- 12023软件测试必问的33个面试题【带答案】
- 2【Python】进阶学习:计算一个人BMI(身体质量指数)指数_计算身体质量指数python
- 3开发安全之:Cross-Site Scripting: DOM_cross-site scripting: dom parser.parsefromstring(s
- 4(建议收藏)OpenHarmony系统能力SystemCapability列表
- 5杭州城市开发者社区活动:CSDN CMeet 系列技术生态沙龙活动 《探索未来:生成式AI赋能千行百业·杭州》 等你来
- 6/usr/bin/env: 'bash\r': No such file or directory_/usr/bin/env: ‘bash\r’: no such file or directory
- 7解决android WebView无法唤起其他app_web 禁止自动唤起app
- 8导出或将模型转换为USDZ
- 91923: 2018蓝桥杯培训-STL应用专题-day 1 sort作业题3_2018蓝桥杯培训-stl应用专题 sort作业题1
- 10python爬取路况信息_高德实时路况数据获取
【机器学习3】鸢尾花数据集可视化,让枯燥的数据颜值爆表!_iris数据集可视化
赞
踩
本篇博客结合参考bilibili up主---同济子豪兄的【子豪兄机器学习】玩转鸢尾花iris数据集视频进行对经典数据集 鸢尾花数据集的研究探索。
鸢尾花

(梵高生命中的鸢尾花)
鸢尾花数据集?
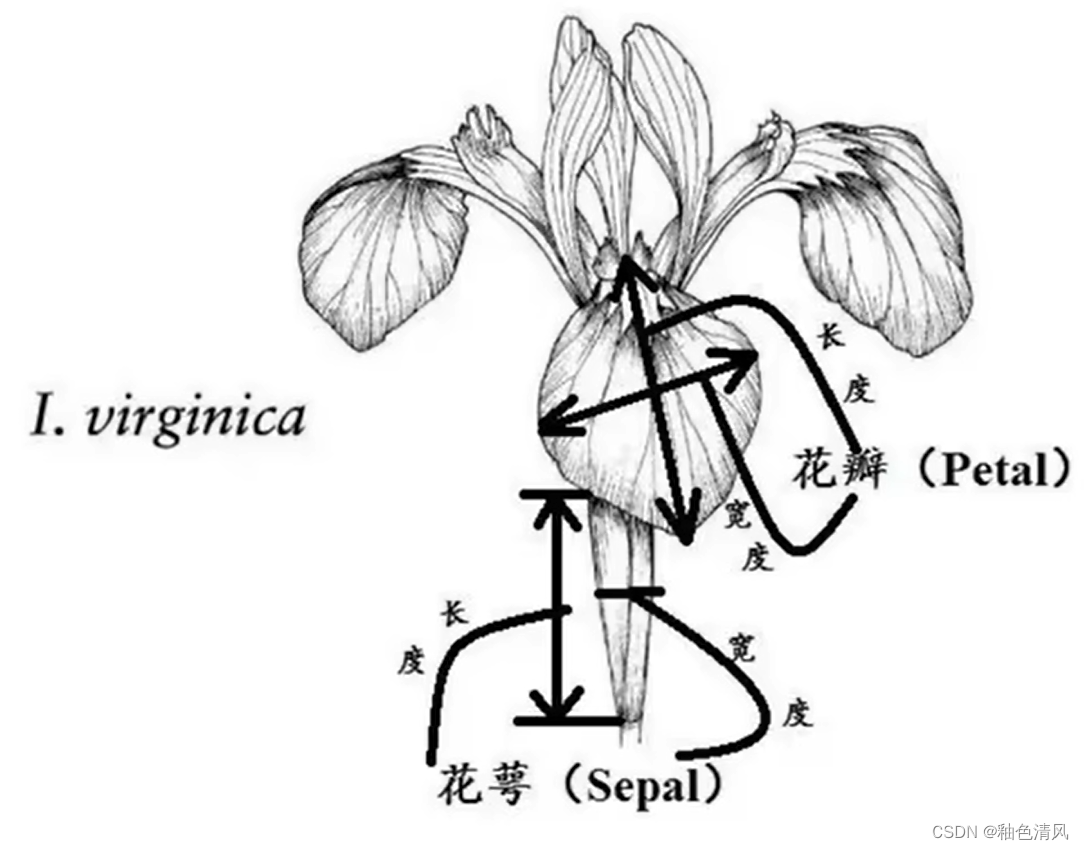
Iris数据集是常用的分类实验数据集,由Fisher, 1936收集整理。Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。
数据集包含150个数据样本,分为3类,每类50个数据,每个数据包含4个属性。可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类。
机器学习基本概念——特征、标签
特征是输入变量,即简单线性回归中的
变量,如鸢尾花数据集中的花萼长度、花萼宽度、花瓣长度、花瓣宽度,可以将这四个特征指定为
。
标签是我们要预测的事物,即简单线性回归中的
变量,如鸢尾花数据集中的鸢尾花的种类。
所以本次我们要研究的鸢尾花数据集包含了四个特征,一个标签。
导入鸢尾花数据库
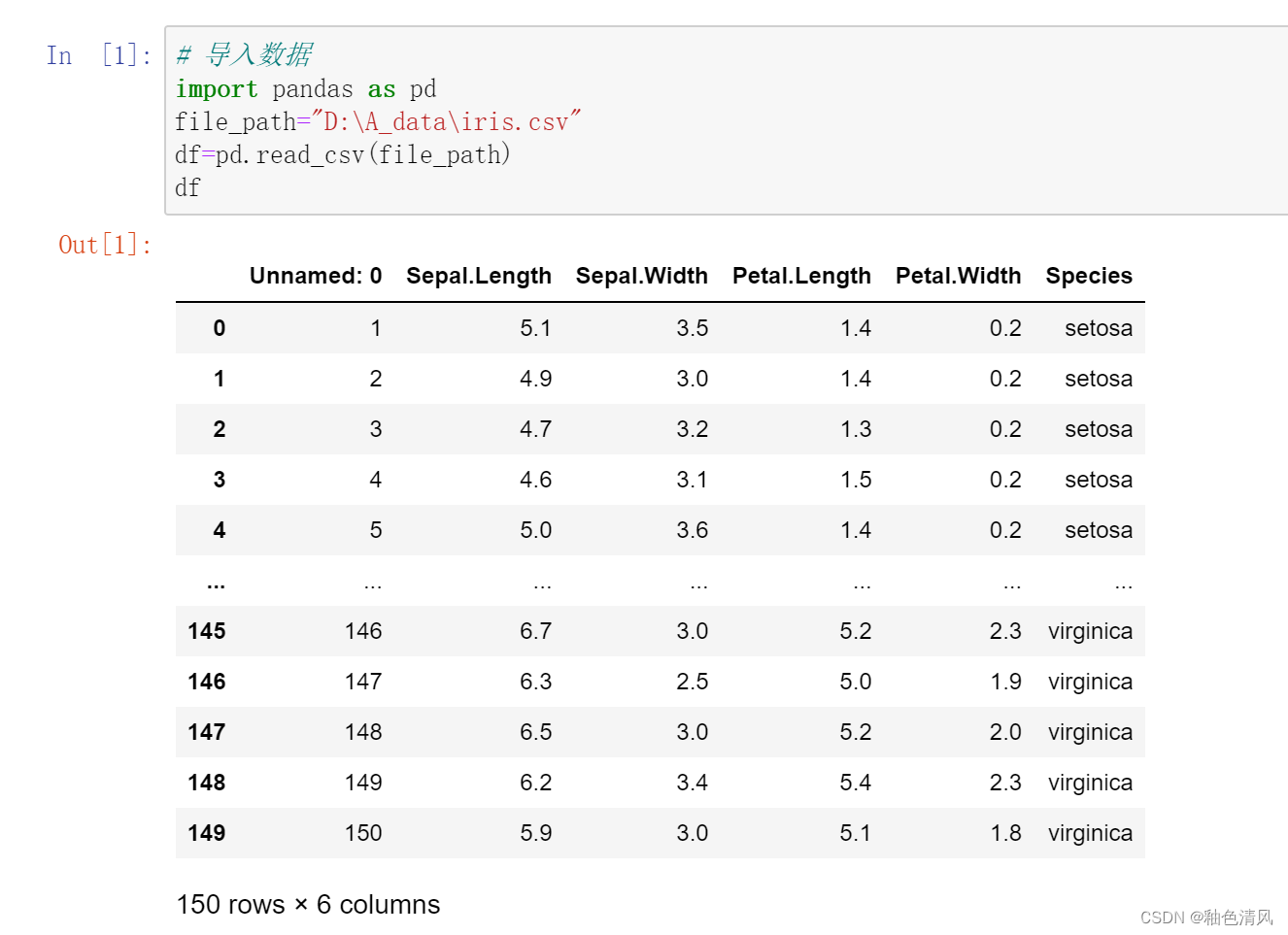
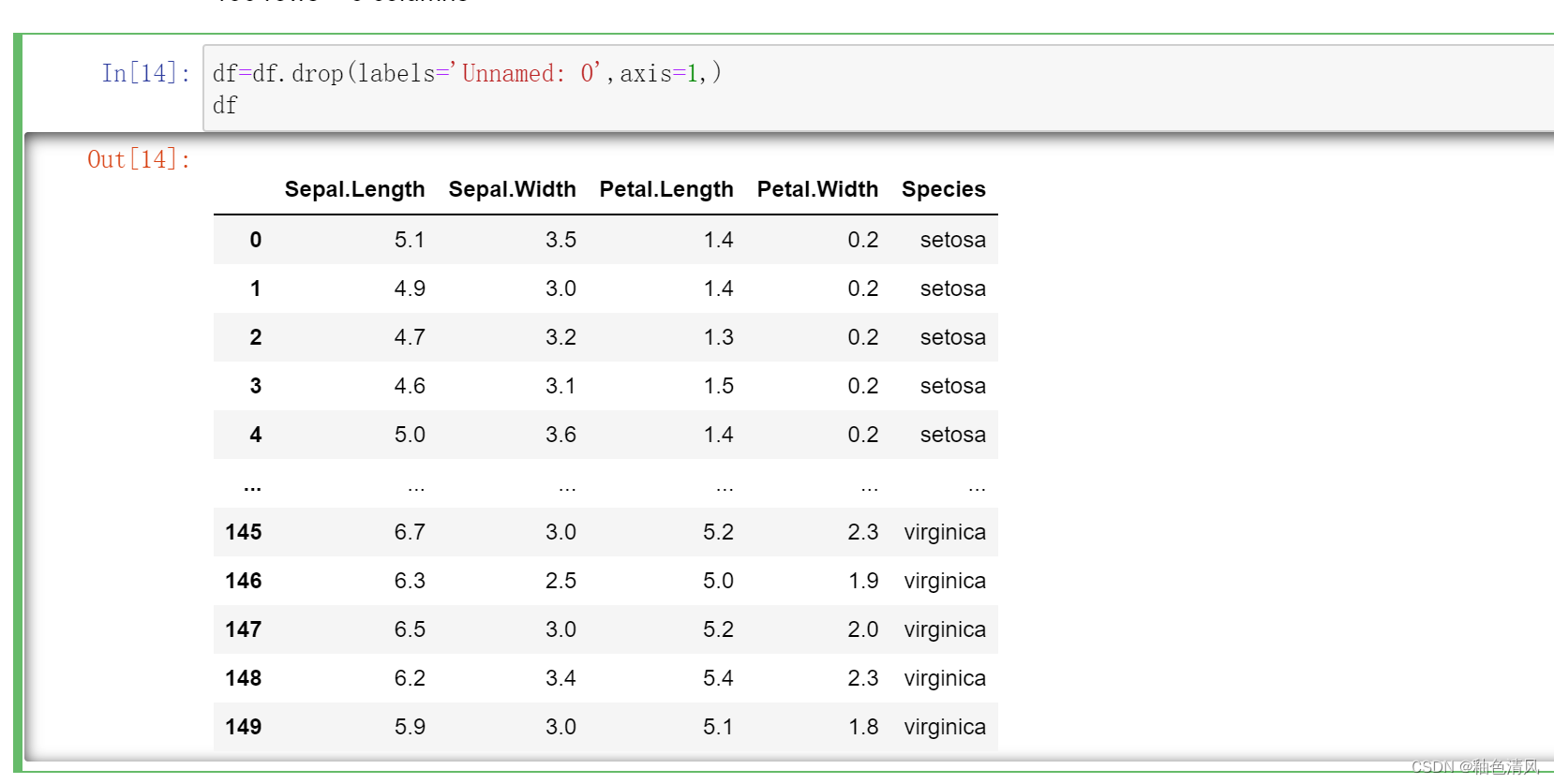
我们看到的加粗的一列是索引列,表格中的第0列是Unnamed: 0这一列,我认为这一列对后续的研究没有什么太大帮助,所以我考虑删除这一列。
删除某一列:drop()方法:
参数说明:
labels 就是要删除的行列的名字,用列表给定
axis 默认为0,指删除行,因此删除列时要指定axis=1;
index 直接指定要删除的行
columns 直接指定要删除的列
inplace=False,默认该删除操作不改变原数据,而是返回一个执行删除操作后的新的dataframe;
inplace=True,则会直接在原数据上进行删除操作,删除后无法返回。
导入库Python可视化数据库matplotlib

导入 Python可视化库seaborn
seaborn是基于matplotlib的Python可视化库,将matplotlib库进行了进一步的封装,使用更加简单,而且绘制出的图表更加高大上。

使用DataFrame的属性和方法对鸢尾花数据集进行探索性分析
.后面带()的是方法,不带()的是属性
df.shape:150行 5列

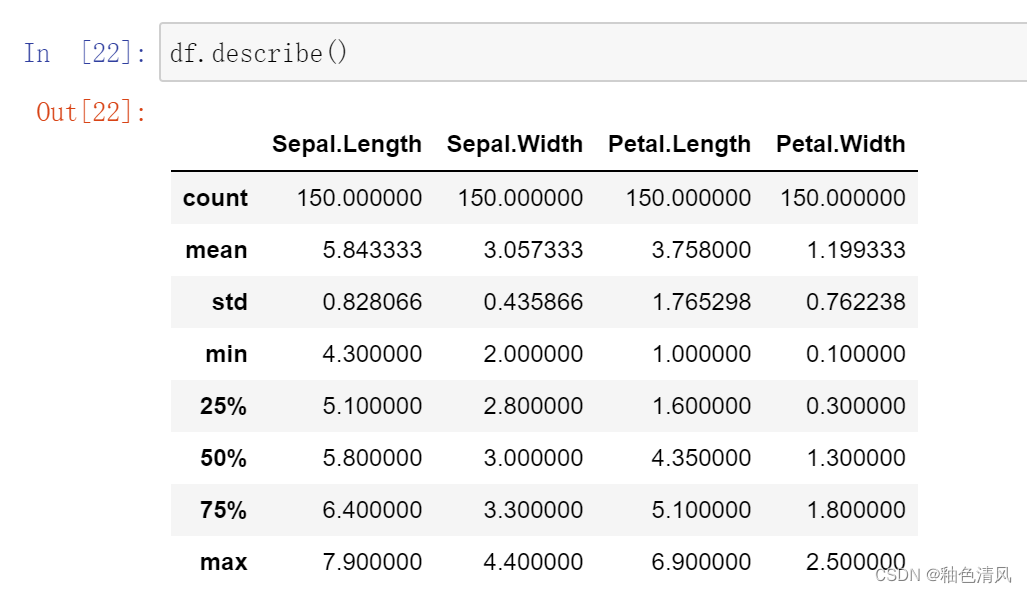
df.describe()查看各列数据的统计特征
df.info()查看缺失值情况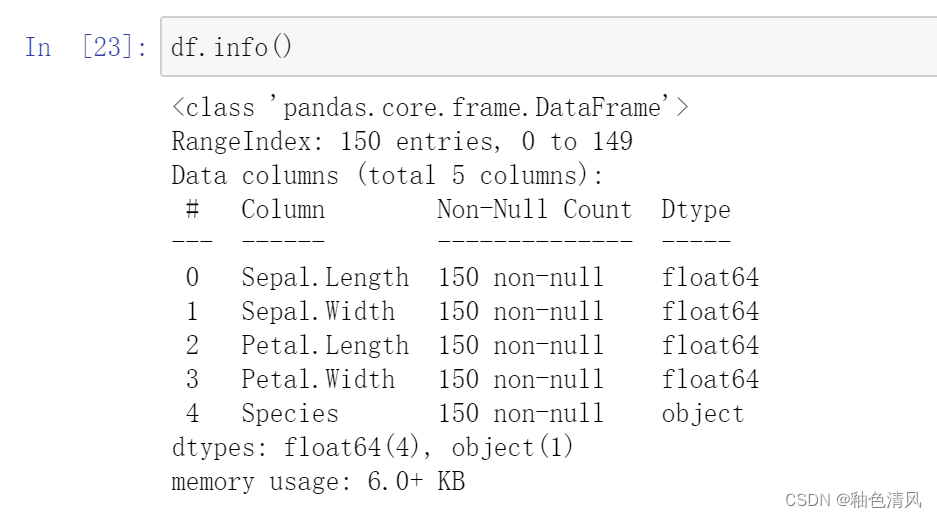
可视化鸢尾花数据
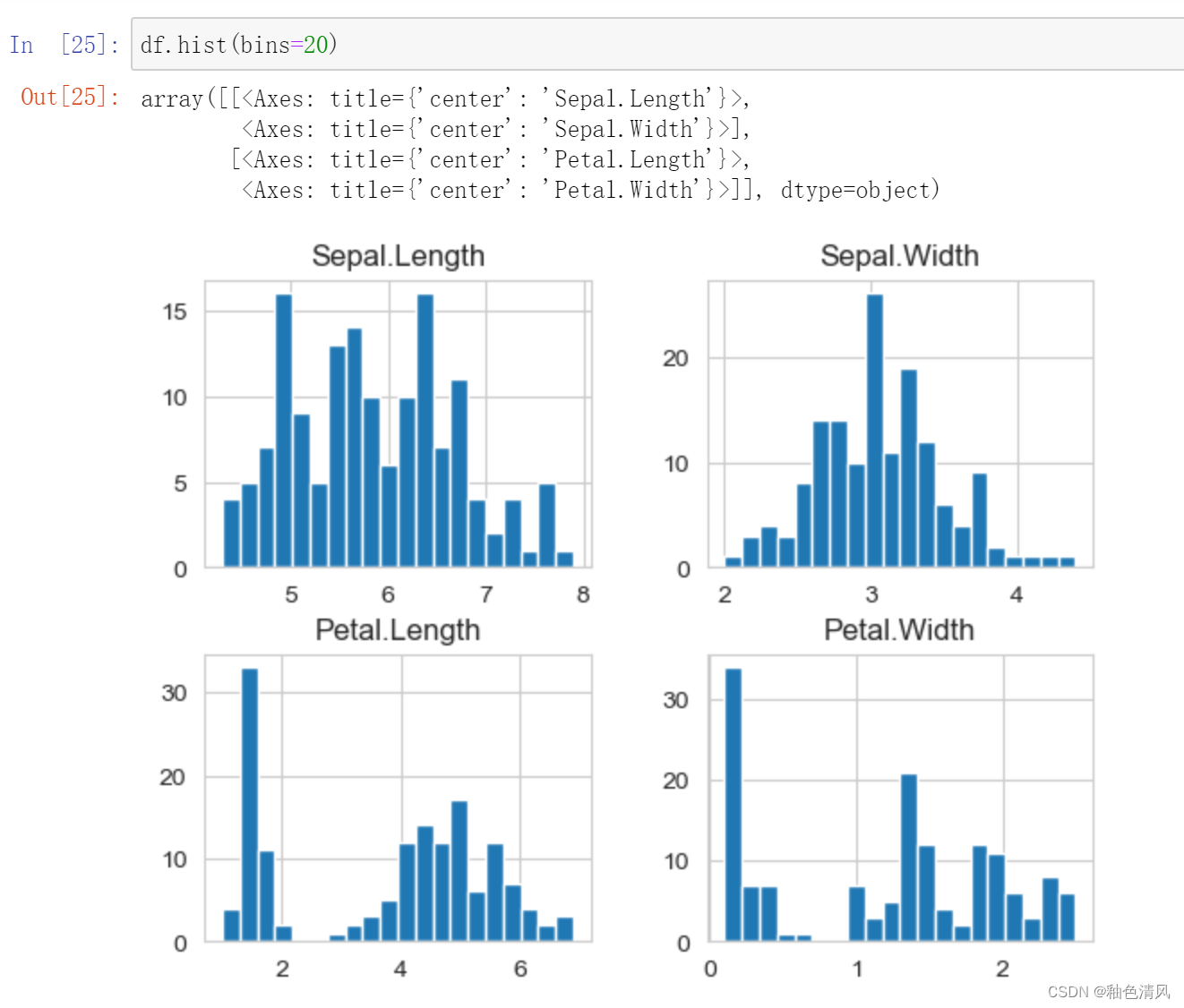
直方图: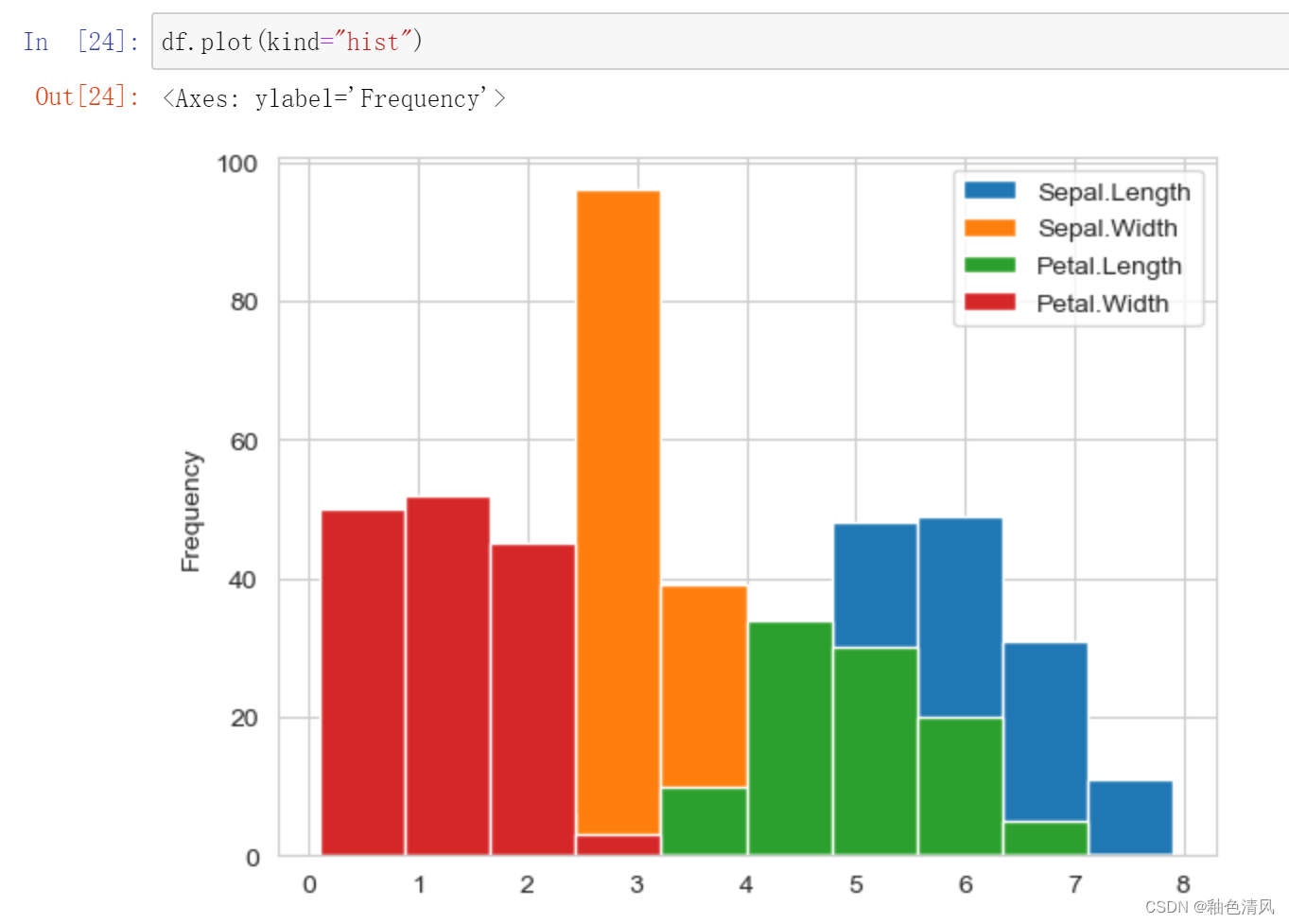
这里绘制出的直方图只是特征列,因为标签列它是三元分类,是离散的而非连续的,(横坐标为厘米)花萼长度、花萼宽度、花瓣长度、花瓣宽度,可以直观的看出每一列的大致分布。
绘制四列特征各自的直方图:
df.plot.area()可以直观的看出三类鸢尾花的花萼长度、花萼宽度、花瓣长度、花瓣跨宽度的大致大小。(由下面可以明显看出三种花的分层)
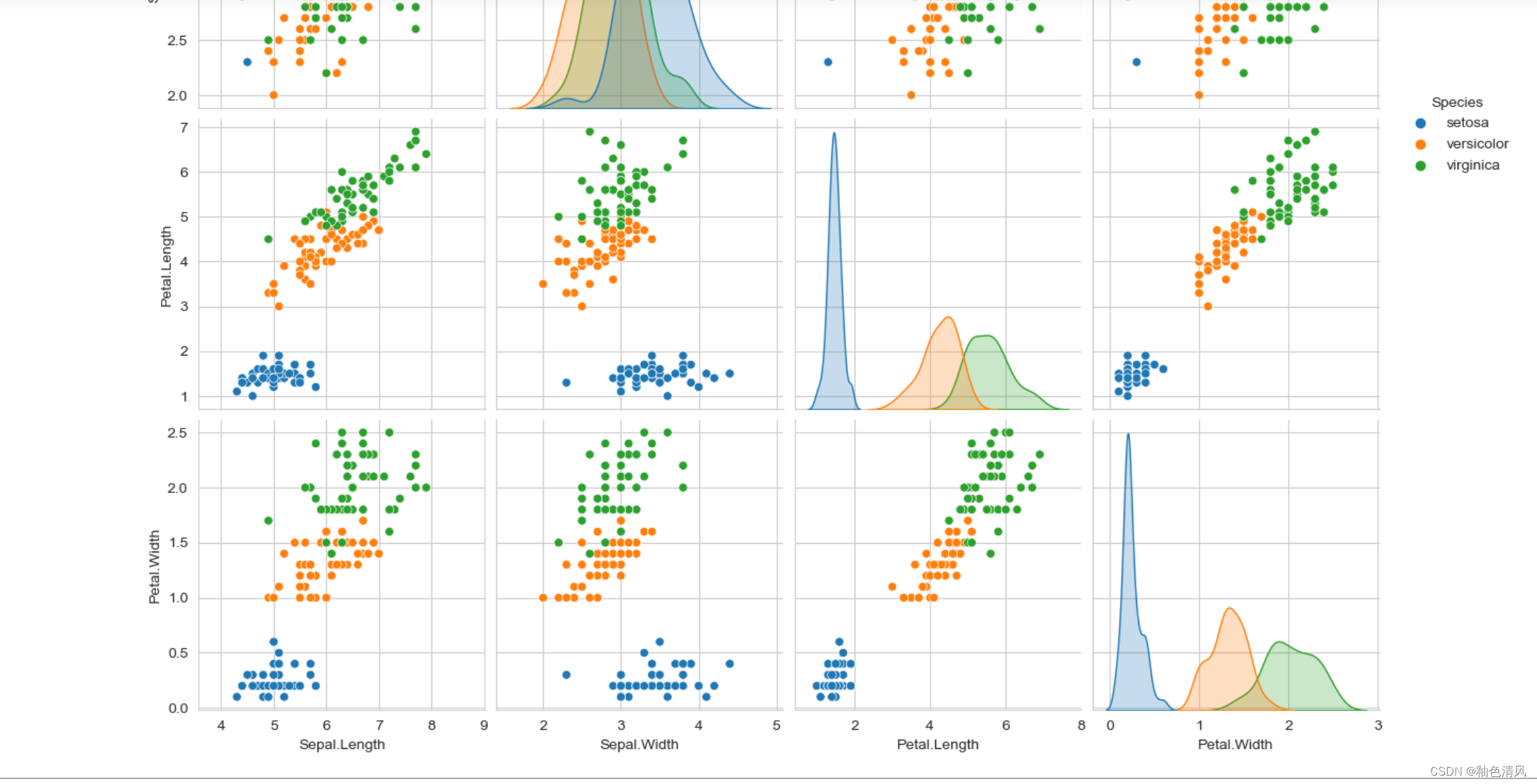
特征两两关系图
("hue":针对某一字段进行分类)因为我们主要探索的是各特征与鸢尾花种类的关系,所以我们选择鸢尾花种类这一标签列为"hue"

绘制KDE图
什么是KDE分布图呢?
KDE分布图,是指Kernel Density Estimation核概率密度估计。可以理解为是对直方图的加窗平滑。通过KDE分布图,可以查看并对训练数据集和测试数据集中特征变量的分布情况。
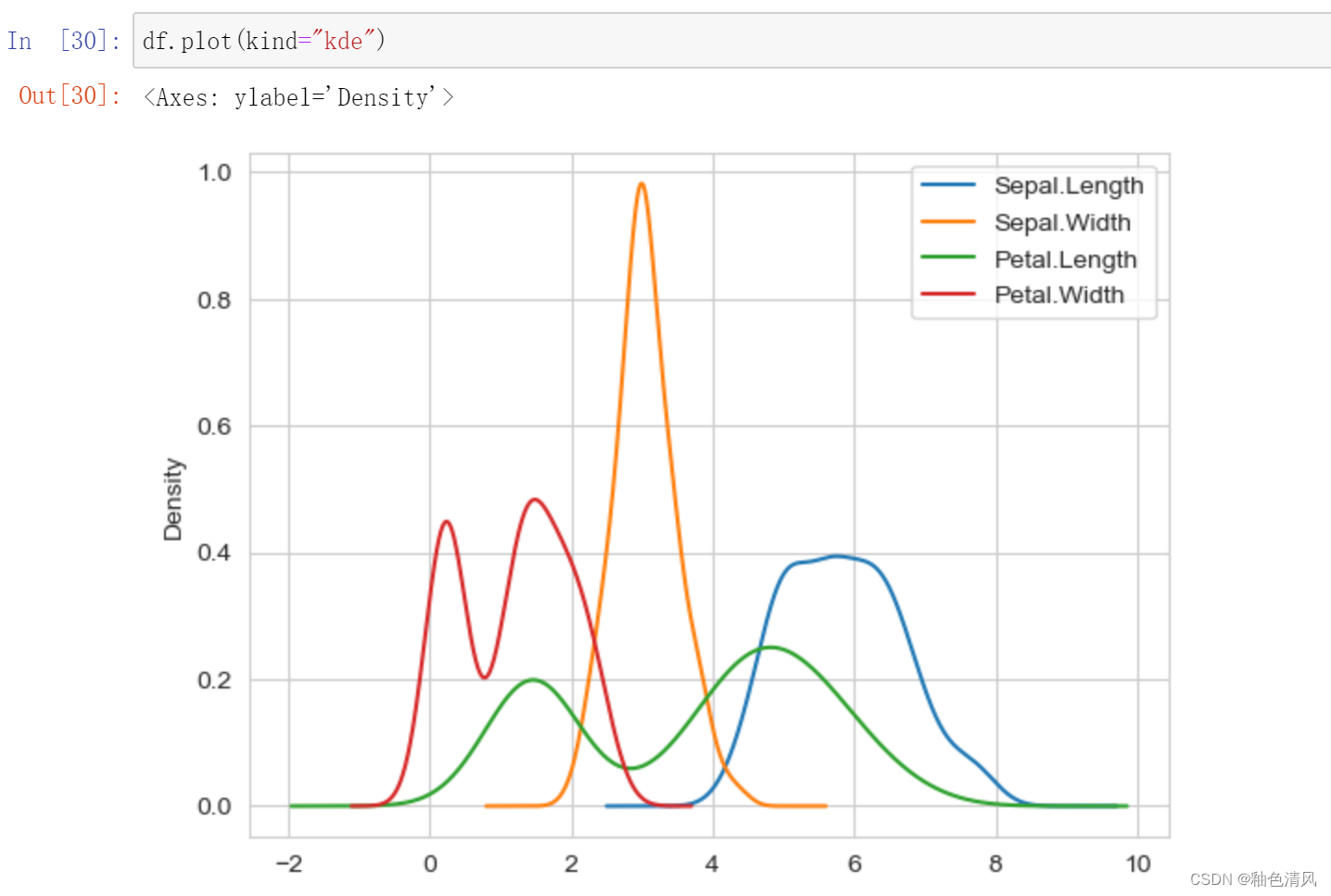
这个KDE图是单独看的四列特征列的各列的数据特征,绘制出来的。通过这个图,比如说橙色的花萼宽度,可以直观的看出它大致分布在0~5这样的一个区间且大部分位于2~4.对比直方图,核密度估计图能够更加全面的反应数据的一个分布特点。

计算特征两两之间的pearson相关系数
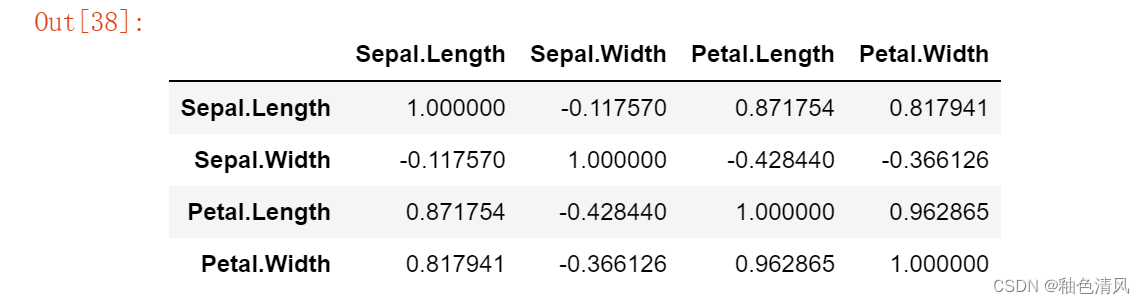
将pearson相关系数矩阵绘制热力图
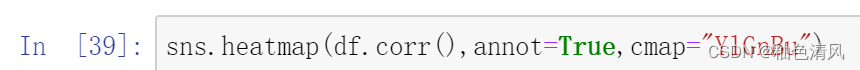
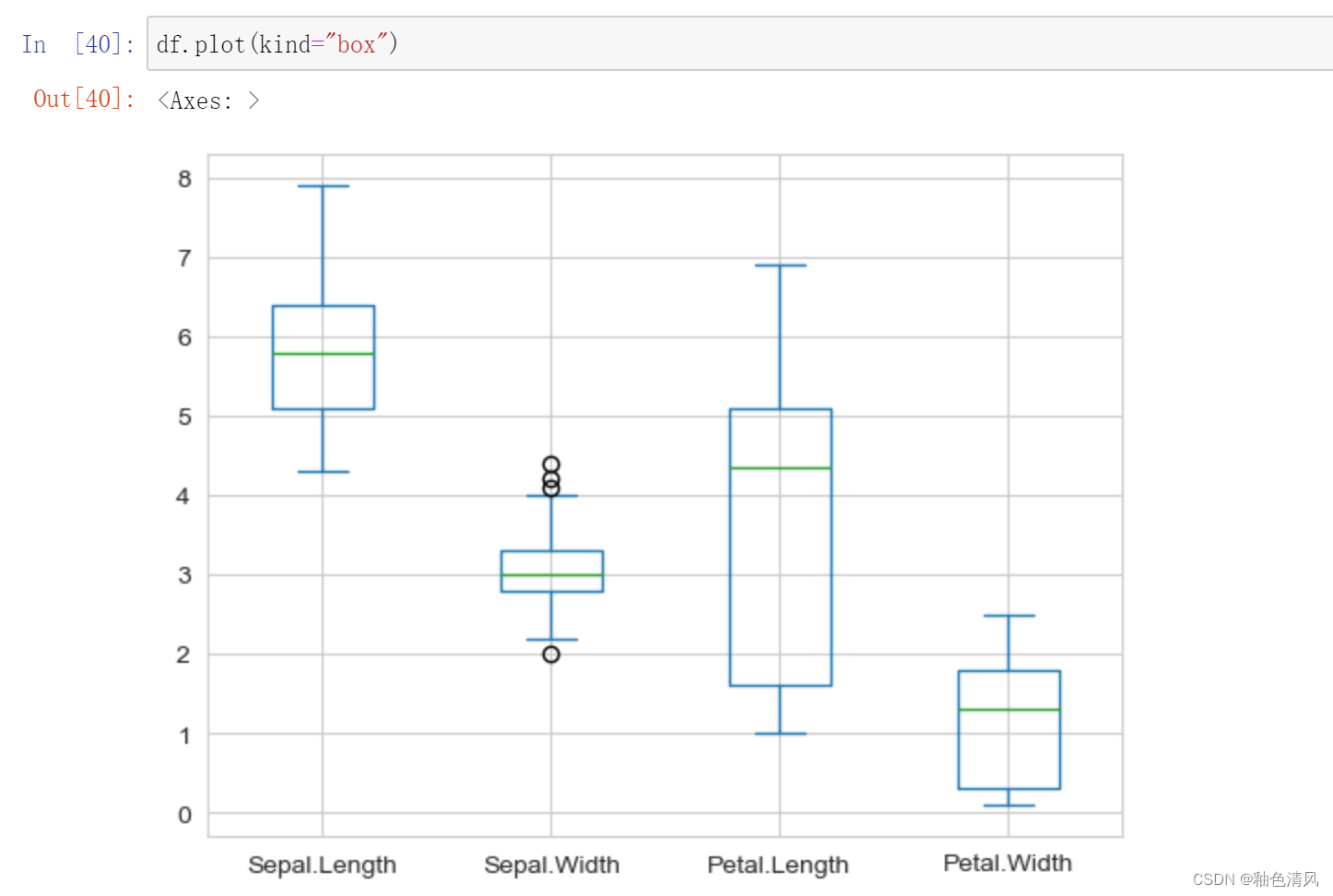
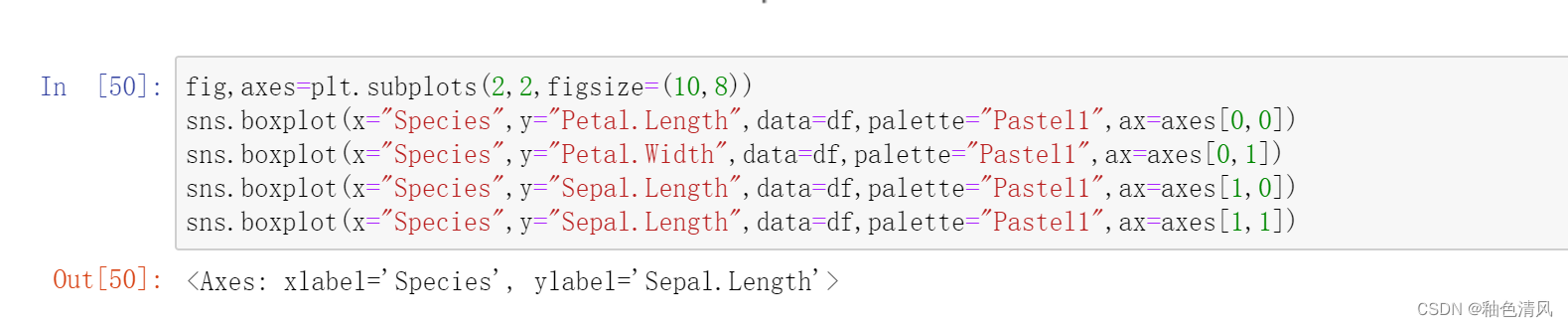
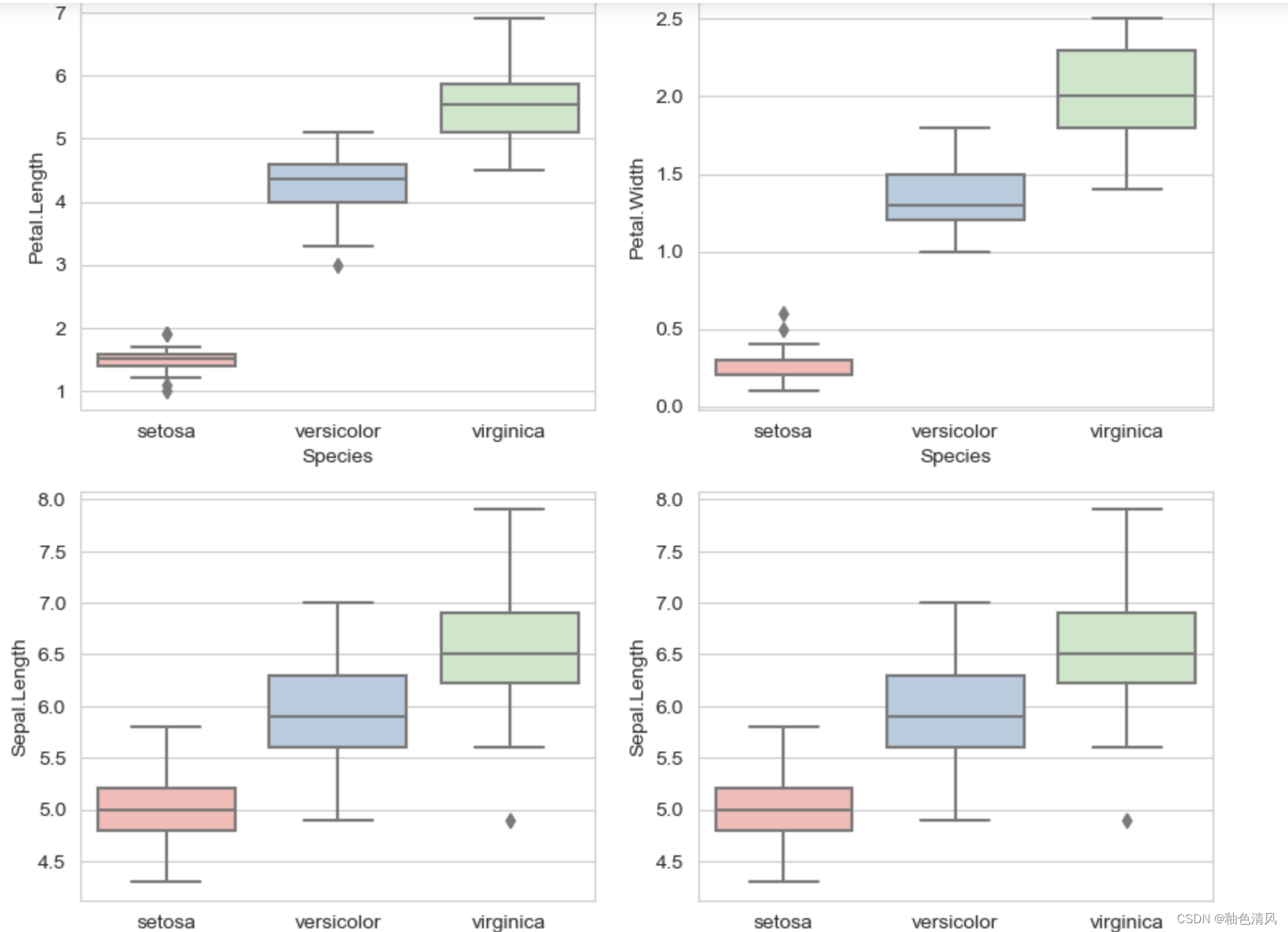
 绘制箱型图:
绘制箱型图:
三种鸢尾花的花瓣长度的箱型图:
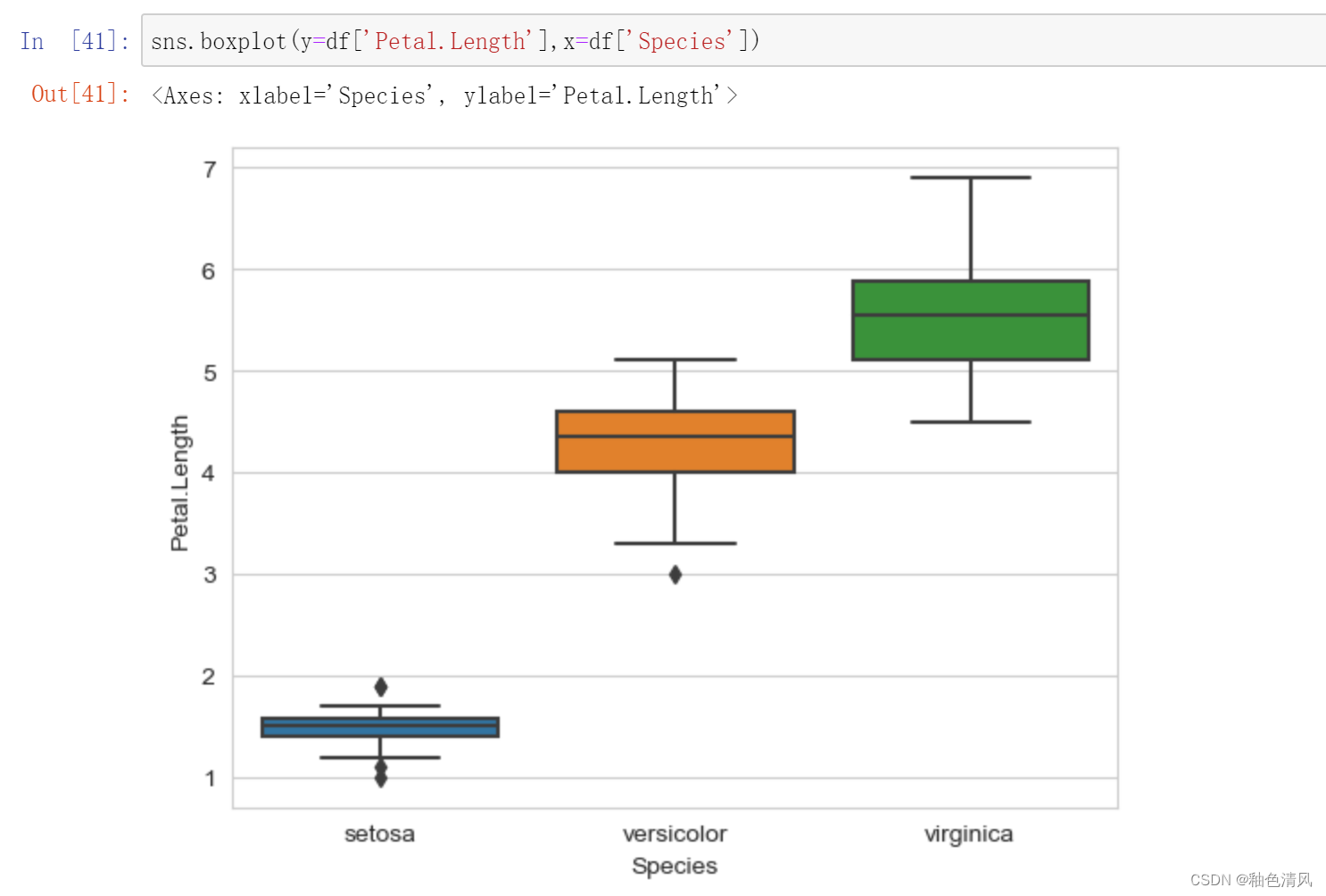
三种鸢尾花花瓣宽度箱型图: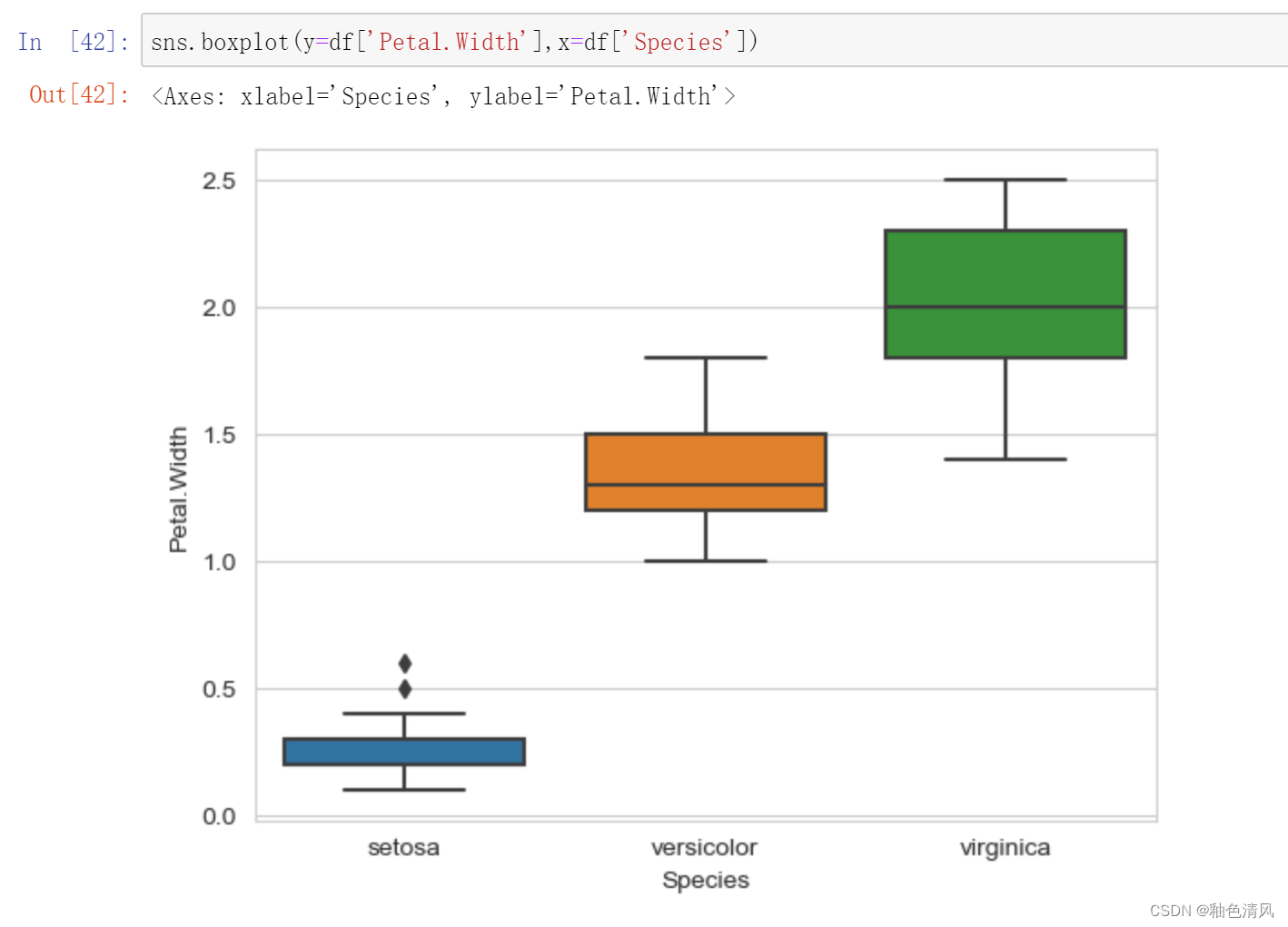
三种鸢尾花花萼长度的箱型图: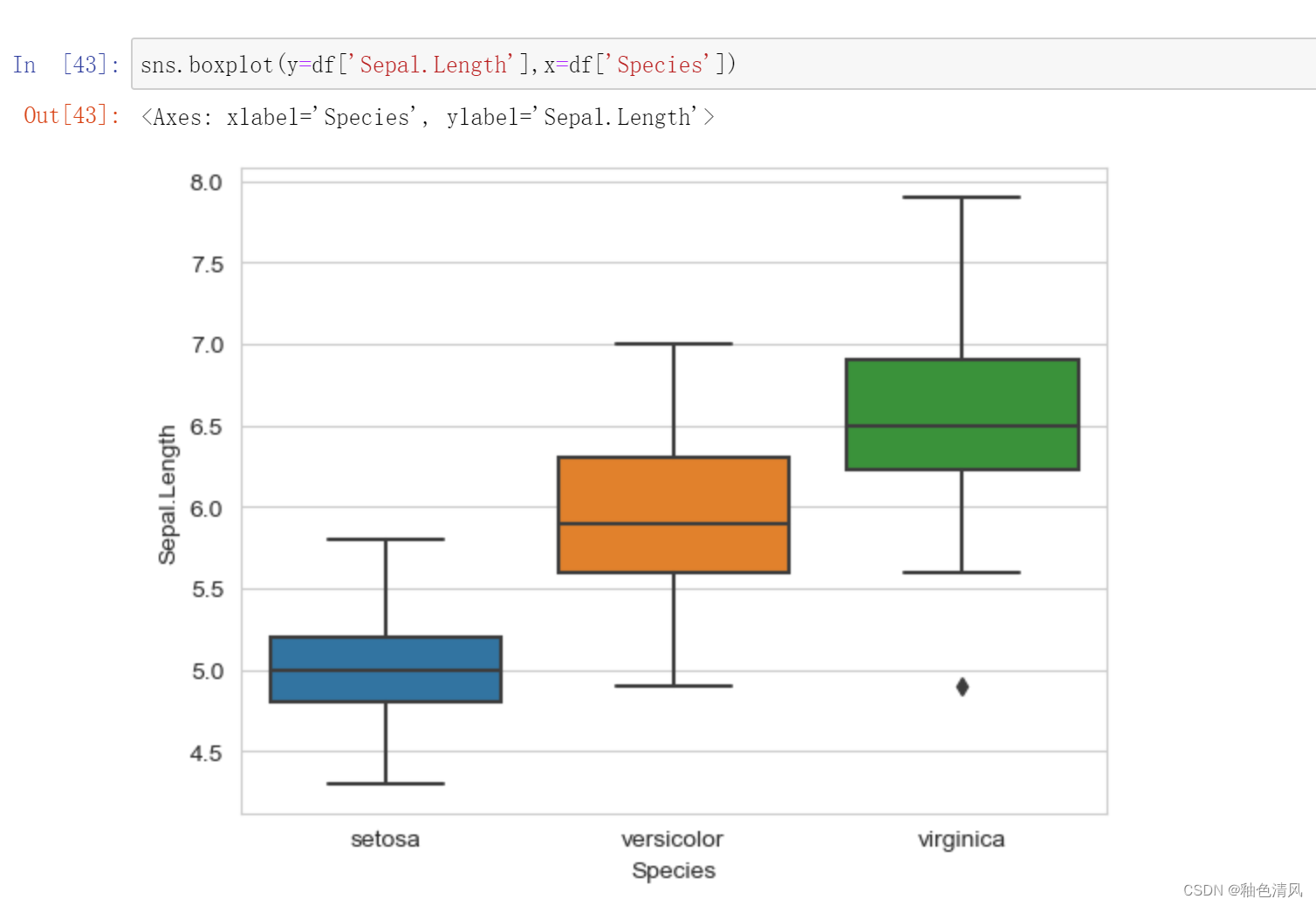
三种鸢尾花花萼宽度的箱型图:
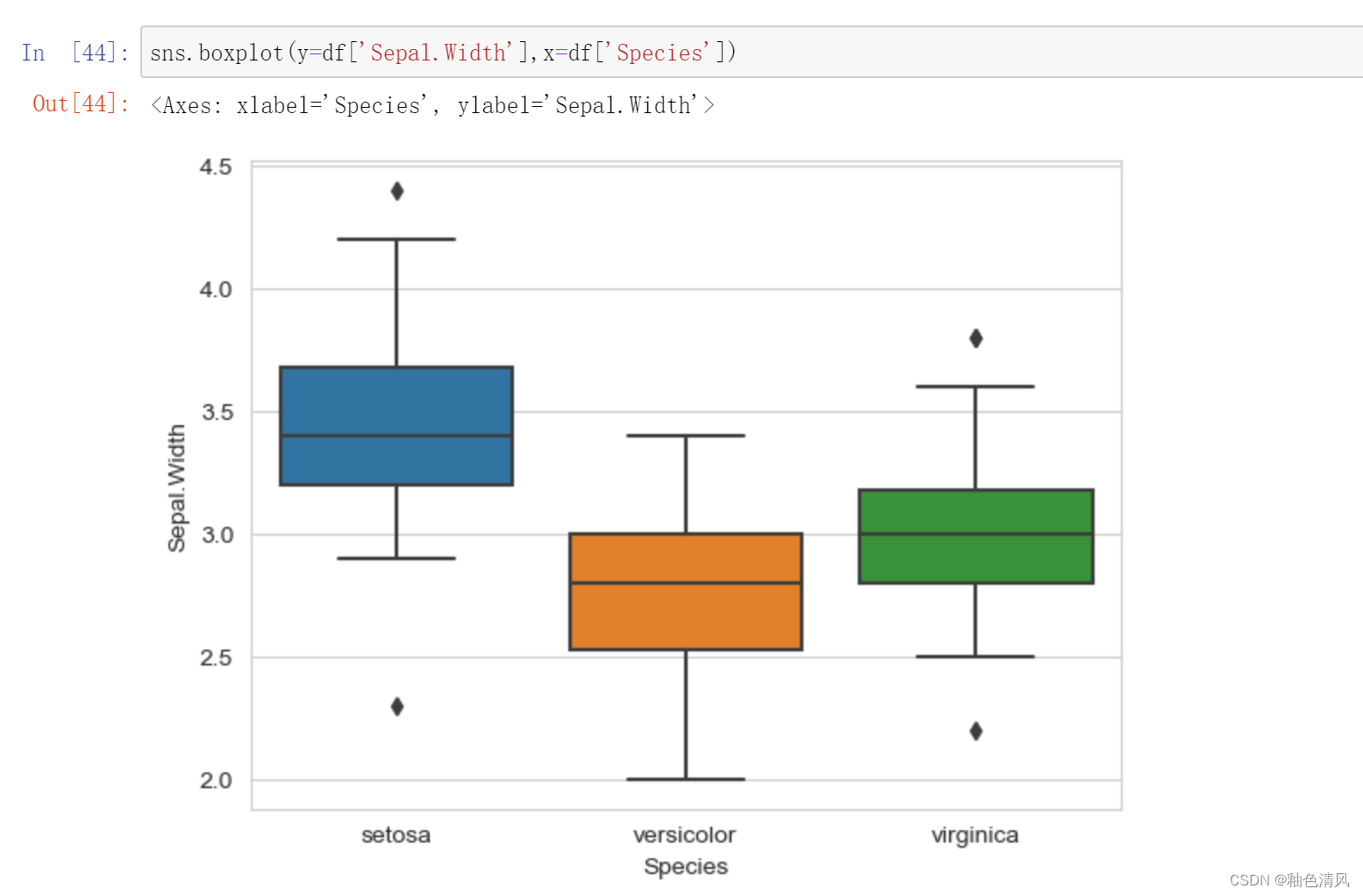
我们可以将以上四个图绘制在一张图表中:
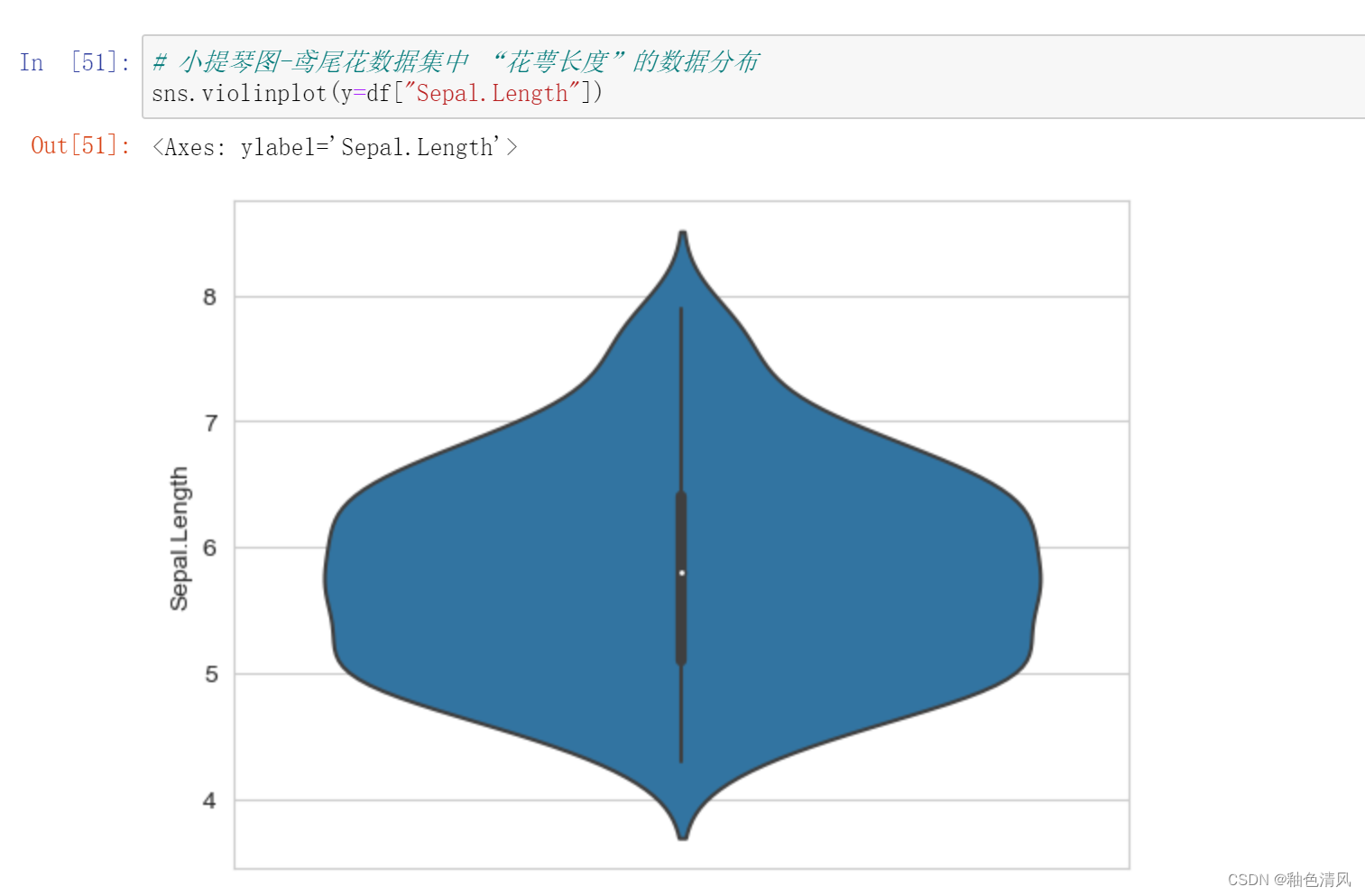
小提琴图
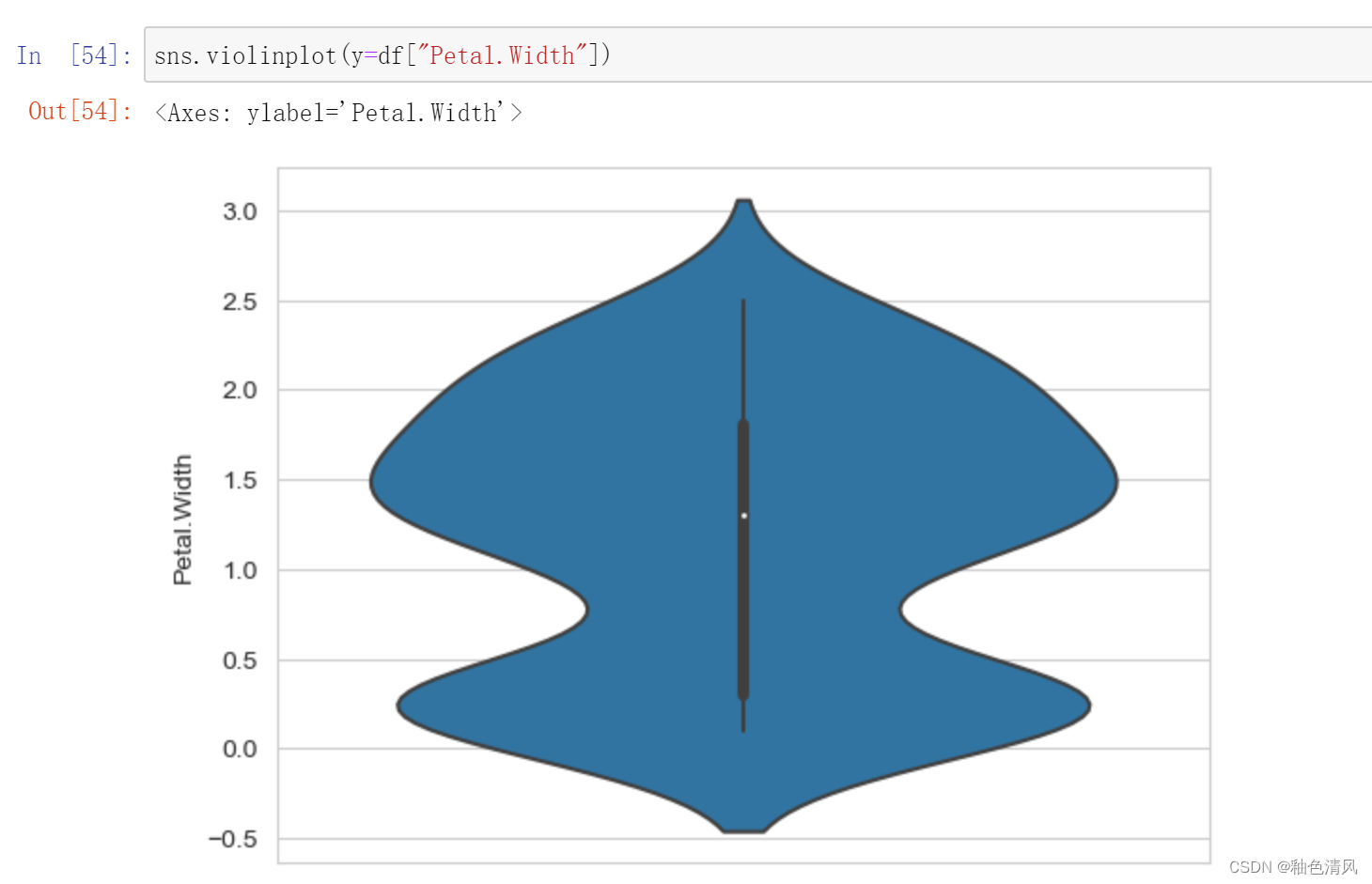
小提琴图 (Violin Plot)是用来展示多组数据的分布状态以及概率密度,是优于箱线图的一种统计图形。他结合了箱线图与密度图,箱线图位于小提琴图内部,两侧是数据的密度图,能显示出数据的多个细节。
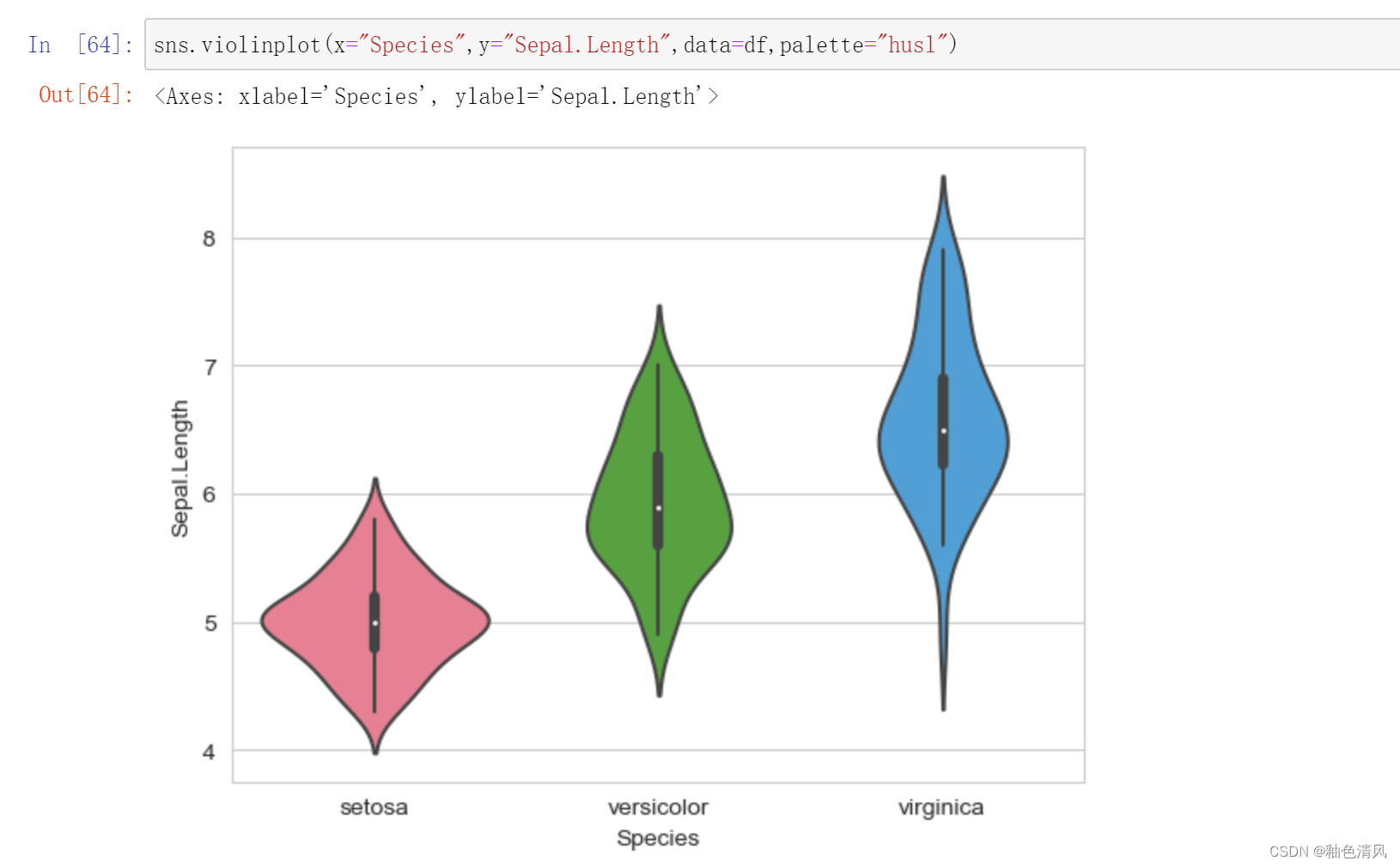
花萼长度:
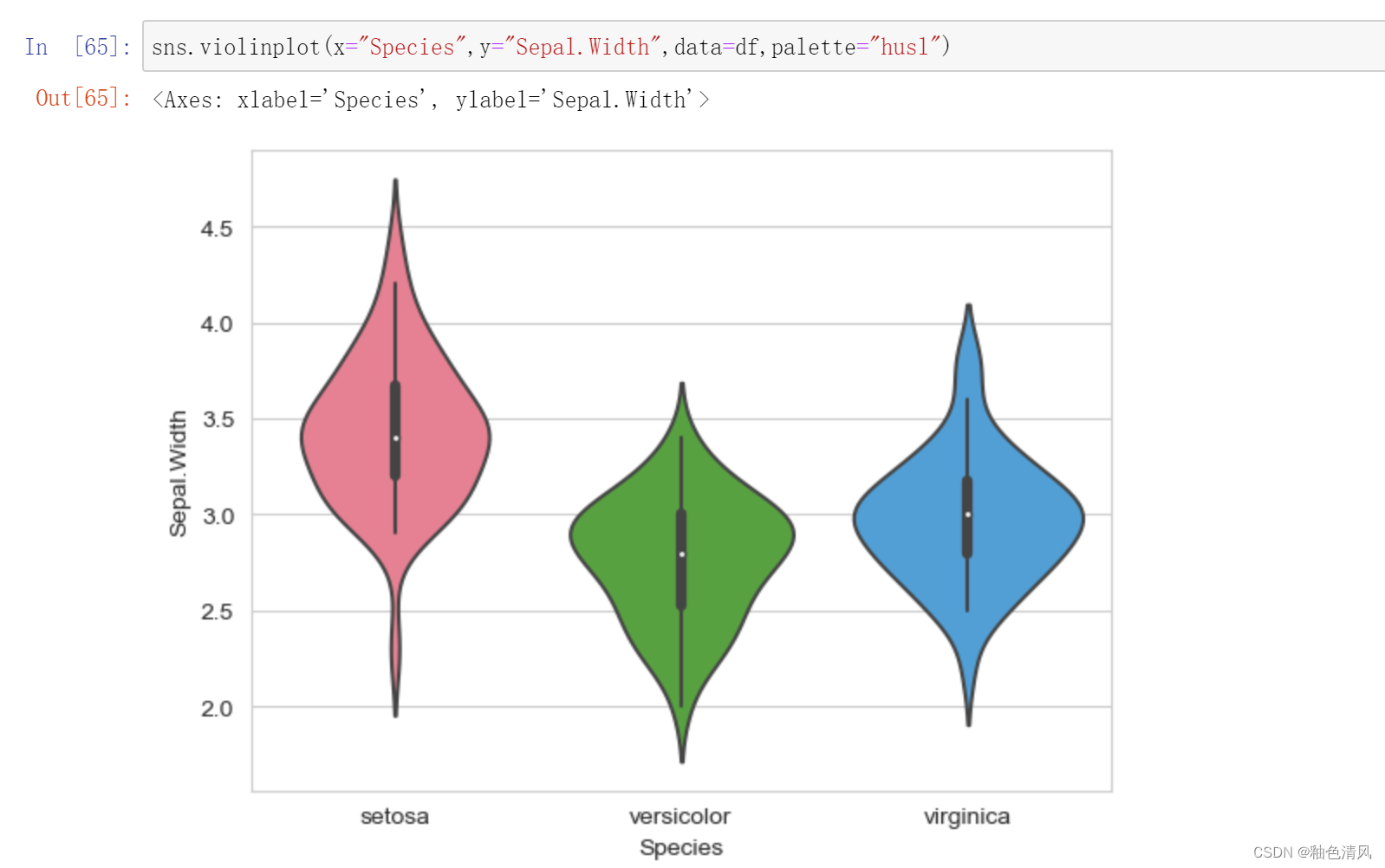
花萼宽度: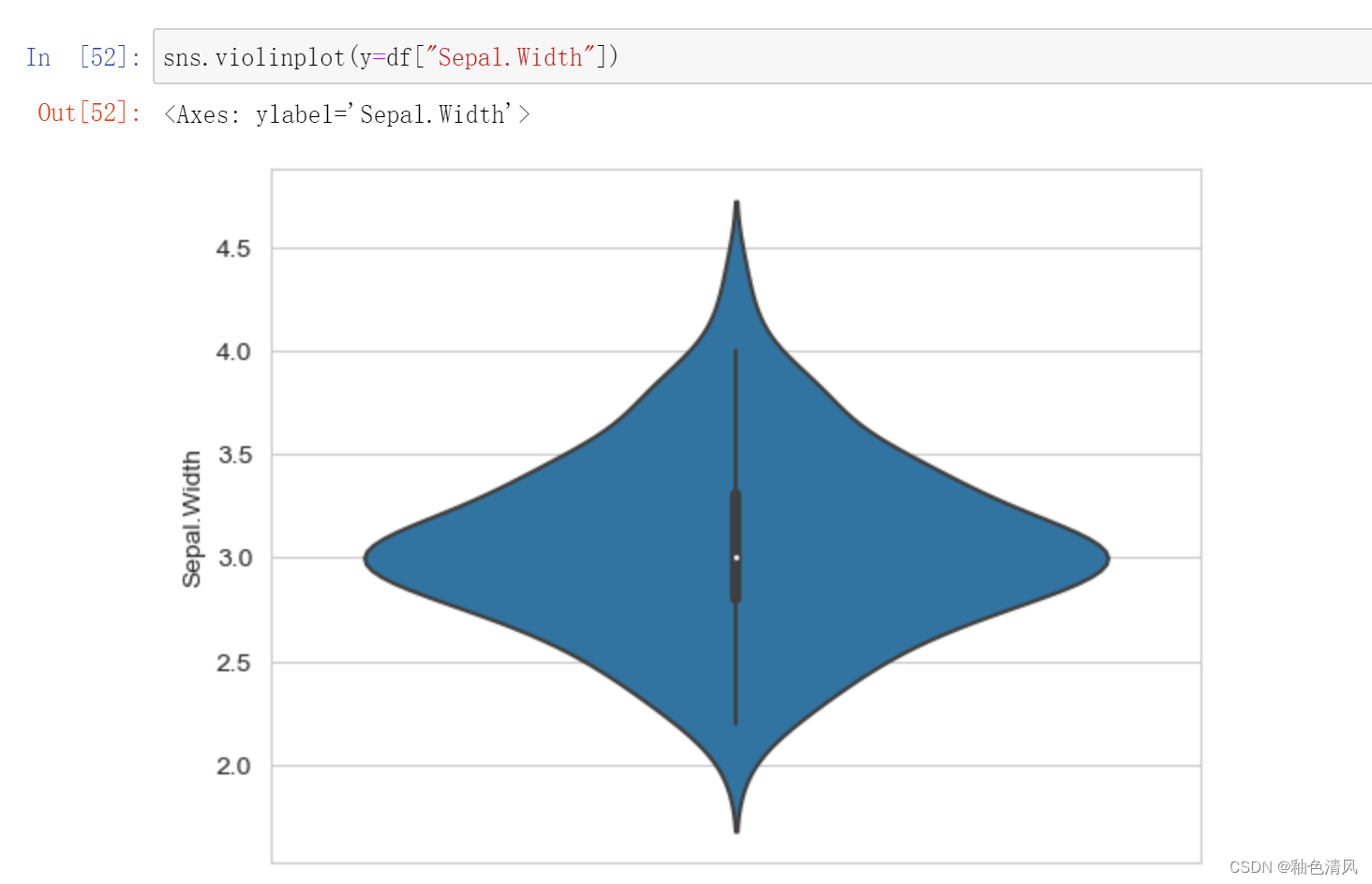
花瓣长度: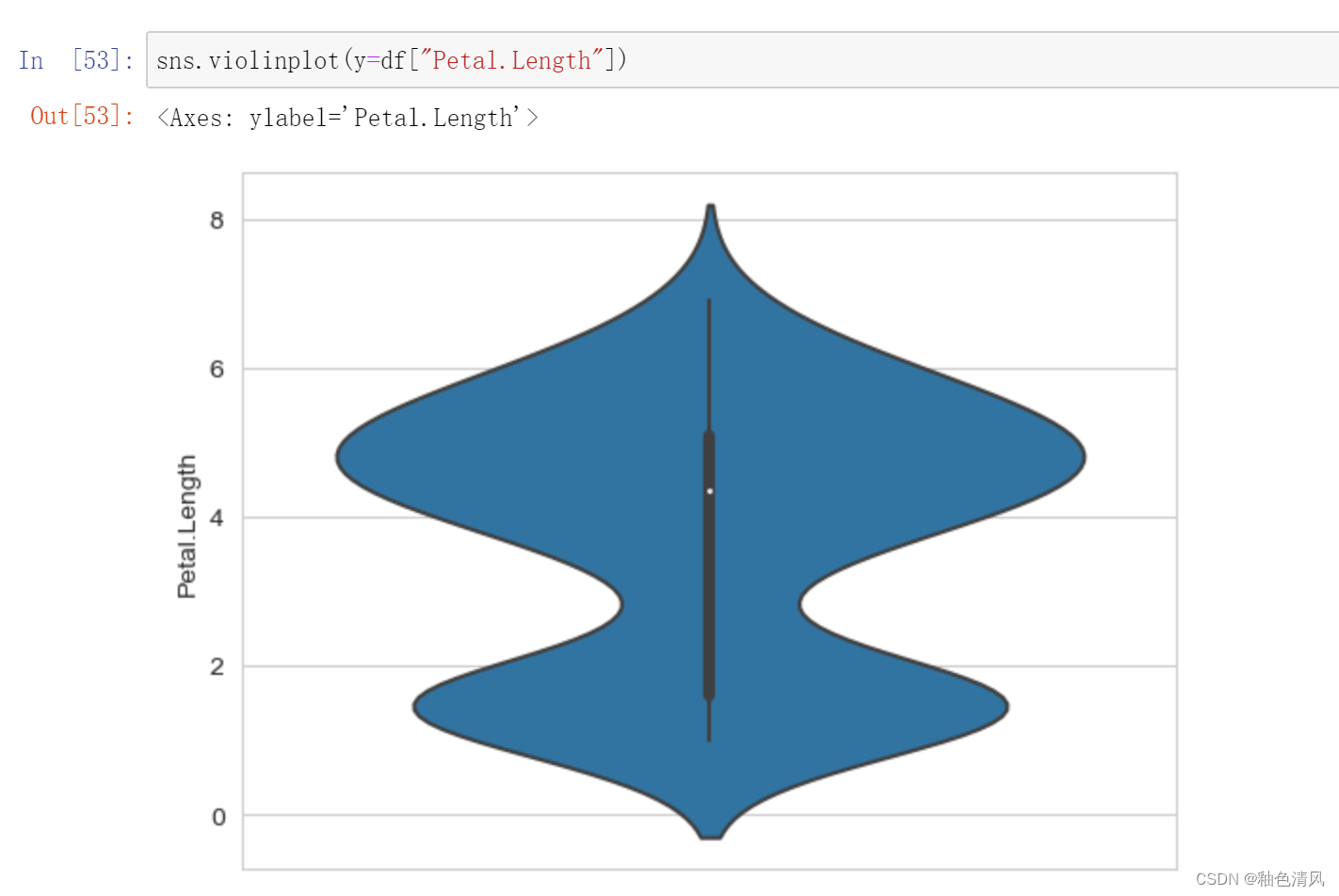
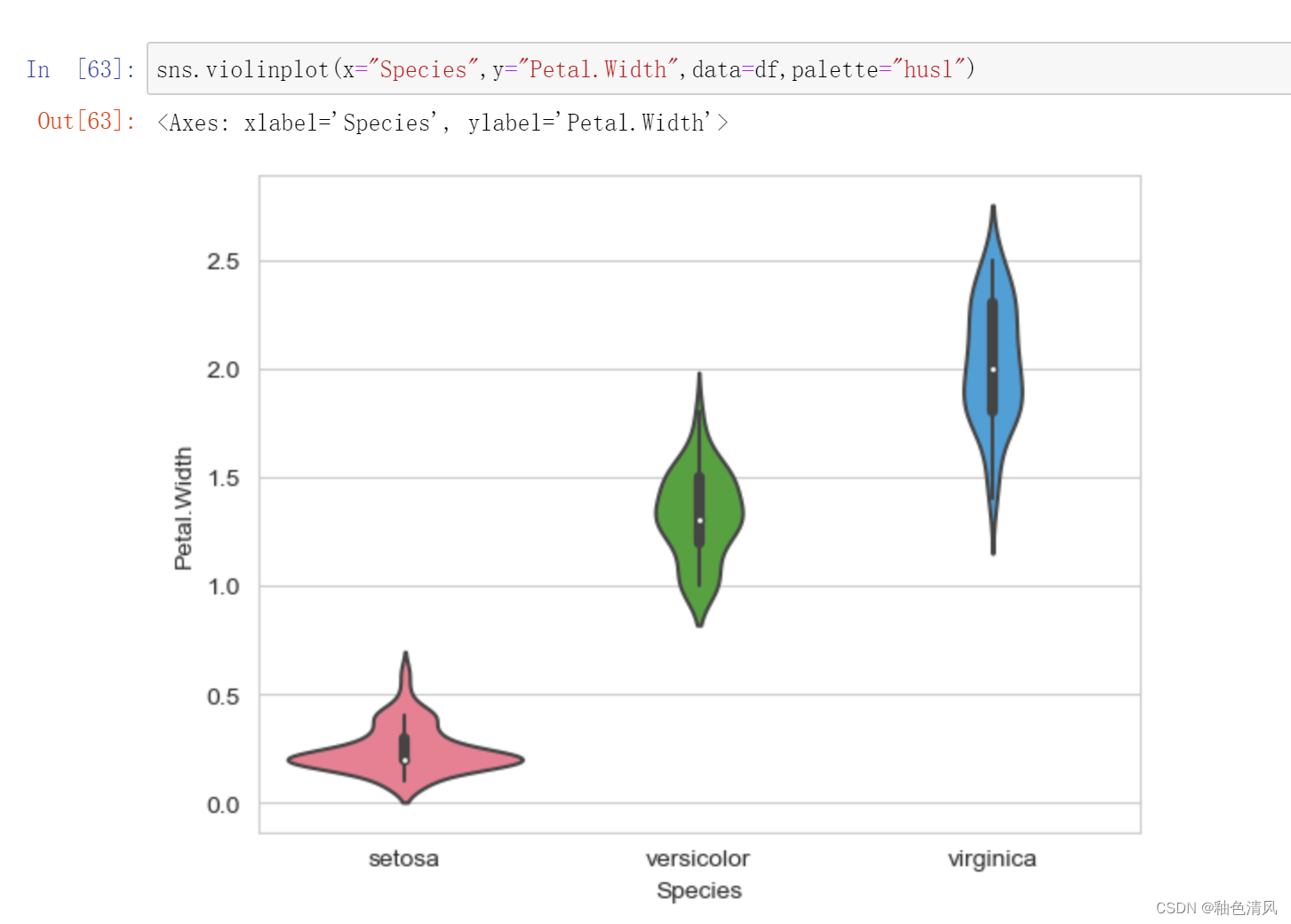
花瓣宽度:
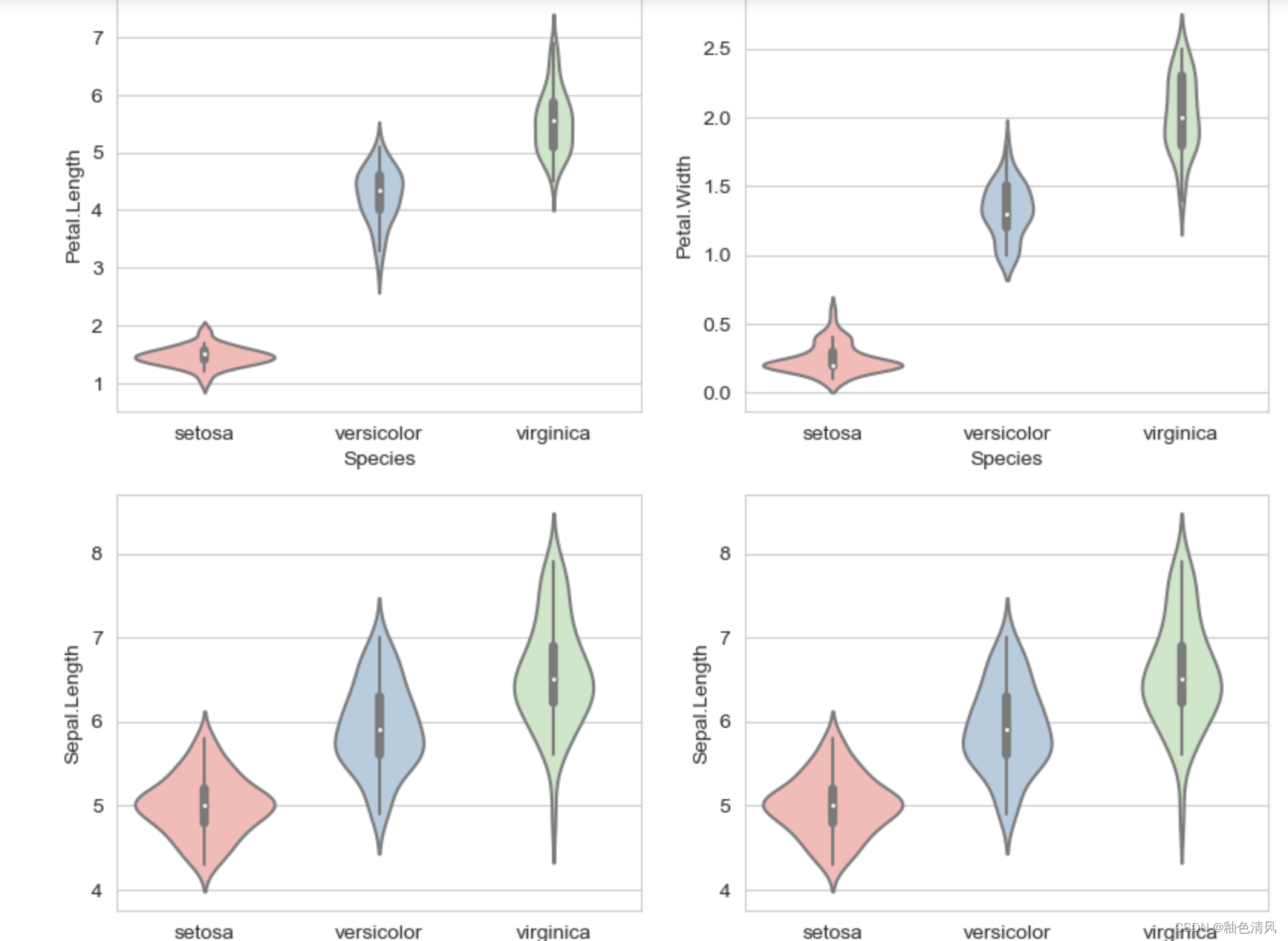
同样,我们可以将我们研究的这一类的四张图片放在一张上面:

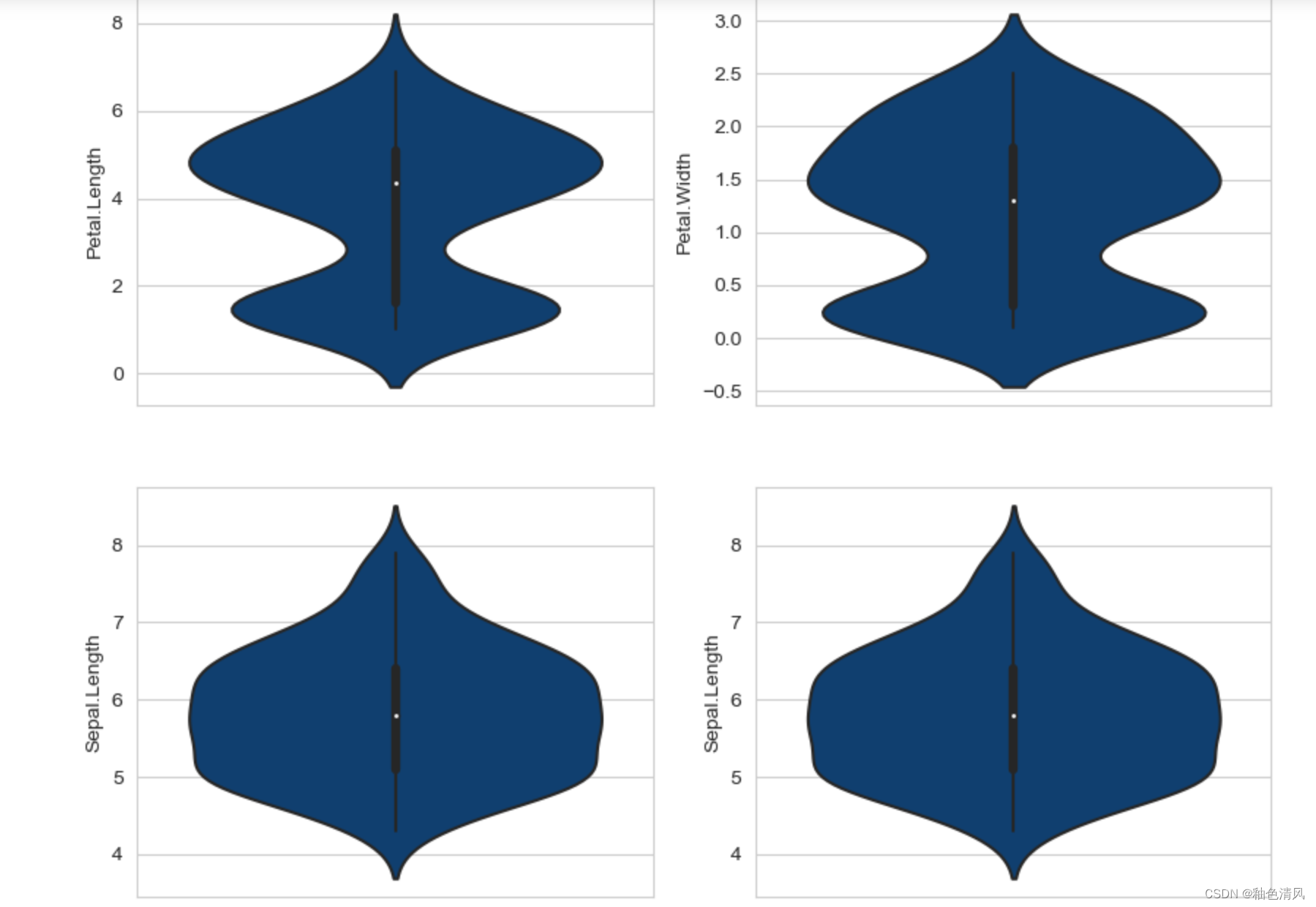
每一个小提琴图中间的黑色的线就是箱型图中间的那条线,相比箱型图,小提琴图能够更加真实全面地反应数据的连续概率密度分布。
不同鸢尾花---花萼长度、花萼宽度、花瓣长度、花瓣宽度小提琴图
不同鸢尾花--花瓣长度 小提琴图
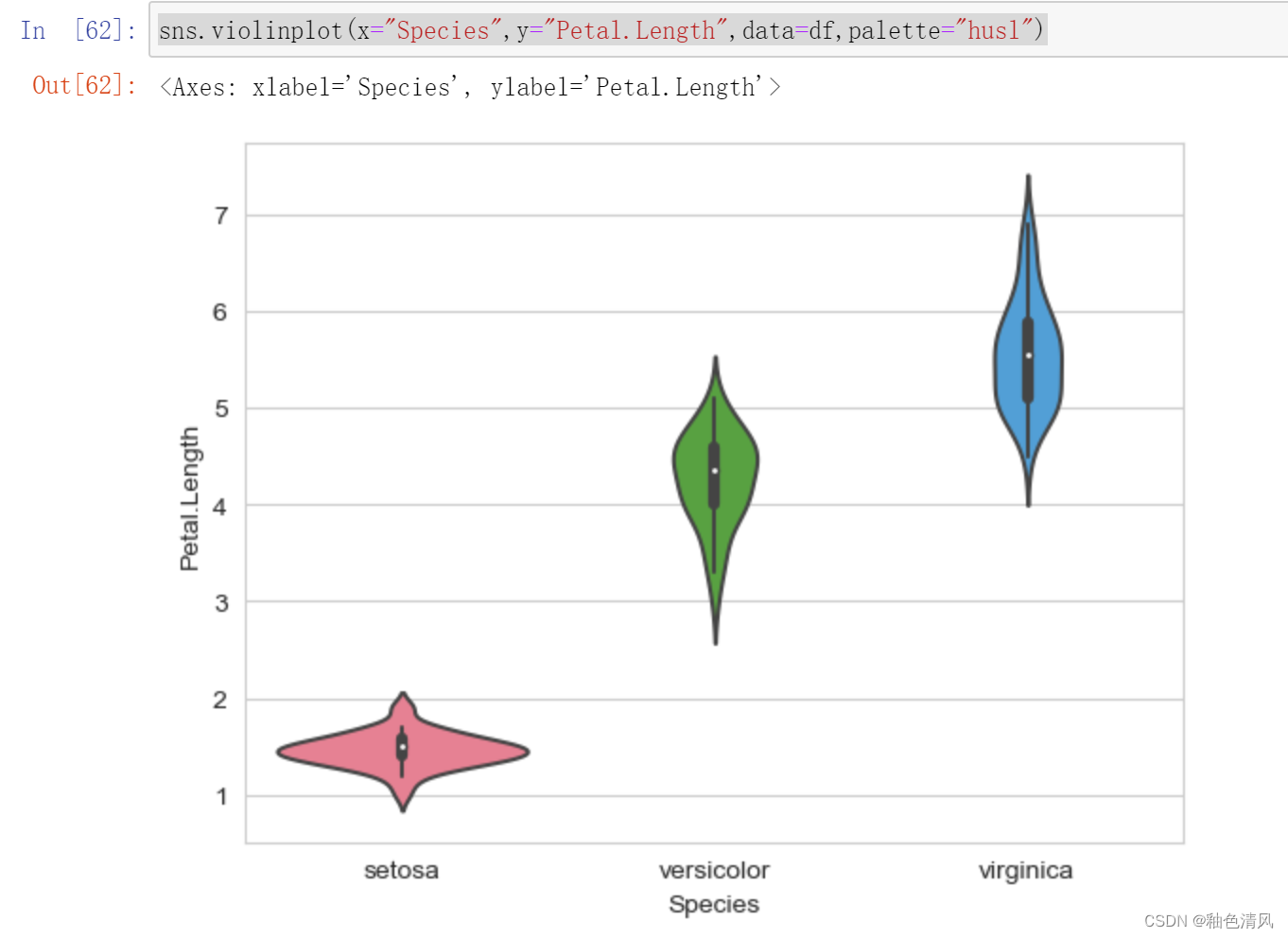
不同鸢尾花---花瓣宽度 小提琴图
不同鸢尾花---花萼长度小提琴图
不同鸢尾花 ----花萼宽度 小提琴图
当然,我们仍然可以将上面四个图放在一张图上 :(还是感觉上面的配色更好看一点)

平行坐标图
平行坐标图是可视化高维几何和分析多元数据的常用方法。看似高大上,但实际上就是简单粗暴地把不同特征的数据绘制成折线图。
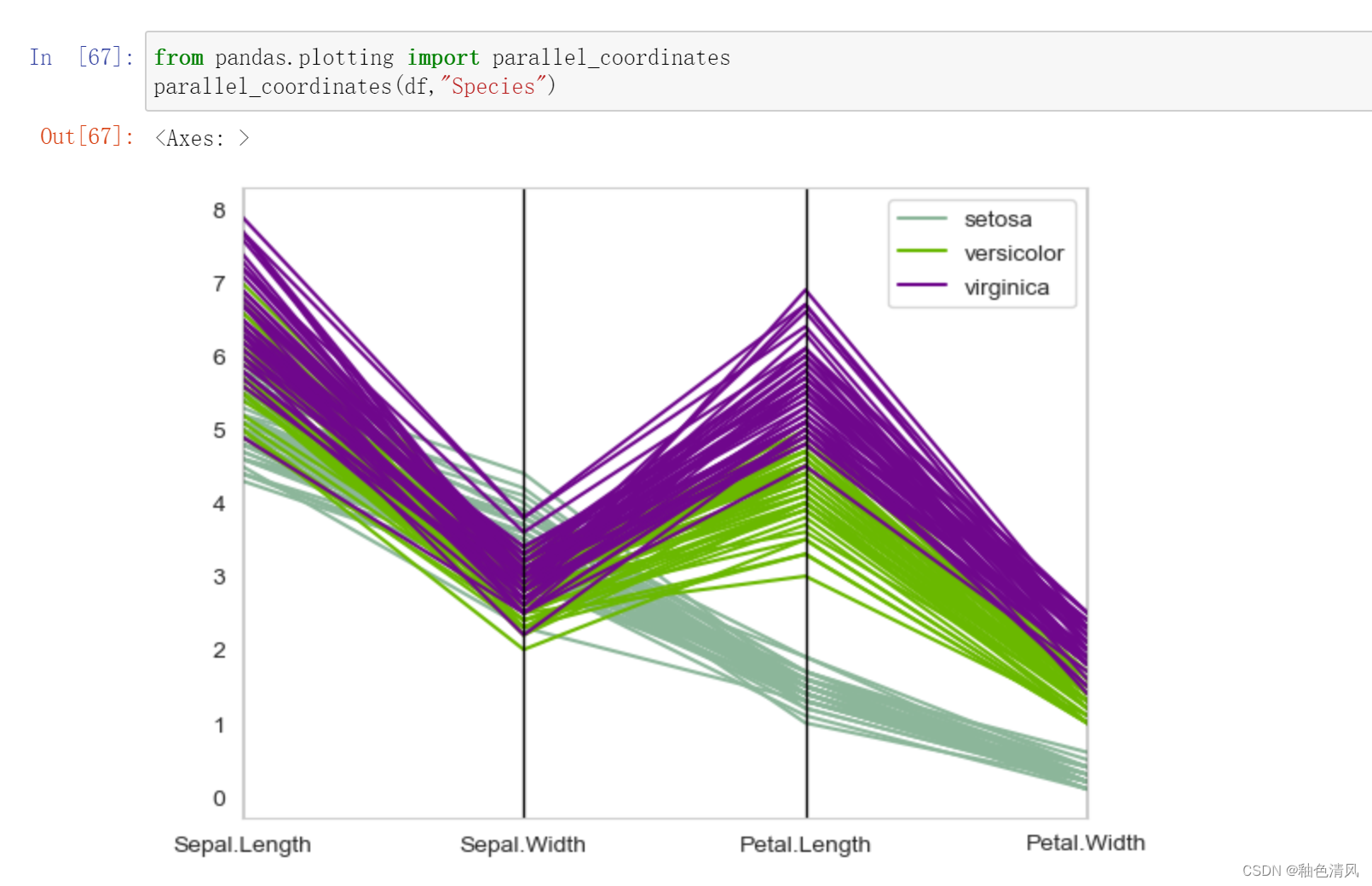
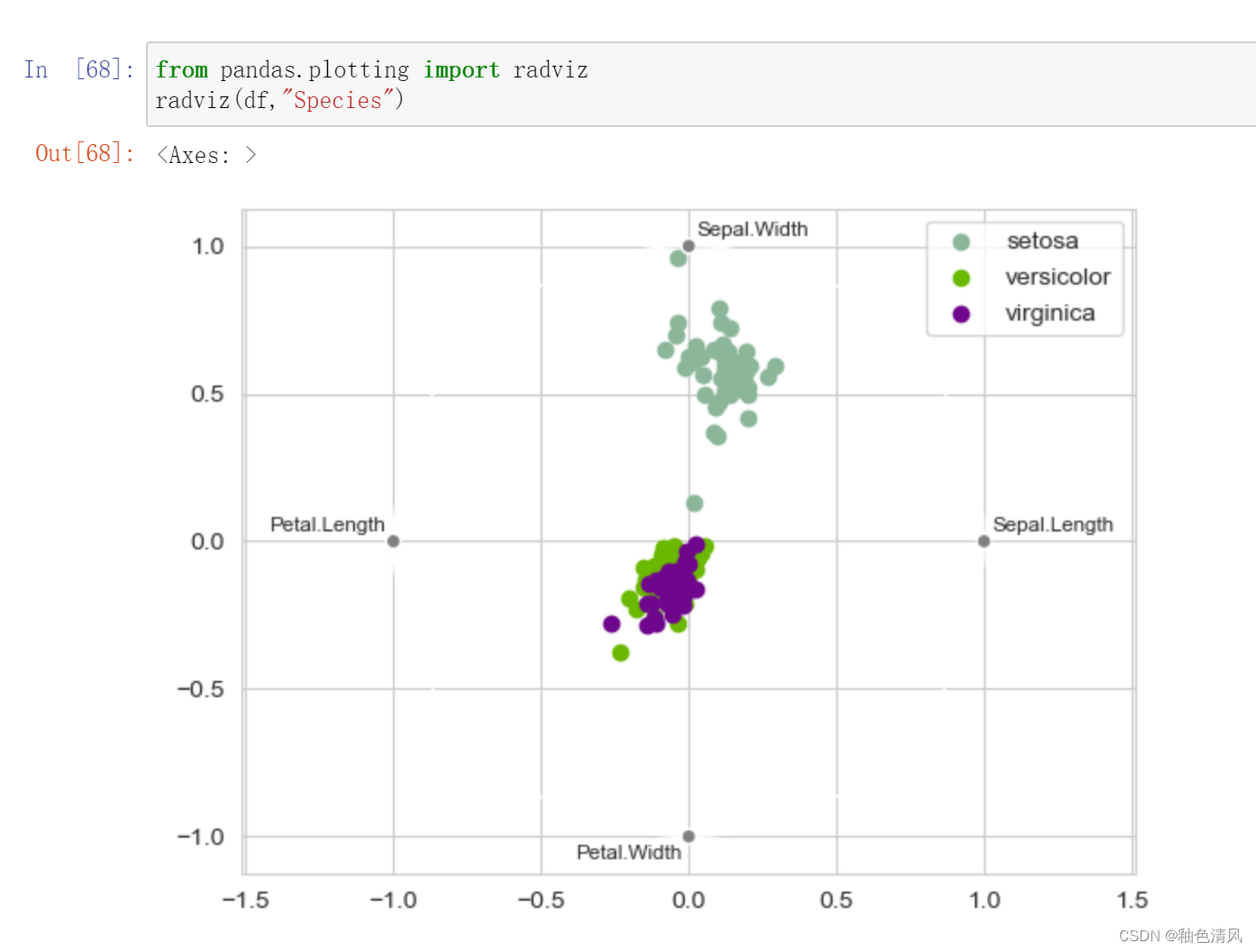
雷达图(径向坐标可视化):
RadViz雷达图(径向坐标可视化)是一种可视化多维数据的方式。
本质是将多维特征降维压缩到二维,每个数据压缩为一个点。它是基于基本的弹簧压力最小化算法。
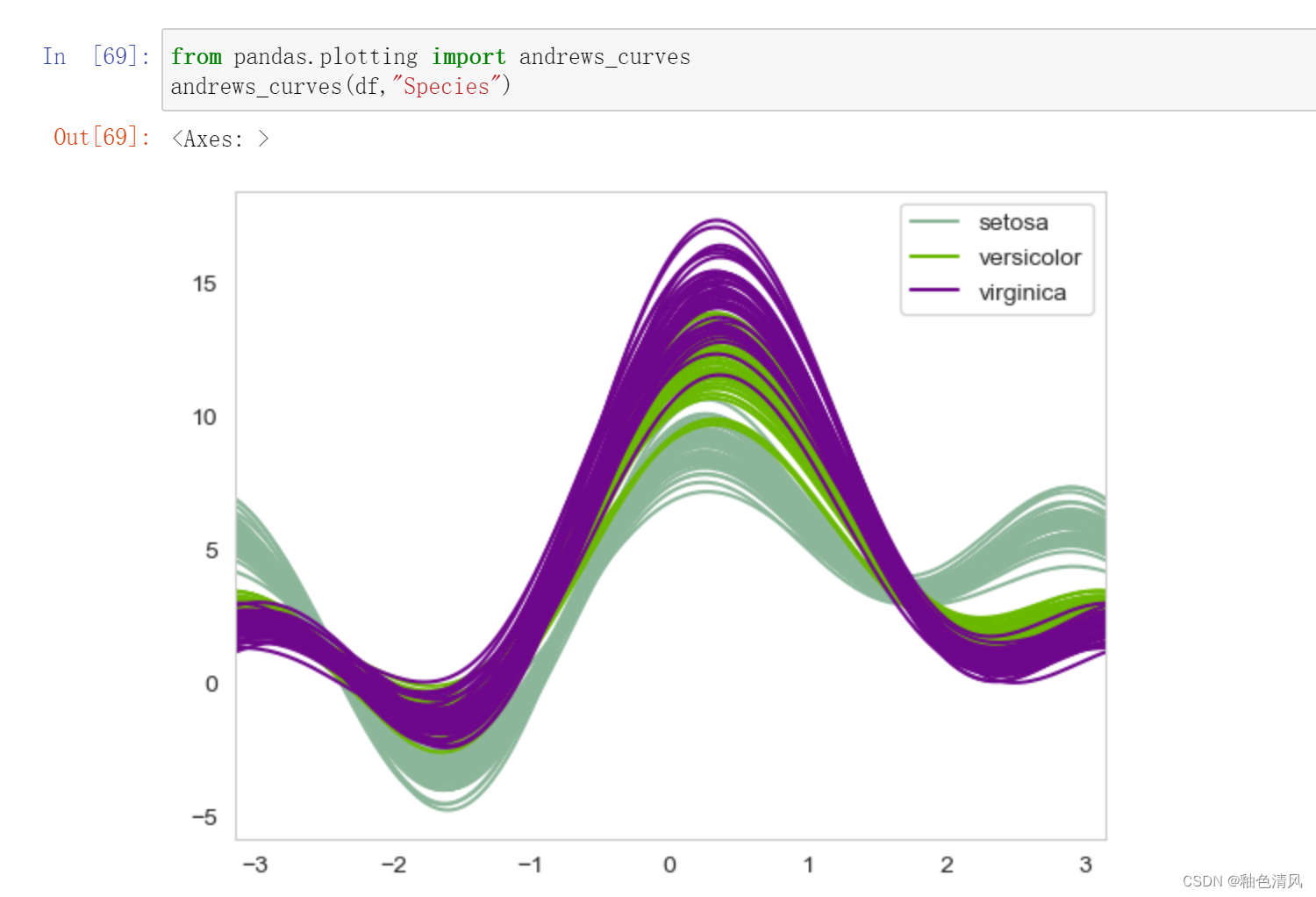
安德鲁斯曲线
安德鲁斯曲线将每个样本的属性值转化为傅里叶序列的系数来绘制曲线。
它将四维空间映射为二维的一个曲线。每一根线都表示一根鸢尾花。