
- 1本题要求统计给定整数M和N区间内素数的个数并对它们求和。
- 2山东移动E900V22D-S905L3B-5800-2ABMA02-安卓4.4.2-线刷固件包_e900v22d固件下载
- 3SpringBoot之操作Elasticsearch(基于RestTemplate方式实现)_elasticsearchresttemplate初始化
- 4旅行商问题(回溯算法)_旅行商问题回溯法
- 5技术阻击疫情,开发者在行动
- 6投票报名服务表结构 mysql_数据库投票表设计
- 7玩客云armbian刷机教程_玩客云刷机
- 8Windows下利用开源的FreeFileSync进行定期自动备份_freesync定时同步
- 9海外社交营销为什么用云手机?不用普通手机?
- 10[bug_fix][framework_base] RuntimeException: Failed to set system property——关于SystemProperty设置失败的问题_java.lang.runtimeexception: failed to set system p
Fine-Grained Semantically Aligned Vision-Language Pre-Training细粒度语义对齐的视觉语言预训练_语义对齐 细粒度
赞
踩
abstract
大规模的视觉语言预训练在广泛的下游任务中显示出令人印象深刻的进展。现有方法主要通过图像和文本的全局表示的相似性或对图像和文本特征的高级跨模态关注来模拟跨模态对齐。然而,他们未能明确学习视觉区域和文本短语之间的细粒度语义对齐,因为只有全局图像-文本对齐信息可用。在本文中,我们介绍放大镜![]() ,一个细粒度语义的Ligned visiOn-langUage PrE 训练框架,从博弈论交互的新视角学习细粒度语义对齐。为了有效地计算博弈论交互作用,我们进一步提出了一种不确定性感知神经Shapley交互学习模块。实验表明,LOUPE在各种视觉语言任务上都达到了最先进的性能。此外,无需任何对象级人工注释和微调,LOUPE 在对象检测和视觉接地方面实现了具有竞争力的性能。更重要的是,LOUPE开辟了一个新的有前途的方向,即从大规模原始图像-文本对中学习细粒度语义。这项工作的存储库位于 https://github.com/YYJMJC/LOUPE。
,一个细粒度语义的Ligned visiOn-langUage PrE 训练框架,从博弈论交互的新视角学习细粒度语义对齐。为了有效地计算博弈论交互作用,我们进一步提出了一种不确定性感知神经Shapley交互学习模块。实验表明,LOUPE在各种视觉语言任务上都达到了最先进的性能。此外,无需任何对象级人工注释和微调,LOUPE 在对象检测和视觉接地方面实现了具有竞争力的性能。更重要的是,LOUPE开辟了一个新的有前途的方向,即从大规模原始图像-文本对中学习细粒度语义。这项工作的存储库位于 https://github.com/YYJMJC/LOUPE。
1介绍
从大规模视觉语言预训练中学习可转移的跨模态表示,在各种下游任务中表现出卓越的性能。现存作品大多可分为两类:双编码器和融合编码器。双编码器方法JIA2021扩展; LI2021监督; 拉德福德2021学习; 姚2021菲利普采用两个独立的编码器嵌入图像和文本,并通过图像和文本的全局特征之间的余弦相似度对跨模态对齐进行建模。虽然这种架构通过离线预计算图像和文本表示来有效地进行大规模图像文本检索,但它们无法对视觉区域和文本短语之间的细粒度语义对齐进行建模。另一方面,融合编码器方法陈2020uniter; 金2021维尔特; LI2021对齐; LI2020奥斯卡; LU2019维尔伯特; QI2020图片伯特; TAN2019LXMERT; SU2019VL系列尝试使用单个多模态编码器对图像和文本的串联序列进行联合建模。这些方法通过高级跨模态注意力模拟软对准瓦斯瓦尼2017注意.然而,他们只能通过端到端训练来学习隐式对齐,缺乏明确的监督来鼓励视觉区域和文本短语之间的语义对齐。学习到的跨模态注意力矩阵通常是分散的和无法解释的。此外,它们的检索效率低下,因为它需要在推理过程中对每个图像-文本对进行联合编码。 从图像-文本预训练中学习细粒度语义对齐对于许多跨模态推理任务(例如,视觉基础)至关重要 yu2016建模、图片说明 XU2015展会),但由于视觉区域和文本短语之间的对齐信息不可用,因此它特别具有挑战性,这使得细粒度语义对齐学习成为弱监督学习问题。在本文中,我们解决了这个问题,同时保持了较高的检索效率,提出了放大镜![]() ,从博弈论的新颖视角来看,一个细粒度的语义L ignedvisiOn-langUage PrE-training 框架。我们将输入的补丁和单词标记表述为多个玩家到一个合作博弈中,并量化博弈论的相互作用(即 Shapley 相互作用 Grabisch1999公理; Shapley1953值),以调查语义对齐信息。LOUPE从两个阶段学习细粒度语义对齐:标记级Shapley交互建模和语义级Shapley交互建模,我们首先学习识别图像的语义区域,这些语义区域对应于一些语义上有意义的实体,然后将这些区域与配对文本中的短语对齐。
,从博弈论的新颖视角来看,一个细粒度的语义L ignedvisiOn-langUage PrE-training 框架。我们将输入的补丁和单词标记表述为多个玩家到一个合作博弈中,并量化博弈论的相互作用(即 Shapley 相互作用 Grabisch1999公理; Shapley1953值),以调查语义对齐信息。LOUPE从两个阶段学习细粒度语义对齐:标记级Shapley交互建模和语义级Shapley交互建模,我们首先学习识别图像的语义区域,这些语义区域对应于一些语义上有意义的实体,然后将这些区域与配对文本中的短语对齐。
具体来说,标记级 Shapley 交互建模旨在将图像的补丁标记分组到语义区域中,这些语义区域在语义上对应于某些视觉实例。从博弈论的角度来看,我们以补丁令牌为玩家,以图像和文本之间的相似度得分为博弈函数。 直观地讲,假设一组补丁标记对应图像中的视觉实例,那么它们往往具有很强的交互性,形成对应实例的完整语义,这有助于更好地判断与配对文本的相似度。 基于这一见解,我们将标记级Shapley交互作为软监督标签,以鼓励模型从图像中捕获语义区域。然后,语义层面的Shapley交互建模推断出语义区域和短语之间的细粒度语义对齐。我们将每个区域和短语视为玩家,并将细粒度的相似度分数定义为游戏函数。如果一个区域和一个短语有很强的对应关系,它们往往会相互作用,并有助于细粒度的相似性分数。通过测量每个区域-短语对之间的Shapley交互作用,我们获得了指导预训练模型的对齐信息。 由于计算精确的Shapley相互作用是一个NP难题松井2001NP,现有方法主要采用基于抽样的方法CASTRO2009多项式以获得无偏的估计。然而,随着玩家数量的增加,他们需要数千个模型评估。为了降低计算成本,我们进一步提出了一种高效的混合Shapley交互学习策略,其中不确定性感知神经Shapley交互学习模块与基于采样的方法协同工作。实验结果表明,该混合策略在保持估计精度的同时,显著节省了计算成本。更多分析见第 4.5 节。
我们的框架用作代理训练目标,明确地在局部区域和短语表示之间建立细粒度的语义对齐。对于下游任务,可以直接删除此代理目标,从而呈现高效且语义敏感的双编码器模型。实验表明,LOUPE在图像文本检索基准上达到了最先进的水平。在MSCOCO上进行文本到图像检索方面,LOUPE在recall@1上比其最强大的竞争对手高出4.2%。此外,无需任何微调,LOUPE就成功地以零样本方式转移到物体检测和视觉接地任务。对于物体检测,它在COCO上实现了12.1%的mAP,在PASCAL VOC上实现了19.5%的mAP。在视觉接地方面,它在 RefCOCO 上实现了 26.8% 的准确度,在 RefCOCO+ 上实现了 23.6% 的准确度。我们的贡献总结如下:
- •
我们建议放大镜
 这显式地学习了视觉区域和文本短语之间的细粒度语义对齐,同时保留了双编码器的高检索效率。
这显式地学习了视觉区域和文本短语之间的细粒度语义对齐,同时保留了双编码器的高检索效率。 - •
我们介绍了一种高效且有效的混合Shapley交互学习策略,该策略基于不确定性感知的神经Shapley交互学习模块和基于采样的方法。
- •
对图像文本数据进行预训练,LOUPE 实现了图像文本检索的新技术,并成功转移到需要更细粒度的对象级视觉理解(即对象检测和视觉基础)的任务中,而无需任何微调。
-
• 由于对大量对象类别进行手动注释既耗时又不可扩展,我们的工作展示了一种很有前途的替代方案,即从有关图像的原始文本中学习细粒度的语义,这些文本很容易获得并包含更广泛的视觉概念。
2相关工作
视觉语言预训练。预训练和微调范式在自然语言处理中的巨大成功Brown2020语言; 德夫林2018伯特和计算机视觉Dosovitskiy2020图片; HE2020势头; WEI2022MVP已扩展到视觉和语言的联合领域安德森2018底部; 安通2015VQA; LI2020无监督.占主导地位的视觉语言预训练模型可分为两类:双编码器和融合编码器。双编码器方法JIA2021扩展; LI2021监督; 拉德福德2021学习; 姚2021菲利普采用两个单独的编码器分别嵌入图像和文本,并通过余弦相似性对跨模态交互进行建模。这种架构对于大规模图像文本检索非常有效,因为图像和文本表示可以离线预先计算。然而,简单地测量全局表示之间的余弦相似性是肤浅的,无法捕获区域和短语之间的细粒度语义关系。 融合编码器方法陈2020uniter; 黄2021看到; 黄2020像素; 金2021维尔特; LI2021对齐; LI2020UNIMO; LI2020奥斯卡; LU2019维尔伯特; QI2020图片伯特; SU2019VL系列; TAN2019LXMERT; yu2020厄尼; 张2021VINVL采用单一的多模态编码器,对图像和文本的串联序列进行联合建模,实现更深层次的跨模态交互。然而,这些方法效率较低,因为图像和文本交织在一起以计算跨模态注意力,并且无法离线预先计算。此外,没有明确的监督信号来鼓励区域和短语之间的一致性。部分作品陈2020uniter; LI2020UNIMO; LI2020奥斯卡; LU2019维尔伯特; TAN2019LXMERT; yu2020厄尼; 张2021VINVL; 钟2022区域剪辑尝试利用现成的对象检测器来提取对象特征以进行预训练。然而,检测器通常在有限的对象类别上进行预训练。 此外,考虑到对内存和计算的过度需求,现有方法通常固定检测模型的参数,并将区域检测视为预处理步骤,与视觉语言预训练脱节。因此,性能也受到检测模型质量的制约。 菲 利 普姚2021菲利普使用标记级最大相似度来增强双编码器方法的跨模态交互。要学习显式细粒度语义对齐,GLIPLI2021停飞和 X-VLM曾2021多利用人工注释的数据集,其中具有边界框注释的区域与文本描述对齐。这种方式非常耗时,并且很难从互联网扩展到更大的原始图像文本数据。 相比之下,我们提出的框架从原始图像-文本数据中显式学习细粒度语义对齐,同时保持了双编码器的高效率。详细讨论可在附录 K. Shapley Values 中找到。Shapley 价值观Shapley1953值最初是在博弈论中引入的。从理论上讲,它已被证明是公平估计每个玩家在合作博弈中的贡献的独特指标,从而满足某些理想的公理Weber1988概率.凭借坚实的理论基础,Shapley值最近被研究为深度神经网络(DNN)的事后解释方法datta2016算法; Lundberg2017统一; 张2020口译.Lundberg等人。 Lundberg2017统一提出一种基于Shapley值的统一归因方法来解释DNN的预测。Ren 等人. REN2021统一建议用Shapley值来解释对抗性攻击。在本文中,我们提出了通过博弈论交互来模拟细粒度语义对齐,以及一种有效的Shapley交互学习策略。
3方法
在本节中,我们首先在第 3.1 节中介绍细粒度语义对齐视觉语言预训练的问题表述。然后,我们在第3.2节中提出了相应的细粒度语义对齐学习的LOUPE框架,并在第3.3节中提出了一种有效的Shapley交互学习方法。
3.1问题表述和模型概述
一般来说,视觉语言预训练旨在学习图像编码器�我和文本编码器�T通过跨模态对比学习,其中匹配的图像-文本对被优化以更接近,不匹配的对被优化以走得更远。让�我(我我)和�T(�我)表示图像和文本的全局表示形式。那么跨模态对比损失可以表述为:
| ℒCMC公司=−日志经验值(�我(我我)⊤�T(�我)/�))∑��经验值(�我(我我)⊤�T(��)/�)−日志经验值(�我(我我)⊤�T(�我)/�))∑��经验值(�我(我�)⊤�T(�我)/�)) | (1) |
哪里�是批大小和�是温度超参数。 虽然很直观,但这种方式只能学习图像和文本之间的粗略对齐,但无法明确捕获视觉区域和文本短语之间的细粒度语义对齐。为了学习细粒度的语义对齐,同时保持高检索效率,我们提出了LOUPE,这是一种从合作博弈论中萌芽的细粒度语义对齐视觉语言预训练框架。 如图 1 所示,LOUPE 从两个阶段学习细粒度语义对齐:标记级 Shapley 交互建模和语义级 Shapley 交互建模。 对于令牌级的Shapley交互建模,我们学习在基于令牌的语义聚合损失的指导下,将图像的补丁标记聚合到语义上对应于某些视觉概念的语义区域ℒ美国运输安全管理局(TSA).在语义层面的Shapley交互建模中,通过细粒度语义对齐损失,学习聚合区域与文本短语之间的语义对齐ℒFSA公司.结合两个新提出的损失,细粒度语义对齐的视觉语言预训练的完整目标可以表述为:
| ℒ=ℒCMC公司+ℒ美国运输安全管理局(TSA)+ℒFSA公司 | (2) |
这种新的预训练目标强制图像编码器捕获语义区域,并在视觉区域和文本短语之间建立细粒度的语义对齐。在推理过程中,可以直接将其删除,从而呈现出高效且语义敏感的双编码器。
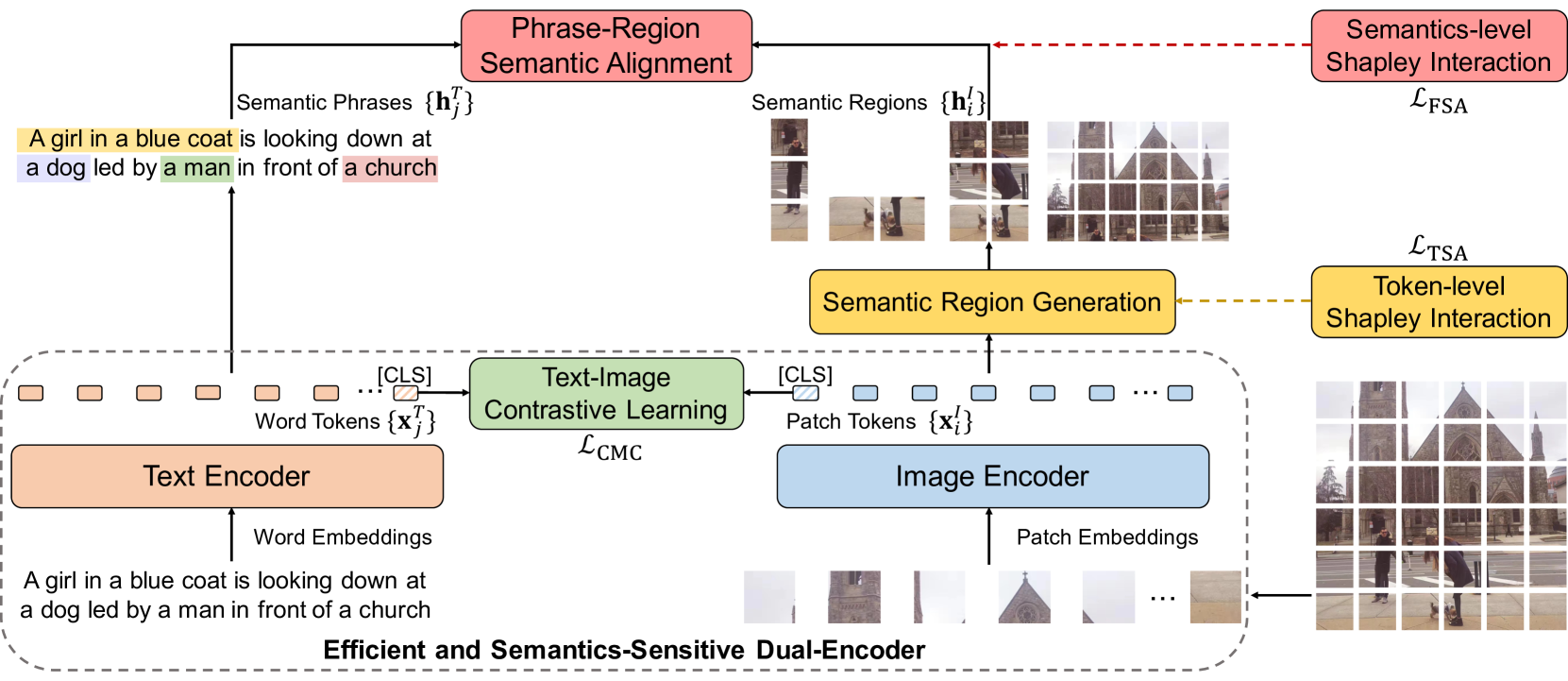
图 1:LUUPE概述。我们的框架作为一个代理训练目标,鼓励图像编码器捕获语义区域,并在区域和短语表示之间建立语义对齐。对于下游任务,可以轻松删除代理训练目标,从而呈现高效且语义敏感的双编码器。
3.2将细粒度语义对齐解释为博弈论交互
3.2.1预赛
Shapley 价值观。Shapley 价值观Shapley1953值是一种经典的博弈论解决方案,用于对合作博弈中每个参与者的重要性或贡献进行公正的估计。考虑一款带有
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

