
- 1自己再造一个大规模预训练语言模型?可以的_自建大语言模型的可能性
- 2一致性算法—Paxos算法原理与推导_主题一致性计算原理
- 3聊天机器人框架Rasa资源整理_rasa nlu 预料数据下载
- 4Kafka注册中心:揭秘分布式系统的核心协调者(二)
- 5Selenium的加载策略_selenium 加载策略
- 6设计模式——结构型模式简单介绍
- 7两道逆向题分析总结_if ( (v16 & 2147483648) == 0 ) { v18 = v16; v19 =
- 8superset详解(二)--sql工具箱_superset sql传参
- 9Linux安装R以及依赖库出现的一些问题及解决方法_> devtools::install_github('taiyun/recharts')downl
- 10pycharm下载opencv库
大数据从入门到实战 - Spark的安装与使用_第1关:scala语言开发环境的部署
赞
踩
叮嘟!这里是小啊呜的学习课程资料整理。好记性不如烂笔头,今天也是努力进步的一天。一起加油进阶吧!

一、关于此次实践
1、实战简介
随着大数据时代的到来,各行各业的工作者都迫切需要更好更快的数据计算与分析工具,2009年,Spark应运而生,在很短的时间里就崭露头角,受到了业界的广泛肯定与欢迎,如今已是Apache软件基金会会下的顶级开源项目之一。相较于曾经引爆大数据产业革命的Hadoop MapReduce框架,Spark带来的改进更加令人欢欣鼓舞。
首先,基于内存计算的Spark速度更快,减少了迭代计算时的IO开销,而且支持交互性使用,其次。Spark丰富的API提供了更强大的易用性,它支持使用Scala、Java、Python与R语言进行编程,有助于开发者轻松构建并行的应用程序。而且,Spark支持多种运行模式,既可以运行于独立的集群模式或Hadoop集群模式中,也可以运行在云星宇Amazon EC2等云环境中。
还等什么呢,赶紧开始学习Spark吧。
2、全部任务

二、实践详解
1、第1关:Scala语言开发环境的部署

任务描述
本关任务:安装与配置Scala开发环境。
相关知识
Scala是一种函数式面向对象语言,它融汇了许多前所未有的特性,而同时又运行于JVM之上。随着开发者对Scala的兴趣日增,以及越来越多的工具支持,无疑Scala语言将成为你手上一件必不可少的工具。
而我们将要学习的大数据框架Spark底层是使用Scala开发的,使用scala写出的代码长度是使用java写出的代码长度的1/10左右,代码实现更加简练。
所以安装与配置Scala的环境是我们在开始学习Spark之前要完成的准备工作。
接下来我们开始安装,分为三个步骤:
下载解压;
配置环境;
校验。
- 1
- 2
- 3
下载解压
在Scala官网根据平台选择下载Scala的安装包,

接下来,解压到/app目录下:
mkdir /app //创建 app 目录
tar -zxvf scala-2.12.7.tgz -C /app
- 1
- 2
提示:在平台已经将解压包下载在/opt目录下了,就不需要再从网络下载了。
配置环境
接下来我们开始配置环境,在自己本机上需要配置好Java环境,因为Scala是基于jvm的(在平台已经将Java环境配置好了):
vi /etc/profile
- 1

不要忘了配置好之后source /etc/profile
校验
- 1
在命令行输入:scala -version出现如下结果就配置成功了

按照惯例,我们在开始一个编程语言要进行一个仪式,哈哈,那就是,Hello World,接下来我们使用Scala输出Hello World:
在命令行中输入scala进入Scala命令行,输入println("Hello World") 就可以啦。


2、第2关:安装与配置Spark开发环境

任务描述
本关任务:安装与配置Spark开发环境。
相关知识
Apache Spark是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab(加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
本关我们来配置一个伪分布式的Spark开发环境,与配置Hadoop类似分为三个步骤:
下载解压安装包;
配置环境变量;
配置Spark环境;
校验。
- 1
- 2
- 3
- 4
下载解压安装包
我们从官网下载好安装包,


接下来解压,在平台已经将spark安装包下载到/opt目录下了,所以不需要再下载了。
tar -zxvf spark-2.2.2-bin-hadoop2.7.tgz -C /app
- 1
将压缩包解压到/app目录下。
配置环境变量
我们将spark的根目录配置到/etc/profile中(在文件末尾添加)。
vim /etc/profile
- 1
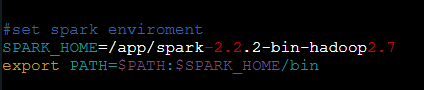
不要忘了source /etc/profile
修改Spark配置文件
切换到conf目录下:
cd /app/spark-2.2.2-bin-hadoop2.7/conf
- 1
在这里我们需要配置的是spark-env.sh文件,但是查看目录下文件只发现一个spark-env.sh.template文件,我们使用命令复制该文件并重命名为spark-env.sh即可;

接下来编辑spark-env.sh,在文件末尾添加如下配置:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_111
export SCALA_HOME=/app/scala-2.12.7
export HADOOP_HOME=/usr/local/hadoop/
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_MASTER_IP=machine_name # machine_name 根据自己的主机确定
export SPARK_LOCAL_IP=machine_name # machine_name 根据自己的主机确定
- 1
- 2
- 3
- 4
- 5
- 6
参数解释:

如何查看机器名/主机名呢?
很简单,在命令行输入:hostname即可。
校验
最后我们需要校验是否安装配置成功了;
现在我们启动spark并且运行spark自带的demo:
首先我们在spark根目录下启动spark:
在spark的根目录下输入命令./sbin/start-all.sh即可启动,使用jps命令查看是否启动成功,有woker和master节点代表启动成功。

接下来运行demo:
- 在Spark根目录使用命令
./bin/run-example SparkPi > SparkOutput.txt运行示例程序 - 在运行的时候我们可以发现打印了很多日志,最后我们使用cat SparkOutput.txt可以查看计算结果(计算是有误差的所以每次结果会不一样):
好了,如果你能到这一步就已经完成了伪分布式Spark的安装啦。

Ending!
更多课程知识学习记录随后再来吧!
就酱,嘎啦!
- 1

注:
人生在勤,不索何获。

