
- 1vscode怎么写qt项目_项目经理-自我评价怎么写(范文)
- 2TCP/UDP协议详解_udp协议字段长度不够16位的要补全吗
- 3人工智能大模型原理与应用实战:深入解析Transformer模型_transform人工智能
- 4gitee查询用户名和密码 Android Studio 3.5以上版本新特性 sharePreferences 使用 不同的Activity间的preferences共享问题 Fragmen_android studio git查看当前用户名与密码
- 5mysql的show processlist命令大作用
- 6运营方法 - 运营的思考方法_运营与管理十六字真经 周雄伟
- 72023年排名前34位的无代码测试工具_kobiton
- 8mybatis mysql 多租户_MyBatis利用MyCat实现多租户的简单思路分享
- 9自然语言处理相关问题总结_自然语言处理问题
- 10Git 工作原理
文献学习-37-动态场景中任意形状针的单目 3D 位姿估计:一种高效的视觉学习和几何建模方法
赞
踩
On the Monocular 3D Pose Estimation for Arbitrary Shaped Needle in Dynamic Scenes: An Efficient Visual Learning and Geometry Modeling Approach
Authors: Bin Li,† , Student Member, IEEE, Bo Lu,† , Member, IEEE, Hongbin Lin, Yaxiang Wang, Fangxun Zhong, Member, IEEE, Qi Dou, Member, IEEE and Yun-Hui Liu, Fellow, IEEE
Source: IEEE TRANSACTIONS ON MEDICAL ROBOTICS AND BIONICS
Keywords: Surgical Robotics, Pose Estimation, Geometry Modeling, Vision-based Manipulation

Abstract:
导向图像的针具姿态估计对于机器人自主缝合至关重要,但它面临着重大挑战,因为针具的视觉投影细长,且手术环境动态多变。当前最先进的方法依赖额外的先验信息(如手握姿态、精确的运动学等)来实现亚毫米级别的精度,这限制了它们在不同手术场景中的应用。这篇论文提出了一种新的通用框架,用于单目针具姿态估计:视觉学习网络用于高效的几何特征提取,以及新颖的几何模型用于精确的姿态恢复。
为了精确捕获针具的特征,引入了一种基于形态学的多尺度掩码轮廓融合机制。然后,为针具姿态建立了一个新的状态表示,并开发了一个物理投影模型来推导其与特征之间的关系。还制定了一个抗遮挡目标,以联合优化姿态和推断特征的偏置,从而在遮挡场景下实现亚毫米级别的精度。方法既不需要CAD模型,也不依赖于圆形形状的假设,可以广泛估计其他小型平面轴对称物体的姿态。
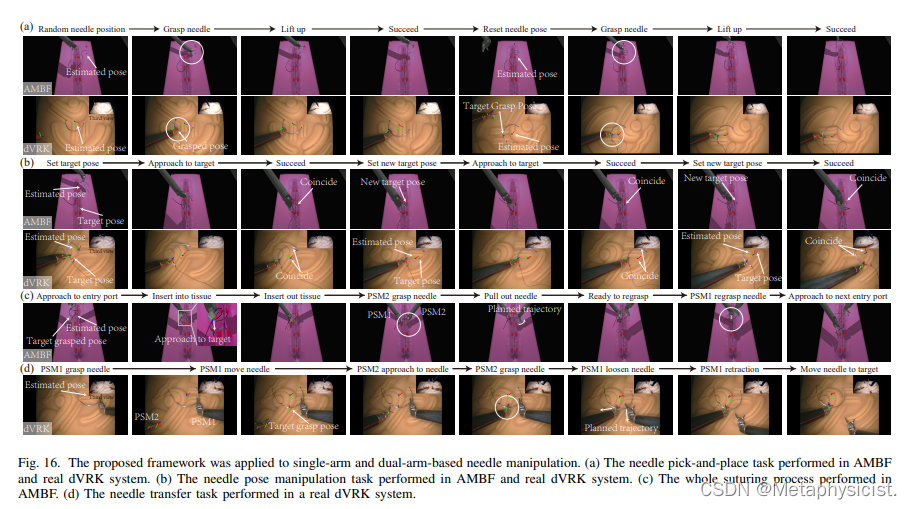
在内外活体实验场景中验证了估计的中间特征和针具最终姿态的准确性。进一步将框架部署到dVRK平台上,实现针具的自动精确操作,证明了其在机器人手术中的应用可行性。

图 1. 实时精确的针位姿估计示意图:动态且具有挑战性的手术场景,可以促进真实操作平台中各种针相关操作的机器人辅助自动化,例如 dVRK 系统中的针通过。
自动机器人手术有潜力显著提高手术精度,确保不受外科医生个体因素影响的一致性,并增强相比手动手术的安全性。自主缝合是自动化手术的关键组成部分,包括针具操作,如抓取、插入和交接等。
为了提高机器人缝合的效率和可靠性,过去几十年来,研究人员一直关注针具操作的自动化。在临床共识中,自主缝合的核心部分是实时针具姿态估计,因为它为针穿透组织进行伤口闭合时的后续轨迹规划和动作控制提供指导信息。然而,针具姿态估计通常面临的重大挑战是如何在具有挑战性的手术环境中实现高精度,这直接影响到自主缝合的安全性。例如,手术场景中可能包含镜头污染、反射或其他干扰因素。另外,针具的窄长形状,加上可能被组织或器械遮挡,也会阻碍高精度的估计。
为了高效且准确地提取必要的感知信息,视觉感知模型应该针对针具形状进行定制,防止在未针对针具形状设计的自然视觉方法中(如[8]和[9]中较大的或正常形状的物体)提取不准确的视觉特征。基于视觉特征,姿态求解器需要在缝合过程中准确且可用,因此它应该达到与当前最先进的方法相当的精度,但不需要它们所需的一些先验假设,如手握姿态配置或者准确的运动学信息。这是关键,因为在不被夹持器夹住时,针可以在空间或组织中的任何位置。此外,算法应该对噪声不敏感,以在出现意外噪声时保持姿态估计的鲁棒性。考虑到不同手术中针具的多样性(例如,妇科和整形手术中针的圆形/通用形状),算法应该具有通用性,以适应不同形状的针具,并且易于应用于各种手术程序。因此,开发一种新的针具姿态估计模型,系统地解决上述问题,对于实现机器人辅助自主缝合至关重要。
在本文中,提出了一种系统框架,实现在具有挑战性的手术场景中实时的针具姿态估计,达到当前最先进的性能,而无需依赖先验假设(如手握设置或圆形形状)。为了应对与针具形状相关的视觉感知挑战,提出了一种定制的针具网络(Needle-Net),用于从单目图像中提取针具的几何特征,包括掩码、关键点和检测结果,这些可以端到端地进行训练。为了获得有助于后续精确姿态估计的针具细长细节,首先在多尺度上分别学习粗掩码和精细轮廓,然后利用一种新颖的基于形态学的掩码轮廓融合机制将它们合并成精确的针具掩码。然后,开发了一种基于稀疏点描述符和基于几何的图像平面上的6自由度(DoF)物理模型的新型几何模型,并在几何流形上优化姿态。接着,提出了一个新颖的抗遮挡目标函数,涉及重新投影的点和掩码,随后使用粗到细的非线性优化器求解,实现高效且准确的姿态估计,能够补偿复杂手术场景中细长针具的不准确视觉感知。最后,在自收集的活体临床数据集和脱活体模型数据集上验证了框架,结果表明方法可以实现对中间特征和最终估计针具姿态的精确估计。此外,通过在达芬奇研究套件(dVRK)上进行视觉引导的针具操作评估了框架,证明了它在自动化机器人辅助手术中的可行性。
这是前期工作的全面改进版本,该工作在AccelNet手术机器人挑战赛中排名第一。这是第一个可以在动态遮挡环境中从单目图像中实时准确估计任意形状针具姿态的工作,精度达到亚毫米级别,为机器人手术中的自动针具操作奠定了坚实的基础。主要贡献如下:
1. 提出视觉学习与几何建模的无缝结合,实现高精度的姿态估计。
2. 一个高效的针具网络,用于提取长而窄形针具对象的精确几何特征。
3. 一种新的针具姿态表示状态空间,以及在这个空间上的基于几何的的姿态优化模型。
4. 在活体/脱活体图像和真实机器人部署的广泛实验,展示了姿态精度及其在自动手术中的适用性。
如表I所示,与现有方法进行了比较,并强调了在通用可操作性方面的独特优势:
1. 它可以在动态遮挡的手术场景中运行,提供与当前最先进的方法相当的精度,同时避免了额外的先验假设(如手握姿态或准确的运动学)。
2. 其高效流程(约60fps)和准确性能(@0.85mm/2.75°的误差)使得它适合在手术机器人中部署。
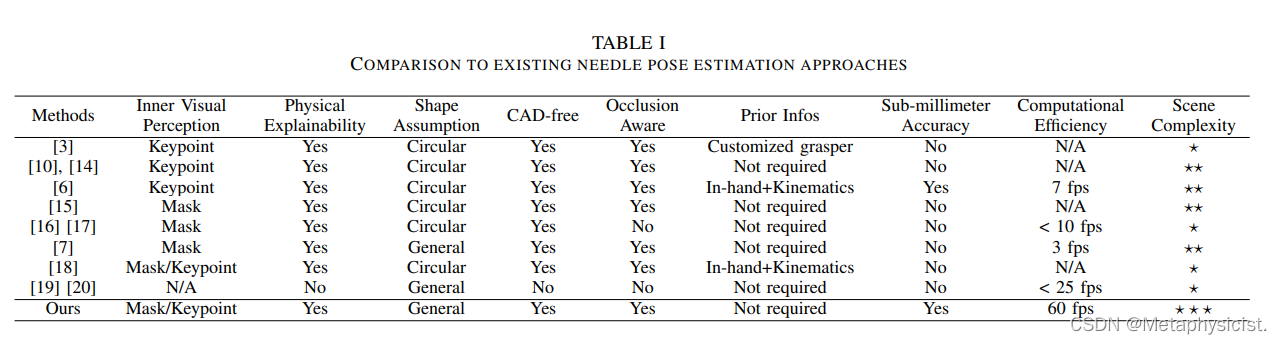
图 2. 所提出的框架由一个多任务 Needle-Net 组成,该网络共享一个特征编码器和用于提取几何基元的不同头,即用于针存在的检测头、用于对象分割的掩模头以及用于关键点定位的关键点头和 能见度。 如果检测到针,则将使用代数几何模型根据先前提取的几何基元以及附加解耦参数(稀疏点先验和相机固有参数)来有效估计新颖的 6-DoF 位姿空间中的 3D 位姿。 否则,如果没有检测到针,则不需要进一步估计。
图3 基于透视投影的3D几何姿态模型。 针是一个具有固定中心轴的弯曲物体,用沿轴的对应点对其进行编码。
A. 框架概述:
该框架由多任务 Needle-Net 和几何 3D 位姿估计组件组成。
Needle-Net 首先确定针是否存在,如果存在,则提取几何基元,如分割掩模、关键点等。
然后,几何姿态估计组件使用这些基元来有效地估计针的 3D 姿态。
B. 检测、分割和几何基元提取子网络:
Needle-Net 使用共享特征编码器和单独的头进行检测、分割和关键点提取。
对于分割,它使用基于形态学的掩模轮廓融合(MCF)机制来精确分割细弯针。
对于关键点,它提取针的起点和终点并对它们的可见性/遮挡进行分类。
它使用结合交叉熵和 Jaccard 损失的混合损失函数来训练分割,并使用关键点的几何原始损失。
为了使框架轻量级以进行实时部署,它使用深度可分离卷积。
总体而言,关键创新在于多任务 Needle-Net 架构、用于精确分割的 MCF 模块以及基于提取的图元构建的几何姿态估计组件。
图 4. 几何示意图对应于基于恒定深度假设的 (a) θinit1 和 (b) θinit2 的初始粗略计算。
图5.存在遮挡时的姿态估计示意图。 优化函数考虑可见区域像素到投影轴点集的最小距离,遮挡部分不影响最小JA对应的位姿极值。
C. 针状物体的 3D 位姿估计
1. 几何投影模型及表示法: - 针状物体使用沿其曲线中心轴的离散点来表示。 - 使用投影的起点/终点和描述针方向的两个角度(θ1、θ2)定义新颖的 6-DoF 位姿空间。 - 导出方程来计算针在相机框架中的平移和旋转分量。
2. 3D Pose初始化: - 当检测到针时,使用恒定深度假设和提取的关键点来估计初始粗略姿势。 - 初始角度θ_init1和θ_init2根据几何关系计算。
3. 3D姿势的细化: - 制定了抗遮挡目标函数 (JA),以最小化可见掩模区域中的像素与投影的 3D 点之间的距离。 - LM算法用于有效优化6-DoF位姿参数x以最小化JA。
- 对于具有一个闭塞关键点的圆形针,执行附加的局部旋转细化步骤。 - EKF 用于平滑机器人部署过程中的稳定性估计姿势。
关键的创新是新颖的 6-DoF 姿态表示、抗遮挡目标函数以及利用提取的几何基元的从粗到细的姿态估计方法。
实验部分:
A.数据集:
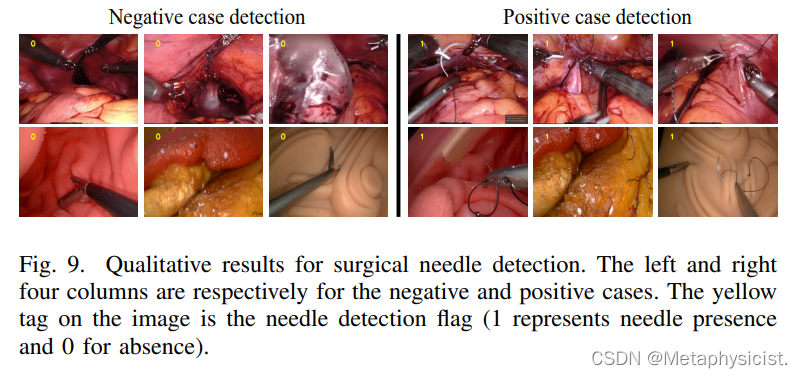
- 作者根据体内子宫切除视频和体外模型模拟操作创建了一个包含 1428 张图像(769 张阳性图像,659 张阴性图像)的新数据集。
- 阳性样本用掩模、开始/结束关键点及其可见性/遮挡进行注释。
- 使用带有 apriltags 的透明亚克力板创建了额外的 20 个案例评估数据集,以获得地面真实 3D 姿势。
B. 实施细节:
- Needle-Net 使用 NVIDIA RTX 3090 GPU 和 Adam 优化器进行训练。
- 对于 3D 位姿估计,根据已知的物理参数或样条拟合对针轴进行均匀采样(200 个点)。
- Levenberg-Marquardt 算法用于姿势优化,并使用 EKF 过滤最终姿势输出。
- 该框架部署在达芬奇研究套件 (dVRK) 平台上,用于自动针操作。
C. 检测、分割和几何特征检测的评估:
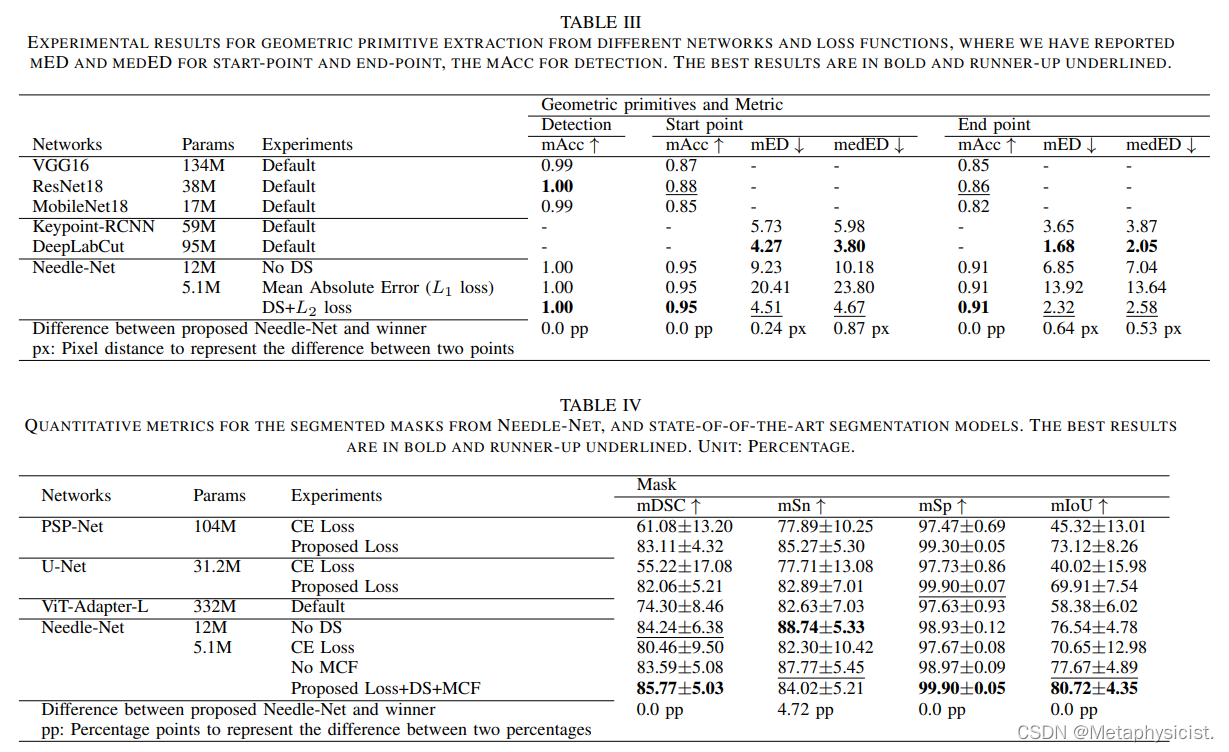
- Needle-Net 在测试集上实现了 100% 的检测准确率,优于 VGG16、ResNet18 和 MobileNet18。
- 对于关键点检测,Needle-Net 的平均准确率达到 95%,优于 Keypoint-RCNN 和 DeepLabCut。
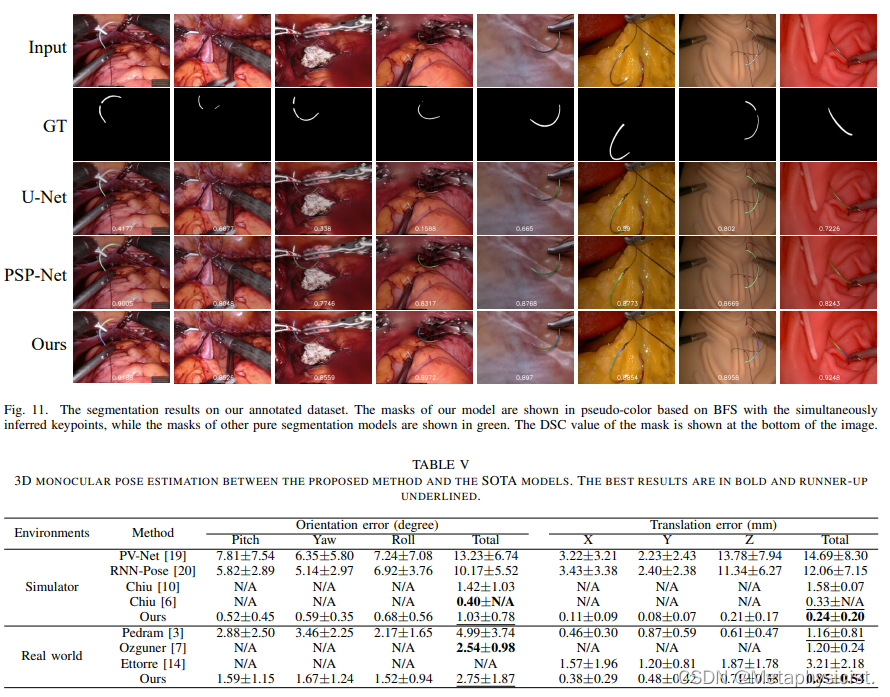
- 对于分割,具有所提出的损失和 MCF 模块的 Needle-Net 实现了最佳性能,平均 DSC 为 85.77%,平均 IoU 为 80.72%,优于 U-Net、PSPNet 和 ViT-Adapter。
D. 3D位姿估计评估:
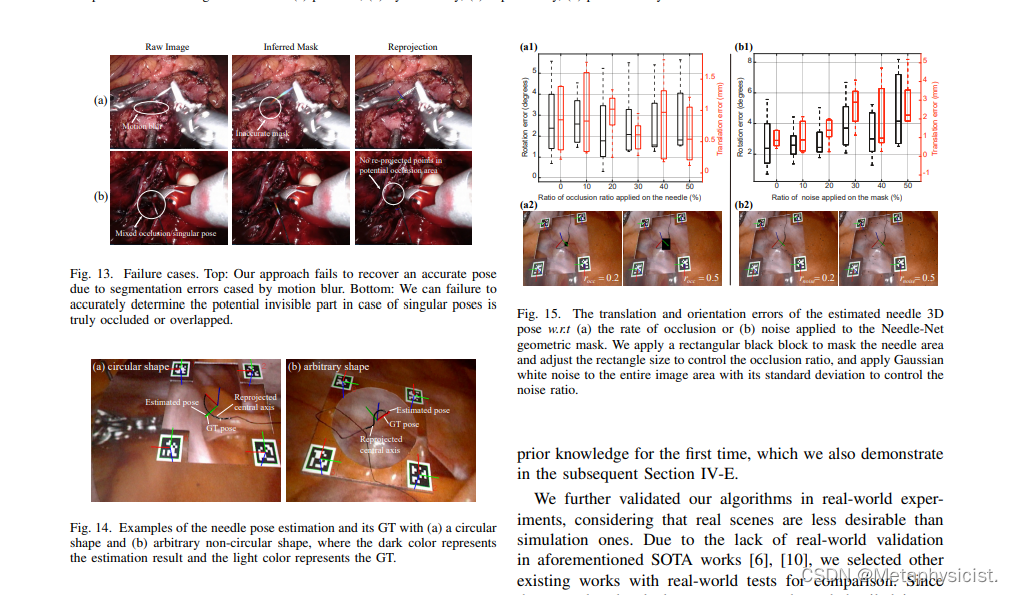
- 定性结果表明该方法可以处理手术场景中的各种遮挡场景、反射和其他具有挑战性的条件。
- 对 20 个案例数据集的定量评估显示,中位位置误差为 1.42 毫米,中位方向误差为 2.16 度。
- 该框架已成功部署在 dVRK 平台上,用于自动针操作任务。
总的来说,实验证明了所提出的多任务 Needle-Net 和 3D 姿态估计框架在具有挑战性的手术场景中的有效性。
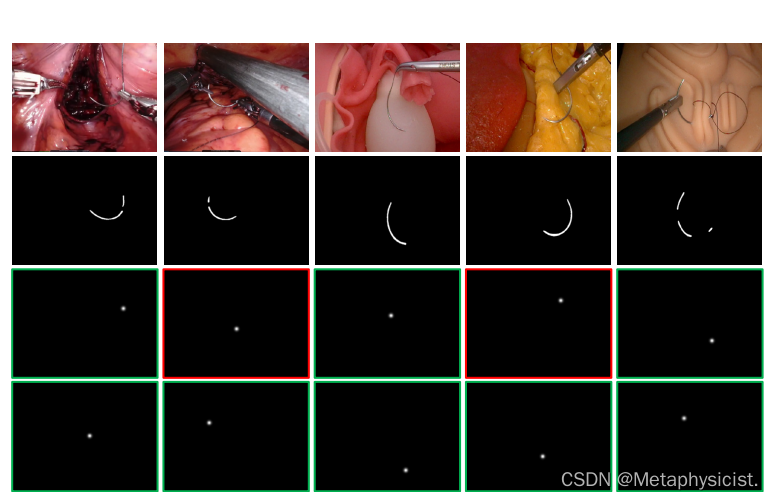
图 6. 来自内部子宫切除术和几个体模的带注释的自我收集图像示例。 从上到下逐行依次是原始图像、掩模、起始关键点热图和结束关键点热图。 热图周围的绿色框表示关联的关键点可见,而红色框表示关联的关键点被遮挡


图 7.(a) 根据真实图像数据进行 3D 姿态评估的一般图像。 手动提取不包含 apriltag 的子图像(如左侧未变暗的部分所示)并用作 Needle-Net 输入图像。 apriltag 用于计算 3D 位姿 GT。 (b) 重新投影到原始图像上的估计 3D 姿态。



Reference:
[1] Li, B., Lu, B., Lin, H., Wang, Y., Zhong, F., Dou, Q., & Liu, Y. H. (2024). On the Monocular 3D Pose Estimation for Arbitrary Shaped Needle in Dynamic Scenes: An Efficient Visual Learning and Geometry Modeling Approach. IEEE Transactions on Medical Robotics and Bionics.

