
- 1若依框架请求访问:/xxxx/xxxxx,认证失败,无法访问系统资源_若依 认证失败,无法访问系统资源
- 2回溯算法(递归)_int test(int x){return (x==1)?1:(x+test(x-1))}
- 3【GitHub项目推荐--远程桌面软件】【转载】_开源远程控制软件 github
- 42023世界人工智能大会-图技术高峰论坛重磅来袭!邀您共同参与!_2023年世界人工智能大会论坛
- 5STM32 标准库+ESP8266+华为云物联网平台_stm32通过esp8266上传数据到云平台
- 6git仓库迁移_git mirror bare
- 7无法访问hadoop yarn8088端口的解决方法_hadoop集群访问不了yarn网页
- 8Spark SQL ---结构化数据文件处理
- 9C++求点到线段和任意曲线的最短距离_c语言 点 到 曲线 的 距离 代码
- 10Ubuntu 安装和使用MySQL_ubuntu mysql
网传Llama 3比肩GPT-4?别闹了_llama3和gpt
赞
踩
相信大家近期都被Llama 3刷屏了。Llama 3的预训练数据达到了15万亿,是Llama 2的7倍;微调数据用了100万条人工标注数据,是Llama 2的10倍。
足以看出Meta训练Llama 3 是下了大血本的。开源社区拥抱Llama3也是空前热烈,发布才4天Hugging Face上已经出现了1000多个Llama 3的变体,现在也就不到一周,数字已经飙升到了3600多个了。
与此同时,网络上的声音也多了起来:
有讽刺说国内马上遍地自研GPT-4的; 有被Llama 3 一秒800 tokens的生成速度惊到的;
GPT-3.5研究测试:
https://hujiaoai.cn
GPT-4研究测试:
https://higpt4.cn
Claude-3研究测试(全面吊打GPT-4):
https://hiclaude3.com
但还有一大波人在狂吹Llama 3达到了GPT-4级别。最近刷到的这类文章数不胜数,知乎上随手一搜:



Llama 3的发布,虽然意义非凡。但是近期相当多的大小媒体在未经评测的情况下就开始“造神“了。
不可否认的是Llama 3 70B确实是开源线的里程碑,表现惊艳。但笔者用了一段时间后,对其比肩GPT-4这个结论存疑。
就在几天前,笔者终于等来了清华大学SuperBench团队的新一轮全球大模型评测结果。而且SuperBench团队不负众望,在这次评测中加测了Llama 3-8b 和Llama 3-70b两个模型,率先发布了 Llama 3的最全的评测成绩。
SuperBench是由清华大学牵头发布的大模型综合能力评测平台,集齐了语义、对齐、代码、安全和智能体5大评测基准,相比国外主流榜单,SuperBench以中文能力评价为主,对国人的现实参考意义可能比国外学术界的主流榜单都要大。
我们来一起看下这一轮的测评结果:
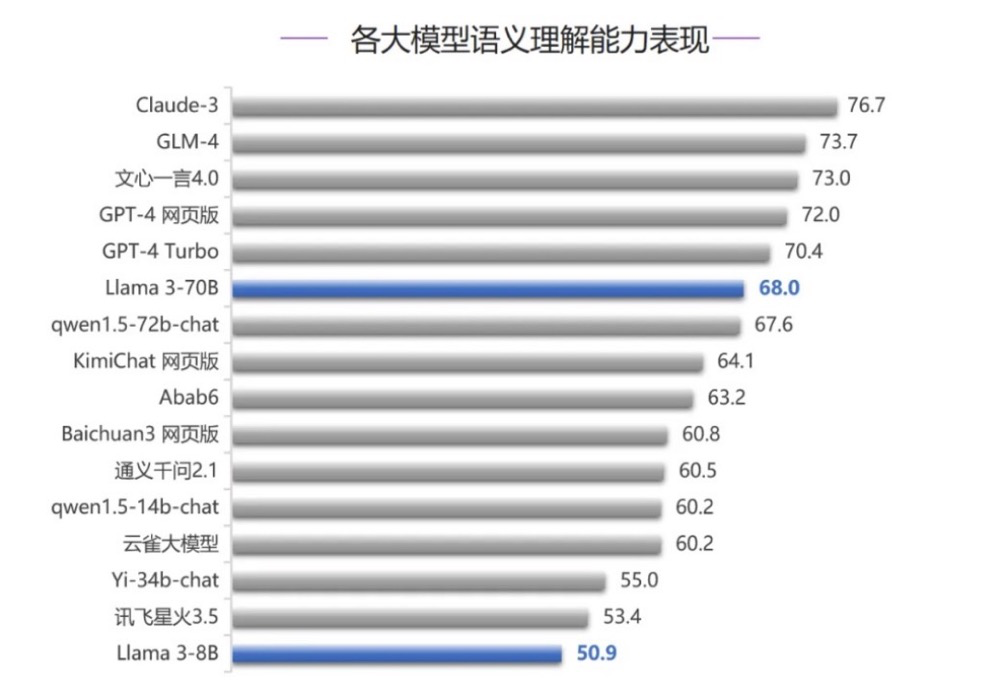
1.大模型语义理解能力
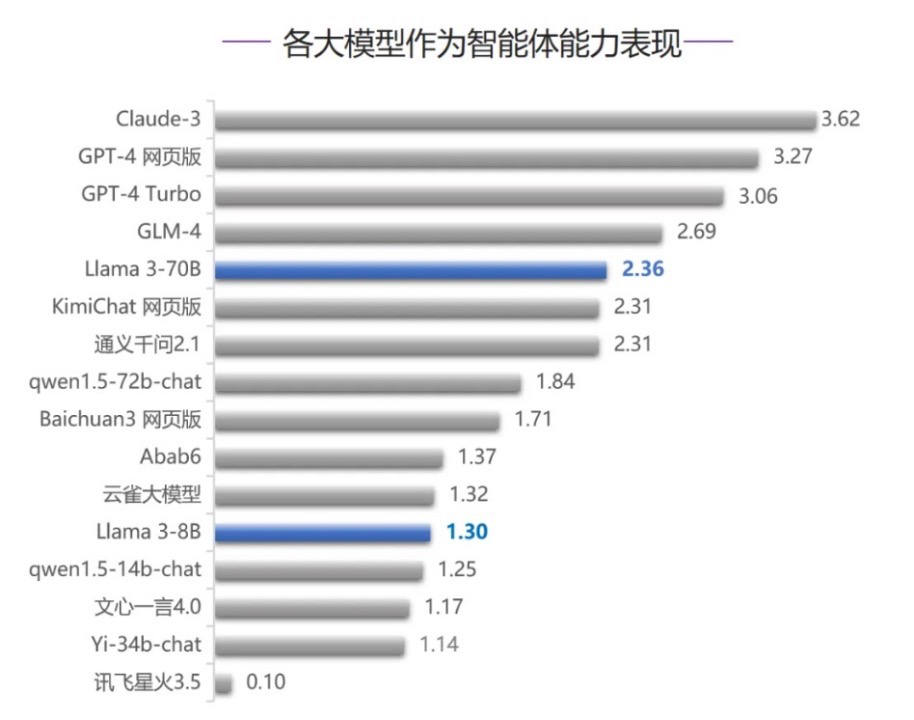
2.大模型智能体能力
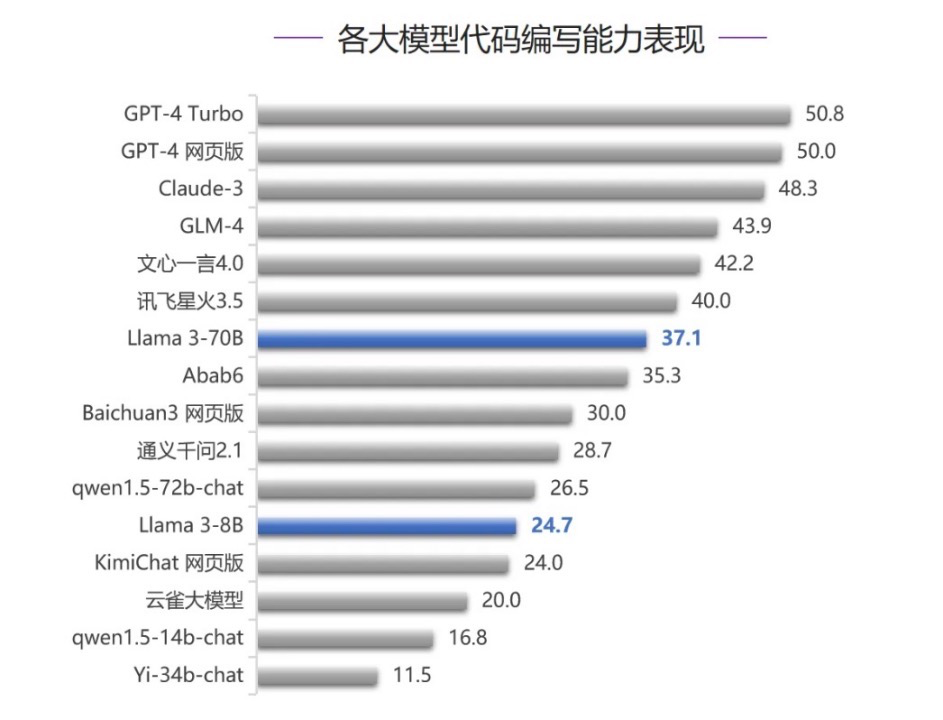
3.大模型代码能力
4.大模型人类对齐能力

5.大模型安全与价值观表现
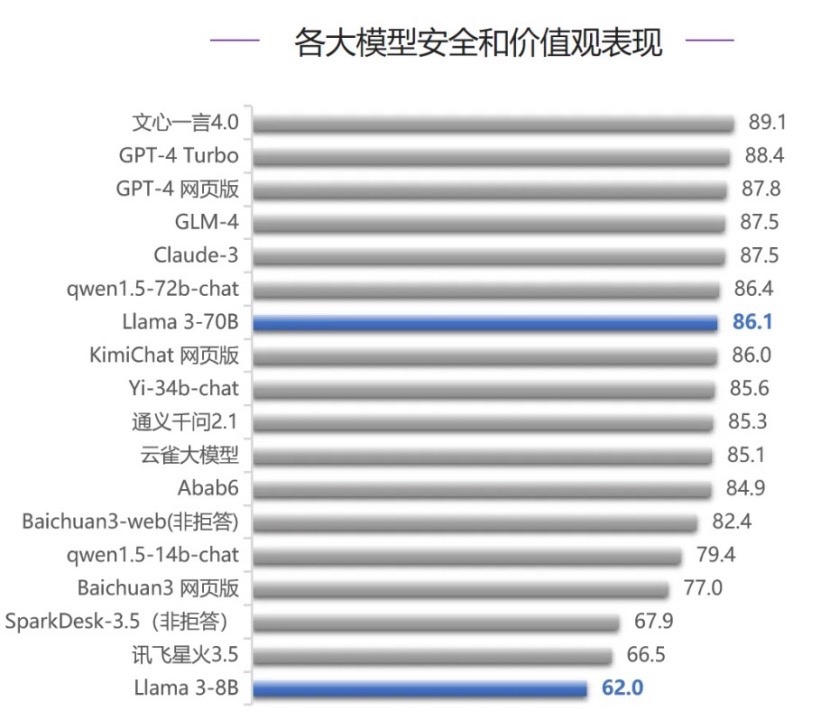
在语义理解能力评测中,Claude-3第一, GLM-4和文心一言4.0分别位列第二名、第三名,超过了GPT-4,Llama 3-70B位列第六名。
代码能力测评中,依旧是GPT-4最厉害,然后是Claude 3 、GLM-4、文心一言4.0,Llama 3-70B的表现相对这些国内外的主流闭源还是弱一些。
不过在智能体评测中,Llama 3-70B跻身第五名,也是5项评测中成绩最好的,仅此于GPT-4、Claude 3 和国产大模型GLM-4。
从以上数据可以看到,开源的Llama 3 70B模型还是谈不上比肩GPT-4和 Claude 3的。
当然,Llama 3 400B的版本我们还没见到,400B的版本能不能真的比肩GPT-4,得等放出来再说了。
在看Llama 3评测结果的时候,笔者倒是无意间发现了一个信息:
智谱AI 的GLM-4和百度的文心一言4.0在5项评测中,基本一直在前5名,Llama-3-70b在五项评测中超过了大多数国内模型,只落败GLM-4和文心一言4.0。来自智谱AI的GLM-4和来自百度的文心一言4.0经常出现在榜单前列。
其中,智谱GLM-4甚至在各项评测中均超越了Llama 3,各个评测维度表现亮眼。
要知道,一年前的国产大模型还在追赶GPT3.5,如今真要说哪个模型“比肩”或“接近”GPT-4的话,吹GLM-4和文心一言4.0可比吹Llama 3靠谱多了。
笔者也是一个狂热+资深的大模型测评爱好者,自身的使用体验与SuperBench的评测结论还是有高度一致的。
这里借机讲一讲智谱GLM-4。
对笔者来说,GLM-4确实是真正用下来为数不多的靠谱国产大模型之一,从实际使用体验上,说其数一数二还是非常扎实的。这个现象其实跟这个公司的基因有很大关系。
智谱AI成立于2019年,是清华大学计算机系知识工程实验室的技术成果转化而来的创业公司,也是国内最早研究大模型底层技术的明星科研团队之一。一言以蔽之,学术&技术基因非常深厚。尽管如今智谱AI已经成为一家商业公司,但其在学术研究上的投入和贡献依旧不容小视。
近期一篇让笔者印象深刻的论文就是智谱团队发表的——“Understanding Emergent Abilities of Language Models from the Loss Perspective“。
这篇论文得出了一个非常刷新认知的结论——以OpenAI为主导的“Scaling Law引发大模型能力涌现”的结论可能是错的。
本文通过严谨的实验发现,大模型的能力涌现与模型大小没有直接关系,损失函数loss 才是涌现的关键——也就是说即使是小模型,只要loss收敛小到一定值,也能达到同样的性能。
要知道,不管是Open AI的GPT迭代路线还是谷歌、Meta其他大厂模型的发展态势,模型一直是朝着参数越来越大、效果也越来也好的路子上走的。
笔者仔细研究了下论文,总结下来,作者们分析了不同size的模型在12个不同数据集上对比不同loss下的模型性能表现,12个数据集包含了不同类型的英文和中文任务。
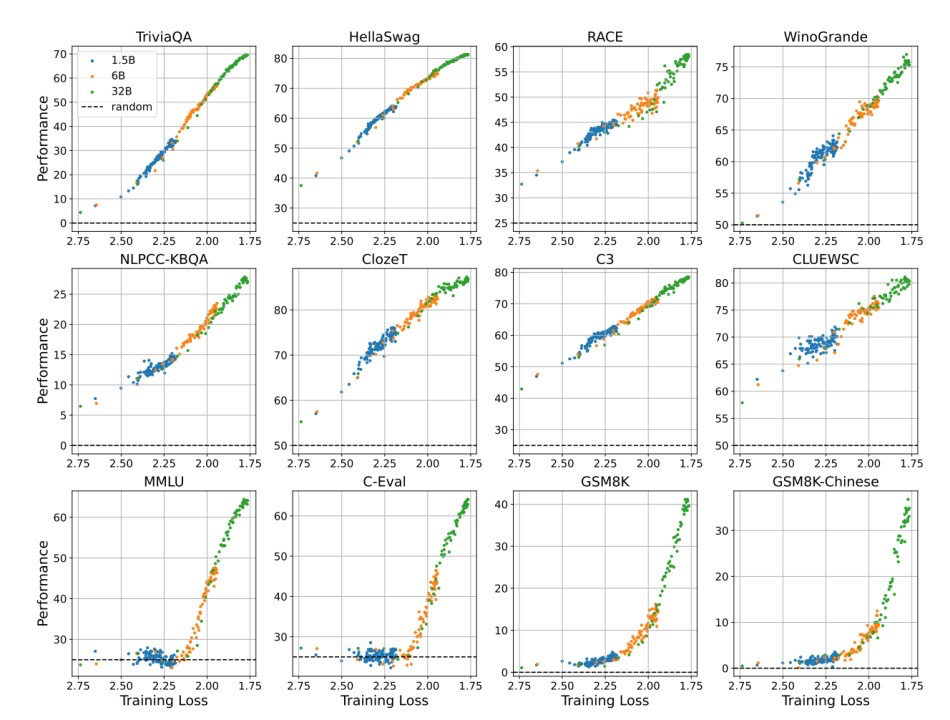
三个颜色区分不同规模,横坐标是loss值,纵坐标是performance,可以看到橙色的6B模型和绿色的32B模型在同一个loss附近是是区分不开的,也就是不同大小的模型在相同的loss附近达到了差不多的性能。
基于Llama 2的7B、13B、33B、65B四种规模的模型相邻的point也是重叠的,也是相似的表现。
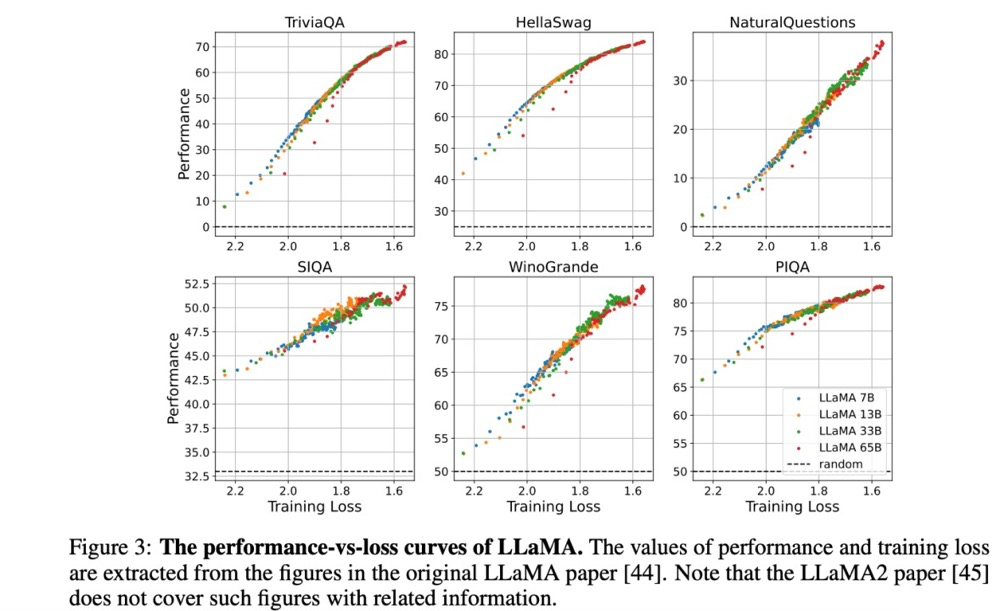
这个实验观测还是非常有意思的。相信会有更多的研究者沿着这篇论文的结论去设计更多的实验去challenge这个“在学术界几乎已成共识但从未被理论证实过”的结论,这也可能改写未来AGI的发展路线。
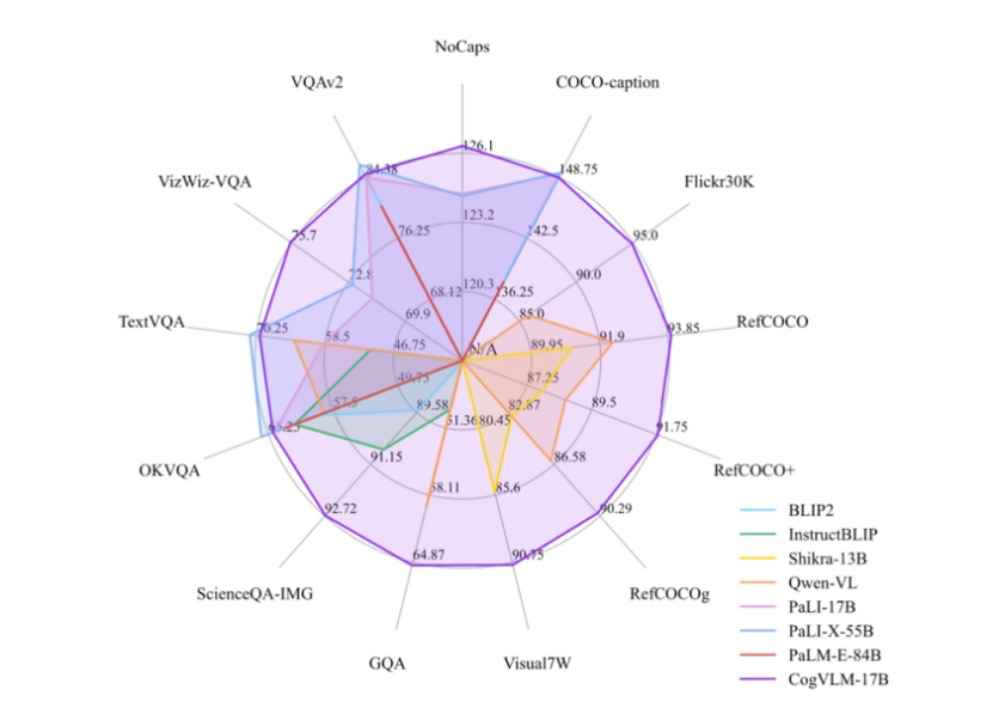
除了在大模型基础理论上有研究创新之外,智谱AI在多模态领域也是没停下来,联合清华先后推出CogView文本-图像生成模型和CogVideo文本-视频生成模型 最新的视觉语言基础模型 CogVLM更是在14个多模态榜单上实现SOTA,变身14边形战士。
想起来前段时间,OpenAI CEO在前段时间的采访中提到“持续创新是最难的,它可以指导产品迭代的方向和公司决策”。而智谱AI这一系列的学术创新和快速的模型迭代、产品发布,让笔者常常在智谱AI身上看到OpenAI的影子——一群深信AGI的技术狂热信徒真正践行着用技术去改变世界的伟大梦想。
说智谱AI是国内大模型技术No.1的创业团队,毫不夸张。
笔者也时常留意智谱AI的商业化进展。智谱AI在商业化上从ToB出发,是国内率先将大模型的变革在企业中落地生花的大模型厂商之一,有效拉动了传统行业的智能化转型,目前已经有超过 2000 家生态合作伙伴,1000 家规模化应用和200 家深度共创客户,广泛覆盖了咨询服务业、传媒行业、食品行业等等,其中不乏德勤中国、分众传媒、华泰证券、马蜂窝、蒙牛、上汽汽车等传统行业龙头企业。
而智谱AI在ToC上,也是有口皆碑。在夕小瑶科技说的数百个社群里,时不时就会发生“哪家国产模型最好用”的口水战,笔者细心的发现几乎每次都会有人站出来力挺智谱AI。
而笔者尤其喜欢使用智谱清言的AI搜索功能:

我们编辑部的小伙伴也经常使用智谱清言来辅助新媒体运营,数据分析甚至生成一些图片素材。可以说是编辑部秘藏AI神器之一了。
尽管Llama 3 为代表的开源力量是否能击败闭源派系的话题在近期出现了不少争议,但作为一名普通用户,可以值得肯定的是,以智谱AI为代表的国产力量已经与国外先进的闭源商业巨头差距大大减小。这个追赶速度,甚至已经超越了开源社区追赶闭源巨头的速度。
正因为国产厂商终年如一日的持续发力,才会有如今的变化。这件事情同样值得我们去关注和肯定。
总之,2024年:
比起开源闭源之争,国产厂商的逆势突围大戏同样令人期待。




