
- 1myCobot pro 机械臂(6)逆向运动学_机械臂逆运动学
- 2Flink CDC 整库 / 多表同步至 Kafka 方案(附源码)_cdckafka
- 3Your branch and 'origin/master' have diverged, and have # and # different commits each, respectively
- 4python实现Android实时投屏操控_scrcpy投屏python
- 5职场生存法则和处世之道_职场处事之道
- 6《从零开始学python+自然语言处理100题》——给自己的记录_自然语言处理100练
- 7【深度学习图像识别课程】keras实现CNN系列:(7)迁移学习的原理和应用_机器学习、迁移学习和cnn
- 8windows版redis_redis windows
- 9分布式学习-总结
- 10图像分割实战-系列教程2:Unet系列算法(Unet、Unet++、Unet+++、网络架构、损失计算方法)
Grafana技术实践V1.0_grafana vega
赞
踩
文章目录
1 GRAFANA简述
Grafana是一款采用 go 语言编写的开源应用,主要用于大规模指标数据的可视化展现,是网络架构和应用分析中最流行的时序数据展示工具,目前已经支持绝大部分常用的时序数据库
Grafana支持许多不同的数据源。每个数据源都有一个特定的查询编辑器,该编辑器定制的特性和功能是公开的特定数据来源。 官方支持的数据源有153种,其中比较引人注目的是Json、HTML、Durid、ClickHouse、Cloudera Manager、Mysql、ElasticSearch、SQLservice (sorry 是我只认识这几种)。

1.1 GRAFANA的特点
Grafana的主要特点
①可视化:快速和灵活的客户端图形具有多种选项。面板插件为许多不同的方式可视化指标和日志。
②报警:可视化地为最重要的指标定义警报规则。Grafana将持续评估它们,并发送通知。
③通知:警报更改状态时,它会发出通知。接收电子邮件通知。
④动态仪表盘:使用模板变量创建动态和可重用的仪表板,这些模板变量作为下拉菜单出现在仪表板顶部。
⑤混合数据源:在同一个图中混合不同的数据源!可以根据每个查询指定数据源。这甚至适用于自定义数据源。
⑥注释:注释来自不同数据源图表。将鼠标悬停在事件上可以显示完整的事件元数据和标记。
⑦过滤器:过滤器允许您动态创建新的键/值过滤器,这些过滤器将自动应用于使用该数据源的所有查询
1.2 GRAFANA的组件介绍
DashBoard:仪表盘,就像汽车仪表盘一样可以展示很多信息,包括车速,水箱温度等。Grafana的DashBoard就是以各种图形的方式来展示从Datasource拿到的数据。
Row:行,DashBoard的基本组成单元,一个DashBoard可以包含很多个row。一个row可以展示一种信息或者多种信息的组合,比如系统内存使用率,CPU五分钟及十分钟平均负载等。所以在一个DashBoard上可以集中展示很多内容。
Panel:面板,实际上就是row展示信息的方式,支持表格(table),列表(alert list),热图(Heatmap)等多种方式,具体可以去官网上查阅。
Query Editor:查询编辑器,用来指定获取哪一部分数据。类似于sql查询语句,比如你要在某个row里面展示test这张表的数据,那么Query Editor里面就可以写成select *from test。这只是一种比方,实际上每个DataSource获取数据的方式都不一样,所以写法也不一样(http://docs.grafana.org/features/datasources/),比如像zabbix,数据是以指定某个监控项的方式来获取的。
Organization:组织,org是一个很大的概念,每个用户可以拥有多个org,grafana有一个默认的main org。用户登录后可以在不同的org之间切换,前提是该用户拥有多个org。不同的org之间完全不一样,包括datasource,dashboard等都不一样。创建一个org就相当于开了一个全新的视图,所有的datasource,dashboard等都要再重新开始创建。
User:用户,这个概念应该很简单,不用多说。Grafana里面用户有三种角色admin,editor,viewer。admin权限最高,可以执行任何操作,包括创建用户,新增Datasource,创建DashBoard。editor角色不可以创建用户,不可以新增Datasource,可以创建DashBoard。viewer角色仅可以查看DashBoard。在2.1版本及之后新增了一种角色read only editor(只读编辑模式),这种模式允许用户修改DashBoard,但是不允许保存。每个user可以拥有多个organization。
1.3 GRAFANA的界面功能介绍

1侧面菜单切换:切换侧边菜单,允许您专注于仪表盘中显示的数据。侧面菜单提供对与仪表盘无关的功能(如用户,组织和数据源)的访问。
2信息中心下拉菜单:此下拉菜单显示您当前正在查看的信息中心,并允许您轻松切换到新的信息中心。从这里,您还可以创建新的信息中心,导入现有的信息中心和管理信息中心播放列表。
3星型仪表盘:对当前仪表盘执行星号(或取消星标)。加星标的信息中心在默认情况下会显示在您自己的主页信息中心上,并且是标记您感兴趣的信息中心的便捷方式。
4共享仪表盘:通过创建链接或创建其静态快照来共享当前仪表盘。在共享前确保信息中心已保存。
5保存仪表盘:当前仪表盘将与当前仪表盘名称一起保存。
6设置:管理仪表盘设置和功能,如模板和注释
1.4 GRAFANA各个实例通信网络端口
| 端口名称 | 默认端口 | 说明 |
|---|---|---|
| elasticsearch.http.port | 9200 | elasticsearch Web端口 |
| kibana.server.port | 5601 | kibana Web端口 |
| mysql | 3306 | mysql连接端口 |
| kafka | 9092 | kafka端口 |
| zookeeper | 2181 | zookeeper端口 |
| grafana | 3000 | grafana的Web端口) |
| confluent | 8082 | conluent代理端口 |
| kafka_exporter | 9308 | kafka_exporter的端口 |
2 GRAFANA部署
2.1 中间件版本选取
| 中间件名称 | 版本号 |
|---|---|
| CentOS | CentOS 7 |
| Java | 1.8.0_121 |
| ElasticSearch | elasticsearch-6.3.1 |
| Kibana | kibana-6.3.1 |
| zookeeper | zookeeper-3.5.7 |
| mysql | 5.7.28 |
| kafka | 2.3.1 |
| confluent | 4.0.0 |
| prometheus | 2.9.2 |
| kafka_exporter | 1.2.0 |
2.2 环境准备
Grafana主要是做数据质量。因为不属于Apache的小弟所以依赖并不严重。需要安装zookeeper、kafka、confluent、ElasticSearch、kibana、mysql在案例中使用。
zookeeper:节点管理
kafka:实现kafka+grafana数据管理
confluent:kafka的代理,集成kafka、zookeeper
ELasticSearch:实现ElasticSearch+grafana数据管理
Kibana:ElasticSearch的可视化
mysql:mysql+grafana实现数据管理
2.2.1 CentOS 7
CentOS 7安过程省略。预先创建用户/用户组zhouchen
预先安装jdk1.8.0_121 +
预先安装zookeeper
预先安装kafka
预先安装ElasticSearch
预先安装Kibana
预先安装Mysql
2.2.2 关闭防火墙-root
1.查看防火墙状态
firewall-cmd --state
2.停止firewall
systemctl stop firewalld.service
3.禁止firewall开机启动
systemctl disable firewalld.service
- 1
- 2
- 3
- 4
- 5
- 6
2.3 安装CONFLUENT
Confluent是kafka的集成平台,可以看做是类似CDH。使用Confluent会集成zookeeper与kafka,当然也可以单独安装kafka与zookeeper。这里我采用的方式是直接安装集成的confluent。
2.3.1 解压安装包
[zhouchen@hadoop202 software]$ tar -zxvf confluent-oss-4.0.0-2.11.tar.gz.1 -C /opt/module
- 1
2.3.2 修改confluent中关于kafka和zookeeper的配置
[zhouchen@hadoop202 software]$ cd /opt/module/confluent-4.0.0/etc/kafka
[zhouchen@hadoop202 software]$ vim consumer.properties
#修改的内容如下:
bootstrap.servers=hadoop202:9092,hadoop203:9092,hadoop204:9092
- 1
- 2
- 3
- 4
[zhouchen@hadoop202 software]$ vim producer.properties
#修改的内容如下:
bootstrap.servers=hadoop202:9092,hadoop203:9092,hadoop204:9092
- 1
- 2
- 3
[zhouchen@hadoop202 software]$ vim server.properties
#修改的内容如下:
#broker.id listeners按照本机修改
#Kafka的节点名,唯一不可重复
broker.id=0
#Kafka的监听地址,由于当前host一致
listeners=PLAINTEXT://hadoop202:9092
#kafka中配置的日志位置
log.dirs=/opt/module/kafka-2.3.1/logs
#kafka中配置的zookeeper的地址
zookeeper.connect=hadoop202:2181,hadoop203:2181,hadoop204:2181
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
[zhouchen@hadoop202 software]$ vim zookeeper.properties #修改的内容如下: #zookeeper中配置的目录位置 dataDir=/opt/module/zookeeper-3.5.7/zkData # the port at which the clients will connect clientPort=2181 # disable the per-ip limit on the number of connections since this is a non-production config maxClientCnxns=60 # The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # The number of snapshots to retain in dataDir autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature autopurge.purgeInterval=24 #######################cluster########################## server.2=hadoop202:2888:3888 server.3=hadoop203:2888:3888 server.4=hadoop204:2888:3888

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
2.3.3 修改confluent中代理配置
[zhouchen@hadoop202 opt]$ cd /opt/module/confluent-4.0.0/etc/kafka-rest
[zhouchen@hadoop202 kafka-rest]$ vim kafka-rest.properties
#修改的内容如下:
#代理的kafka的信息
bootstrap.servers=PLAINTEXT://hadoop202:9092
bootstrap.servers=PLAINTEXT://hadoop202:9092,PLAINTEXT://hadoop203:9092,PLAINTEXT://hadoop204:9092
- 1
- 2
- 3
- 4
- 5
- 6
2.3.4 分发目录
[zhouchen@hadoop202 module]$ xsync confluent-4.0.0/
- 1
2.3.5 修改剩余节点配置中的节点名称与监听
hadoop203
[zhouchen@hadoop203 software]$ vim server.properties
#修改的内容如下:
broker.id=1
listeners=PLAINTEXT://hadoop203:9092
- 1
- 2
- 3
- 4
hadoop204
[zhouchen@hadoop204 software]$ vim server.properties
#修改的内容如下:
broker.id=2
listeners=PLAINTEXT://hadoop204:9092
- 1
- 2
- 3
- 4
2.3.6 启动服务
(注意顺序不能颠倒;关闭的时候倒序关闭)
1.启动zookeeper
[zhouchen@hadoop202 module]$ nohup ${CONFLUENT_HOME}/bin/zookeeper-server-start ${CONFLUENT_HOME}/etc/kafka/zookeeper.properties >/dev/null 2>&1 &
- 1
2.启动kafka
[zhouchen@hadoop202 module]$ nohup ${CONFLUENT_HOME}/bin/kafka-server-start ${CONFLUENT_HOME}/etc/kafka/server.properties >/dev/null 2>&1 &
- 1
3.启动kafka-rest
[zhouchen@hadoop202 module]$ nohup ${CONFLUENT_HOME}/bin/kafka-rest-start ${CONFLUENT_HOME}/etc/kafka/server.properties >/dev/null 2>&1 &
- 1
2.3.7 查看进程
[zhouchen@hadoop203 confluent-4.0.0]$ xcall jps
- 1

2.4 KAFKA_EXPORTER安装
1.下载安装包
wget https://github.com/danielqsj/kafka_exporter/releases/download/v1.2.0/kafka_exporter-1.2.0.linux-amd64.tar.gz
- 1
2.解压
tar -zxvf kafka_exporter-1.2.0.linux-amd64.tar.gz
- 1
3.启动
./kafka_exporter
- 1
2.5 PROMETHEUS安装
1.下载安装包
下载地址:https://prometheus.io/download/
或者直接在CentOS执行:
wget -c https://github.com/prometheus/prometheus/releases/download/v2.9.2/prometheus-2.9.2.linux-amd64.tar.gz
- 1
2.解压
[zhouchen@hadoop203 software]$ tar -zxvf prometheus-2.9.2.linux-amd64.tar.gz -C /opt/module/
- 1
3.修改配置
[zhouchen@hadoop202 module]$ mv prometheus-2.9.2.linux-amd64/ prometheus-2.9.2
[zhouchen@hadoop202 prometheus-2.9.2]$ vim prometheus.yml
#修改的内容见红字:
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['hadoop202:9090']
- job_name: 'kafka'
static_configs:
- targets: ['hadoop202:9308']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
4.界面登录
http://hadoop202:9090

2.6 GRAFANA安装
1.下载包
[zhouchen@hadoop202 software]$ wget https://dl.grafana.com/oss/release/grafana-7.0.3-1.x86_64.rpm
- 1
2.安装包
[zhouchen@hadoop202 software]$ sudo yum install grafana-7.0.3-1.x86_64.rpm
- 1
3.配置服务在启动时启动(root执行)
[zhouchen@hadoop202 software]$ sudo systemctl enable grafana-server.service
- 1
4.启动服务(root执行)
[root@hadoop202 software]# systemctl start grafana-server
[root@hadoop202 software]# systemctl status grafana-server
- 1
- 2
2.6.1 Grafana修改登录密码
1.查找grafana.db文件
[root@hadoop202 /]# find / -name "grafana.db"
/var/lib/grafana/grafana.db
- 1
- 2
2.使用sqlite3加载数据库文件
[root@hadoop202 /]# sqlite3 /var/lib/grafana/grafana.db
- 1
3.对密码还原
sqlite> .tables
sqlite> select * from user;
sqlite> update user set password = '59acf18b94d7eb0694c61e60ce44c110c7a683ac6a8f09580d626f90f4a242000746579358d77dd9e570e83fa24faa88a8a6', salt = 'F3FAxVm33R' where login = 'admin';
- 1
- 2
- 3
#此时的用户密码都是admin
2.6.2 界面登录grafana
http://hadoop202:3000

3 GRAFANA+CONFLUENT实现KFAKA提醒
界面配置如下:

-
选择类型为Kafka REST Proxy
-
Kafka REST Proxy地址为http://hadoop202:8082;直接浏览器登陆http://hadoop202:8082/topics 可以查看有哪些topic。
-
点击send test按钮,可以发送报警测试
-
消费对应的topic,检查测试
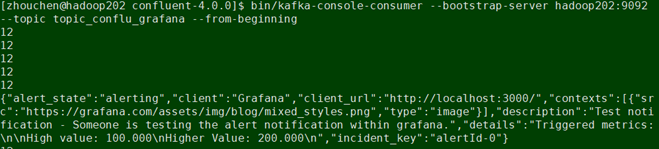
4 GRAFANA+PROMETHEUS+KAFKA_EXPOETER实现KAFKA监控
4.1 查看JOB状态

这里的hadoop202:9308是指Kafka_expoeter的端口,而kafka_exporter启动的时候监听的是hadoop202:9092
4.2 配置GRAFANA
1.添加prometheus为数据源

2.加载仪表盘模板


3.查看仪表盘性能指标

5 GRAFANA常用场景
在grafana使用完之后,感觉这个中间件就是作为集群监控的,而不是作为数据监控的。它所指的支持众多数据源是指能监控其他插件的性能。
在使用grafana之后的感受就是,依赖严重,包括监控仪表盘需要导入或者二次开发编写json。
网上还有其他的实现案例这里就不一一去实现了:
https://www.cnblogs.com/caoweixiong/category/1622389.html
这里包含十几种Grafana+Prometheus去监控其他中间件的案例
Prometheus + Grafana(三)nginx 设置反向代理
Prometheus + Grafana(四)系统监控之钉钉预警
Prometheus + Grafana(五)系统监控之Linux服务器
Prometheus + Grafana(六)系统监控之MySql
Prometheus + Grafana(七)系统监控之Redis
Prometheus + Grafana(八)系统监控之Kafka
Prometheus + Grafana(九)系统监控之RabbitMQ
Prometheus + Grafana(十)系统监控之Elasticsearch
Prometheus + Grafana(十一)系统监控之HBase
Prometheus + Grafana(十二)系统监控之Spark
Prometheus + Grafana(十三)系统监控之Cassandra
Prometheus + Grafana(十四)系统监控之Canal
6 GRAFANA常见问题分析
6.1 界面登录失败,密码错误
首次登录会出现不知道用户密码的情况(用户名密码在配置信息里)
解决:
根据2.4.1修改grafana用户名密码

