
- 1Python下使用mqtt协议_python mqtt模块
- 2Go之map详解
- 3文心一言4.0 VS ChatGPT4.0哪家强?!每月60块的文心一言4.0值得开吗?_文心一言40.和chatgpt4对比
- 4YOLOv5(ultralytics) 训练自己的数据集,VOC2007为例_ultralytics能训练sam吗
- 5git push到自己仓库时报错master -> master (branch is currently checked out)_master -> master (push declined due to repository
- 6Git基本介绍及使用
- 7这6种最佳移动自动化测试工具你知道吗?
- 8四川易点慧电子商务抖音小店:安全正规,购物新选择
- 9Python tkinter (10) ——Combobox控件_python combobox 改变值
- 10使用docker安装mysql
k-means聚类算法 心得分享(含python实现代码)_pythonkmeans聚类算法代码
赞
踩
目录
2.5循环执行步骤2-4,直到达到最大迭代次数或者聚类中心不再发生变化。
1.K-means聚类算法
1.1 引言:
K-Means 是一种常用的无监督聚类算法,该算法的主要作用是将相似的样本自动归到一个类别中,它将一组数据分为 K 个簇。
1.2 K-Means 算法的基本思想
首先随机选择 K 个聚类中心点,然后对每个数据点计算其到每个聚类中心点的距离,将其归为离它最近的聚类中心点所代表的簇。
接着重新计算每个簇的中心点,重复上述步骤,直到聚类中心点不再发生变化或者达到最大迭代次数。
1.3 K-Means 算法的优缺点:
优点:由于不需要数据标注,所以它简单、高效,适用于大规模数据集。
缺点:非常依赖于初始聚类中心点的选择,容易收敛到局部最优解。
注:(局部最优解就是指在某个搜索空间中,找到的一组解能够使目标函数取得局部最优值,但并不能保证它是全局最优解。)而且对于非球形分布的数据,K-Means 算法的效果可能不理想。
此外,K-Means 算法需要预先指定聚类的个数 K,这也是一个需要考虑的问题。
1.4 K-Means 算法的应用:
K-Means 算法的应用非常广泛,例如:文本聚类、图像分割、基因组聚类等。它也是许多其他聚类算法的基础,如层次聚类、DBSCAN 等。
2.K-means聚类算法的实现具体步骤
1初始化聚类中心
2计算每个数据点到聚类中心的距离
3确定每个数据点所属聚类簇
4更新聚类中心
5循环执行步骤2-4,直到达到最大迭代次数或者聚类中心不再发生变化。
2.1初始化聚类中心
2.1.1选择K个点:
k-means算法非常依赖于初始聚类中心点的选择,
下面是常用于确定初始聚类中心的方法。
1)随机选择 K 个数据点作为初始聚类中心:
这是 K-Means 算法最基本的方法,但由于随机性,可能会导致算法收敛到一个较差的局部最优解。
2)K-Means++:
首先随机选择一个数据点作为第一个聚类中心,然后对于每个数据点,
计算其到已选聚类中心的距离的平方,并选择一个距离当前聚类中心最远(距离和最大)的数据点作为下一个聚类中心,
依此类推,直到选择完 K 个聚类中心。这种方法可以在一定程度上避免随机选择带来的影响,
提高算法收敛到全局最优解的概率。
3)均匀采样:从数据集中均匀采样 K 个数据点作为初始聚类中心。
这种方法简单、直接,但可能会导致初始聚类中心的选择不够随机,影响算法的性能。
4)人工选择:有时候可以根据领域知识或经验来手动选择初始聚类中心,这样可以更好地适应具体问题的特点,但需要相应的领域知识或经验。
对于以下数据集的验证,我将使用方法1)。

图 1—步骤1初始化聚类中心实现具体代码
使用choice 函数,从a(只要是ndarray都可以,但必须是一维的)中随机抽取数字,并组成指定大小(size)的数组。
使用np.ones函数,将每个样本标记为int型的1,再在前面添加‘-’,使其初始化为-1。
2.2计算每个数据点到聚类中心的距离
2.2.1 距离计算
对于各样本点到质心的距离计算,我采用了欧氏距离,欧氏距离为 k—means 算法的最常用距离计算方式。
亮点:在计算距离时,我想通过Numpy广播机制来简化代码,高效计算,但这要求维数相同,且各维度的长度相同。所以我首先将centroids数组从原来的一维数组扩展为二维数组,使其能够与data数组进行逐元素的操作。这里使用了NumPy的广播规则,该规则会自动将较小的数组沿着缺失的维度进行扩展,以使得两个数组具有相同的形状。然后,计算data中每个数据点与每个质心之间的差值的平方,此时得到一个shape:(2,150,2)数组,使用sum函数在第二个维度上对所有差值的平方进行求和,最后取平方根。这样就得到了一个二维数组,其中第一维(行)表示centroids数组中的每个质心,第二维(列)表示data数组中的每个元素表示一个质心和一个数据点之间的欧式距离。

图 2—步骤2实现具体代码
 图3—步骤2实现效果
图3—步骤2实现效果
2.3确定每个数据点所属聚类簇
使用numpy中argmin函数,选择参数axis=0,即返回垂直方向最小的值(行索引),即为所属类簇。

图4—步骤3实现具体代码
2.4更新聚类中心
2.4.1判断聚类结果
在更新聚类中心前,先判断是否已经收敛并计算sse(误差平方和)。使用array_equal函数可以检查两个数组是否具有相同的形状和元素。
2.4.2 更新聚类中心坐标
对data中在上一次聚类结果中属于不同簇的数据进行遍历,遍历k次,使用mean函数对垂直方向上求均值,作为下一次聚类中心的坐标,同时更新样本所属簇的标签。
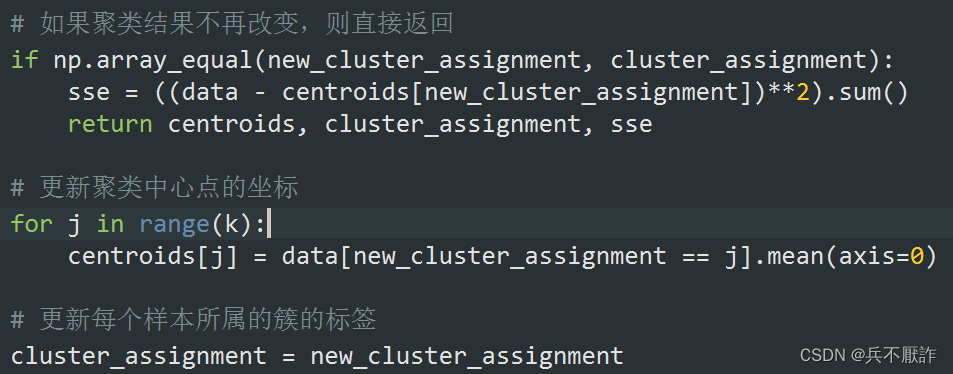
图5—步骤4实现具体代码
2.5循环执行步骤2-4,直到达到最大迭代次数或者聚类中心不再发生变化。
这里,我设置的最大迭代次数为300 次,为了防止出现死循环。
3.K值的选取
3.1手肘法基本介绍
手肘法是一种常用的选择 K 值的方法。手肘法的基本思想是,通过绘制不同 K 值下聚类模型的SSE,SSE是指“Sum of Squared Errors”(误差平方和),它是k-means算法中的一个重要指标,用于评估聚类结果的好坏。在k-means算法中,SSE是所有簇内数据点到其对应中心点的距离平方和。
通过观察损失函数随 K 值变化的趋势,找到一个最佳的 K 值,使得在这个 K 值之后,增加聚类数对于损失函数的改善效果变得不明显,形象地说,这个 K 值就是损失函数曲线的“拐点”,类似于手肘的形状,因此被称为“手肘法”。
3.2手肘法的基本步骤
1)循环使用 K-Means 算法,计算不同 K 值(2-10)下的聚类模型
2)计算每个聚类模型的损失函数值(误差平方和)
3)绘制损失函数随 K 值变化的曲线图
4)找到损失函数曲线的“拐点”,确定最佳的 K 值
3.2.1 sse可视化准备
首先创建空列表用来记录不同k值下的sse,调用kmeans函数,获取其中第三个返回值,即sse。并添加到列表中,为接下来的可视化做准备。

图6—手肘法可视化准备实现具体代码
3.2.2 sse可视化
使用matplotlib库函数中绘制折线图,x轴为Ks,即不同k值,y轴为sses,选择蓝色线条,×标注。设置坐标轴标题与图像标题,最后通过观察图像,输入k值,为最后的聚类结果做准备。
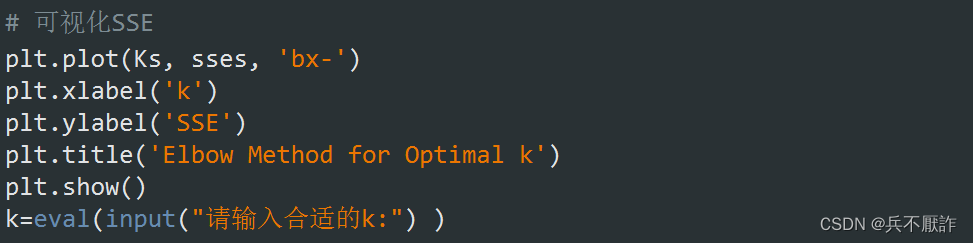
图7—手肘法可视化实现具体代码
4.数据集的导入与处理
4.1数据集的导入
由于我整个代码中没有使用pandas的dataframe数据结构,所以没有直接使用read_csv函数而是以普通打开csv文件的方式进行文件导入,下面我以鸢尾花数据集为例,首先打开观察鸢尾花数据集,发现它自带有表头,为了不让表头影响后续代码运行,使用next()函数,跳过表头,再使用列表推导式与map映射函数,按行将数据导入。
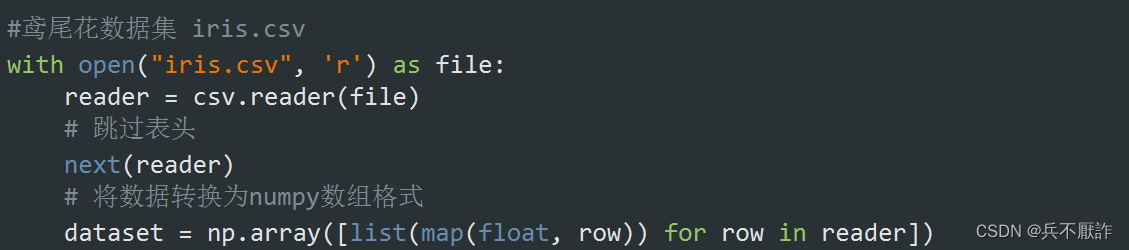
图8—数据集的导入具体代码
4.2数据集的降维处理
4.2.1降维处理的方法介绍
由于数据集中特征往往不止一种,而为了利用不同特征来帮助我们更好的聚类,我们通常使用PCA算法。主成分分析算法(PCA)是最常用的线性降维方法,它的目标是通过某种线性投影,将高维的数据映射到低维的空间中,并期望在所投影的维度上数据的信息量最大(方差最大),以此使用较少的数据维度,同时保留住较多的原数据点的特性。
4.2.1降维处理的实现
fit_transform()方法首先使用PCA拟合数据集,然后将数据集转换为新的2维表示。这样做的结果是一个新的NumPy数组,它的形状为(n_samples, 2),在许多情况下,将数据降维到二维可以用于可视化数据。例如,如果原始数据集是一个具有多个特征的图像数据集,则可以使用PCA将其降维到二维,
然后在二维平面上显示每个图像的投影。这样做可以帮助我们直观地理解数据集中的模式和结构。

图9—降维处理实现具体代码
5.聚类结果可视化
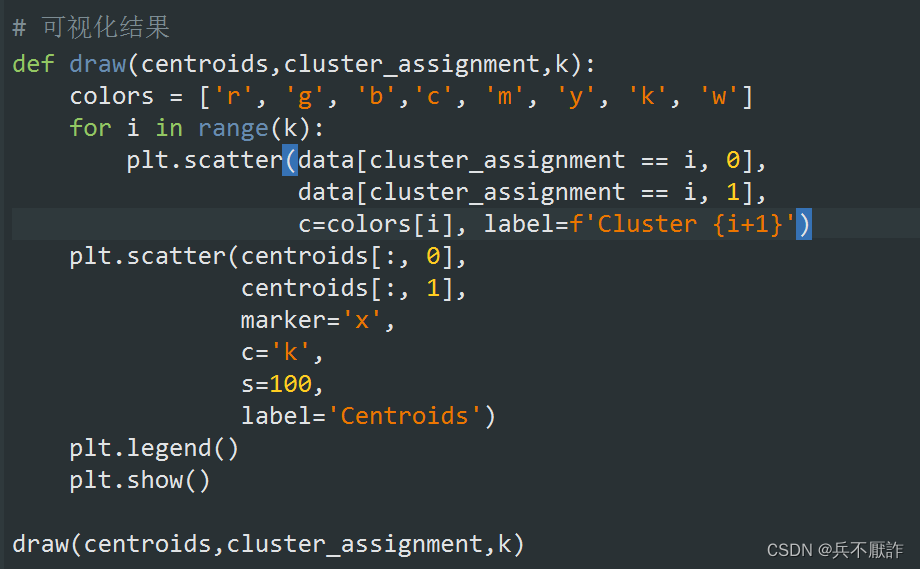
图10—聚类结果可视化实现具体代码
6.不足与待改进
6.1初始化
起始点的选取在一定程度上会影响最后的聚类效果,通过上网搜索相关文档发现,有K-Means++算法,二分K-Means算法等多种方法。
6.1.1K-Means++算法
在聚类中心的初始化过程中的基本原则是使得初始的聚类中心之间的相互距离尽可能远,这样可以避免出现上述的问题。K-Means++算法的初始化过程如下所示:
在数据集中随机选择一个样本点作为第一个初始化的聚类中心,选择出其余的聚类中心。计算样本中的每一个样本点与已经初始化的聚类中心之间的距离,记为d_i。选择一个新的数据点作为新的聚类中心,选择的原则是:距离较大的点,被选取作为聚类中心的概率较大。重复上述过程,直到k个聚类中心都被确定。
6.1.2二分K-Means算法
该算法首先将所有点作为一个簇,然后将该簇一分为二。之后选择其中一个簇继续进行划分,选择哪一个簇进行划分取决于对其划分时候可以最大程度降低 SSE(平方和误差)的值。上述基于 SSE 的划分过程不断重复,直到得到用户指定的簇数目为止。
6.2 距离计算
距离计算还可以通过曼哈顿距离,在处理特定问题时使用,这里没有涉及。
7.完整代码
- import numpy as np
- import matplotlib.pyplot as plt
- import csv
- from sklearn.decomposition import PCA
-
- def kmeans(data, k, max_iter=300):
- """
- kmeans算法实现
- 参数
- ----------
- data : numpy.ndarray
- 数据集,每一行为一个样本
- k : int
- 聚类的簇数
- max_iter : int, optional
- 最大迭代次数,默认为300
- 返回值
- -------
- centroids : numpy.ndarray
- k个聚类中心点的坐标
- cluster_assignment : numpy.ndarray
- 每个样本所属的簇的标签
- sse : float
- 聚类结果的SSE值
- """
- # 从数据中随机选择k个样本作为初始的聚类中心点
- centroids = data[np.random.choice(data.shape[0], k, replace=False)]
- # 初始化每个样本所属的簇的标签为-1
- cluster_assignment = -np.ones(data.shape[0], dtype=int)
- for i in range(max_iter):
- # 计算每个样本到k个聚类中心点的距离
- broad_centroids=centroids[:, np.newaxis]
- distances = np.sqrt(((data -broad_centroids )**2).sum(axis=2))
-
- # 通过最小距离确定每个样本所属的簇的标签
- new_cluster_assignment = np.argmin(distances, axis=0)
-
- # 如果聚类结果不再改变,则直接返回
- if np.array_equal(new_cluster_assignment, cluster_assignment):
- sse = ((data - centroids[new_cluster_assignment])**2).sum()
- return centroids, cluster_assignment, sse
-
- # 更新聚类中心点的坐标
- for j in range(k):
- centroids[j] = data[new_cluster_assignment == j].mean(axis=0)
-
- # 更新每个样本所属的簇的标签
- cluster_assignment = new_cluster_assignment
-
- sse = ((data - centroids[new_cluster_assignment])**2).sum()
- return centroids, cluster_assignment, sse
-
-
- # 导入数据
- #鸢尾花数据集
- with open("iris.csv", 'r') as file:
- reader = csv.reader(file)
- # 跳过表头
- next(reader)
- # 将数据转换为numpy数组格式
- dataset = np.array([list(map(float, row)) for row in reader])
-
-
-
- #降维处理
- def dimred(dataset):
- pca=PCA(n_components=2)
- data=pca.fit_transform(dataset)
- return data
-
- data=dimred(dataset)
-
- # 计算不同k值下的SSE值
- Ks = range(1, 11)
- sses = []
- for k in Ks:
- sse = kmeans(data, k)[2]
- sses.append(sse)
-
- # 可视化SSE
- plt.plot(Ks, sses, 'bx-')
- plt.xlabel('k')
- plt.ylabel('SSE')
- plt.title('Elbow Method for Optimal k')
- plt.show()
- k=eval(input("请输入合适的k:") )
-
- # 聚类
- centroids, cluster_assignment,see = kmeans(data, k)
-
- # 可视化结果
- def draw(centroids,cluster_assignment,k):
- colors = ['r', 'g', 'b','c', 'm', 'y', 'k', 'w']
- for i in range(k):
- plt.scatter(data[cluster_assignment == i, 0],
- data[cluster_assignment == i, 1],
- c=colors[i], label=f'Cluster {i+1}')
- plt.scatter(centroids[:, 0],
- centroids[:, 1],
- marker='x',
- c='k',
- s=100,
- label='Centroids')
- plt.legend()
- plt.show()
-
- draw(centroids,cluster_assignment,k)
8、结语
如果您觉得写的不错,不妨三连(怎么说也点赞)支持一下吧!

