
- 1Xcode真机调试不了,提示 “Please reconnect the device”_please check the device connection and ensure that
- 2C++显式调用析构函数问题一二_c++显式析构
- 3用win10主机telnet登录 win10虚拟机_telnet登录win10
- 4Linux下如何安装MySQL以及开放远程连接_linux mysql 开启远程
- 5从逆风飞扬到“攻守”平衡,Aruba谋定2023
- 6Python机器学习零基础理解K-means聚类_django viewset retrieve
- 7【前端】实现Vue组件页面跳转的多种方式_前端页面向下滑动时跳转另一个页面
- 8鸿蒙万能卡片实战系列课【李洋】(1-9)_原子化服务相对于传统应用的差异性包括?
- 9大厂技术面试中的手撕代码应该如何准备?_手撕代码不会怎么办
- 10七大排序算法(插排,希尔,选择排序,堆排,冒泡,快排,归并)--图文详解_希尔排序、冒泡排序、快速排序、归并排序思维导图
ES入门八:Mapping的详细讲解_es mapping
赞
踩
什么是Mapping?**Mapping定义了索引中的文档有哪些字段及其类型、这些字段是如何存储和索引的。**每个文档都是一个字段的集合,每个字段都有自己的数据类型,例如我们定义的books索引,其中有book_id、name等字段。所以Mapping的作用有:
- 定义索引中各个字段的名称和对应的类型
- 定义各个字段、倒排索引的相关设置。如使用某字段使用什么分词器等
PUT books
{
"mappings": {
"properties": {
"book_id": {
"type": "keyword"
},
"name": {
"type": "text",
"analyzer": "standard"
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
如上示例是我们定义了一个索引的Mapping例子,可以看到book_id的类型为keyword,而name的类型为text,并且name字段指定了分词器为standard
我们本篇的内容主要分为以下几点:
- 什么是Dynamic Mapping
- Mapping支持的基本数据类型有哪些
- 如何快速定义Mapping
- Mapping常用的参数有哪些
Dynamic Mapping
除了预先定义好Mapping外,如果写入文档时索引不存在的时候会自动创建索引,或者写入的字段不存在也会自动创建这个字段,官方把这个功能称之为 Dynamic Mapping。
动态索引的好处是使得我们无需手动定义Mapping,ES帮我们根据文档的信息自动推算出各个字段的信息。但是啊,推算的东西不一定准确的,很多时候并不是我们想要的东西。所以还是尽量自定义Mapping
# 在不存在的索引中写入一个文档 PUT test_mapping/_doc/1 { "name": "es", "count": 1 } # 使用下面指令查看其 Mapping 的结果 GET test_mapping/_mapping # Dynamic Mapping 产生的 Mapping 结果 { "test_mapping" : { "mappings" : { "properties" : { "count" : { "type" : "long" }, "name" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } } } } } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
Mapping支持的数据类型
Dynamic Mapping的功能可以自动推断字段的类型,这些类型都是ES支持的基本类型,这些类型主要有: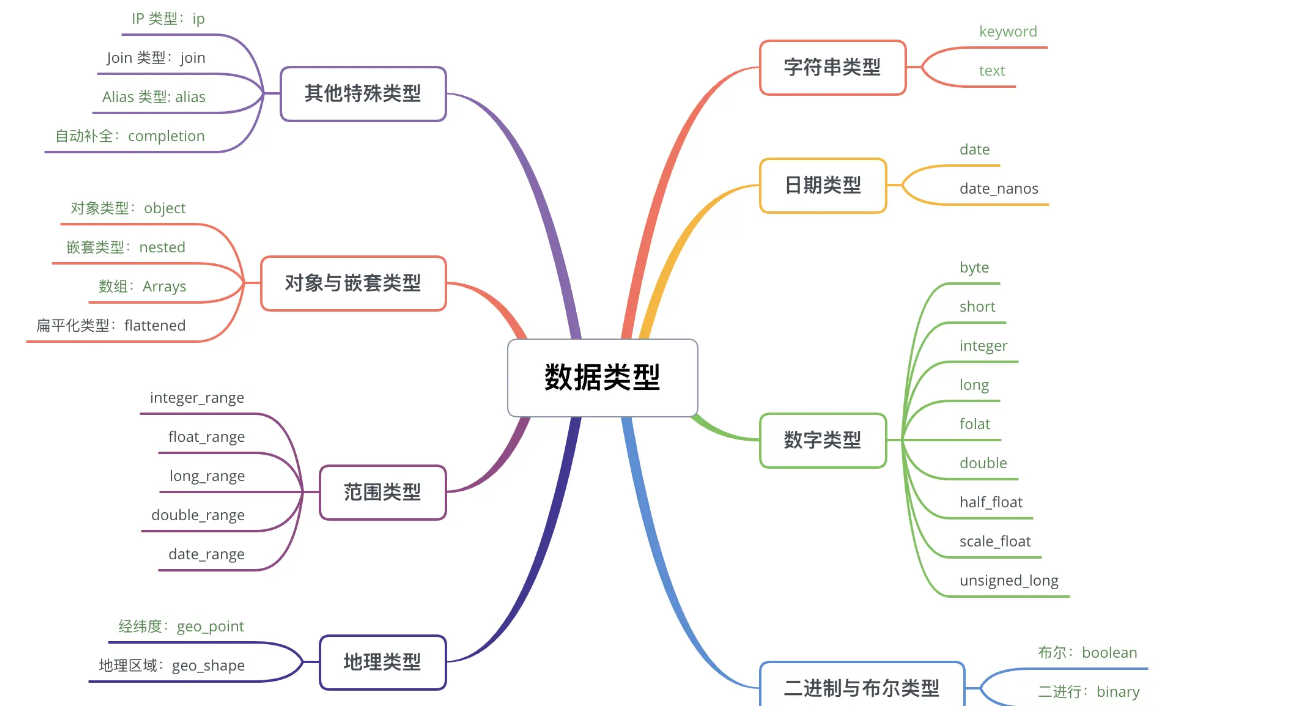
字符串
在7.x之后的版本中,字符串类型只有keyword和text两种,旧版本的string类型不再支持
- keyword类型适合存储简短、结构化的字符串,例如产品Id、产品名称等。它适合用于聚合、过滤、精确查询
- text类型的字段适合存储全文本数据,如短信内容,邮件内容等。text的类型数据将会被分词器进行分词,最终成为一个一个词项存储在倒排索引中
日期类型
我们知道JSON是没有热情类型的,所以其形式可以如下表示
- 字符串包含日期格式,例如:“2015-01-01” 或者 “2015/01/01 12:10:30”。
- 时间戳,以毫秒或者秒为单位
实际上,在底层ES都会把日期类型转换为UTC,并且作为毫秒形式的时间戳用一个long来存储
数字类型
数字类型分为byte、short、integer、long、float、double、half_float、scaled_float、unsigned_long
在需求满足的条件下,应当选择尽可能小的数据类型,除了可能会减少存储空间外,也会提高索引数据和检索数据的效率
对象和嵌套类型
我们的数据很多时候都需要用到数组和对象、嵌套类型等复杂数据类型来表示的,例如书本作者可以有多个,这个作者字段就需要保存为一个数组。
下面来介绍一下对象和数组,至于嵌套对象,后面会讲
对象
JSON中是可以嵌套对象的,保存对象类型可以用object类型,但实际上在ES中会讲原JSON文档扁平化存储的,加入作者字段是一个对象,那么可以表示为:
{
"author": {
"first":"zhang",
"last":"san"
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
实际在存储的时候,ES在存储的时候会转换为以下格式:
{
"author.first": "zhang",
"author.last": "san"
}
- 1
- 2
- 3
- 4
- 5
数组
对于数组来说,ES并没有定义关键字来表示一个字段为数组类型。默认情况下,**任何一个字段都可以包含0个或多个值,只需要这些值是相同的数据类型。**所以我们在创建数据的时候可以直接写入数组类型:
PUT books/_doc/3
{
"author": ["Neil Matthew","Richard Stones"],
}
- 1
- 2
- 3
- 4
- 5
快速自定义Mapping
前面我们提到最好不要用Dynamic Mapping来生成Mapping,但是如果Mapping拥有的字段非常多的时候,自定义Mapping是非常痛苦的并且容易出错。那有没有办法减轻一下我们的工作量哪?
我们可以把JSON对象直接写入,利用Dynamic Mapping的特性帮我们生成一个初步可用的Mapping,然后我们修改这个 Mapping来直到满足我们的需求。
大概的步骤如下:
- 创建临时索引,并写入业务数据
- 获取这个临时索引的Mapping
- 根据业务场景,完善这个Mapping。如对某些字段定义的分词器等
- 完成后删除临时的索引,并创建符合需求的索引
我们在使用Dynamic Mapping的时候,JSON文档的字段类似会自动转换为ES的类型,下面是对照表:
Mapping的常用参数
Mapping参数可以用来控制某个字段的特性。例如这个字段是否被索引、用什么分词器、空值是否可以被搜索到等。Mapping提供的参数有很多,我们看看常见的几个:index、analyzer、dynamic、null_value、copy_to
index
当某个字段不想被索引或者查询的时候,可以用index参数来进行控制,其接受的值为true或者false。使用示例如下:
PUT index_param_index
{
"mappings": {
"properties": {
"name": {
"type": "text",
"index": false # name 字段不进行索引操作
},
"address": { "type": "text" }
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
analyzer
这个参数其实我们用过多次了,它是用来指定使用哪个分词器的
当我们进行全文本搜索的时候,会将检索的内容先进行分词,然后在进行匹配。默认情况下,检索的内容使用的分词器和与字段指定的分词器是一致的,但如果设置了search_analyzer,检索内容使用的分词器将与search_analyzer设定的一致。其使用示例如下:
PUT analyzer_index
{
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "simple",
"search_analyzer": "standard"
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
dynamic
可以在文档和对象级别对Dynamic Mapping进行控制,刚刚在Dynamic Mapping一节的内容中介绍过dynamic属性对文档级别的影响了,现在结合文档和对象级别来一个示例:
PUT dynamic_index { "mappings": { "dynamic": "strict", # 1,文档级别,表示文档不能动态添加 top 级别的字段 "properties": { "author": { # 2,author 对象继承了文档级别的设置。 "properties": { "address": { "dynamic": "true", # 3,表示 address 对象可以动态添加字段 "properties":{} }, "country": { "properties":{} } } } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- dynamic:strict,如果写入不存在的字段,文档数据写入会失败。其中author对象没有设置dynamic属性,其将会继承top级别的dynamic设置,也就是说author必须有
- author.address对象级别中也设置了dynamic属性为true,其效果address对象可以动态添加字段
null_value
如果需要对null值实现搜索的时候,需要设置字段的null_value参数。null_value参数默认值为null,其允许用户使用指定值替换控制,以便它可以索引和搜索
需要注意的是,**null_value只决定数据是如何索引的,不影响_source的内容,并且null_value的值的类型需要与字段的类型一致。**例如一个long字段的字段,其null_value的值不能为空字符串。使用“NULL”显示值来代替null,使用示例如下:
# 创建索引 PUT null_value_index { "mappings": { "properties": { "id": { "type": "keyword" }, "email": { "type": "keyword", "null_value": "NULL" # 使用 "NULL" 显式值 } } } } # 插入数据 PUT null_value_index/_doc/1 { "id": "1", "email": null } # 查询空值数据 GET null_value_index/_search { "query": { "term": { "email": "NULL" } # 使用显式值来查询空值的文档 } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
copy_to
copy_to参数允许用户复制多个字段的值到目标字段,这个字段可以像单个字段那样呗查询。其示例如下:
# 创建索引 PUT users { "mappings": { "properties": { "first_name": { "type": "text", "copy_to": "full_name" }, "last_name": { "type": "text", "copy_to": "full_name" }, "full_name": { "type": "text" } } } } # 插入数据 PUT users/_doc/1 { "first_name": "zhang", "last_name": "san" } # 查询 GET users/_search { "query": { "match": { "full_name": { "query": "zhang san", "operator": "and" } } } } # 结果 { "hits" : { "hits" : [ { "_source" : { "first_name" : "zhang", "last_name" : "san" } } ] } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52

