
- 1android自定义选年控件,Android精美日历控件CalendarView自定义使用完全解析
- 2获取屏幕分辨率_Macbook外接显示器开启HiDPI调整分辨率方法(For OS X Catalina 15.1)...
- 3软件测试面试题汇总,【全网最全整理】_软件测试题库
- 4VSCode 使用 Keil5 插件推荐 附带Keil5安装教程_vscode+keil
- 5Llama3中文微调模型-Llama3-Chinese-8B-Instruct概述_llama3 chinese
- 6labelme转COCO数据集(物体检测),Python教程零基础入门_labelme数据格式转coco
- 7stm32毕设 stm32的人体健康状态检测系统(项目开源)
- 8Banana Pi BPI-W3之RK3588安装Qt+opencv+采集摄像头画面._rk3588开发qt
- 9网络安全之弱口令与命令爆破(中篇)(技术进阶)
- 10Stata:时间序列中的格兰杰因果检验_stata格兰杰因果检验的命令
注意力机制23种魔改方法汇总,含2023最新_2023注意力机制
赞
踩
加注意力机制一直深度学习论文创新和模型涨点的重要方式,但当下简单的改变已经不算创新或者涨点效果很不理想了,目前根据场景魔改注意力机制才是主流。
为了让大家更好地改模型、找创新点,提升性能,今天我就给同学们梳理了23个必备的注意力机制模型,既有经典的,也有最新前沿。
通过学习前辈们的魔改方法,我们能够从中找到更多的启发,获得自己的idea,发出顶会。这些模型的论文以及代码我也都整理了,这里只做简单介绍,建议同学们看原文仔细研读。
需要论文及模型代码的同学看文末
1.即插即用CloFormer
论文:Rethinking Local Perception in Lightweight Vision Transformer
重新思考轻量级视觉变压器中的局部感知
「简述:」论文介绍了一种名为CloFormer的轻量级视觉转换器,它通过利用上下文感知的本地增强,提高了在图像分类、目标检测和语义分割等任务上的性能。CloFormer通过引入一种名为AttnConv的卷积操作,结合共享权重和上下文感知权重,有效地捕捉了高频率的本地信息。实验结果表明,CloFormer在各种视觉任务中具有显著优势。

2.可变形大核注意力
论文:Reversible Column Networks
可逆的柱状神经网络
「简述:」论文提出了一种新的神经网络设计范式——可逆列网络(RevCol)。RevCol主要由多个子网络(称为“列”)的副本组成,这些子网络之间使用了多级可逆连接。这种架构方案使得RevCol的行为与传统的网络非常不同:在正向传播过程中,当特征通过每个列时,它们被逐渐解开,同时保持总信息量,而不是像其他网络那样进行压缩或丢弃。

3.引入LSKnet中Lskblock注意力块
论文:Large Selective Kernel Network for Remote Sensing Object Detection
用于遥感目标检测的大规模选择性核网络
「简述:」论文提出了远程感应目标检测新方法LSKNet,这种网络可以动态地调整其大的空间感受野,以更好地模拟远程感应场景中不同物体的范围上下文。文章中提到,这是首次在远程感应目标检测领域探索大型和选择性核机制。通过在标准基准上使用这种技术,LSKNet在HRSC2016(98.46% mAP)、DOTA-v1.0(81.85% mAP)和FAIR1M-v1.0(47.87% mAP)等基准上实现了新的SOTA分数。

4.动态稀疏注意力
论文:BiFormer: Vision Transformer with Bi-Level Routing Attention
具有双层路由注意力的视觉Transformer
简述:该文提出了一种动态稀疏注意力机制,通过双层路由实现,可灵活分配计算,并具有内容意识。这种机制可以过滤掉无关的键值对,并应用精细的令牌到令牌注意力。作者使用这种机制构建了一种新型通用视觉转换器BiFormer,可以自适应地关注查询中的相关令牌,而不会被其他无关令牌分散注意力。

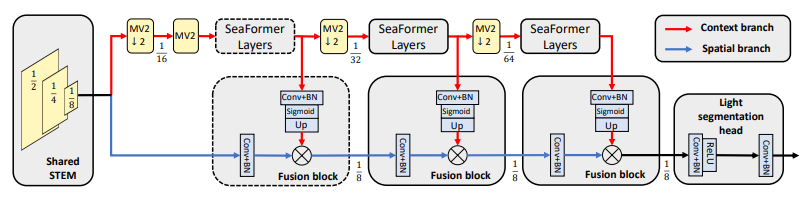
5.即插即用注意力模块sea_AttentionBlock
论文:SEAFORMER: SQUEEZE-ENHANCED AXIAL TRANSFORMER FOR MOBILE SEMANTIC SEGMENTATION
轻量级移动端语义分割模型
「简述:」论文介绍了一种新的方法,叫做SeaFormer,用于在移动设备上进行语义分割。这个方法设计了一个通用的注意力块,可以用来创建一系列主干架构,具有优越的成本效益。在与轻量级分割头配合使用时,该方法在ARM基于的移动设备上实现了最佳的分割精度和延迟。
6.全新注意力机制EMA
论文:Efficient Multi-Scale Attention Module with Cross-Spatial Learning
具有跨空间学习的高效多尺度注意力模块
「简述:」论文提出了一种新的高效多尺度注意力模块(EMA),可以更好地保留每个通道的信息,减少计算开销。该模块将部分通道重塑为批量维度,并将通道维度分组为多个子特征,使空间语义特征在每个特征组内分布良好。它还通过将全局信息编码来重新校准每个并行分支中的通道权重,并进一步聚合两个并行分支的输出特征以捕获像素级的成对关系。

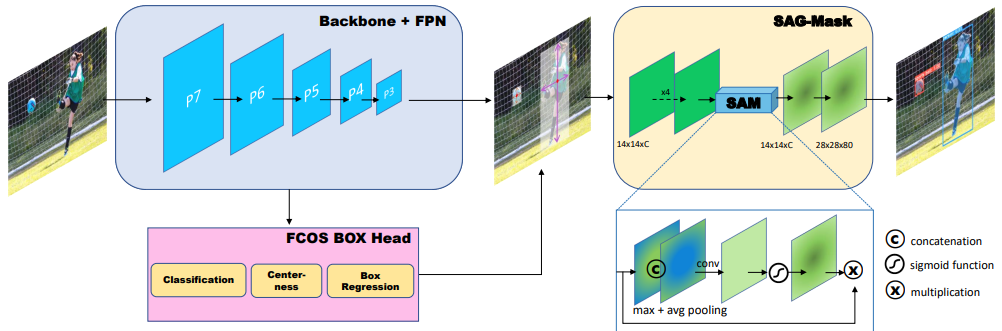
7.Efficient se注意力机制
论文:CenterMask : Real-Time Anchor-Free Instance Segmentation
实时无锚点实例分割
「简述:」CenterMask是一种高效实例分割方法,它结合了FCOS检测器和注意力引导掩膜分支,提高了检测性能。文章还改进了VoVNetV2主干网络,提高了性能。CenterMask和CenterMask-Lite分别针对大型和小型模型进行设计,CenterMask实现了38.3%的性能,超过了所有以前的最先进方法,同时速度更快。
8.SGE注意力机制
论文:Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks
改进卷积网络中的语义特征学习
「简述:」这篇文章介绍了一种轻量级的神经网络模块SGE,它可以调整卷积神经网络中每个子特征的重要性,从而提高图像识别任务的性能。SGE通过生成注意力因子来调整每个子特征的强度,有效抑制噪声。与流行的CNN主干网络集成时,SGE可以显著提高图像识别性能。

9.Ge注意力机制
论文:Gather-Excite: Exploiting Feature Context in Convolutional Neural Networks
利用卷积神经网络中的特征上下文
「简述:」论文提出了一种新的方法,通过引入两个操作符“收集”和“激发”,来改善卷积神经网络(CNN)对上下文的利用。这两个操作符可以有效地从大范围空间中聚合响应,并将信息重新分配给本地特征。这个方法简单且轻量级,可以轻松集成到现有的CNN架构中,而且只增加了很少的参数和计算复杂性。此外,作者还提出了一种参数化的收集-激发操作符对,进一步提高了性能,并将其与最近引入的挤压和激励网络进行了关联。

10.SE注意力机制
论文:Squeeze-and-Excitation Networks
挤压和激励网络
「简述:」论文提出了“挤压和激励”(SE)块,用于改进卷积神经网络(CNN)的性能。SE块可以适应地重新校准通道特征响应,通过建模通道之间的相互依赖关系来增强CNN的表示能力。这些块可以堆叠在一起形成SENet架构,使其在多个数据集上具有非常有效的泛化能力。

11.Global Context注意力机制
论文:Global Context Networks
全局上下文建模网络
「简述:」论文发现非局部网络对全局上下文的建模对于不同查询位置是相同的。因此,作者创建了一个更简单的网络,只考虑查询无关的全局上下文,减少了计算量。作者还将非局部块的一个转换函数替换为两个瓶颈函数,进一步减少了参数数量。这个新网络叫做全局上下文网络(GCNet),它在各种识别任务的主要基准上表现得比非局部网络更好。

12.CBAM注意力机制
论文:CBAM: Convolutional Block Attention Module
卷积块注意力模块
「简述:」这篇文章介绍了CBAM模块,可以增强卷积神经网络(CNN)的性能。这个模块能够同时关注CNN的通道和空间两个维度,对输入特征图进行自适应细化。这个模块轻量级且通用,可以无缝集成到任何CNN架构中,并可以进行端到端训练。实验表明,使用CBAM可以显著提高各种模型的分类和检测性能。

13.ECA注意力机制
论文:ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
深度卷积神经网络的高效通道注意力
「简述:」这篇文章提出了通道注意力模块ECA,可以提升深度卷积神经网络的性能,同时不增加模型复杂性。通过改进现有的通道注意力模块,作者提出了一种无需降维的局部交互策略,并自适应选择卷积核大小。ECA模块在保持性能的同时更高效,实验表明其在多个任务上具有优势。

14.GAM注意力机制
论文:Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions
保留信息以增强通道-空间交互
「简述:」这篇文章提出了一种全局注意力机制,通过减少信息损失和增强全局交互表示来提高深度神经网络的性能。作者引入了3D排列和多层感知器来进行通道注意力,同时引入卷积空间注意力子模块。在CIFAR-100和ImageNet-1K图像分类任务上的评估表明,该方法优于几种最近的注意力机制,包括ResNet和轻量级的MobileNet。

15.Parnet attention注意力机制
论文:NON-DEEP NETWORKS
浅层网络
「简述:」论文提出了一种使用并行子网络来构建高性能“非深度”神经网络的方法,以减少深度和计算量。通过利用并行子结构,该方法实现了只用12层网络就能在ImageNet上达到80%以上的准确率,在CIFAR10上达到96%的准确率,在CIFAR100上达到81%的准确率。此外,作者还分析了这种设计的缩放规则,并展示了如何在不改变网络深度的情况下提高性能。

16.non-local注意力机制
论文:Non-local Neural Networks
非局部神经网络
「简述:」这篇文章介绍了一种新的计算机视觉方法,称为“非局部操作”,它能够捕捉长距离的依赖关系。这种方法受到非局部均值方法的启发,可以计算所有位置的特征加权和。这个构建块可以插入许多计算机视觉架构中。在视频分类任务中,这种方法能够与当前的竞争者竞争或超越它们;在静态图像识别中,这种方法能够改善目标检测/分割和姿态估计。

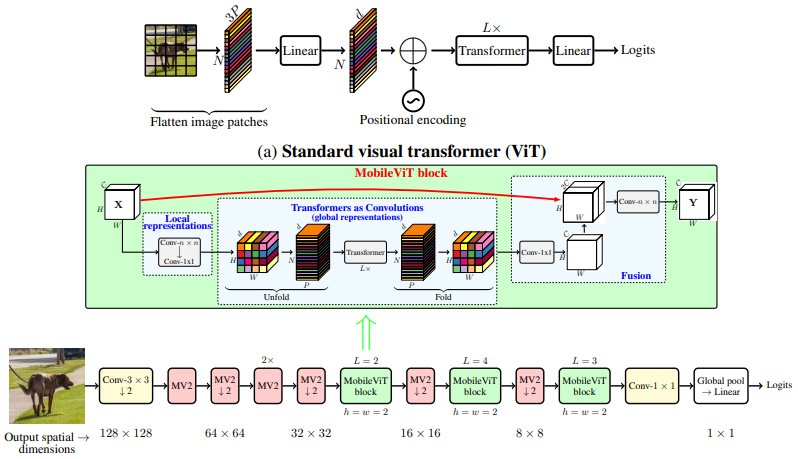
17.MobileViT Attention
论文:MOBILEVIT: LIGHT-WEIGHT, GENERAL-PURPOSE, AND MOBILE-FRIENDLY VISION TRANSFORMER
轻量级、通用和移动友好的视觉transformer
「简述:」论文提出了一种名为MobileViT的轻量级和通用视觉转换器,用于移动设备上的视觉任务。MobileViT结合了CNN和ViT的优点,提供了一个不同的视角来进行全局信息处理。实验结果表明,MobileViT在各种任务和数据集上显著优于CNN和ViT基网络。在ImageNet-1k数据集上,MobileViT实现了78.4%的top-1准确率,参数约为6百万,比MobileNetv3(CNN基)和DeIT(ViT基)高出3.2%和6.2%。在MS-COCO目标检测任务上,MobileViT比MobileNetv3高出5.7%的准确率。
18.即插即用的SK Attention
论文:Selective Kernel Networks
选择性核网络
「简述:」论文提出了一个动态选择机制,允许每个神经元根据输入信息动态调整其感受野大小。设计了选择性核(SK)单元作为构建块,其中不同核大小的多个分支通过由这些分支中的信息引导的softmax注意力进行融合。这些分支上的不同注意力会产生融合层中神经元的不同大小的有效的感受野。多个SK单元堆叠成一个称为选择性核网络(SKNet)的深层网络。

19.Double Attention Networks
论文:A2 -Nets: Double Attention Networks
双重注意力网络
「简述:」论文提出了一种新的神经网络组件,名为“双注意力块”,它能够从整个输入图像/视频中提取重要的全局特征,并使神经网络更有效地访问整个空间的特征,从而提高识别任务的性能。实验表明,配备双注意力块的神经网络在图像和动作识别任务上均优于现有的更大规模神经网络,同时参数和计算量也减少。

20.极化自注意力(Polarized Self-Attention)
论文:Polarized Self-Attention: Towards High-quality Pixel-wise Regression
用于高质量像素级回归
「简述:」论文提出了“极化自注意力(PSA)”,旨在解决像素级回归问题。PSA通过保持高内部分辨率和直接适应典型精细回归的输出分布来提高性能。实验结果表明,PSA可以显著提高标准基线和最佳水平的性能。

21.自注意力和CNN融合
论文:ACMix:On the Integration of Self-Attention and Convolution
关于自注意力和卷积的集成
「简述:」论文表明卷积和自注意力这两种强大的表示学习方法之间存在深层次的联系。它们的第一阶段都包含相同的操作,即分解为多个1×1的卷积。基于这个观察,文章提出了一种混合模型,结合了自注意力和卷积的优点,具有最小的计算开销。实验表明,该模型在图像识别和下游任务上取得了显著改进的结果。

22.Context Aggregation
论文:Container: Context Aggregation Network
上下文聚合网络
「简述:」论文介绍了一种神经网络模型,名为CONTAINER。这种模型可以用于多头上下文聚合,能够同时利用长程交互和局部卷积操作的优点,达到更快的收敛速度。与基于Transformer的方法不同,CONTAINER模型可以很好地扩展到依赖更大输入图像分辨率的下游任务。文章还介绍了一种轻量级网络变体,名为CONTAINER-LIGHT,可以用于对象检测和实例分割网络,相比具有相似计算和参数大小的ResNet-50主干,可以显著提高检测和掩膜的准确率。此外,该方法在自监督学习方面也取得了有希望的结果。

23.弱监督语义分割的自监督注意力机制
论文:Self-supervised Equivariant Attention Mechanism for Weakly Supervised Semantic Segmentation
弱监督语义分割的自监督等变注意力机制
「简述:」论文提出了一种新的方法来解决图像级弱监督语义分割的问题。该方法基于等变性约束,通过自我监督来发现额外的监督并缩小与全监督之间的差距。文章还提出了一种像素相关模块(PCM),以利用上下文信息并改进像素预测的一致性。

关注下方《学姐带你玩AI》
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

