
- 1NSSCTF做题(6)_$aaa==114514 && $bbb==114514 && $aaa!=$bbb
- 2Github网络安全测试工具库_github漏洞扫描器项目
- 31.springboot压测调优_springboot项目压测了几个请求就padding
- 4关于CSDN博客阅读数显示的一些问题_csdn已阅读包括自己吗
- 5_string
- 6C语言I/O学习笔记(1)stdin,stdout和stderr以及重定向_c语言 重定义 stdin
- 7工业设备嵌入式通讯接口升级方案_设备通讯接口升级权限
- 8【错误记录】Android 编译报错 ( The project uses Gradle version which is incompatible with Android Studio )_unsupported gradle. the project uses gradle versio
- 9搭建自己的chatgpt-web(nextchat)_chatgptweb搭建
- 10uniapp通过custom-tab-bar 自定义tabbar导航栏(主要用于微信小程序)_uniapp custom-tab-bar
【做法说明】Yolo训练行人车辆目标检测数据集储备与模型训练【KITTI】_yolo车辆行人检测数据集
赞
踩
一、数据集介绍
KITTI数据集由德国卡尔斯鲁厄理工学院和丰田工业大学芝加哥分校联合赞助的用于自动驾驶领域研究的数据集。作者收集了长达6个小时的真实交通环境,数据集由经过校正和同步的图像、雷达扫描、高精度的GPS信息和IMU加速信息等多种模态的信息组成。作者还在数据集官网提供了光流、物体检测、深度估计等多种任务的Benchmark。
数据集链接:http://www.cvlibs.net/datasets/kitti/
论文链接:http://www.webmail.cvlibs.net/publications/Geiger2012CVPR.pdf
精确的地面真相由Velodyne激光扫描仪和GPS定位系统提供。我们的数据集是通过在中型城市卡尔斯鲁厄(Karlsruhe)、乡村地区和高速公路上行驶来获取的。每张图像可看到多达15辆汽车和30个行人。除了以原始格式提供所有数据外,我们还为每个任务提取基准。对于我们的每一个基准,我们也提供了一个评估指标和这个评估网站。初步实验表明,在现有基准中排名靠前的方法,如Middlebury方法,在脱离实验室进入现实世界后,表现低于平均水平。我们的目标是减少这种偏见,并通过向社会提供具有新困难的现实基准来补充现有基准。
二、数据集下载
KITTI的官网地址为:The KITTI Vision Benchmark Suite
由于使用做行人车辆目标检测训练,仅寻找与行人,车辆有关的内容,该部分需要注册账号,链接如下:
Download![]() http://www.cvlibs.net/download.php?file=data_object_image_2.zip
http://www.cvlibs.net/download.php?file=data_object_image_2.zip
Download![]() http://www.cvlibs.net/download.php?file=data_object_label_2.zip
http://www.cvlibs.net/download.php?file=data_object_label_2.zip
得到需要的图片和标签。
也可以在官网上直接下载:

文件需要科学上网,下载时注意网速问题。
下载完成后,我们在yolov5/dataset下创建文件夹kitti,在kitti中放入我们的数据
- |——kitti
- ├── imgages
- │ └── origin
- │ ├── 000001.png
- │ └── .......
- └── labels
- ├── origin
- │ ├── 000001.txt
- │ └── .......
- └── xml
三、KITTI数据集LABLE转换
1. KITTI原数据格式介绍
原先文件中,LABLE如下所示。
![]()
官网上可以查询到其数据格式:

2. 数据类别的整合
该数据集的标注一共分为8个类别:
’Car’,’Van’,’Truck’,’Pedestrian’,’Person_sitting’,’Cyclist’,’Misc’和’DontCare’。
在代码中,将’Pedestrian’, ’Person_sitting’合并为’Pedestrian’ ,删除’Misc’和’DontCare’
首先我们把类别归一一下,因为我们需要用到6个类(代码中的路径需要修改)
- # modify_annotations_txt.py
-
- import glob
- import string
-
- txt_list = glob.glob('D:/File/yolov5-mobileone-master/dataset/kitti/labels/origin/*.txt') # 存储Labels文件夹所有txt文件路径
-
- print(txt_list)
- def show_category(txt_list):
- category_list= []
- for item in txt_list:
- try:
- with open(item) as tdf:
- for each_line in tdf:
- labeldata = each_line.strip().split(' ') # 去掉前后多余的字符并把其分开
- category_list.append(labeldata[0]) # 只要第一个字段,即类别
- except IOError as ioerr:
- print('File error:'+str(ioerr))
- print(set(category_list)) # 输出集合
-
- def merge(line):
- each_line=''
- for i in range(len(line)):
- if i!= (len(line)-1):
- each_line=each_line+line[i]+' '
- else:
- each_line=each_line+line[i] # 最后一条字段后面不加空格
- each_line=each_line+'\n'
- return (each_line)
-
- print('before modify categories are:\n')
- show_category(txt_list)
-
- for item in txt_list:
- new_txt=[]
- try:
- with open(item, 'r') as r_tdf:
- for each_line in r_tdf:
- labeldata = each_line.strip().split(' ')
- # if labeldata[0] in ['Truck','Van','Tram']: # 合并汽车类
- # labeldata[0] = labeldata[0].replace(labeldata[0],'Car')
- if labeldata[0] == 'Person_sitting': # 合并行人类
- labeldata[0] = labeldata[0].replace(labeldata[0],'Pedestrian')
- if labeldata[0] == 'DontCare': # 忽略Dontcare类
- continue
- if labeldata[0] == 'Misc': # 忽略Misc类
- continue
- new_txt.append(merge(labeldata)) # 重新写入新的txt文件
- with open(item,'w+') as w_tdf: # w+是打开原文件将内容删除,另写新内容进去
- for temp in new_txt:
- w_tdf.write(temp)
- except IOError as ioerr:
- print('File error:'+str(ioerr))
-
- print('\nafter modify categories are:\n')
- show_category(txt_list)
输出结果为:
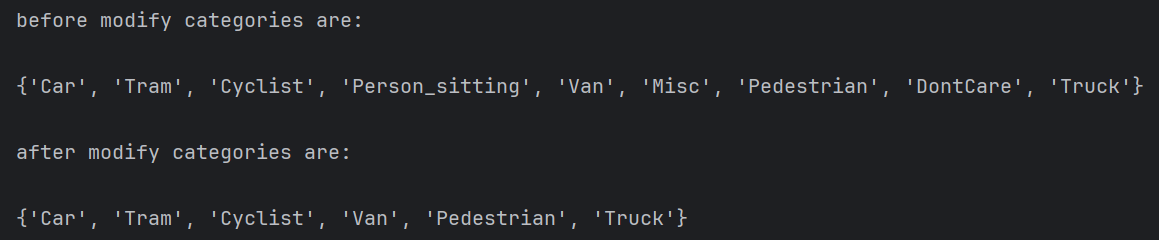
3. 数据的储存(转化为xml文件)
然后再把它转换为xml文件,在Labels目录创建一个xml文件夹用于存放xml。
- # kitti_txt_to_xml.py
- # encoding:utf-8
- # 根据一个给定的XML Schema,使用DOM树的形式从空白文件生成一个XML
- from xml.dom.minidom import Document
- import cv2
- import glob
- import os
- def generate_xml(name,split_lines,img_size,class_ind):
- doc = Document() # 创建DOM文档对象
- annotation = doc.createElement('annotation')
- doc.appendChild(annotation)
- title = doc.createElement('folder')
- title_text = doc.createTextNode('KITTI')
- title.appendChild(title_text)
- annotation.appendChild(title)
- img_name=name+'.jpg'
- title = doc.createElement('filename')
- title_text = doc.createTextNode(img_name)
- title.appendChild(title_text)
- annotation.appendChild(title)
- source = doc.createElement('source')
- annotation.appendChild(source)
- title = doc.createElement('database')
- title_text = doc.createTextNode('The KITTI Database')
- title.appendChild(title_text)
- source.appendChild(title)
- title = doc.createElement('annotation')
- title_text = doc.createTextNode('KITTI')
- title.appendChild(title_text)
- source.appendChild(title)
- size = doc.createElement('size')
- annotation.appendChild(size)
- title = doc.createElement('width')
- title_text = doc.createTextNode(str(img_size[1]))
- title.appendChild(title_text)
- size.appendChild(title)
- title = doc.createElement('height')
- title_text = doc.createTextNode(str(img_size[0]))
- title.appendChild(title_text)
- size.appendChild(title)
- title = doc.createElement('depth')
- title_text = doc.createTextNode(str(img_size[2]))
- title.appendChild(title_text)
- size.appendChild(title)
- for split_line in split_lines:
- line=split_line.strip().split()
- if line[0] in class_ind:
- object = doc.createElement('object')
- annotation.appendChild(object)
- title = doc.createElement('name')
- title_text = doc.createTextNode(line[0])
- title.appendChild(title_text)
- object.appendChild(title)
- bndbox = doc.createElement('bndbox')
- object.appendChild(bndbox)
- title = doc.createElement('xmin')
- title_text = doc.createTextNode(str(int(float(line[4]))))
- title.appendChild(title_text)
- bndbox.appendChild(title)
- title = doc.createElement('ymin')
- title_text = doc.createTextNode(str(int(float(line[5]))))
- title.appendChild(title_text)
- bndbox.appendChild(title)
- title = doc.createElement('xmax')
- title_text = doc.createTextNode(str(int(float(line[6]))))
- title.appendChild(title_text)
- bndbox.appendChild(title)
- title = doc.createElement('ymax')
- title_text = doc.createTextNode(str(int(float(line[7]))))
- title.appendChild(title_text)
- bndbox.appendChild(title)
- # 将DOM对象doc写入文件
- f = open('D:/File/yolov5-mobileone-master/dataset/kitti/labels/xml/'+name+'.xml','w')#xml
- f.write(doc.toprettyxml(indent = ''))
- f.close()
- if __name__ == '__main__':
- class_ind=('Car', 'Cyclist', 'Truck', 'Van', 'Pedestrian', 'Tram')
- # cur_dir=os.getcwd()
- labels_dir= "D:/File/yolov5-mobileone-master/dataset/kitti/labels/origin"
- # labels_dir=os.path.join(cur_dir,'label_2')
- for parent, dirnames, filenames in os.walk(labels_dir):# 分别得到根目录,子目录和根目录下文件
- for file_name in filenames:
- full_path=os.path.join(parent, file_name) # 获取文件全路径
- f=open(full_path)
- split_lines = f.readlines() #以行为单位读
- name= file_name[:-4] # 后四位是扩展名.txt,只取前面的文件名
- img_name=name+'.png'
- img_path=os.path.join('D:/File/yolov5-mobileone-master/dataset/kitti/images/origin',img_name) # 路径需要自行修改
- img_size=cv2.imread(img_path).shape
- generate_xml(name,split_lines,img_size,class_ind)
- print('txts has converted into xmls')
这个时候我们已经将.txt转化为.xml并存放在设定的文件夹xml下了。
4. 数据格式的转化与数据集划分
最后我们再把.xml转化为适合于yolo训练的标签模式,将下面代码放置在数据集文件夹的根目录,注意不要将图片文件夹和要生成文件夹的名称重复。按照0.7:0.15:0.15构造数据集、测试集、验证集并分别分配到不同文件夹去。
- |——kitti
- ├── imgages
- │ ├── train
- │ │ ├── 00XXXA.png
- │ │ └── .......
- │ ├── val
- │ │ ├── 00XXXB.png
- │ │ └── .......
- │ └── test
- │ └── 00XXXC.png
- │ └── .......
- │
- └── labels
- ├── train
- │ ├── 00XXXA.txt
- │ └── .......
- ├── val
- │ ├── 00XXXB.txt
- │ └── .......
- └── test
- ├── 00XXXC.txt
- └── .......
分配代码如下:
- # xml_to_txt_yolo.py
- # 将此文件放置在你的数据集根目录下即可
- # 一定要放到根目录下
-
- import xml.etree.ElementTree as ET
- import os
- import shutil
- import random
-
- xml_file_path = 'D:/File/yolov5-mobileone-master/dataset/kitti/labels/xml/' # 检查和自己的xml文件夹名称是否一致
- images_file_path = 'images/origin/' # 检查和自己的图像文件夹名称是否一致
- # 改成自己的类别名称
- classes = ['Car', 'Cyclist', 'Truck', 'Van', 'Pedestrian', 'Tram']
- # 数据集划分比例,训练集75%,验证集15%,测试集15%
- train_percent = 0.7
- val_percent = 0.15
- test_percent = 0.15
- # 此处不要改动,只是创一个临时文件夹
- if not os.path.exists('temp_labels/'):
- os.makedirs('temp_labels/')
- txt_file_path = 'temp_labels/'
-
-
- def convert(size, box):
- dw = 1. / size[0]
- dh = 1. / size[1]
- x = (box[0] + box[1]) / 2.0
- y = (box[2] + box[3]) / 2.0
- w = box[1] - box[0]
- h = box[3] - box[2]
- x = x * dw
- w = w * dw
- y = y * dh
- h = h * dh
- return x, y, w, h
-
-
- def convert_annotations(image_name):
- in_file = open(xml_file_path + image_name + '.xml')
- out_file = open(txt_file_path + image_name + '.txt', 'w')
- tree = ET.parse(in_file)
- root = tree.getroot()
- size = root.find('size')
- w = int(size.find('width').text)
- h = int(size.find('height').text)
- for obj in root.iter('object'):
- # difficult = obj.find('difficult').text
- cls = obj.find('name').text
- # if cls not in classes or int(difficult) == 1:
- # continue
- if cls not in classes == 1:
- continue
- cls_id = classes.index(cls)
- xmlbox = obj.find('bndbox')
- b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text),
- float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
- bb = convert((w, h), b)
- out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
-
-
- total_xml = os.listdir(xml_file_path)
- num_xml = len(total_xml) # XML文件总数
-
- for i in range(num_xml):
- name = total_xml[i][:-4]
- convert_annotations(name)
-
-
- # *********************************************** #
- # parent folder
- # --data
- # ----images
- # ----train
- # ----val
- # ----test
- # ----labels
- # ----train
- # ----val
- # ----test
- def create_dir():
- if not os.path.exists('images/'):
- os.makedirs('images/')
- if not os.path.exists('labels/'):
- os.makedirs('labels/')
- if not os.path.exists('images/train'):
- os.makedirs('images/train')
- if not os.path.exists('images/val'):
- os.makedirs('images/val')
- if not os.path.exists('images/test'):
- os.makedirs('images/test/')
- if not os.path.exists('labels/train'):
- os.makedirs('labels/train')
- if not os.path.exists('labels/val'):
- os.makedirs('labels/val')
- if not os.path.exists('labels/test'):
- os.makedirs('labels/test')
-
- return
-
-
- # *********************************************** #
- # 读取所有的txt文件
- create_dir()
- total_txt = os.listdir(txt_file_path)
- num_txt = len(total_txt)
- list_all_txt = range(num_txt) # 范围 range(0, num)
-
- num_train = int(num_txt * train_percent)
- num_val = int(num_txt * val_percent)
- num_test = num_txt - num_train - num_val
-
- train = random.sample(list_all_txt, num_train)
- # train从list_all_txt取出num_train个元素
- # 所以list_all_txt列表只剩下了这些元素:val_test
- val_test = [i for i in list_all_txt if not i in train]
- # 再从val_test取出num_val个元素,val_test剩下的元素就是test
- val = random.sample(val_test, num_val)
- # 检查两个列表元素是否有重合的元素
- # set_c = set(val_test) & set(val)
- # list_c = list(set_c)
- # print(list_c)
- # print(len(list_c))
-
- print("训练集数目:{}, 验证集数目:{},测试集数目:{}".format(len(train), len(val), len(val_test) - len(val)))
- for i in list_all_txt:
- name = total_txt[i][:-4]
-
- srcImage = images_file_path + name + '.png'
- srcLabel = txt_file_path + name + '.txt'
-
- if i in train:
- dst_train_Image = 'images/train/' + name + '.png'
- dst_train_Label = 'labels/train/' + name + '.txt'
- shutil.copyfile(srcImage, dst_train_Image)
- shutil.copyfile(srcLabel, dst_train_Label)
- elif i in val:
- dst_val_Image = 'images/val/' + name + '.png'
- dst_val_Label = 'labels/val/' + name + '.txt'
- shutil.copyfile(srcImage, dst_val_Image)
- shutil.copyfile(srcLabel, dst_val_Label)
- else:
- dst_test_Image = 'images/test/' + name + '.png'
- dst_test_Label = 'labels/test/' + name + '.txt'
- shutil.copyfile(srcImage, dst_test_Image)
- shutil.copyfile(srcLabel, dst_test_Label)
- print("complete")
数据分配结果如下:
![]()
数据集、验证集、测试集分配情况如下:
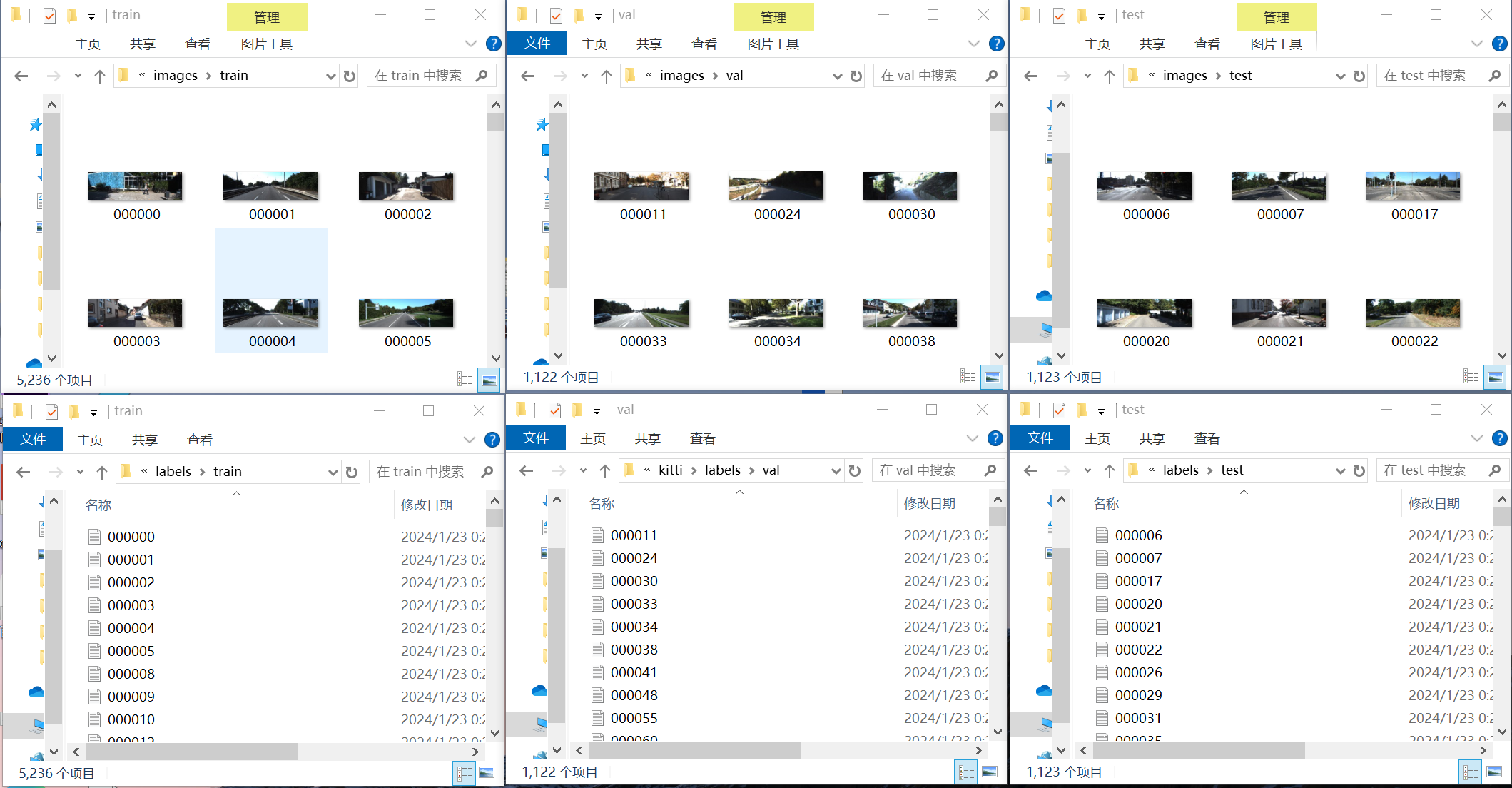
可以看到,数据与标签对应,数据个数与标签一致。
至此,数据准备已经全部完毕,可以载入yolo进行训练。在训练之前需要改变一些参数。
四、配置文件的修改
1. 修改数据集yaml文件
修改yaml文件,将dat目录下的coco128.yaml复制一份修改为kitti.yaml。
需要注意names部分应当与前述的一致,否则会出现错误。
- # kitti.yaml
-
- train: D:/File/yolov5-mobileone-master/dataset/kitti/images/train # train images (relative to 'path') 5236 images
- val: D:/File/yolov5-mobileone-master/dataset/kitti/images/val/ # val images (relative to 'path') 1122 images
- test: D:/File/yolov5-mobileone-master/dataset/kitti/images/test/ # test images (optional)
- nc: 6 # number of classes
- names: ['Car', 'Cyclist', 'Truck', 'Van', 'Pedestrian', 'Tram'] # class names
2. 修改models配置文件
本次实验使用yolov5s,故修改yolov5s.yaml文件,在models目录下。
修改nc(类别数量)即可。
- # yolov5s.yaml
- # YOLOv5 声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/458496推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

