
- 1Xcode真机调试不了,提示 “Please reconnect the device”_please check the device connection and ensure that
- 2C++显式调用析构函数问题一二_c++显式析构
- 3用win10主机telnet登录 win10虚拟机_telnet登录win10
- 4Linux下如何安装MySQL以及开放远程连接_linux mysql 开启远程
- 5从逆风飞扬到“攻守”平衡,Aruba谋定2023
- 6Python机器学习零基础理解K-means聚类_django viewset retrieve
- 7【前端】实现Vue组件页面跳转的多种方式_前端页面向下滑动时跳转另一个页面
- 8鸿蒙万能卡片实战系列课【李洋】(1-9)_原子化服务相对于传统应用的差异性包括?
- 9大厂技术面试中的手撕代码应该如何准备?_手撕代码不会怎么办
- 10七大排序算法(插排,希尔,选择排序,堆排,冒泡,快排,归并)--图文详解_希尔排序、冒泡排序、快速排序、归并排序思维导图
DolphinScheduler 集群模式安装部署
赞
踩
目录
2.4.4 修改 dolphinscheduler_env.sh 配置文件
一、安装部署介绍
软硬件环境建议配置:https://dolphinscheduler.apache.org/zh-cn/docs/3.1.8/about/hardware
DolphinScheduler 提供了 4 种安装部署方式:
-
单机部署(Standalone):Standalone 仅适用于 DolphinScheduler 的快速体验。如果你是新手,想要体验 DolphinScheduler 的功能,推荐使用[Standalone]方式体检。
-
伪集群部署(Pseudo-Cluster):伪集群部署目的是在单台机器部署 DolphinScheduler 服务,该模式下master、worker、api server 都在同一台机器上。如果你想体验更完整的功能,或者更大的任务量,推荐使用伪集群部署。
-
集群部署(Cluster):集群部署目的是在多台机器部署 DolphinScheduler 服务,用于运行大量任务情况。如果你是在生产中使用,推荐使用集群部署或者 kubernetes。
-
Kubernetes 部署:Kubernetes 部署目的是在 Kubernetes 集群中部署 DolphinScheduler 服务,能调度大量任务,可用于在生产中部署。
注意:
- Standalone 仅建议 20 个以下工作流使用,因为其采用内存式的 H2 Database, Zookeeper Testing Server,任务过多可能导致不稳定,并且如果重启或者停止standalone-server 会导致内存中数据库里的数据清空。 如果您要连接外部数据库,比如 mysql 或者 postgresql。
- Kubernetes 部署先决条件:Helm3.1.0+ ;Kubernetes1.12+;PV 供应(需要基础设施支持)。
本次是集群部署 DolphinScheduler 3.1.8
二、集群部署
参考官方文档: https://dolphinscheduler.apache.org/zh-cn/docs/3.1.8/guide/installation/pseudo-cluster
2.1 集群部署规划
集群模式下,可配置多个 Master 及多个 Worker。通常可配置 2~3 个 Master,若干个 Worker。由于集群资源有限,此处配置 2 个 Master,3 个 Worker,集群规划如下。
| 主机名 | ip | 服务 | 备注 |
|---|---|---|---|
| hadoop01 | 192.168.170.136 | master、worker | JDK、MySQL、zookeeper |
| hadoop02 | 192.168.170.137 | master、worker | JDK、zookeeper |
| hadoop03 | 192.168.170.138 | worker | JDK、zookeeper |
2.2 前置准备工作
集群部署 DolphinScheduler 需要有外部软件的支持:
-
操作系统:Linux Centos 7.9
-
部署版本:apache-dolphinscheduler-3.1.8-bin
- JDK:下载 JDK (1.8+),安装并配置
JAVA_HOME环境变量,并将其下的bin目录追加到PATH环境变量中。如果你的环境中已存在,可以跳过这步。(JDK 安装教程:Linux 部署 JDK+MySQL+Tomcat 详细过程_linux系统部署mysql+tomcat-CSDN博客) - 二进制包:在下载页面下载 DolphinScheduler 二进制包。(下载 DolphinScheduler 3.1.8 连接地址:https://archive.apache.org/dist/dolphinscheduler/3.1.8/apache-dolphinscheduler-3.1.8-bin.tar.gz)
- 数据库:PostgreSQL (8.2.15+) 或者 MySQL (5.7+),两者任选其一即可,如 MySQL 则需要 JDBC Driver 8.0.16。(MySQL 8 数据库安装教程:CentOS 7 安装&卸载 MySQL 8 详细图文教程_centos7卸载mysql8-CSDN博客)
- 注册中心:ZooKeeper (3.4.6+)。(zookeeper 安装教程:【Zookeeper 初级】02、Zookeeper 集群部署-CSDN博客)
注意: DolphinScheduler 本身不依赖 Hadoop、Hive、Spark,但如果你运行的任务需要依赖他们,就需要有对应的环境支持。
2.3 准备 DolphinScheduler 启动环境
2.3.1 配置用户免密及权限(各个节点)
创建部署用户,并且一定要配置 sudo 免密。以创建 dolphinscheduler 用户为例:
- # 创建用户需使用 root 登录
- useradd dolphinscheduler
-
- # 添加密码
- echo "dolphinscheduler" | passwd --stdin dolphinscheduler
-
- # 配置 sudo 免密
- sed -i '$adolphinscheduler ALL=(ALL) NOPASSWD: NOPASSWD: ALL' /etc/sudoers
- sed -i 's/Defaults requirett/#Defaults requirett/g' /etc/sudoers
-
- # 修改目录权限,使得部署用户对二进制包解压后的 dolphinscheduler 目录有操作权限
- chown -R dolphinscheduler:dolphinscheduler /bigdata/dolphinscheduler
注意:
- 因为任务执行服务是以
sudo -u {linux-user}切换不同 linux 用户的方式来实现多租户运行作业,所以部署用户需要有 sudo 权限,而且是免密的。初学习者不理解的话,完全可以暂时忽略这一点。- 如果发现
/etc/sudoers文件中有 "Defaults requirett" 这行,也请注释掉。
2.3.2 配置机器SSH免密登陆
由于安装的时候需要向不同机器发送资源,所以要求各台机器间能实现SSH免密登陆。配置免密登陆的步骤如下:
- [root@hadoop01 /bigdata]# su dolphinscheduler
- [dolphinscheduler@hadoop01 /root]$ ssh-keygen
- [dolphinscheduler@hadoop01 /root]$ ssh-copy-id hadoop01
- [dolphinscheduler@hadoop01 /root]$ ssh-copy-id hadoop02
- [dolphinscheduler@hadoop01 /root]$ ssh-copy-id hadoop03
注意: 配置完成后,可以通过运行命令
ssh localhost判断是否成功,如果不需要输入密码就能 ssh 登陆则证明成功
2.3.3 启动 zookeeper 集群
进入 zookeeper 的安装目录,将 zoo_sample.cfg 配置文件复制到 conf/zoo.cfg,并将 conf/zoo.cfg 中 dataDir 中的值改成 dataDir=./tmp/zookeeper
- # 启动 zookeeper
- ./bin/zkServer.sh start
2.4 初始化数据库
DolphinScheduler 元数据存储在关系型数据库中,目前支持 PostgreSQL 和 MySQL。下面分别介绍如何使用 MySQL 初始化数据库。
2.4.1 创建数据库、用户和授权
- -- 进入 MySQL 命令行
- [root@hadoop01 ~]# mysql -u root -pqwe123456
-
- -- 创建 dolphinscheduler 的元数据库,并指定编码
- mysql> CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
-
- -- 创建 dolphinscheduler 的数据库用户和密码,并限定登陆范围
- mysql> CREATE USER 'dolphinscheduler'@'%' IDENTIFIED BY 'Qwe123456.';
-
- -- 为 dolphinscheduler 数据库授权
- mysql> grant all privileges on dolphinscheduler.* to 'dolphinscheduler'@'%' ;
-
- -- 刷新权限
- mysql> flush privileges;
2.4.2 解压安装包
上传 DolphinScheduler 安装包到 hadoop01节点,并解压安装包到该目录。
-
- [root@hadoop01 ~]# tar -zxvf apache-dolphinscheduler-3.1.8-bin.tar.gz -C /bigdata/
- [root@hadoop01 ~]# mv /bigdata/apache-dolphinscheduler-3.1.8-bin /bigdata/dolphinscheduler
2.4.3 添加 MySQL 驱动
需要手动下载 mysql-connector-java 驱动 (8.0.16) 并移动到 DolphinScheduler 的每个模块的 libs 目录下,其中包括 api-server/libs 和 alert-server/libs 和 master-server/libs 和 worker-server/libs。
- # 复制 mysql 的驱动到对应 libs 目录中
- [root@hadoop01 ~]# cp mysql-connector-java-8.0.16.jar /bigdata/dolphinscheduler/alert-server/libs/
- [root@hadoop01 ~]# cp mysql-connector-java-8.0.16.jar /bigdata/dolphinscheduler/master-server/libs/
- [root@hadoop01 ~]# cp mysql-connector-java-8.0.16.jar /bigdata/dolphinscheduler/worker-server/libs/
- [root@hadoop01 ~]# cp mysql-connector-java-8.0.16.jar /bigdata/dolphinscheduler/api-server/libs/
- [root@hadoop01 ~]# cp mysql-connector-java-8.0.16.jar /bigdata/dolphinscheduler/tools/libs/
2.4.4 修改 dolphinscheduler_env.sh 配置文件
文件 ./bin/env/dolphinscheduler_env.sh 描述了下列配置:
-
DolphinScheduler 的数据库配置,将 username 和 password 改成你在上一步中设置的用户名和密码
-
一些任务类型外部依赖路径或库文件,如
JAVA_HOME和SPARK_HOME都是在这里定义的 -
注册中心
zookeeper -
服务端相关配置,比如缓存,时区设置等
如果您不使用某些任务类型,您可以忽略任务外部依赖项,但您必须根据您的环境更改 JAVA_HOME、注册中心和数据库相关配置。
- # 修改内容如下
- [root@hadoop01 ~]# vim /bigdata/dolphinscheduler/bin/env/dolphinscheduler_env.sh
-
- # JAVA_HOME, will use it to start DolphinScheduler server
- # 改为自己的 JDK 路径
- export JAVA_HOME=${JAVA_HOME:-/usr/java/jdk1.8.0_381}
-
- # Database related configuration, set database type, username and password
- # MySQL 数据库连接信息
- export DATABASE=${DATABASE:-mysql}
- export SPRING_PROFILES_ACTIVE=${DATABASE}
- export SPRING_DATASOURCE_URL="jdbc:mysql://192.168.170.136:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8&useSSL=false&allowPublicKeyRetrieval=true"
- export SPRING_DATASOURCE_USERNAME=${SPRING_DATASOURCE_USERNAME:-"dolphinscheduler"}
- export SPRING_DATASOURCE_PASSWORD=${SPRING_DATASOURCE_PASSWORD:-"Qwe123456."}
-
- # DolphinScheduler server related configuration
- # 不用修改
- export SPRING_CACHE_TYPE=${SPRING_CACHE_TYPE:-none}
- export SPRING_JACKSON_TIME_ZONE=${SPRING_JACKSON_TIME_ZONE:-UTC}
- export MASTER_FETCH_COMMAND_NUM=${MASTER_FETCH_COMMAND_NUM:-10}
-
- # Registry center configuration, determines the type and link of the registry center
- # zookeeper 集群信息
- export REGISTRY_TYPE=${REGISTRY_TYPE:-zookeeper}
- export REGISTRY_ZOOKEEPER_CONNECT_STRING=${REGISTRY_ZOOKEEPER_CONNECT_STRING:-hadoop01:2181,hadoop02:2181,hadoop03:2181}
-
- # Tasks related configurations, need to change the configuration if you use the related tasks.
- # 对已有可以正常配置,没有的保持默认即可
- export HADOOP_HOME=${HADOOP_HOME:-/bigdata/hadoop/server/hadoop-3.2.4}
- export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-/bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop}
- export SPARK_HOME1=${SPARK_HOME1:-/bigdata/spark-3.2.4}
- export SPARK_HOME2=${SPARK_HOME2:-/bigdata/spark-3.2.4}
- export PYTHON_HOME=${PYTHON_HOME:-/usr/local/anaconda3/bin/python}
- export HIVE_HOME=${HIVE_HOME:-/bigdata/apache-hive-3.1.2}
- export FLINK_HOME=${FLINK_HOME:-/bigdata/flink}
- export DATAX_HOME=${DATAX_HOME:-/bigdata/datax}
- export SEATUNNEL_HOME=${SEATUNNEL_HOME:-/bigdata/seatunnel}
- export CHUNJUN_HOME=${CHUNJUN_HOME:-/bigdata/chunjun}
-
- export PATH=$HADOOP_HOME/bin:$SPARK_HOME1/bin:$SPARK_HOME2/bin:$PYTHON_HOME/bin:$JAVA_HOME/bin:$HIVE_HOME/bin:$FLINK_HOME/bin:$DATAX_HOME/bin:$SEATUNNEL_HOME/bin:$CHUNJUN_HOME/bin:$PATH

2.4.5 初始化元数据
- # 切换到 dolphinscheduler 目录下,执行命令
- [root@hadoop01 ~]# cd /bigdata/dolphinscheduler/
- [root@hadoop01 /bigdata/dolphinscheduler]# bash tools/bin/upgrade-schema.sh
2.5 修改 install_env.sh 文件
完成基础环境的准备后,需要根据你的机器环境修改配置文件。配置文件可以在目录 bin/env 中找到,他们分别是 并命名为 install_env.sh 和 dolphinscheduler_env.sh。文件 install_env.sh 描述了哪些机器将被安装 DolphinScheduler 以及每台机器对应安装哪些服务。您可以在路径 bin/env/install_env.sh 中找到此文件,可通过以下方式更改env变量,export <ENV_NAME>=,配置详情如下。
- [root@hadoop01 ~]# vim /bigdata/dolphinscheduler/bin/env/install_env.sh
- # 所有组件涉及的机器
- ips=${ips:-"192.168.170.136,192.168.170.137,192.168.170.138"}
-
- # ssh 连接的端口
- sshPort=${sshPort:-"22"}
-
- # master 节点
- masters=${masters:-"192.168.170.136,192.168.170.137"}
-
- # 工作节点
- workers=${workers:-"192.168.170.136:default,192.168.170.137:default,192.168.170.138:default"}
-
- # 部署报警服务的机器
- alertServer=${alertServer:-"192.168.170.138"}
-
- # 部署前端 API 接口的服务器
- apiServers=${apiServers:-"192.168.170.136"}
-
- # 安装路径
- installPath=${installPath:-"/bigdata/dolphinscheduler-3.1.8"}
-
- # 使用的用户
- deployUser=${deployUser:-"root"}
-
- # 在 zookeeper 中使用的名称空间
- zkRoot=${zkRoot:-"/dolphinscheduler"}
2.6 启动 DolphinScheduler
使用上面创建的部署用户运行以下命令完成部署,部署后的运行日志将存放在 logs 文件夹内
- [root@hadoop01 ~]# cd /bigdata/dolphinscheduler/
- [root@hadoop01 /bigdata/dolphinscheduler]# bash ./bin/install.sh
注意: 第一次部署的话,可能出现 5 次 sh: bin/dolphinscheduler-daemon.sh: No such file or directory 相关信息,此为非重要信息直接忽略即可。
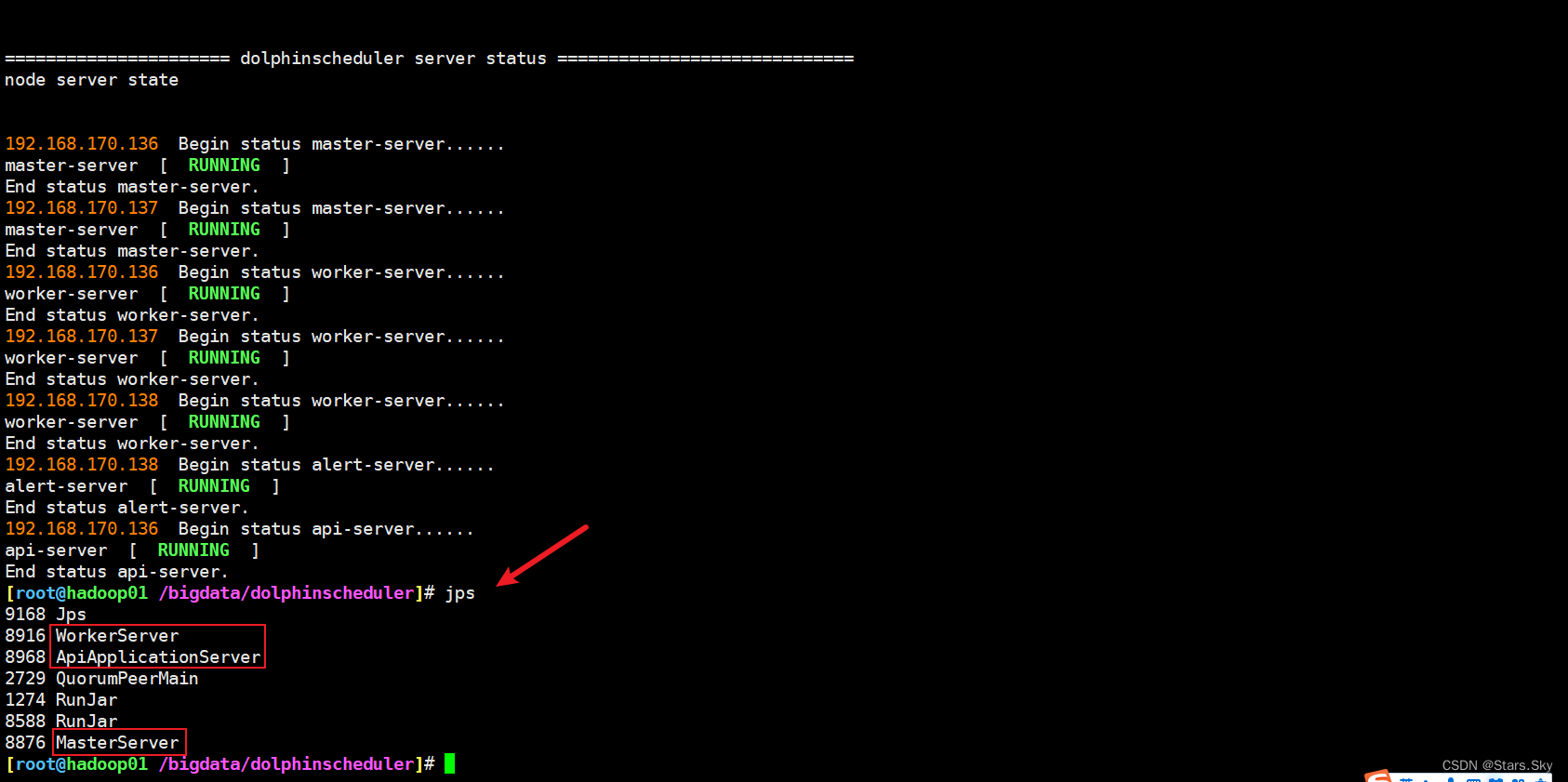
2.7 登录 DolphinScheduler
浏览器访问地址 http://localhost:12345/dolphinscheduler/ui 即可登录系统UI。默认的用户名和密码是 admin/dolphinscheduler123

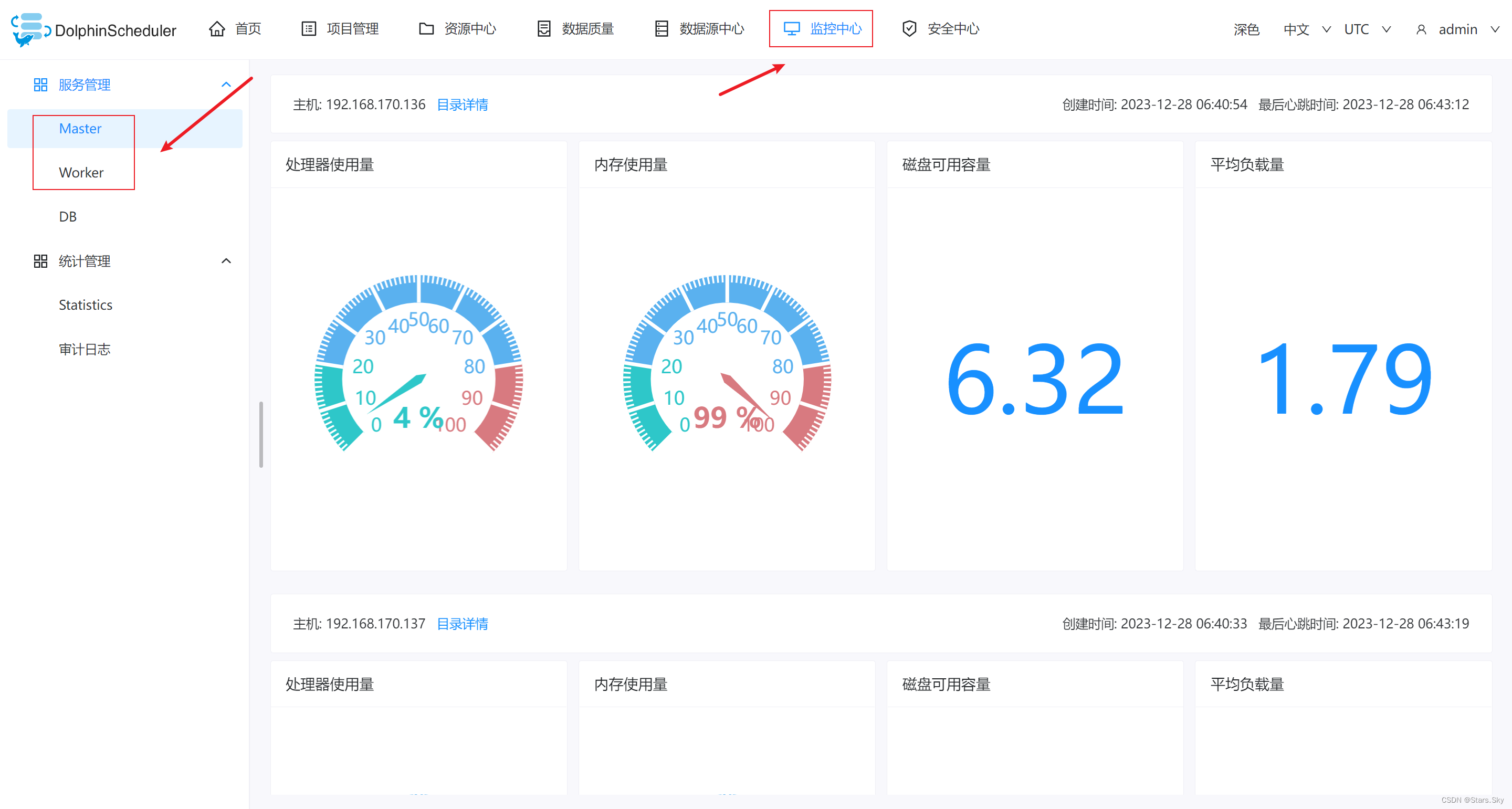
在监控中心即可查看各个组件的状态:
2.8 启停服务
第一次安装后会自动启动所有服务的,如有服务问题或者后续需要启停,命令如下。下面的操作脚本都在 dolphinScheduler 安装目录 bin 下(/bigdata/dolphinscheduler-3.1.8/)。
- # 一键停止集群所有服务
- bash ./bin/stop-all.sh
-
- # 一键开启集群所有服务
- bash ./bin/start-all.sh
-
- # 启停 Master
- bash ./bin/dolphinscheduler-daemon.sh stop master-server
- bash ./bin/dolphinscheduler-daemon.sh start master-server
-
- # 启停 Worker
- bash ./bin/dolphinscheduler-daemon.sh start worker-server
- bash ./bin/dolphinscheduler-daemon.sh stop worker-server
-
- # 启停 Api
- bash ./bin/dolphinscheduler-daemon.sh start api-server
- bash ./bin/dolphinscheduler-daemon.sh stop api-server
-
- # 启停 Alert
- bash ./bin/dolphinscheduler-daemon.sh start alert-server
- bash ./bin/dolphinscheduler-daemon.sh stop alert-server
注意 1 : 每个服务在路径
<service>/conf/dolphinscheduler_env.sh中都有dolphinscheduler_env.sh文件,这是可以为微 服务需求提供便利。意味着您可以基于不同的环境变量来启动各个服务,只需要在对应服务中配置<service>/conf/dolphinscheduler_env.sh然后通过<service>/bin/start.sh命令启动即可。但是如果您使用命令/bin/dolphinscheduler-daemon.sh start <service>启动服务器,它将会用文件bin/env/dolphinscheduler_env.sh覆盖<service>/conf/dolphinscheduler_env.sh然后启动服务,目的是为了减少用户修改配置的成本.注意 2 :服务用途请具体参见《系统架构设计》小节。Python gateway service 默认与 api-server 一起启动,如果您不想启动 Python gateway service 请通过更改 api-server 配置文件
api-server/conf/application.yaml中的python-gateway.enabled : false来禁用它。

