
- 1SAP中权限常用Table清单列表_sap user role table
- 2度量衡计算工具_单位换算器|度量衡计量单位换算转换器下载v1.0 官方版 - 欧普软件下载...
- 3Git必知必会基础(10):本地冲突(conflicts)解决--rebase
- 4【编译链接与运行】_bin文件bss段
- 5节日专访|「我」是「我」
- 6计算机毕业设计基于springboot+vue+elementUI的疫情防控期间某村外出务工人员信息管理系统(源码+系统+mysql数据库+Lw文档)_村人员信息查询系统源码下载
- 7科研 | AI芯片:CPU GPU TPU DPU NPU BPU简介_npu和dpu
- 8SpringCloud - Eureka服务注册中心_注册中心eureka 连接限制
- 9开源鸿蒙系统4.0社保卡读卡器开发包适配
- 10Nginx手册_输入一个路径,实现将该路径下所有的文件归类。相同类型的文件放在同一个文件夹下
NLPer福利 清华推出Prompt-tuning开源工具包,取代传统的微调fine-tuning_清华prompt-tuning工具包
赞
踩
大家好,我是对白。
今天要给大家推荐一下我校计算机系NLP实验室的最新成果:OpenPrompt开源工具包。有了它,初学者也可轻松部署Prompt-learning框架来利用预训练模型解决各种NLP问题,下面就让我们一起来看看吧。
如何高效地使用大规模预训练语言模型(Pre-trained Language Models, PLMs)是近年NLP领域中的核心问题之一。一直以来,传统的微调(fine-tuning范式)一直是驱动大模型的“基本操作”。在微调范式中,我们需要在预训练模型上引入额外的目标函数来,从而将大模型适配到各类下游任务中。
背景介绍:
Promp****t-learning范式的崛起
最近一段时间,一种新的驱动大模型的范式受到了NLP界的广泛关注,它就是提示学习(prompt-learning,又prompt-tuning),它将对输入的文本按照模板进行特殊的处理,把任务重构成一个“预训练任务”。比如,在一个情感分类任务中,我们需要判断“这电影让我感觉浪费生命”这句话的情感是“正向”还是“负向”,则可以用模板把分类问题转化为一个“完形填空”问题:“这电影让我感觉浪费生命,它真的很[MASK]”,这里的输出是“棒”和“糟”来对应二分类。研究发现,在训练样本较少时,prompt-learning的表现会异常优异,它能够有效地建立起预训练和模型适配之间的桥梁。更重要地,它是我们驱动超大模型(如无法直接微调的千亿参数模型)的有效手段。
OpenPrompt:
开源Prompt-learning工具包
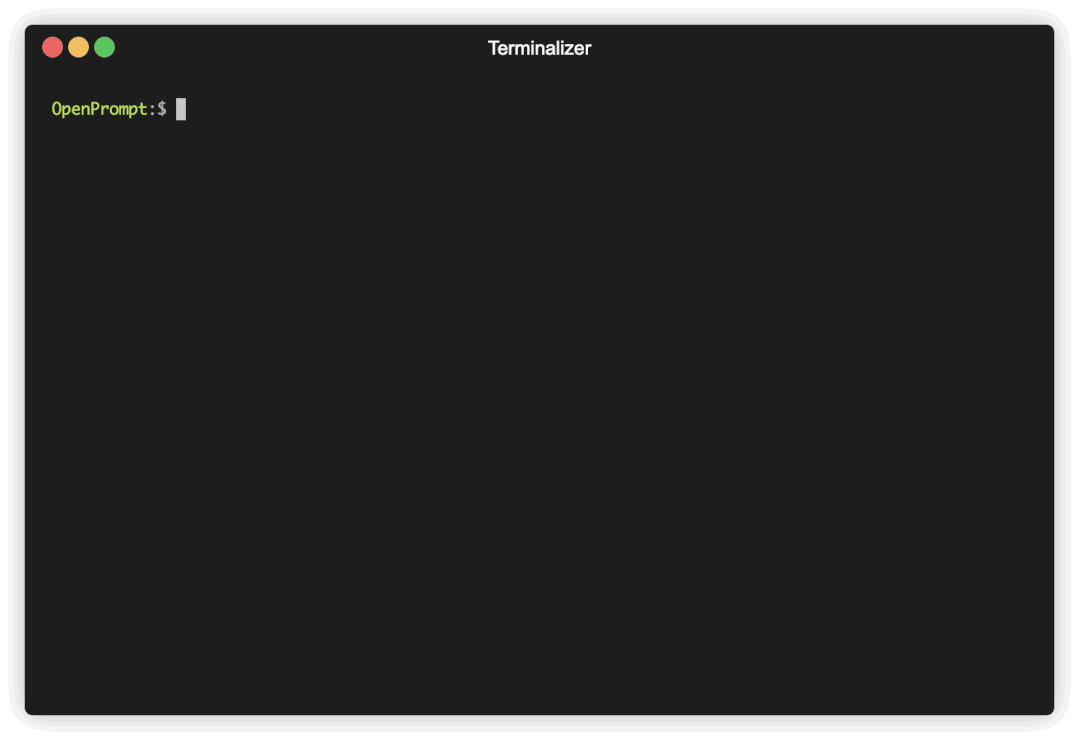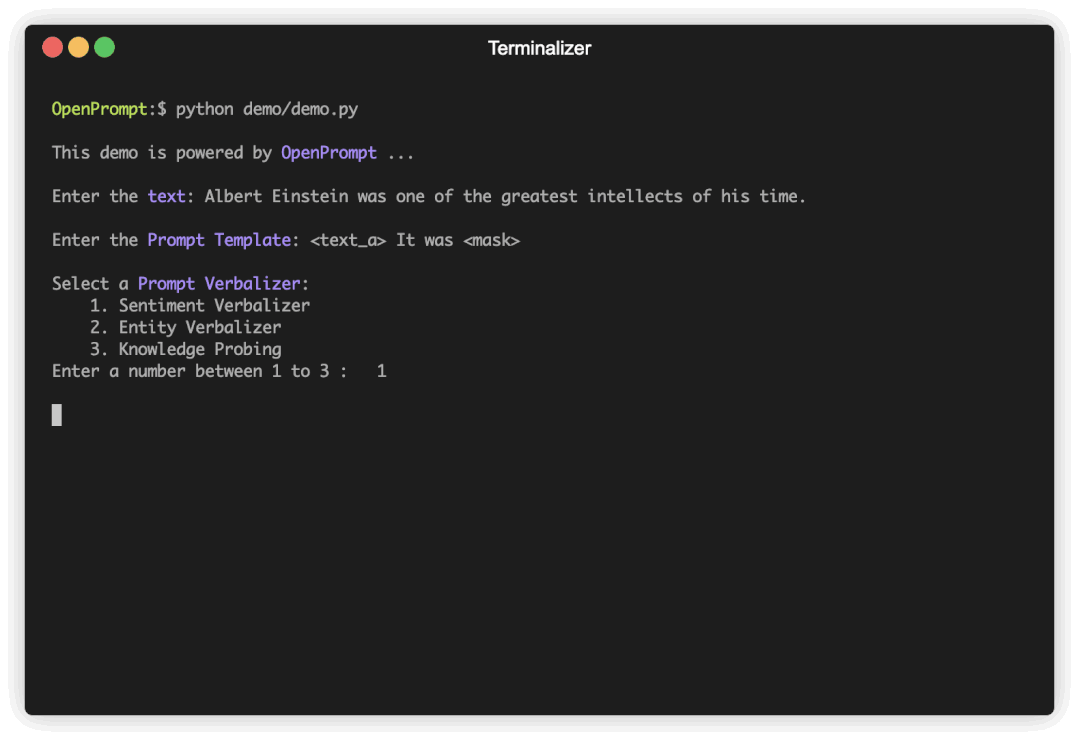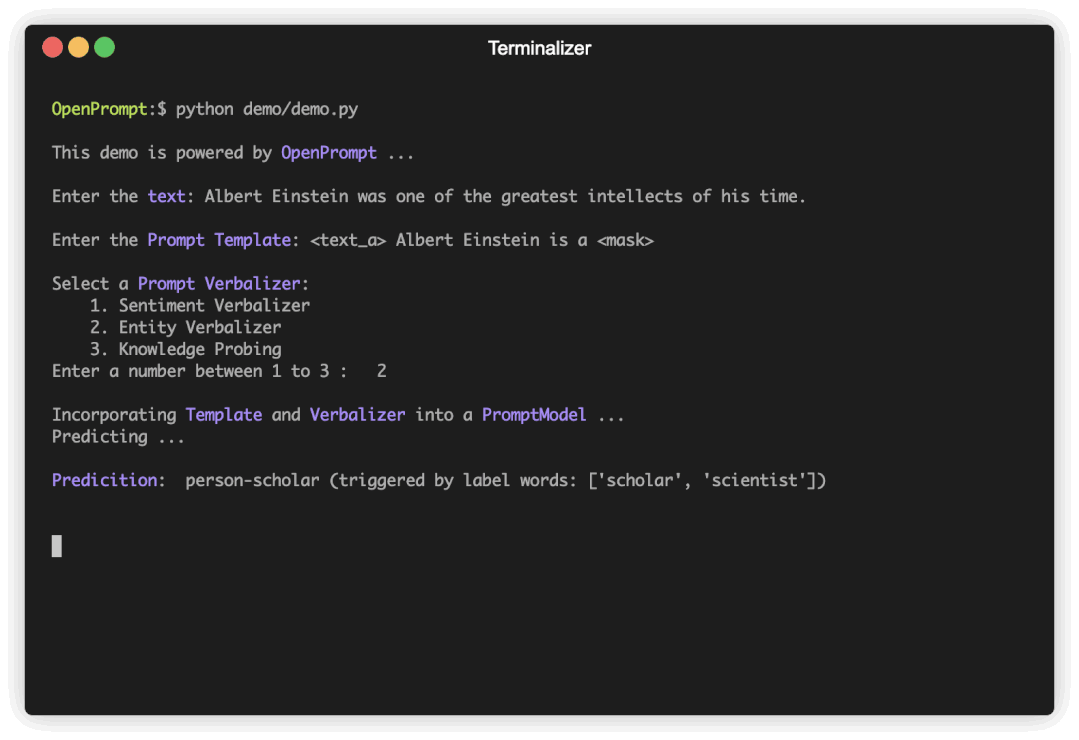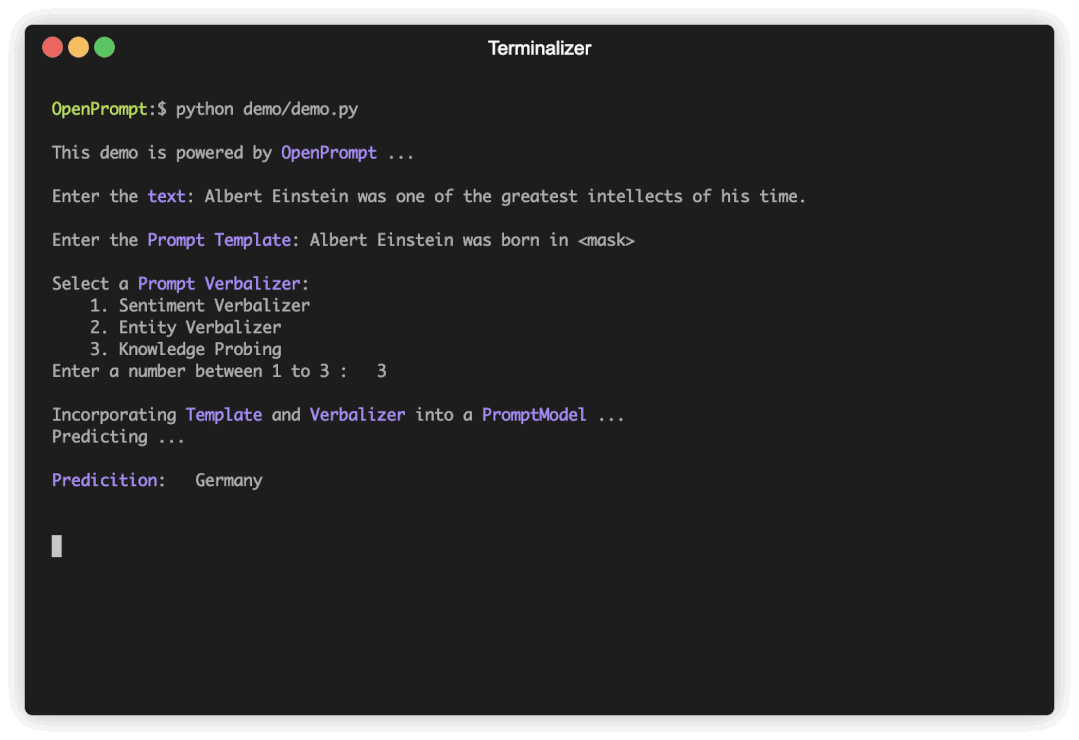
图1 使用OpenPrompt来建模不同的NLP任务
如今,NLP学术界已经出现了一系列的prompt-learning方法,内容涵盖了模板的构建和搜索,标签到词典的映射和优化,prompt-learning在各种下游任务的适配等等。然而,当我们去具体深入源代码时,会发现prompt-learning的实现方式是没有统一的范式的,这些方法都是力求在已有的传统微调框架中进行细微高效的改动来实现prompt-learning,可能会造成较差的可读性和可复现性。事实上,一个prompt-learning流程是预训练任务、当前任务、人类先验知识、模型架构的综合过程。我们可能在具体实现中遇到各种细节问题,如:该用什么类型的模型,是MLM还是seq2seq?该用什么参数级别的模型,是亿级、十亿级还是百亿级以上的超大模型?该使用什么模板?是人工构建还是用soft tokens随机初始化?该如何构建标签到词表的映射?该使用什么训练手段?**最近,清华大学自然语言处理实验室团队发布了一个统一范式的prompt-learning工具包OpenPrompt,**旨在让初学者、开发者、研究者都能轻松地部署prompt-learning框架来利用预训练模型解决各种NLP问题。它有如下特点:
-
易用性**。**基于OpenPrompt工具包,使用者可以快速根据不同任务部署prompt-learning框架。
-
**组合性。**从前的prompt-learning研究往往只实验了一种设定,在OpenPrompt的模块化支持下,使用者可以自由地将模型、模板、标词映射进行组合,从而进行更加全面的实验。
-
**拓展性。**OpenPrompt具有灵活的可拓展性,使用者可以轻松地在其之上完成进阶开发,让你的prompt-learning研究快人一步!
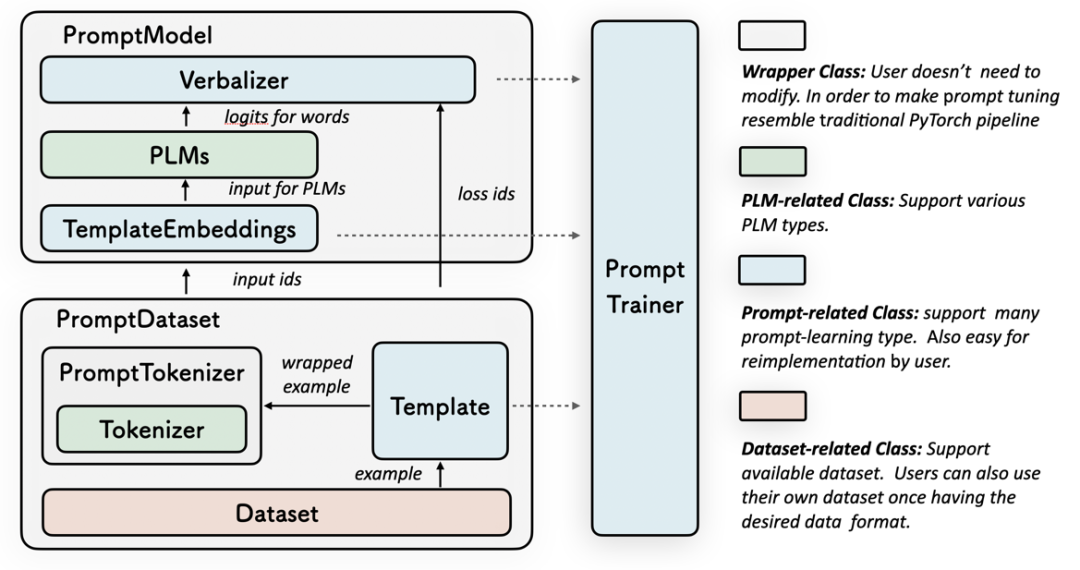
图2 OpenPrompt工具包结构图
同时,开发团队已经用OpenPrompt实现了一些代表性的prompt-learning工作,可以看出,在科学的模块设计下,这些工作都是可以在OpenPrompt统一框架下实现的。
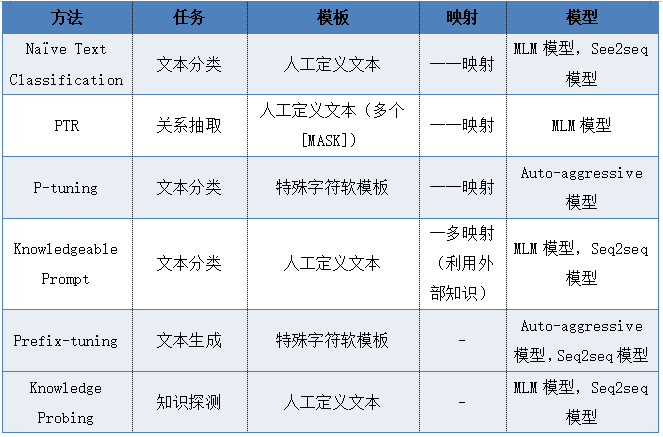
表1 一些OpenPrompt中实现的prompt-learning工作
关于更详细的用法和说明,请扫描下方二维码或参考项目链接https://github.com/thunlp/OpenPrompt。

上手教程:
使用OpenPrompt
OpenPrompt的使用非常简便,首先git clone项目并且安装依赖:

在OpenPrompt中,一个PromptModel是由一个Template类、一个Verbalizer和一个预训练模型组成,其中Template类主要负责模板的定义,在这里不仅支持从文件中直接读入人工定义的模板,也支持通过迭代搜索等方式构建模板,Verbalizer类则是负责从标签词到词表的映射的定义,同样支持进阶操作。
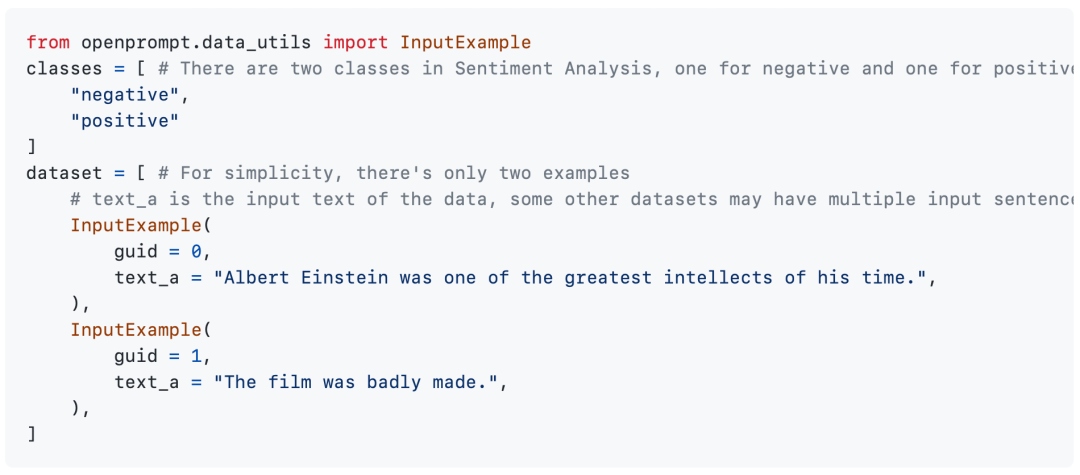
第一步:定义任务
Prompt-learning范式几乎可以应用到任意的NLP范式上,因此第一步是定义当前的任务,这里本质上是定义classes和InputExample。这里使用情感分类为例。
第二步:选择预训练模型
选择预训练模型的本质上是选择预训练任务,不同的预训练模型也具有不同的特性,在OpenPrompt的模块性和灵活性的支持下,我们鼓励开发着探索不同预训练语言模型的特性,OpenPrompt与Huggingface Transfomers库兼容,可以一键调用。

第三步:定义模板(Template)
模板是prompt-learning中最重要的模块之一,它可以是文本或者无意义的特殊字符,将原始输入进行修改和封装。

第四步:定义映射(Verbalizer)
Verbalizer将标签映射到词典中的标签词中,它也是prompt-learning中比较重要的组成部分(但并不是必要的,如在生成任务中)。

第五步:定义PromptModel
将以上这些模块结合,我们将得到一个PromptModel,尽管在当前的例子中,这些模块只是封装到了一起,但在实际操作中,用户可以定义很多它们之间的进阶交互。

接下来就可以进行训练了!训练的流程和PyTorch的传统范式兼容,关注官方文档来获取更多关于OpenPrompt的信息。
进阶开发:
使用OpenPrompt开发自己的prompt-learning框架
OpenPrompt中提供了一些经典数据集的下载链接,同时使用者也可以根据自己的需求将数据集来开发prompt-learning框架。由于prompt-learning在少样本学习中的优异表现,OpenPrompt提供了少样本采样FewShotSampler类,使得使用者可以轻松对数据集进行不同粒度的采样,验证自己的prompt-learning框架的有效性。
在使用者自己实现的Template类中,需要继承prompt_base文件中的Template基类,这里定义了作为Template的基本属性,使用者可以指定构建模板的具体方式,其中哪些token是要被训练的,哪些token是不在词表中的新特殊字符(即soft-encoding),同时可以通过定义wrap_one_example方法来定义如何将一个输入数据用模板进行包装。在Verbalizer类中,同样地,使用者可以通过定义label_words来确定词表中的哪些词需要被标签所对应,同时可以设置如何将这些词的logits取出并应用的方式。通过将Template、Verbalizer和模型本身进行组合,我们可以得到一个PromptModel类,在这个类中,我们可以定义它们之间的具体交互,如每一个输入可能对应一个Template和多个Verbalizer等等。
定义好自己的Prompt之后,开发者还可以设置不同的优化方式,如只优化prompt本身而不改变模型参数来进行具体地训练,工具包中已经缺省地提供了具体训练过程中的接口,如指定哪些文本是需要truncate的等等,使用者也可以自由地按照自己的想法对训练和评测过程进行修改。
参考文献
-
Liu P, Yuan W, Fu J, et al. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing[J]. arXiv preprint arXiv:2107.13586, 2021.
-
Han X, Zhao W, Ding N, et al. PTR: Prompt Tuning with Rules for Text Classification[J]. arXiv preprint arXiv:2105.11259, 2021.
-
Gao T, Fisch A, Chen D. Making pre-trained language models better few-shot learners[J]. arXiv preprint arXiv:2012.15723, 2020.
-
Ding N, Chen Y, Han X, et al. Prompt-learning for fine-grained entity typing[J]. arXiv preprint arXiv:2108.10604, 2021.
-
Lester B, Al-Rfou R, Constant N. The power of scale for parameter-efficient prompt tuning[J]. arXiv preprint arXiv:2104.08691, 2021.
-
Le Scao T, Rush A M. How many data points is a prompt worth?[C]//Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021: 2627-2636.
-
Liu X, Zheng Y, Du Z, et al. GPT Understands, Too[J]. arXiv preprint arXiv:2103.10385, 2021.
-
Qin G, Eisner J. Learning How to Ask: Querying LMs with Mixtures of Soft Prompts[J]. arXiv preprint arXiv:2104.06599, 2021.
-
Schick T, Schmid H, Schütze H. Automatically identifying words that can serve as labels for few-shot text classification[J]. arXiv preprint arXiv:2010.13641, 2020.
-
Li X L, Liang P. Prefix-tuning: Optimizing continuous prompts for generation[J]. arXiv preprint arXiv:2101.00190, 2021.
-
Zhao T Z, Wallace E, Feng S, et al. Calibrate before use: Improving few-shot performance of language models[J]. arXiv preprint arXiv:2102.09690, 2021.
-
Hu S, Ding N, Wang H, et al. Knowledgeable prompt-tuning: Incorporating knowledge into prompt verbalizer for text classification[J]. arXiv preprint arXiv:2108.02035, 2021.
机器学习/对比学习算法交流群
已建立机器学习/深度学习算法交流群!想要进交流群学习的同学,可以直接加我的微信号:duibai996。
加的时候备注一下:昵称+学校/公司。群里聚集了很多学术界和工业界大佬,欢迎一起交流算法心得,日常还可以唠嗑~

关于我
你好,我是对白,清华计算机硕士毕业,现大厂算法工程师,拿过8家大厂算法岗SSP offer(含特殊计划),薪资40+W-80+W不等。
高中荣获全国数学和化学竞赛二等奖。
本科独立创业五年,两家公司创始人,拿过三百多万元融资(已到账),项目入选南京321高层次创业人才引进计划。创业做过无人机、机器人和互联网教育,保研清华后退居股东。
我每周至少更新三篇原创,分享人工智能前沿算法、创业心得和人生感悟。我正在努力实现人生中的第二个小目标,上方关注后可以加我微信交流。
期待你的关注,我们一起悄悄拔尖,惊艳所有~

