
- 1PiflowX组件-OracleCdc
- 2机器学子之集成分类算法
- 3常用数学符号 _↑ⅰⅹ:1彳、::↑∴、ⅰⅰⅰ??∵ⅰ↓小{ⅰ氵!一。∞ⅰl↓1′1↖`:
- 440+岁老测试员的生涯回顾,Python自动化从业十年是种什么体验?_40岁从测试转it运维
- 5AutoGPT使用教程_autogpt怎么用
- 6字节跳动全链路压测(Rhino)的实践
- 7python 字符串模糊匹配 Fuzzywuzzy_fuzzy_wuzzy_wuzza_writer
- 8【2024】使用Rancher管理k8s集群和创建k8s集群
- 9云计算平台: Hadoop、Spark、Storm等开源框架与容器化技术的结合优化_spark云平台
- 102024年最新版快手直播推流码获取工具_快手推流码获取工具免费
#03 【chatglm】微调大模型的问题要放在哪个字段?四五个样本怎样让大模型记住?_instruction input output
赞
踩
公众号每天更新5条大模型问题及解决方案
今天,在【NLP学习群】中,一位同学一下问了2个问题,相信大家在微调时也会遇到这样的问题,自己问题应该放在instruction、input、output哪个字段,用什么格式去训练呢?只有四五个样本,怎样让大模型记住啊?
01 该放在哪个字段?
input 字段是用于存储输入文本的数据库字段,通常包含问题的文本。这些问题文本将作为模型的输入,模型将根据这些输入生成相应的输出。
output 字段通常包含模型的输出文本,这些输出文本是模型根据输入文本生成的回复。
instruction 字段通常用于存储指示模型生成输出的指令,例如,在问题后面加上一个冒号
看不懂吗?看一个示例的代码,你就懂了
Instruction :“输入一个描述人的句子,输出这个人的好坏”Input :“他经常扶老奶奶过马路”Output :“好人”02 只有几句话,怎样让大模型记住?
这需要用到“LoRA”来微调,这是一种高效的融入学习算法,也是我教得最多的微调方案,类似人类把新知识融入现有知识体系的学习过程。学习时无需新知识特别多的样本,学习后原有的庞大知识和能力可以基本不受影响。
准备数据
1,构造数据
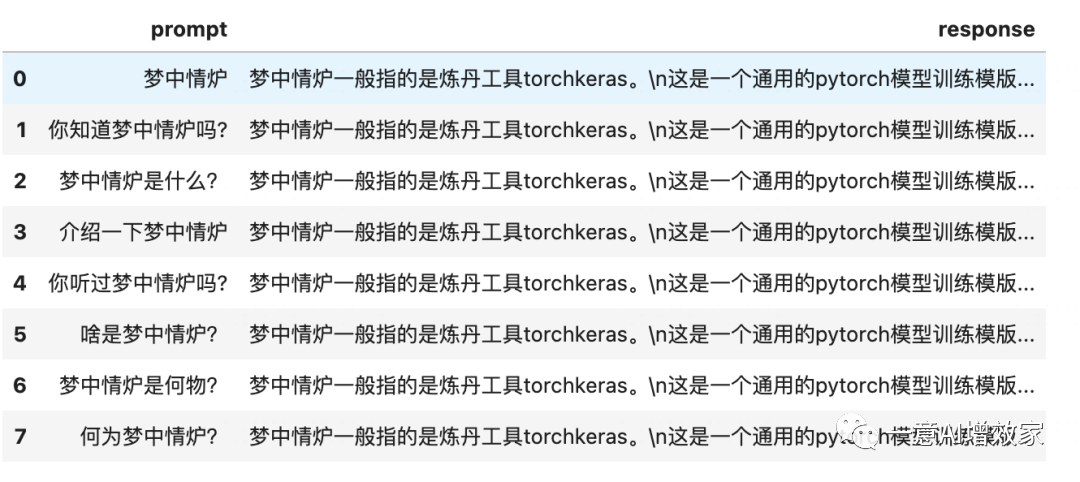
#定义一条知识样本~keyword = '梦中情炉'description = '''梦中情炉一般指的是炼丹工具torchkeras。这是一个通用的pytorch模型训练模版工具。torchkeras是一个三好炼丹炉:好看,好用,好改。她有torch的灵动,也有keras的优雅,并且她的美丽,无与伦比。所以她的作者一个有毅力的吃货给她取了一个别名叫做梦中情炉。'''#对prompt使用一些简单的数据增强的方法,以便更好地收敛。def get_prompt_list(keyword): return [f'{keyword}', f'你知道{keyword}吗?', f'{keyword}是什么?', f'介绍一下{keyword}', f'你听过{keyword}吗?', f'啥是{keyword}?', f'{keyword}是何物?', f'何为{keyword}?', ]data =[{'prompt':x,'response':description} for x in get_prompt_list(keyword) ]dfdata = pd.DataFrame(data)display(dfdata)
import datasets #训练集和验证集一样ds_train_raw = ds_val_raw = datasets.Dataset.from_pandas(dfdata)2,数据转换
#这是支持 history列处理,并且按照batch预处理数据的方法。 def preprocess(examples): max_seq_length = cfg.max_source_length + cfg.max_target_length model_inputs = { "input_ids": [], "labels": [], } for i in range(len(examples[cfg.prompt_column])): if examples[cfg.prompt_column][i] and examples[cfg.response_column][i]: query, answer = examples[cfg.prompt_column][i], examples[cfg.response_column][i] history = examples[cfg.history_column][i] if cfg.history_column is not None else None prompt = tokenizer.build_prompt(query, history) prompt = cfg.source_prefix + prompt a_ids = tokenizer.encode(text=prompt, add_special_tokens=True, truncation=True, max_length=cfg.max_source_length) b_ids = tokenizer.encode(text=answer, add_special_tokens=False, truncation=True, max_length=cfg.max_target_length) context_length = len(a_ids) input_ids = a_ids + b_ids + [tokenizer.eos_token_id] labels = [tokenizer.pad_token_id] * context_length + b_ids + [tokenizer.eos_token_id] pad_len = max_seq_length - len(input_ids) input_ids = input_ids + [tokenizer.pad_token_id] * pad_len labels = labels + [tokenizer.pad_token_id] * pad_len labels = [(l if l != tokenizer.pad_token_id else -100) for l in labels] model_inputs["input_ids"].append(input_ids) model_inputs["labels"].append(labels) return model_inputsds_train = ds_train_raw.map( preprocess, batched=True, num_proc=4, remove_columns=ds_train_raw.column_names) ds_val = ds_val_raw.map( preprocess, batched=True, num_proc=4, remove_columns=ds_val_raw.column_names)3,构建管道
data_collator = DataCollatorForSeq2Seq( tokenizer, model=None, label_pad_token_id=-100, pad_to_multiple_of=None, padding=False)dl_train = DataLoader(ds_train,batch_size = cfg.batch_size, num_workers = 2, shuffle = True, collate_fn = data_collator )dl_val = DataLoader(ds_val,batch_size = cfg.batch_size,num_workers = 2, shuffle = False, collate_fn = data_collator )for batch in dl_train: breakprint(len(dl_train))二,定义模型
下面我们使用AdaLoRA方法来微调ChatGLM2,以便给模型注入和梦中情炉 torchkeras相关的知识。
AdaLoRA是LoRA方法的一种升级版本,使用方法与LoRA基本一样。
主要差异在于,在LoRA中不同训练参数矩阵的秩是一样的被固定的。
但AdaLoRA中不同训练参数矩阵的秩是会在一定范围内自适应调整的,那些更重要的训练参数矩阵会分配到更高的秩。
通常认为,AdaLoRA的效果会好于LoRA。
from peft import get_peft_model, AdaLoraConfig, TaskType#训练时节约GPU占用model.config.use_cache=Falsemodel.supports_gradient_checkpointing = True #model.gradient_checkpointing_enable()model.enable_input_require_grads() peft_config = AdaLoraConfig( task_type=TaskType.CAUSAL_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1, target_modules=["query", "value"]) peft_model = get_peft_model(model, peft_config) peft_model.is_parallelizable = Truepeft_model.model_parallel = Truepeft_model.print_trainable_parameters()三,训练模型
我们使用我们的梦中情炉torchkeras来实现最优雅的训练循环~
注意这里,为了更加高效地保存和加载参数,我们覆盖了KerasModel中的load_ckpt和save_ckpt方法,
仅仅保存和加载可训练lora权重,这样可以避免加载和保存全部模型权重造成的存储问题。
from torchkeras import KerasModel from accelerate import Accelerator class StepRunner: def __init__(self, net, loss_fn, accelerator=None, stage = "train", metrics_dict = None, optimizer = None, lr_scheduler = None ): self.net,self.loss_fn,self.metrics_dict,self.stage = net,loss_fn,metrics_dict,stage self.optimizer,self.lr_scheduler = optimizer,lr_scheduler self.accelerator = accelerator if accelerator is not None else Accelerator() if self.stage=='train': self.net.train() else: self.net.eval() def __call__(self, batch): #loss with self.accelerator.autocast(): loss = self.net(input_ids=batch["input_ids"],labels=batch["labels"]).loss #backward() if self.optimizer is not None and self.stage=="train": self.accelerator.backward(loss) if self.accelerator.sync_gradients: self.accelerator.clip_grad_norm_(self.net.parameters(), 1.0) self.optimizer.step() if self.lr_scheduler is not None: self.lr_scheduler.step() self.optimizer.zero_grad() all_loss = self.accelerator.gather(loss).sum() #losses (or plain metrics that can be averaged) step_losses = {self.stage+"_loss":all_loss.item()} #metrics (stateful metrics) step_metrics = {} if self.stage=="train": if self.optimizer is not None: step_metrics['lr'] = self.optimizer.state_dict()['param_groups'][0]['lr'] else: step_metrics['lr'] = 0.0 return step_losses,step_metrics KerasModel.StepRunner = StepRunner #仅仅保存lora相关的可训练参数def save_ckpt(self, ckpt_path='checkpoint', accelerator = None): unwrap_net = accelerator.unwrap_model(self.net) unwrap_net.save_pretrained(ckpt_path) def load_ckpt(self, ckpt_path='checkpoint'): self.net = self.net.from_pretrained(self.net.base_model.model,ckpt_path) self.from_scratch = False KerasModel.save_ckpt = save_ckpt KerasModel.load_ckpt = load_ckptoptimizer = torch.optim.AdamW(peft_model.parameters(),lr=cfg.lr) keras_model = KerasModel(peft_model,loss_fn = None, optimizer=optimizer) ckpt_path = 'single_chatglm2'keras_model.fit(train_data = dl_train, val_data = dl_val, epochs=100, patience=20, monitor='val_loss', mode='min', ckpt_path = ckpt_path, mixed_precision='fp16', gradient_accumulation_steps = cfg.gradient_accumulation_steps )至此!问题解决!
因为设备、目标不同,如果你的问题还没解决,可以公众号后台回复“问答3000条”进群,有更多同学帮你,也可以点公众号里的有偿1对1!

一意AI增效家
AI领域学习伴侣、大模型训练搭档、企服AI产品安全认证、专家培训咨询、企服知识图谱、数字人搭建
公众号
目前一意AI提供的价值主要在四个方面!
#1 高质量数据集
我搭建了一个数据共享交换平台,目前已收录中文对话、金融、医疗、教育、儿童故事五个领域优质数据集,还可以通过会员之间共享,工众后台:“数据集”下载。
#2 报错或问题解决
你可能像我们NLP学习群中的同学一样,遇到各种报错或问题,我每天挑选5条比较有代表性的问题及解决方法贴出来,供大家避坑;每天更新,工众后台:“问答3000条”获清单汇总。
#3 运算加速
还有同学是几年前的老爷机/笔记本,或者希望大幅提升部署/微调模型的速度,我们应用了动态技术框架,大幅提升其运算效率(约40%),节省显存资源(最低无显卡2g内存也能提升),工众后台:“加速框架”;
#4 微调训练教程
如果你还不知道该怎么微调训练模型,我系统更新了训练和微调的实战知识库,跟着一步步做,你也能把大模型的知识真正应用到实处,产生价值。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

