俗类的条件概率所需的数据,即P(w0|0),P(w1|0),P(w2|0)··· p0Num += trainMatrix[i] p0Denom += sum(trainMatrix[i]) p1Vect = p1Num/p1Denom #相除 p0Vect = p0Num/p0Denom #print(p1Num) #print(p0Num) #print(p1Denom) #print(p0Denom) return p0Vect,p1Vect,pAbusive #返回属于低俗类的条件概率数组,属于非低俗类的条件概率数组,文档属于低俗类的概率 """ 函数说明:朴素贝叶斯分类器分类函数 Parameters: vec2Classify - 待分类的词条数组 p0Vec - 非低俗类的条件概率数组 p1Vec -低俗类的条件概率数组 pClass1 - 文档属于低俗类的概率 Returns: 0 - 属于非低俗类 1 - 属于低俗类 """ def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1): #从左到右对一个序列的项累计地应用有两个参数的函数,以此合并序列到一个单一值。 #例如,reduce(lambda x, y: x+y, [1, 2, 3, 4, 5]) 计算的就是((((1+2)+3)+4)+5)。 p1 = reduce(lambda x,y:x*y, vec2Classify * p1Vec) * pClass1 #对应元素相乘 p0 = reduce(lambda x,y:x*y, vec2Classify * p0Vec) * (1.0 - pClass1) print('p0:',p0) print('p1:',p1) if p1 > p0: return 1 else: return 0 """ 函数说明:测试朴素贝叶斯分类器 Parameters: 无 Returns: 无 """ def testingNB(): ## Step 1: load data print("Step 1: load data...") #创建数据 #创建实验样本 listPosts,listClasses = loadDataSet() #创建词汇表 myVocabList = createVocabList(listPosts) #向量化样本 trainMat=[] for postinDoc in listPosts: #将实验样本向量化 trainMat.append(setOfWords2Vec(myVocabList, postinDoc)) #print(trainMat) ## Step 2: training... print("Step 2: training...") #训练朴素贝叶斯分类器 p0V,p1V,pAb = trainNB(np.array(trainMat),np.array(listClasses)) ## Step 3: testing print("Step 3: testing...") #测试样本1 testEntry = ['love', 'my', 'dalmation'] #测试样本向量化 thisDoc = np.array(setOfWords2Vec(myVocabList, testEntry)) ## Step 4: show the result print("Step 4: show the result...") if classifyNB(thisDoc,p0V,p1V,pAb): print(testEntry,'属于低俗类') #执行分类并打印分类结果 else: print(testEntry,'属于非低俗类') #执行分类并打印分类结果 #测试样本2 testEntry = ['stupid', 'garbage'] #测试样本向量化 thisDoc = np.array(setOfWords2Vec(myVocabList, testEntry)) if classifyNB(thisDoc,p0V,p1V,pAb): print(testEntry,'属于低俗类') #执行分类并打印分类结果 else: print(testEntry,'属于非低俗类') #执行分类并打印分类结果 if __name__ == '__main__': testingNB()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
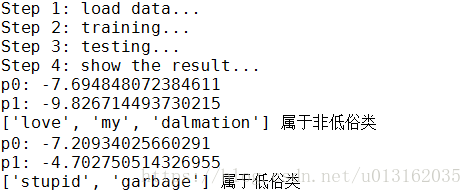
我们测试了两个词条,在使用分类器前,也需要对词条向量化,然后使用classifyNB()函数,用朴素贝叶斯公式,计算词条向量属于低俗类和非低俗类的概率。运行结果如下:
你会发现,这样写的算法无法进行分类,p0和p1的计算结果都是0,这里显然存在问题。那么怎么解决呢?

在计算的时候已经出现了概率为0的情况。如果新实例文本,包含这种概率为0的分词,那么最终的文本属于某个类别的概率也就是0了。显然,这样是不合理的,为了降低这种影响,可以将所有词的出现数初始化为1,并将分母初始化为2。这种做法就叫做拉普拉斯平滑(Laplace Smoothing)又被称为加1平滑,是比较常用的平滑方法,它就是为了解决0概率问题。
除此之外,另外一个遇到的问题就是下溢出,这是由于太多很小的数相乘造成的。学过数学的人都知道,两个小数相乘,越乘越小,这样就造成了下溢出。在程序中,在相应小数位置进行四舍五入,计算结果可能就变成0了。为了解决这个问题,对乘积结果取自然对数。通过求对数可以避免下溢出或者浮点数舍入导致的错误。同时,采用自然对数进行处理不会有任何损失。下图给出函数f(x)和ln(f(x))的曲线。

# -*- coding: utf-8 -*- import numpy as np """ 函数说明:创建实验样本 Parameters: 无 Returns: postingList - 实验样本切分的词条 classVec - 类别标签向量 """ def loadDataSet():#实验样本集,返回文档集合和类别标签,人工手动标注 postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], #切分的词条 ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'], ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'], ['stop', 'posting', 'stupid', 'worthless', 'garbage'], ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'], ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']] #类别标签向量,1代表低俗性词汇,0代表不是 classVec = [0,1,0,1,0,1] #返回实验样本切分的词条和类别标签向量 return postingList,classVec """ 函数说明:将切分的实验样本词条整理成不重复的词条列表,也就是词汇表 Parameters: dataSet - 整理的样本数据集 Returns: vocabSet - 返回不重复的词条列表,也就是词汇表 """ #创建一个包含在所有文档中出现的不重复的列表 |用于求两个集合并集,词集 def createVocabList(dataSet): #创建一个空的不重复列表 vocabSet = set([]) #遍历数据集 for document in dataSet: vocabSet = vocabSet | set(document) #取并集 #print(vocabSet) return list(vocabSet)#生成一个包含所有单词的列表 """ 函数说明:根据vocabList词汇表,将inputSet向量化,向量的每个元素为1或0 Parameters: vocabList - createVocabList返回的列表 inputSet - 切分的词条列表 Returns: returnVec - 文档向量,词集模型 """ def setOfWords2Vec(vocabList, inputSet): #创建一个其中所含元素都为0的向量 returnVec = [0] * len(vocabList) #遍历每个词条 for word in inputSet: #如果词条存在于词汇表中,则置1 if word in vocabList: returnVec[vocabList.index(word)] = 1 else: print("the word: %s is not in my Vocabulary!" % word) #print(returnVec) return returnVec #返回文档向量 """ 函数说明:朴素贝叶斯分类器训练函数 Parameters: trainMatrix - 训练文档矩阵,即setOfWords2Vec返回的returnVec构成的矩阵 trainCategory - 训练类别标签向量,即loadDataSet返回的classVec Returns: p0Vect - 非低俗的条件概率数组 p1Vect - 低俗类的条件概率数组 pAbusive - 文档属于低俗类的概率 """ def trainNB(trainMatrix,trainCategory): #计算训练的文档条数 numTrainDocs = len(trainMatrix) #print("numTrainDocs:" + str(numTrainDocs)) #计算每篇文档的词条数 numWords = len(trainMatrix[0]) #print("numWords:" + str(numWords)) #文档属于低俗类的概率 pAbusive = sum(trainCategory)/float(numTrainDocs) #创建numpy.ones数组, #创建numpy.ones数组,词条出现数初始化为1,拉普拉斯平滑 p0Num = np.ones(numWords); p1Num = np.ones(numWords) #分母初始化为2.0 p0Denom = 2.0; p1Denom = 2.0 for i in range(numTrainDocs): #统计属于低俗类的条件概率所需的数据,即P(w0|1),P(w1|1),P(w2|1)··· if trainCategory[i] == 1: p1Num += trainMatrix[i] p1Denom += sum(trainMatrix[i]) else: #统计属于非低俗类的条件概率所需的数据,即P(w0|0),P(w1|0),P(w2|0)··· p0Num += trainMatrix[i] p0Denom += sum(trainMatrix[i]) p1Vect = np.log(p1Num/p1Denom) #相除 p0Vect = np.log(p0Num/p0Denom) #print(p1Num) #print(p0Num) #print(p1Denom) #print(p0Denom) return p0Vect,p1Vect,pAbusive #返回属于低俗类的条件概率数组,属于非低俗类的条件概率数组,文档属于低俗类的概率 """ 函数说明:朴素贝叶斯分类器分类函数 Parameters: vec2Classify - 待分类的词条数组 p0Vec - 非低俗类的条件概率数组 p1Vec -低俗类的条件概率数组 pClass1 - 文档属于低俗类的概率 Returns: 0 - 属于非低俗类 1 - 属于低俗类 """ def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1): #从左到右对一个序列的项累计地应用有两个参数的函数,以此合并序列到一个单一值。 p1 = sum(vec2Classify * p1Vec) + np.log(pClass1) #对应元素相乘 p0 = sum(vec2Classify * p0Vec) + np.log(1.0 - pClass1) print('p0:',p0) print('p1:',p1) if p1 > p0: return 1 else: return 0 """ 函数说明:测试朴素贝叶斯分类器 Parameters: 无 Returns: 无 """ def testingNB(): ## Step 1: load data print("Step 1: load data...") #创建数据 #创建实验样本 listPosts,listClasses = loadDataSet() #创建词汇表 myVocabList = createVocabList(listPosts) #向量化样本 trainMat=[] for postinDoc in listPosts: #将实验样本向量化 trainMat.append(setOfWords2Vec(myVocabList, postinDoc)) #print(trainMat) ## Step 2: training... print("Step 2: training...") #训练朴素贝叶斯分类器 p0V,p1V,pAb = trainNB(np.array(trainMat),np.array(listClasses)) ## Step 3: testing print("Step 3: testing...") #测试样本1 testEntry = ['love', 'my', 'dalmation'] #测试样本向量化 thisDoc = np.array(setOfWords2Vec(myVocabList, testEntry)) ## Step 4: show the result print("Step 4: show the result...") if classifyNB(thisDoc,p0V,p1V,pAb): print(testEntry,'属于低俗类') #执行分类并打印分类结果 else: print(testEntry,'属于非低俗类') #执行分类并打印分类结果 #测试样本2 testEntry = ['stupid', 'garbage'] #测试样本向量化 thisDoc = np.array(setOfWords2Vec(myVocabList, testEntry)) if classifyNB(thisDoc,p0V,p1V,pAb): print(testEntry,'属于低俗类') #执行分类并打印分类结果 else: print(testEntry,'属于非低俗类') #执行分类并打印分类结果 if __ name__ == \' __main__ \': testingNB()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
结果如下。
【完整代码参考1.NB_word2vec的NB_word2vec_v1.1.py】
3.6.1.2朴素贝叶斯之微博评论筛选实现-调用sklearn库
调用sklearn库的数据输入和前面一节相同,主要是调用库的过程,直接看代码,代码很详细,笔者不想在细讲了。
# -*- coding: utf-8 -*- import numpy as np from sklearn.naive_bayes import GaussianNB from sklearn.model_selection import train_test_split """ 函数说明:创建实验样本 Parameters: 无 Returns: postingList - 实验样本切分的词条 classVec - 类别标签向量 """ def loadDataSet():#实验样本集,返回文档集合和类别标签,人工手动标注 postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], #切分的词条 ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'], ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'], ['stop', 'posting', 'stupid', 'worthless', 'garbage'], ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'], ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']] #类别标签向量,1代表低俗性词汇,0代表不是 classVec = [0,1,0,1,0,1] #返回实验样本切分的词条和类别标签向量 return postingList,classVec """ 函数说明:将切分的实验样本词条整理成不重复的词条列表,也就是词汇表 Parameters: dataSet - 整理的样本数据集 Returns: vocabSet - 返回不重复的词条列表,也就是词汇表 """ #创建一个包含在所有文档中出现的不重复的列表 |用于求两个集合并集,词集 def createVocabList(dataSet): #创建一个空的不重复列表 vocabSet = set([]) #遍历数据集 for document in dataSet: vocabSet = vocabSet | set(document) #取并集 #print(vocabSet) return list(vocabSet)#生成一个包含所有单词的列表 """ 函数说明:根据vocabList词汇表,将inputSet向量化,向量的每个元素为1或0 Parameters: vocabList - createVocabList返回的列表 inputSet - 切分的词条列表 Returns: returnVec - 文档向量,词集模型 """ def setOfWords2Vec(vocabList, inputSet): #创建一个其中所含元素都为0的向量 returnVec = [0] * len(vocabList) #遍历每个词条 for word in inputSet: #如果词条存在于词汇表中,则置1 if word in vocabList: returnVec[vocabList.index(word)] = 1 else: print("the word: %s is not in my Vocabulary!" % word) #print(returnVec) return returnVec #返回文档向量 """ 函数说明:测试朴素贝叶斯分类器 Parameters: 无 Returns: 无 """ def testingNB(): ## Step 1: load data print("Step 1: load data...") #创建数据#创建实验样本 listPosts,listClasses = loadDataSet() #创建词汇表 myVocabList = createVocabList(listPosts) #向量化样本 trainMat=[] for postinDoc in listPosts: #将实验样本向量化 trainMat.append(setOfWords2Vec(myVocabList, postinDoc)) #print(trainMat) ## Step 3: init NB print("Step 3: init NB...") #初始化贝叶斯分类器 gnb = GaussianNB() ## Step 4: training... print("Step 4: training...") #训练数据 gnb.fit(trainMat, listClasses) ## Step 5: testing print("Step 5: testing...") testEntry = ['love', 'my', 'dalmation'] #testEntry = ['stupid', 'garbage'] #测试样本向量化 thisDoc = np.array(setOfWords2Vec(myVocabList, testEntry)) #print(thisDoc) #预测数据 predictedLabel = gnb.predict([thisDoc]) #predictedLabel = gnb.fit(trainMat, listClasses).predict(thisDoc) ## Step 6: show the result print("Step 6: show the result...") print(predictedLabel) if (predictedLabel == 0): print("属于非低俗类") else: print("属于低俗类") if __name__ == '__main__': testingNB()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
运行结果如下。
【完整代码参考1.NB_word2vec的NB_word2vec_v2.py】

3.6.2朴素贝叶斯之鸢尾花卉分类
在上一章,笔者使用了KNN对鸢尾花卉进行了分类,那么在这一章还可以不?答案是可以的。我们还是用两种方法完成,一种是所有的算法都自己编写,另外一种是调用sklearn的API来实现。
3.6.2.1 朴素贝叶斯实战之鸢尾花卉分类实现
直接上代码吧.
# -*- coding: utf-8 -*- import numpy as np import csv#用于处理csv文件 import random#用于随机数 """ 函数说明:加载数据 Parameters: filename - 文件名 split - 分隔符 trainingSet - 训练集 testSet - 测试集 Returns: 无 """ def loadDataset(filename, split, trainSet = [], testSet = []): with open(filename, 'rt') as csvfile: #从csv中读取数据并返回行数 lines = csv.reader(csvfile) dataset = list(lines) for x in range(len(dataset)-1): for y in range(4): dataset[x][y] = float(dataset[x][y]) #保存数据集到训练集和测试集#random.random()返回随机浮点数 if random.random() < split: trainSet.append(dataset[x]) else: #将获得的测试数据放入测试集中 testSet.append(dataset[x]) """ 函数说明:分割数据 Parameters: dataSet - 数据集 Returns: data_X - 特征数据集 data_Y - 标签数据集 """ def segmentation_Data(dataSet): #得到文件行数 Lines = len(dataSet) #返回的NumPy矩阵,解析完成的数据:4列 data_X = np.zeros((Lines,4)) data_Y = [] for x in range(Lines): data_X[x,:] = dataSet[x][0:4] if dataSet[x][-1] == 'Iris-setosa': data_Y.append(1) elif dataSet[x][-1] == 'Iris-versicolor': data_Y.append(2) elif dataSet[x][-1] == 'Iris-virginica': data_Y.append(3) return data_X, data_Y """ 函数说明:将切分的实验样本词条整理成不重复的词条列表,也就是词汇表 Parameters: dataSet - 整理的样本数据集 Returns: vocabSet - 返回不重复的词条列表,也就是词汇表 """ #创建一个包含在所有文档中出现的不重复的列表 |用于求两个集合并集,词集 def createVocabList(dataSet): #创建一个空的不重复列表 vocabSet = set([]) #遍历数据集 for document in dataSet: vocabSet = vocabSet | set(document) #取并集 #print(vocabSet) return list(vocabSet)#生成一个包含所有单词的列表 """ 函数说明:根据vocabList词汇表,将inputSet向量化,向量的每个元素为1或0 Parameters: vocabList - createVocabList返回的列表 inputSet - 切分的词条列表 Returns: returnVec - 文档向量,词集模型 """ def setOfWords2Vec(vocabList, inputSet): #创建一个其中所含元素都为0的向量 returnVec = [0] * len(vocabList) #遍历每个词条 for word in inputSet: #如果词条存在于词汇表中,则置1 if word in vocabList: returnVec[vocabList.index(word)] = 1 else: pass #print("the word: %s is not in my Vocabulary!" % word) #print(returnVec) return returnVec #返回向量 """ 函数说明:朴素贝叶斯分类器训练函数 Parameters: trainMatrix - 训练文档矩阵,即setOfWords2Vec返回的returnVec构成的矩阵 trainCategory - 训练类别标签向量,即loadDataSet返回的classVec Returns: p1Vect,p2Vect,p3Vect,pAbusive,pBbusive,pCbusive """ def trainNB(trainMatrix,trainCategory): #计算训练的文档条数 numTrainDocs = len(trainMatrix) #print("numTrainDocs:" + str(numTrainDocs)) #计算每篇文档的词条数 numWords = len(trainMatrix[0]) #print("numWords:" + str(numWords)) count = np.full(3, 0.0) for i in range(len(trainCategory)): if trainCategory[i] == 1: count[0] += 1 elif trainCategory[i] == 2: count[1] += 1 else: count[2] += 1 pbusive = [] #计算先验概率 for i in range(3): pb = count[i] /float(numTrainDocs) pbusive.append(pb) #print(pbusive) #创建numpy.ones数组,词条出现数初始化为1,拉普拉斯平滑 pNum = np.ones((3,numWords)) #print(pNum) #分母初始化为0.0#避免其中一项为0的影响 pDenom = np.full(3, 2.0) #print(pDenom) for i in range(numTrainDocs): #统计属于低俗类的条件概率所需的数据,即P(w0|1),P(w1|1),P(w2|1)··· if trainCategory[i] == 1: pNum[0] += trainMatrix[i] pDenom[0] += sum(trainMatrix[i]) elif trainCategory[i] == 2: pNum[1] += trainMatrix[i] pDenom[1] += sum(trainMatrix[i]) else: pNum[2] += trainMatrix[i] pDenom[2] += sum(trainMatrix[i]) pVect = [] #避免下溢出问题 for i in range(3): pV = np.log(pNum[i]/pDenom[i]) #相除 pVect.append(pV) return pVect, pbusive #返回条件概率数组 """ 函数说明:朴素贝叶斯分类器分类函数 Parameters: vec2Classify - 待分类的词条数组 pVec pClass lables - 标签 Returns: 最大概率的标签 """ def classifyNB(vec2Classify, pVec, pClass,lables): #概率列表 p = [] #从左到右对一个序列的项累计地应用有两个参数的函数,以此合并序列到一个单一值 for i in range(len(lables)): result = sum(vec2Classify * pVec[i]) + np.log(pClass[i]) p.append(result) #返回p中元素从小到大排序后的索引值 # 按照升序进行快速排序,返回的是原数组的下标。 # 比如,x = [30, 10, 20, 40] # 升序排序后应该是[10,20,30,40],他们的原下标是[1,2,0,3] # 那么,numpy.argsort(x) = [1, 2, 0, 3] sortedpIndices = np.argsort(p) #返回最大概率标签 return lables[sortedpIndices[-1]] """ 函数说明:计算准确率 Parameters: testSet - 测试集 predictions - 预测值 Returns: 返回准确率 """ #计算准确率 def getAccuracy(testSet, predictions): correct = 0 for x in range(len(testSet)): if testSet[x] == predictions[x]: correct += 1 return (correct/float(len(testSet)))*100.0 """ 函数说明:测试朴素贝叶斯分类器 Parameters: 无 Returns: 无 """ def testingNB(): ## Step 1: load data print("Step 1: load data...") #创建数据 #prepare data trainSet = []#训练数据集 testSet = []#测试数据集 split = 0.8#分割的比例 #lables = ['Iris-setosa','Iris-versicolor','Iris-virginica'] lables = [1, 2, 3] loadDataset('C:/TensorFlow/irisdata.txt', split, trainSet, testSet) #数据集分割 train_X,train_Y = segmentation_Data(trainSet) test_X,test_Y = segmentation_Data(testSet) print('Train set: ' + repr(len(trainSet))) print('Test set: ' + repr(len(testSet))) #print(train_X) #print(train_Y) #创建实验样本 #listPosts,listClasses = loadDataSet() #创建词汇表 myVocabList = createVocabList(train_X) #向量化样本 trainMat=[] for postinDoc in train_X: #将实验样本向量化 trainMat.append(setOfWords2Vec(myVocabList, postinDoc)) #print(trainMat) ## Step 2: training... print("Step 2: training...") #训练朴素贝叶斯分类器 pV,pb = trainNB(np.array(trainMat),np.array(train_Y)) ## Step 3: testing print("Step 3: testing...") #测试样本 #testEntry = [5.1,3.5,1.4,0.2] #testEntry = [6.8,2.8,4.8,1.4] thisDoc = [] predictedLabel = [] for postinDoc in test_X: #将实验样本向量化 thisDoc.append(setOfWords2Vec(myVocabList, postinDoc)) #测试样本向量化 #thisDoc = np.array(setOfWords2Vec(myVocabList, testEntry)) for i in range(len(thisDoc)): result = classifyNB(thisDoc[i],pV,pb,lables) predictedLabel.append(result) ## Step 4: show the result print("Step 4: show the result...") #print(predictedLabel) #print(test_Y) #准确率 accuracy = getAccuracy(test_Y, predictedLabel) print('\nAccuracy: ' + repr(accuracy) + '%') if __name__ == '__main__': testingNB()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
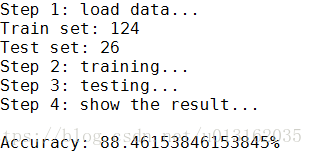
结果如下所示。
【完整代码参考2.NB_Iris_ Classify下的NB_Iris_Classify_v1】
3.6.2.2朴素贝叶斯实战之鸢尾花卉分类实现-调用sklearn库
接下来,我们使用sklearn来进行分类,代码如下。
# -*- coding: utf-8 -*- from sklearn import datasets from sklearn.naive_bayes import GaussianNB from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score ## Step 1: load data print("Step 1: load data...") #导入数据 iris = datasets.load_iris() ## Step 2: split data print("Step 2: split data...") #分离数据 # X = features X = iris.data # Y = label Y = iris.target X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=.6) ## Step 3: init NB print("Step 3: init NB...") #初始化贝叶斯分类器 gnb = GaussianNB() ## Step 4: training... print("Step 4: training...") #训练数据 gnb.fit(X_train, Y_train) ## Step 5: testing print("Step 5: testing...") #预测数据 predictedLabel = gnb.predict(X_test) #predictedLabel = gnb.fit(X_train, Y_train).predict(X_test) ## Step 6: show the result print("Step 6: show the result...") #求准确率 # http://scikit-learn.org/stable/modules/generated/sklearn.metrics.accuracy_score.html print(accuracy_score(Y_test, predictedLabel)) print("predictedLabel is :") print(predictedLabel)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
结果如下所示。
【完整代码参考2.NB_Iris_ Classify下的NB_Iris_Classify_v2.py】

3.6.3朴素贝叶斯之垃圾邮件过滤
3.6.3.1朴素贝叶斯之垃圾邮件过滤实现
朴素贝叶斯的一个最著名的应用:电子邮件垃圾过滤。
对于英文文本,我们可以以非字母、非数字作为符号进行切分,使用split函数即可。编写代码如下:
# -*- coding: UTF-8 -*- import re """ 函数说明:接收一个大字符串并将其解析为字符串列表 Parameters: 无 Returns: 无 """ def textParse(bigString): #将字符串转换为字符列表 listOfTokens = re.split(r'\W*', bigString) #将特殊符号作为切分标志进行字符串切分,即非字母、非数字 return [tok.lower() for tok in listOfTokens if len(tok) > 2] #除了单个字母,例如大写的I,其它单词变成小写 """ 函数说明:将切分的实验样本词条整理成不重复的词条列表,也就是词汇表 Parameters: dataSet - 整理的样本数据集 Returns: vocabSet - 返回不重复的词条列表,也就是词汇表 """ def createVocabList(dataSet): vocabSet = set([]) #创建一个空的不重复列表 for document in dataSet: vocabSet = vocabSet | set(document) #取并集 return list(vocabSet) if __name__ == '__main__': docList = []; classList = [] for i in range(1, 26): #遍历25个txt文件 wordList = textParse(open('email/spam/%d.txt' % i, 'r').read()) #读取每个垃圾邮件,并字符串转换成字符串列表 docList.append(wordList) classList.append(1) #标记垃圾邮件,1表示垃圾文件 wordList = textParse(open('email/ham/%d.txt' % i, 'r').read()) #读取每个非垃圾邮件,并字符串转换成字符串列表 docList.append(wordList) classList.append(0) #标记非垃圾邮件,1表示垃圾文件 vocabList = createVocabList(docList) #创建词汇表,不重复 print(vocabList) 根据词汇表,我们就可以将每个文本向量化。我们将数据集分为训练集和测试集,使用交叉验证的方式测试朴素贝叶斯分类器的准确性。编写代码如下: # -*- coding: utf-8 -*- import numpy as np import random import re """ 函数说明:将切分的实验样本词条整理成不重复的词条列表,也就是词汇表 Parameters: dataSet - 整理的样本数据集 Returns: vocabSet - 返回不重复的词条列表,也就是词汇表 """ def createVocabList(dataSet): vocabSet = set([]) #创建一个空的不重复列表 for document in dataSet: vocabSet = vocabSet | set(document) #取并集 return list(vocabSet) """ 函数说明:根据vocabList词汇表,将inputSet向量化,向量的每个元素为1或0 Parameters: vocabList - createVocabList返回的列表 inputSet - 切分的词条列表 Returns: returnVec - 文档向量,词集模型 """ def setOfWords2Vec(vocabList, inputSet): #创建一个其中所含元素都为0的向量 returnVec = [0] * len(vocabList) #遍历每个词条 for word in inputSet: if word in vocabList: #如果词条存在于词汇表中,则置1 returnVec[vocabList.index(word)] = 1 else: print("the word: %s is not in my Vocabulary!" % word) return returnVec#返回文档向量 """ 函数说明:朴素贝叶斯分类器训练函数 Parameters: trainMatrix - 训练文档矩阵,即setOfWords2Vec返回的returnVec构成的矩阵 trainCategory - 训练类别标签向量,即loadDataSet返回的classVec Returns: p0Vect p1Vect pAbusive """ def trainNB(trainMatrix,trainCategory): #计算训练的文档数目 numTrainDocs = len(trainMatrix) #计算每篇文档的词条数 numWords = len(trainMatrix[0]) pAbusive = sum(trainCategory)/float(numTrainDocs) p0Num = np.ones(numWords); p1Num = np.ones(numWords) #创建numpy.ones数组,词条出现数初始化为1,拉普拉斯平滑 #分母初始化为2,拉普拉斯平滑 p0Denom = 2.0 p1Denom = 2.0 for i in range(numTrainDocs): if trainCategory[i] == 1: #统计属于侮辱类的条件概率所需的数据,即P(w0|1),P(w1|1),P(w2|1)··· p1Num += trainMatrix[i] p1Denom += sum(trainMatrix[i]) else: #统计属于非侮辱类的条件概率所需的数据,即P(w0|0),P(w1|0),P(w2|0)··· p0Num += trainMatrix[i] p0Denom += sum(trainMatrix[i]) #取对数,防止下溢出 p1Vect = np.log(p1Num/p1Denom) p0Vect = np.log(p0Num/p0Denom) #返回条件概率数组 return p0Vect,p1Vect,pAbusive """ 函数说明:朴素贝叶斯分类器分类函数 Parameters: vec2Classify - 待分类的词条数组 p0Vec 条件概率数组 p1Vec pClass1 Returns: """ def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1): p1 = sum(vec2Classify * p1Vec) + np.log(pClass1) #对应元素相乘。logA * B = logA + logB,所以这里加上log(pClass1) p0 = sum(vec2Classify * p0Vec) + np.log(1.0 - pClass1) if p1 > p0: return 1 else: return 0 """ 函数说明:接收一个大字符串并将其解析为字符串列表 Parameters: 无 Returns: 无 """ def textParse(bigString): #将字符串转换为字符列表 #将特殊符号作为切分标志进行字符串切分,即非字母、非数字 listOfTokens = re.split(r'\W*', bigString) #除了单个字母,例如大写的I,其它单词变成小写 return [tok.lower() for tok in listOfTokens if len(tok) > 2] """ 函数说明:测试朴素贝叶斯分类器 Parameters: 无 Returns: 无 """ def spamTest(): ## Step 1: load data print("Step 1: load data...") docList = [] classList = [] fullText = [] for i in range(1, 26): #遍历25个txt文件 #读取每个垃圾邮件,并字符串转换成字符串列表 wordList = textParse(open('email/spam/%d.txt' % i, 'r').read()) docList.append(wordList) fullText.append(wordList) #标记垃圾邮件,1表示垃圾文件 classList.append(1) #读取每个非垃圾邮件,并字符串转换成字符串列表 wordList = textParse(open('email/ham/%d.txt' % i, 'r').read()) docList.append(wordList) fullText.append(wordList) #标记非垃圾邮件,1表示垃圾文件 classList.append(0) #创建词汇表,不重复 vocabList = createVocabList(docList) trainingSet = list(range(50)) #创建存储训练集的索引值的列表和测试集的索引值的列表 testSet = [] #从50个邮件中,随机挑选出40个作为训练集,10个做测试集 for i in range(10): #随机选取索索引值 randIndex = int(random.uniform(0, len(trainingSet))) #添加测试集的索引值 testSet.append(trainingSet[randIndex]) #在训练集列表中删除添加到测试集的索引值 del(trainingSet[randIndex]) #创建训练集矩阵和训练集类别标签系向量 trainMat = [] trainClasses = [] ## Step 2: training... print("Step 2: training...") #遍历训练集 for docIndex in trainingSet: #将生成的词集模型添加到训练矩阵中 trainMat.append(setOfWords2Vec(vocabList, docList[docIndex])) #将类别添加到训练集类别标签系向量中 trainClasses.append(classList[docIndex]) #训练朴素贝叶斯模型 p0V, p1V, pSpam = trainNB(np.array(trainMat), np.array(trainClasses)) #错误分类计数 errorCount = 0 ## Step 3: testing print("Step 3: testing...") #遍历测试集 for docIndex in testSet: #测试集的词集模型 wordVector = setOfWords2Vec(vocabList, docList[docIndex]) #如果分类错误 if classifyNB(np.array(wordVector), p0V, p1V, pSpam) != classList[docIndex]: #错误计数加1 errorCount += 1 print("分类错误的测试集:",docList[docIndex]) ## Step 4: show the result print("Step 4: show the result...") print('错误率:%.2f%%' % (float(errorCount) / len(testSet) * 100)) if __name__ == '__main__': spamTest()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
【完整代码参考3.NB_email_Classify下的NB_email_Classify_v1】
函数spamTest()会输出在10封随机选择的电子邮件上的分类错误概率。既然这些电子邮件是随机选择的,所以每次的输出结果可能有些差别。如果发现错误的话,函数会输出错误的文档的此表,这样就可以了解到底是哪篇文档发生了错误。如果想要更好地估计错误率,那么就应该将上述过程重复多次,比如说10次,然后求平均值。相比之下,将垃圾邮件误判为正常邮件要比将正常邮件归为垃圾邮件好。
3.6.3.2朴素贝叶斯之垃圾邮件过滤实现-调用sklearn库
和前面的例子一样,调用sklearn库。
# -*- coding: utf-8 -*- import random import re from sklearn.naive_bayes import GaussianNB from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score """ 函数说明:将切分的实验样本词条整理成不重复的词条列表,也就是词汇表 Parameters: dataSet - 整理的样本数据集 Returns: vocabSet - 返回不重复的词条列表,也就是词汇表 """ def createVocabList(dataSet): vocabSet = set([]) #创建一个空的不重复列表 for document in dataSet: vocabSet = vocabSet | set(document) #取并集 return list(vocabSet) """ 函数说明:根据vocabList词汇表,将inputSet向量化,向量的每个元素为1或0 Parameters: vocabList - createVocabList返回的列表 inputSet - 切分的词条列表 Returns: returnVec - 文档向量,词集模型 """ def setOfWords2Vec(vocabList, inputSet): #创建一个其中所含元素都为0的向量 returnVec = [0] * len(vocabList) #遍历每个词条 for word in inputSet: if word in vocabList: #如果词条存在于词汇表中,则置1 returnVec[vocabList.index(word)] = 1 else: print("the word: %s is not in my Vocabulary!" % word) return returnVec #返回文档向量 """ 函数说明:接收一个大字符串并将其解析为字符串列表 Parameters: 无 Returns: 无 """ def textParse(bigString): #将特殊符号作为切分标志进行字符串切分,即非字母、非数字 #将字符串转换为字符列表 listOfTokens = re.split(r'\W*', bigString) #print(listOfTokens) return [tok.lower() for tok in listOfTokens if len(tok) > 2] #除了单个字母,例如大写的I,其它单词变成小写 """ 函数说明:测试朴素贝叶斯分类器 Parameters: 无 Returns: 无 """ def spamTest(): ## Step 1: load data print("Step 1: load data...") docList = [] classList = [] fullText = [] for i in range(1, 26): #遍历25个txt文件 wordList = textParse(open('email/spam/%d.txt' % i, 'rt').read()) #读取每个垃圾邮件,并字符串转换成字符串列表 docList.append(wordList) fullText.append(wordList) classList.append(1) #标记垃圾邮件,1表示垃圾文件 wordList = textParse(open('email/ham/%d.txt' % i, 'rt').read()) #读取每个非垃圾邮件,并字符串转换成字符串列表 docList.append(wordList) fullText.append(wordList) classList.append(0) #标记非垃圾邮件,1表示垃圾文件 vocabList = createVocabList(docList) #创建词汇表,不重复 trainingSet = list(range(50)) #创建存储训练集的索引值的列表和测试集的索引值的列表 testSet = [] for i in range(10): #从50个邮件中,随机挑选出40个作为训练集,10个做测试集 randIndex = int(random.uniform(0, len(trainingSet))) #随机选取索索引值 testSet.append(trainingSet[randIndex]) #添加测试集的索引值 del(trainingSet[randIndex]) #在训练集列表中删除添加到测试集的索引值 #创建训练集矩阵和训练集类别标签系向量 trainMat = [] trainClasses = [] ## Step 2: training... print("Step 2: training...") #遍历训练集 for docIndex in trainingSet: #将生成的词集模型添加到训练矩阵中 trainMat.append(setOfWords2Vec(vocabList, docList[docIndex])) #将类别添加到训练集类别标签系向量中 trainClasses.append(classList[docIndex]) X_train, X_test, Y_train, Y_test = train_test_split(trainMat, trainClasses, test_size=.6) ## Step 3: init NB print("Step 3: init NB...") #初始化贝叶斯分类器 gnb = GaussianNB() ## Step 4: training... print("Step 4: training...") #训练数据 gnb.fit(X_train, Y_train) ## Step 5: testing print("Step 5: testing...") #预测数据 predictedLabel = gnb.predict(X_test) #predictedLabel = gnb.fit(X_train, Y_train).predict(X_test) ## Step 6: show the result print("Step 6: show the result...") #求准确率 # http://scikit-learn.org/stable/modules/generated/sklearn.metrics.accuracy_score.html print(accuracy_score(Y_test, predictedLabel)) print("predictedLabel is :") print(predictedLabel) if __name__ == '__main__': spamTest()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
结果如下所示。
【完整代码参考3.NB_email_Classify下的NB_email_Classify_v2】

3.6.4朴素贝叶斯sklearn总结
参考文档:
中文:http://sklearn.apachecn.org/cn/0.19.0/modules/naive_bayes.html
英文:http://scikit-learn.org/stable/modules/naive_bayes.html
API:http://scikit-learn.org/stable/modules/classes.html#module-sklearn.naive_bayes
朴素贝叶斯是一类比较简单的算法,scikit-learn中朴素贝叶斯类库的使用也比较简单。相对于决策树,KNN之类的算法,朴素贝叶斯需要关注的参数是比较少的,这样也比较容易掌握。在scikit-learn中,一共有3个朴素贝叶斯的分类算法类。分别是GaussianNB,MultinomialNB和BernoulliNB。其中GaussianNB就是先验为高斯分布的朴素贝叶斯,MultinomialNB就是先验为多项式分布的朴素贝叶斯,而BernoulliNB就是先验为伯努利分布的朴素贝叶斯。上篇文章讲解的先验概率模型就是先验概率为多项式分布的朴素贝叶斯。一般来说,如果样本特征的分布大部分是连续值,使用GaussianNB会比较好。如果如果样本特征的分大部分是多元离散值,使用MultinomialNB比较合适。而如果样本特征是二元离散值或者很稀疏的多元离散值,应该使用BernoulliNB。
GaussianNB类

class sklearn.naive_bayes.GaussianNB(priors=None)
- 1
参数说明:
- priors : 可选参数,默认为None。如果指定了先验信息,则不会根据数据进行调整。
GaussianNB假设特征的先验概率为正态分布,即如下式:
其中
C
k
C_k
Ck为
Y
Y
Y的第
k
k
k类类别。
μ
k
\mu_k
μk和
σ
k
2
\sigma_k^2
σk2为需要从训练集估计的值。
GaussianNB会根据训练集求出
μ
k
\mu_k
μk和
σ
k
2
\sigma_k^2
σk2。
μ
k
\mu_k
μk为在样本类别
C
k
C_k
Ck中,所有
X
j
X_j
Xj的平均值。
σ
k
2
\sigma_k^2
σk2为在样本类别
C
k
C_k
Ck中,所有
X
j
X_j
Xj的方差。
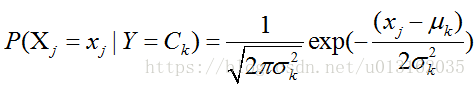
GaussianNB类的主要参数仅有一个,即先验概率priors ,对应 Y Y Y的各个类别的先验概率 P ( Y = C k ) P(Y=C_k) P(Y=Ck) 。这个值默认不给出,如果不给出此时 P ( Y = C k ) = m k / m P(Y=C_k)=mk/m P(Y=Ck)=mk/m 。其中 m m m为训练集样本总数量, m k mk mk为输出为第 k k k类别的训练集样本数。如果给出的话就以priors 为准。
在使用GaussianNB的fit方法拟合数据后,我们可以进行预测。此时预测有三种方法,包括predict,predict_log_proba和predict_proba。
predict方法就是我们最常用的预测方法,直接给出测试集的预测类别输出。
predict_proba则不同,它会给出测试集样本在各个类别上预测的概率。容易理解,predict_proba预测出的各个类别概率里的最大值对应的类别,也就是predict方法得到类别。
predict_log_proba和predict_proba类似,它会给出测试集样本在各个类别上预测的概率的一个对数转化。转化后predict_log_proba预测出的各个类别对数概率里的最大值对应的类别,也就是predict方法得到类别。
BernoulliNB类
class sklearn.naive_bayes.BernoulliNB(alpha=1.0, binarize=0.0, fit_prior=True, class_prior=None)
- 1
参数说明:
- alpha:浮点型可选参数,默认为1.0,其实就是添加拉普拉斯平滑,即为上述公式中的λ ,如果这个参数设置为0,就是不添加平滑;
- binarize : 浮点型可选参数,默认为0.0。样本特性的绑定(映射到布尔值)的阈值。如果没有,输入被认为是由二进制向量构成的。
- fit_prior:布尔型可选参数,默认为True。布尔参数fit_prior表示是否要考虑先验概率,如果是false,则所有的样本类别输出都有相同的类别先验概率。
- class_prior:可选参数,默认为None。
BernoulliNB假设特征的先验概率为二元伯努利分布,即如下式:
P
(
X
j
l
∣
Y
=
C
k
)
=
P
(
j
∣
Y
=
C
k
)
x
j
l
+
(
1
−
P
(
j
∣
Y
=
C
k
)
)
(
1
−
x
j
l
)
)
P(X_{jl}|Y=C_k)=P(j|Y=C_k)x_{jl} + (1-P(j|Y=C_k))(1 - x_{jl}))
P(Xjl∣Y=Ck)=P(j∣Y=Ck)xjl+(1−P(j∣Y=Ck))(1−xjl))

此时 只有两种取值。 x j l x_{jl} xjl只能取值0或者1。
BernoulliNB一共有4个参数,其中3个参数的名字和意义和MultinomialNB完全相同。唯一增加的一个参数是binarize。这个参数主要是用来帮BernoulliNB处理二项分布的,可以是数值或者不输入。如果不输入,则BernoulliNB认为每个数据特征都已经是二元的。否则的话,小于binarize的会归为一类,大于binarize的会归为另外一类。
在使用BernoulliNB的fit或者partial_fit方法拟合数据后,我们可以进行预测。此时预测有三种方法,包括predict,predict_log_proba和predict_proba。由于方法和GaussianNB完全一样。
MultinamialNB类
class sklearn.naive_bayes.MultinomialNB(alpha=1.0, fit_prior=True, class_prior=None)
- 1
参数说明:
- alpha:浮点型可选参数,默认为1.0,其实就是添加拉普拉斯平滑,即为上述公式中的λ ,如果这个参数设置为0,就是不添加平滑;
- fit_prior:布尔型可选参数,默认为True。布尔参数fit_prior表示是否要考虑先验概率,如果是false,则所有的样本类别输出都有相同的类别先验概率。否则可以自己用第三个参数class_prior输入先验概率,或者不输入第三个参数class_prior让MultinomialNB自己从训练集样本来计算先验概率,此时的先验概率为 。其中m为训练集样本总数量,mk为输出为第k类别的训练集样本数。
- class_prior:可选参数,默认为None。
MultinomialNB假设特征的先验概率为多项式分布,即如下式:
其中,
P
(
X
=
x
j
l
∣
Y
=
C
k
)
P(X=x_{jl}|Y=C_k)
P(X=xjl∣Y=Ck)是第
k
k
k个类别的第
j
j
j维特征的第
l
l
l个个取值条件概率。
m
k
mk
mk是训练集中输出为第
k
k
k类的样本个数。
λ
λ
λ 为一个大于
0
0
0的常数,常常取为
1
1
1,即拉普拉斯平滑。也可以取其他值。


MultinomialNB一个重要的功能是有partial_fit方法,这个方法的一般用在如果训练集数据量非常大,一次不能全部载入内存的时候。这时我们可以把训练集分成若干等分,重复调用partial_fit来一步步的学习训练集,非常方便。
GaussianNB和BernoulliNB也有类似的功能。 在使用MultinomialNB的fit方法或者partial_fit方法拟合数据后,我们可以进行预测。此时预测有三种方法,包括predict,predict_log_proba和predict_proba。predict方法就是我们最常用的预测方法,直接给出测试集的预测类别输出。predict_proba则不同,它会给出测试集样本在各个类别上预测的概率。容易理解,predict_proba预测出的各个类别概率里的最大值对应的类别,也就是predict方法得到类别。
predict_log_proba和predict_proba类似,它会给出测试集样本在各个类别上预测的概率的一个对数转化。转化后predict_log_proba预测出的各个类别对数概率里的最大值对应的类别,也就是predict方法得到类别。具体细节不再讲解,可参照官网手册。
参考文献:
[1]H. Zhang (2004). The optimality of Naive Bayes. Proc. FLAIRS.
主页:http://www.cs.unb.ca/~hzhang/
[2]http://sklearn.apachecn.org/cn/0.19.0/modules/naive_bayes.html
[3] http://scikit-learn.org/stable/modules/naive_bayes.html
[4]C.D. Manning, P. Raghavan and H. Schütze (2008). Introduction to Information Retrieval. Cambridge University Press, pp. 234-265.
[5]A. McCallum and K. Nigam (1998). A comparison of event models for Naive Bayes text classification. Proc. AAAI/ICML-98 Workshop on Learning for Text Categorization, pp. 41-48.
[6]V. Metsis, I. Androutsopoulos and G. Paliouras (2006). Spam filtering with Naive Bayes – Which Naive Bayes? 3rd Conf. on Email and Anti-Spam (CEAS).
【注】本章附件中笔者给出了更多的参考代码,请有兴趣的朋友自行阅读。
附件
本章参考代码

