
- 1vue-element-admin 动态路由菜单
- 2python有趣小程序-Python全栈开发-有趣的小程序
- 3光遇android和ios有什么区别,光遇安卓和苹果可以一起玩吗?
- 4【Three.js】解决使用Three.js导入obj模型不可见问题详细记录_three.js加载obj不显示
- 5如何查看mac系统是32位还是64位的操作系统_mac os多少是64位的
- 6shell 局域网IP探活脚本
- 7基于SSM框架图书馆预约占座系统的设计与实现(附源码、论文)
- 8GC root的确定由来_gcroot为什么这么选
- 9大数据Hadoop、Hive、Kafka、Hbase、Spark等框架面经_hadoop面经
- 107.机器学习-十大算法之一拉索回归(Lasso)算法原理讲解_lasso算法产生新的描述符
一文详解AI模型部署及工业落地方式
赞
踩
点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达

Hello大家好,我是老潘,好久不见各位~
最近在复盘今年上半年做的一些事情,不管是训练模型、部署模型搭建服务,还是写一些组件代码等,零零散散是有一些产出。
虽然有了一点点成果,但仍觉着缺点什么。作为深度学习算法工程师,训练模型和部署模型是最基本的要求,每天都在重复着这个工作,但偶尔静下心来想一想,还是有很多事情需要做的:
模型的结构,因为上线业务需要,更趋向于稳定有经验的,而不是探索一些新的结构
模型的加速仍然不够,还没有压榨完GPU的全部潜力
深感还有很多很多需要学习的地方啊。

既然要学习,那么学习路线就显得比较重要了。
本文重点谈谈学习AI部署的一些基础和需要提升的地方。这也是老潘之前学习、或者未来需要学习的一些点,这里抛砖引玉下,也希望大家能够提出一点意见。
AI部署
AI部署这个词儿大家肯定不陌生,可能有些小伙伴还不是很清楚这个是干嘛的,但总归是耳熟能详了。
近些年来,在深度学习算法已经足够卷卷卷之后,深度学习的另一个偏向于工程的方向--部署工业落地,才开始被谈论的多了起来。当然这也是大势所趋,毕竟AI算法那么多,如果用不着,只在学术圈搞研究的话没有意义。因此很多AI部署相关行业和AI芯片相关行业也在迅速发展,现在虽然已经2021年了,但我认为AI部署相关的行业还未到头,AI也远远没有普及。

简单收集了一下知乎关于“部署”话题去年和今年的一些提问:



提问的都是明白人,随着人工智能逐渐普及,使用神经网络处理各种任务的需求越来越多,如何在生产环境中快速、稳定、高效地运行模型,成为很多公司不得不考虑的问题。不论是通过提升模型速度降低latency提高用户的使用感受,还是加速模型降低服务器预算,都是很有用的,公司也需要这样的人才。
在经历了算法的神仙打架、诸神黄昏、灰飞烟灭等等这些知乎热搜后。AI部署工业落地这块似乎还没有那么卷...相比AI算法来说,AI部署的入坑机会更多些。

当然,AI落地部署和神经网络深度学习的关系是分不开的,就算你是AI算法工程师,也是有必要学习这块知识的。并不是所有人都是纯正的AI算法研究员。
聊聊AI部署
AI部署的基本步骤:
训练一个模型,也可以是拿一个别人训练好的模型
针对不同平台对生成的模型进行转换,也就是俗称的parse、convert,即前端解释器
针对转化后的模型进行优化,这一步很重要,涉及到很多优化的步骤
在特定的平台(嵌入端或者服务端)成功运行已经转化好的模型
在模型可以运行的基础上,保证模型的速度、精度和稳定性
就这样,虽然看起来没什么,但需要的知识和经验还是很多的。

因为实际场景中我们使用的模型远远比ResNet50要复杂,我们部署的环境也远远比实验室的环境条件更苛刻,对模型的速度精度需求也比一般demo要高。
对于硬件公司来说,需要将深度学习算法部署到性能低到离谱的开发板上,因为成本能省就省。在算法层面优化模型是一方面,但更重要的是从底层优化这个模型,这就涉及到部署落地方面的各个知识(手写汇编算子加速、算子融合等等);对于软件公司来说,我们往往需要将算法运行到服务器上,当然服务器可以是布满2080TI的高性能CPU机器,但是如果QPS请求足够高的话,需要的服务器数量也是相当之大的。这个要紧关头,如果我们的模型运行的足够快,可以省机器又可以腾一些buffer上新模型岂不很爽,这个时候也就需要优化模型了,其实优化手段也都差不多,只不过平台从arm等嵌入式端变为gpu等桌面端了。
作为AI算法部署工程师,你要做的就是将训练好的模型部署到线上,根据任务需求,速度提升2-10倍不等,还需要保证模型的稳定性。
是不是很有挑战性?
需要什么技术呢?
需要一些算法知识以及扎实的工程能力。
老潘认为算法部署落地这个方向是比较踏实务实的方向,相比设计模型提出新算法,对于咱们这种并不天赋异禀来说,只要肯付出,收获是肯定有的(不像设计模型,那些巧妙的结果设计不出来就是设计不出来你气不气)。
其实算法部署也算是开发了,不仅需要和训练好的模型打交道,有时候也会干一些粗活累活(也就是dirty work),自己用C++、cuda写算子(预处理、op、后处理等等)去实现一些独特的算子。也需要经常调bug、联合编译、动态静态库混搭等等。

算法部署最常用的语言是啥,当然是C++了。如果想搞深度学习AI部署这块,C++是逃离不了的。
所以,学好C++很重要,起码能看懂各种关于部署精巧设计的框架(再列一遍:Caffe、libtorch、ncnn、mnn、tvm、OpenVino、TensorRT,不完全统计,我就列过我用过的)。当然并行计算编程语言也可以学一个,针对不同的平台而不同,可以先学学CUDA,资料更多一些,熟悉熟悉并行计算的原理,对以后学习其他并行语言都有帮助。
系统的知识嘛,还在整理[1],还是建议实际中用到啥再看啥,或者有项目在push你,这样学习的更快一些。
可以选择上手的项目:
好用的开源推理框架:Caffe、NCNN、MNN、TVM、OpenVino
好用的半开源推理框架:TensorRT
好用的开源服务器框架:triton-inference-server
基础知识:计算机原理、编译原理等
需要的深度学习基础知识
AI部署当然也需要深度学习的基础知识,也需要知道怎么训练模型,怎么优化模型,模型是怎么设计的等等。不然你怎会理解这个模型的具体op细节以及运行细节,有些模型结构比较复杂,也需要对原始模型进行debug。
常用的框架
这里介绍一些部署常用到的框架,也是老潘使用过的,毕竟对于某些任务来说,自己造轮子不如用别人造好的轮子。

并且大部分大厂的轮子都有很多我们可以学习的地方,因为开源我们也可以和其他开发者一同讨论相关问题;同样,虽然开源,但用于生产环境也几乎没有问题,我们也可以根据自身需求进行魔改。
这里老潘介绍一些值得学习的推理框架,不瞒你说,这些推理框架已经被很多公司使用于生成环境了。
Caffe[2]
Caffe有多经典就不必说了,闲着无聊的时候看看Caffe源码也是受益匪浅。我感觉Caffe是前些年工业界使用最多的框架(还有一个与其媲美的就是darknet,C实现)没有之一,纯C++实现非常方便部署于各种环境。
适合入门,整体构架并不是很复杂。当然光看代码是不行的,直接拿项目来练手、跑起来是最好的。
第一次使用可以先配配环境,要亲手来体验体验。
至于项目,建议拿SSD来练手!官方的SSD就是拿Caffe实现的,改写了一些Caffe的层和组件,我们可以尝试用SSD训练自己的数据集,然后部署推理一下,这样才有意思!
Libtorch (torchscript)
libtorch是Pytorch的C++版,有着前端API和与Pytorch一样的自动求导功能,可以用于训练或者推理。

Pytorch训练出来的模型经过torch.jit.trace或者torch.jit.scrpit可以导出为.pt格式,随后可以通过libtorch中的API加载然后运行,因为libtorch是纯C++实现的,因此libtorch可以集成在各种生产环境中,也就实现了部署(不过libtorch有一个不能忽视但影响不是很大的缺点[4],限于篇幅暂时不详说)。
libtorch是从1.0版本开始正式支持的,如今是1.9版本。从1.0版本我就开始用了,1.9版本也在用,总的来说,绝大部分API和之前变化基本不大,ABI稳定性保持的不错!
libtorch适合Pytorch模型快速C++部署的场景,libtorch相比于pytorch的python端其实快不了多少(大部分时候会提速,小部分情况会减速)。在老潘的使用场景中,一般都是结合TensorRT来部署,TensorRT负责简单卷积层等操作部分,libtorch复杂后处理等细小复杂op部分。
基本的入门教程:
官方资料以及API:
USING THE PYTORCH C++ FRONTEND[5]
PYTORCH C++ API[6]
libtorch的官方资料比较匮乏,建议多搜搜github或者Pytorch官方issue,要善于寻找。
一些libtorch使用规范:
Load tensor from file in C++ [7]
TensorRT
TensorRT是可以在NVIDIA各种GPU硬件平台下运行的一个C++推理框架。我们利用Pytorch、TF或者其他框架训练好的模型,可以转化为TensorRT的格式,然后利用TensorRT推理引擎去运行我们这个模型,从而提升这个模型在英伟达GPU上运行的速度。速度提升的比例是比较可观的。
在GPU服务器上部署的话,TensorRT是首选!
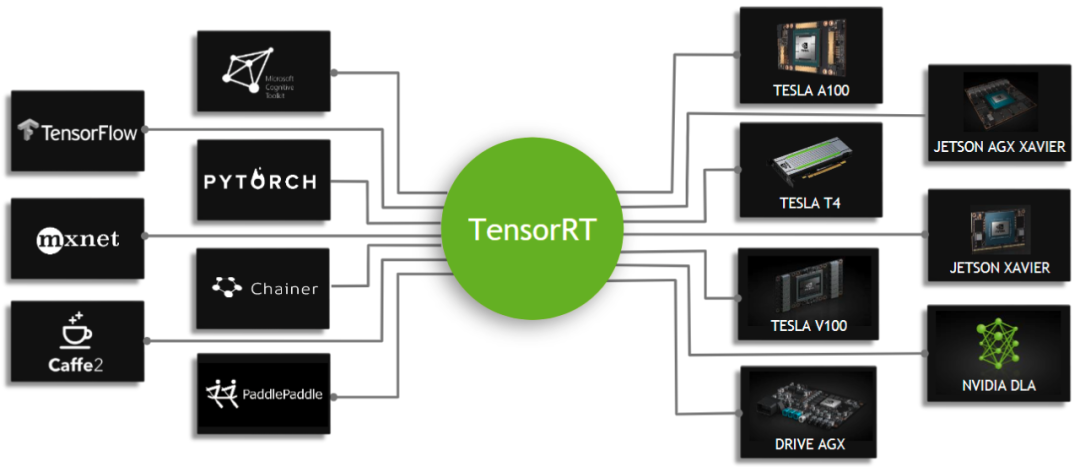
TensorRT老潘有单独详细的教程,可以看这里:
OpenVINO
在英特尔CPU端(也就是我们常用的x86处理器)部署首选它!开源且速度很快,文档也很丰富,更新很频繁,代码风格也不错,很值得学习。

在我这边CPU端场景不是很多,毕竟相比于服务器来说,CPU场景下,很多用户的硬件型号各异,不是很好兼容。另外神经网络CPU端使用场景在我这边不是很多,所以搞得不是很多。
哦对了,OpenVino也可以搭配英特尔的计算棒,亲测速度飞快。
详细介绍可以看这里:
NCNN/MNN/TNN/TVM
有移动端部署需求的,即模型需要运行在手机或者嵌入式设备上的需求可以考虑这些框架。这里只列举了一部分,还有很多其他优秀的框架没有列出来...是不是不好选?
NCNN[8]
MNN[9]
TNN[10]
TVM[11]
Tengine[12]
个人认为性价比比较高的是NCNN[13],易用性比较高,很容易上手,用了会让你感觉没有那么卷。而且相对于其他框架来说,NCNN的设计比较直观明了,与Caffe和OpenCV有很多相似之处,使用起来也很简单。可以比较快速地编译链接和集成到我们的项目中。

TVM和Tengine比较复杂些,不过性能天花板也相比前几个要高些,可以根据取舍尝试。
相关链接:
PaddlePaddle[14]
PaddlePaddle作为国内唯一一个用户最多的深度学习框架,真的不是盖。
很多任务都有与训练模型可以使用,不论是GPU端还是移动端,大部分的模型都很优秀很好用。
如果想快速上手深度学习,飞浆是不错的选择,官方提供的示例代码都很详细,一步一步教你教到你会为止。
最后说一句,国产牛逼。
还有很多框架
当然除了老潘这里介绍的这些,还有很多更加优秀的框架,只不过我没有使用过,这里也就不多评论了。

AI部署中的提速方法
老潘这一年除了训练模型,也部署了不少模型。虽然模型速度有提升,但仍然不够快,仍然还有很多空间去提升。
我的看法是,部署不光是从研究环境到生产环境的转换,更多的是模型速度的提升和稳定性的提升。稳定性这个可能要与服务器框架有关了,网络传输、负载均衡等等,老潘不是很熟悉,也就不献丑了。不过速度的话,从模型训练出来,到部署推理这一步,有什么优化空间呢?

上到模型层面,下到底层硬件层面,其实能做的有很多。如果我们将各种方法都用一遍(大力出奇迹),最终模型提升10倍多真的不是梦!
有哪些能做的呢?
模型结构
剪枝
蒸馏
稀疏化训练
量化训练
算子融合、计算图优化、底层优化
简单说说吧!
模型结构
模型结构当然就是探索更快更强的网络结构,就比如ResNet相比比VGG,在精度提升的同时也提升了模型的推理速度。又比如CenterNet相比YOLOv3,把anchor去掉的同时也提升了精度和速度。
模型层面的探索需要有大量的实验支撑,以及,脑子,我脑子不够,就不参与啦。喜欢白嫖,能白嫖最新的结构最好啦,不过不是所有最新结构都能用上,还是那句话,部署友好最好。

哦,还有提一点,最近发现另一种改变模型结构的思路,结构重参化。还是蛮有搞头的,这个方向与落地部署关系密切,最终的目的都是提升模型速度的同时不降低模型的精度。
之前有个比较火的RepVgg[15]——Making VGG-style ConvNets Great Again就是用了这个想法,是工业届一个非常solid的工作。部分思想与很多深度学习推理框架的算子融合有异曲同工之处。
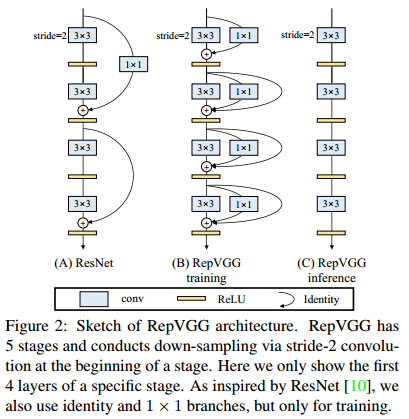
老潘也在项目中使用了repvgg,在某些任务的时候,相对于ResNet来说,repvgg可以在相同精度上有更高的速度,还是有一定效果的。
剪枝
剪枝很早就想尝试了,奈何一直没有时间啊啊啊。
我理解的剪枝,就是在大模型的基础上,对模型通道或者模型结构进行有目的地修剪,剪掉对模型推理贡献不是很重要的地方。经过剪枝,大模型可以剪成小模型的样子,但是精度几乎不变或者下降很少,最起码要高于小模型直接训练的精度。
积攒了一些比较优秀的开源剪枝代码,还咩有时间细看:
yolov3-channel-and-layer-pruning[16]
YOLOv3-model-pruning[17]
centernet_prune[18]
ResRep[19]
蒸馏
我理解的蒸馏就是大网络教小网络,之后小网络会有接近大网络的精度,同时也有小网络的速度。
再具体点,两个网络分别可以称之为老师网络和学生网络,老师网络通常比较大(ResNet50),学生网络通常比较小(ResNet18)。训练好的老师网络利用soft label去教学生网络,可使小网络达到接近大网络的精度。
印象中蒸馏的作用不仅于此,还可以做一些更实用的东西,之前比较火的centerX[20],将蒸馏用出了花,感兴趣的可以试试。
稀疏化
稀疏化就是随机将Tensor的部分元素置为0,类似于我们常见的dropout,附带正则化作用的同时也减少了模型的容量,从而加快了模型的推理速度。
稀疏化操作其实很简单,Pytorch官方已经有支持,我们只需要写几行代码就可以:
- def prune(model, amount=0.3):
- # Prune model to requested global sparsity
- import torch.nn.utils.prune as prune
- print('Pruning model... ', end='')
- for name, m in model.named_modules():
- if isinstance(m, nn.Conv2d):
- prune.l1_unstructured(m, name='weight', amount=amount) # prune
- prune.remove(m, 'weight') # make permanent
- print(' %.3g global sparsity' % sparsity(model))
-
上述代码来自于Pruning/Sparsity Tutorial [21]。这样,通过Pytorch官方的torch.nn.utils.prune模块就可以对模型的卷积层tensor随机置0。置0后可以简单测试一下模型的精度...精度当然是降了哈哈!所以需要finetune来将精度还原,这种操作其实和量化、剪枝是一样的,目的是在去除冗余结构后重新恢复模型的精度。
那还原精度后呢?这样模型就加速了吗?当然不是,稀疏化操作并不是什么平台都支持,如果硬件平台不支持,就算模型稀疏了模型的推理速度也并不会变快。因为即使我们将模型中的元素置为0,但是计算的时候依然还会参与计算,和之前的并无区别。我们需要有支持稀疏计算的平台才可以。
英伟达部分显卡是支持稀疏化推理的,英伟达的A100 GPU显卡在运行bert的时候,稀疏化后的网络相比之前的dense网络要快50%。我们的显卡支持么?只要是Ampere architecture架构的显卡都是支持的(例如30XX显卡)。
Exploiting NVIDIA Ampere Structured Sparsity with cuSPARSELt[22]
How Sparsity Adds Umph to AI Inference[23]
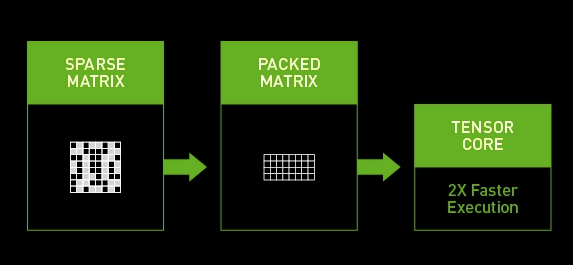
最近的TensorRT8是支持直接导入稀疏化模型的,目前支持Structured Sparsity结构。如果有30系列卡和TensorRT8的童鞋可以尝试尝试~
并且英伟达官方提供了基于Pytorch的自动稀疏化工具——Automatic SParsity[24],总的流程来说就是:
先拿一个完整的模型(dense),然后以一定的稀疏化系数稀疏化这个模型
然后基于这个稀疏化后的模型进行训练
将训练后的模型导出来即可
是不是很简单?
相关讨论:
NVIDIA's Tensor-TFLOPS values for their newest GPUs include sparsity[25]
Pruning BERT to accelerate inference[26]
Which GPU(s) to Get for Deep Learning: My Experience and Advice for Using GPUs in Deep Learning[27]
NVIDIA RTX 3080: Performance Test[28]
量化训练
这里指的量化训练是在INT8精度的基础上对模型进行量化。简称QTA(Quantization Aware Training)。
量化后的模型在特定CPU或者GPU上相比FP32、FP16有更高的速度和吞吐,也是部署提速方法之一。
PS:FP16量化一般都是直接转换模型权重从FP32->FP16,不需要校准或者finetune。
量化训练是在模型训练中量化的,与PTQ(训练后量化)不同,这种量化方式对模型的精度影响不大,量化后的模型速度基本与量化前的相同(另一种量化方式PTQ,TensorRT或者NCNN中使用交叉熵进行校准量化的方式,在一些结构中会对模型的精度造成比较大的影响)。
举个例子,我个人CenterNet训练的一个网络,使用ResNet-34作为backbone,利用TensorRT进行转换后,使用1024x1024作为测试图像大小的指标:
精度/指标
FP32
INT8(PTQ)
INT8(QTA)
AP | 0.93 | 0.83 | 0.94 |
速度 | 13ms | 3.6ms | 3.6ms |
精度不降反升(可以由于之前FP32的模型训练不够彻底,finetune后精度又提了一些),还是值得一试的。
目前我们常用的Pytorch当然也是支持QTA量化的。
不过Pytorch量化训练出来的模型,官方目前只支持CPU。即X86和Arm,具有INT8指令集的CPU可以使用:
x86 CPUs with AVX2 support or higher (without AVX2 some operations have inefficient implementations)
ARM CPUs (typically found in mobile/embedded devices)
已有很多例子。
相关文章:
PyTorch Quantization Aware Training[29]
Pytorch QUANTIZATION[30]
那么GPU支持吗?
Pytorch官方不支持,但是NVIDIA支持。
NVIDIA官方提供了Pytorch的量化训练框架包,目前虽然不是很完善,但是已经可以正常使用:
NVIDIA官方提供的pytorch-quantization-toolkit[31]
利用这个量化训练后的模型可以导出为ONNX(需要设置opset为13),导出的ONNX会有QuantizeLinear和DequantizeLinear两个算子:
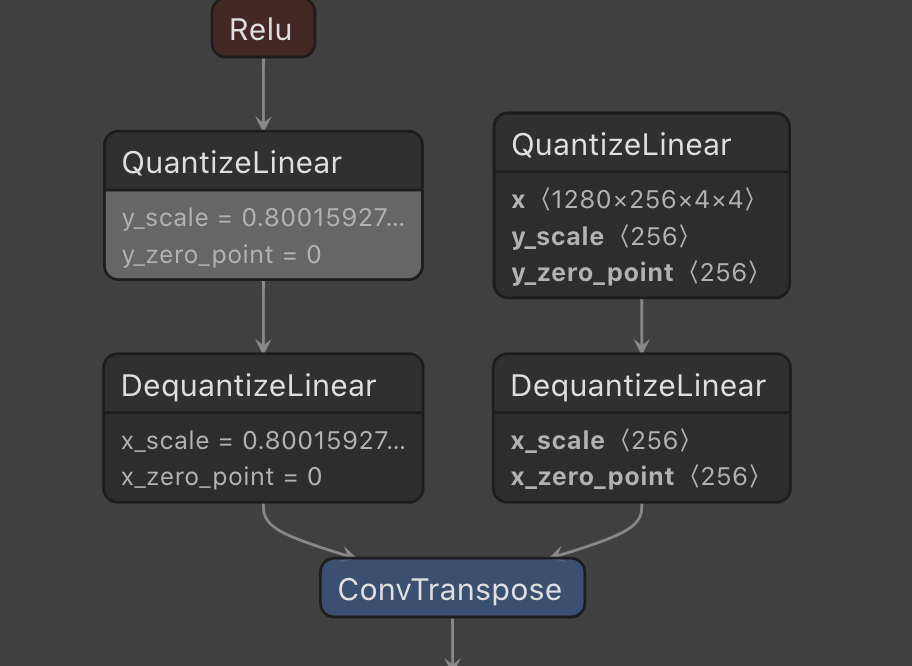
带有QuantizeLinear和DequantizeLinear算子的ONNX可以通过TensorRT8加载,然后就可以进行量化推理:
Added two new layers to the API: IQuantizeLayer and IDequantizeLayer which can be used to explicitly specify the precision of operations and data buffers. ONNX’s QuantizeLinear and DequantizeLinear operators are mapped to these new layers which enables the support for networks trained using Quantization-Aware Training (QAT) methodology. For more information, refer to the Explicit-Quantization, IQuantizeLayer, and IDequantizeLayer ps in the TensorRT Developer Guide and Q/DQ Fusion in the Best Practices For TensorRT Performance guide.
而TensorRT8版本以下的不支持直接载入,需要手动去赋值MAX阈值。
相关例子:
ResNet-50 v1.5 for TensorFlow[32]
BERT Inference Using TensorRT[33]
Questions about int8 inference procedure[34]
常见部署流程
假设我们的模型是使用Pytorch训练的,部署的平台是英伟达的GPU服务器。
训练好的模型通过以下几种方式转换:
Pytorch->ONNX->trt onnx2trt[35]
Pytorch->trt torch2trt[36]
Pytorch->torchscipt->trt trtorch[37]
其中onnx2trt[38]最成熟,torch2trt[39]比较灵活,而trtorch[40]不是很好用。三种转化方式各有利弊,基本可以覆盖90%常见的主流模型。
遇到不支持的操作,首先考虑是否可以通过其他pytorch算子代替。如果不行,可以考虑TensorRT插件、或者模型拆分为TensorRT+libtorch的结构互相弥补。trtorch[41]最新的commit支持了部分op运行在TensorRT部分op运行在libtorch,但还不是很完善,感兴趣的小伙伴可以关注一下。
常见的服务部署搭配:
triton server + TensorRT/libtorch
flask + Pytorch
Tensorflow Server
后记
来北京工作快一年了,做了比较久的AI相关的训练部署工作,一直处于快速学习快速输出的状态,没有好好总结一下这段时间的工作内容和复盘自己的不足。所以趁着休息时间,也回顾一下自己之前所做的东西,总结一些内容和一些经验罢。同时也是抛砖引玉,看看大家对于部署有没有更好的想法。
AI部署的内容还是有很多,这里仅仅是展示其中的冰山一角,对于更多相关的内容,可以关注老潘一起交流哈。
看了上述介绍,如果不确定自己的方向的,可以先打打基础,先看看C++/python等,基础工具熟悉了,之后学习起来会更快。

先这样,我是老潘,我们下期见~
参考资料
[1]
整理: https://t.1yb.co/u5rJ
[2]Caffe: https://github.com/BVLC/caffe
[3]Caffe-SSD: https://github.com/weiliu89/caffe
[4]不能忽视但影响不是很大的缺点: https://github.com/pytorch/pytorch/issues/57894
[5]USING THE PYTORCH C++ FRONTEND: https://pytorch.org/tutorials/advanced/cpp_frontend.html
[6]PYTORCH C++ API: https://pytorch.org/cppdocs/
[7]Load tensor from file in C++ : https://github.com/pytorch/pytorch/issues/20356
[8]NCNN: https://github.com/Tencent/ncnn/tree/master/benchmark
[9]MNN: https://github.com/alibaba/MNN
[10]TNN: https://github.com/Tencent/TNN
[11]TVM: https://tvm.apache.org/
[12]Tengine: https://github.com/OAID/Tengine
[13]NCNN: https://github.com/Tencent/ncnn/tree/master/benchmark
[14]PaddlePaddle: https://www.paddlepaddle.org.cn/
[15]RepVgg: https://github.com/DingXiaoH/RepVGG
[16]yolov3-channel-and-layer-pruning: https://github.com/tanluren/yolov3-channel-and-layer-pruning
[17]YOLOv3-model-pruning: https://github.com/Lam1360/YOLOv3-model-pruning
[18]centernet_prune: https://github.com/panchengl/centernet_prune
[19]ResRep: https://github.com/DingXiaoH/ResRep
[20]centerX: https://github.com/JDAI-CV/centerX
[21]Pruning/Sparsity Tutorial : https://github.com/ultralytics/yolov5/issues/304
[22]Exploiting NVIDIA Ampere Structured Sparsity with cuSPARSELt: https://developer.nvidia.com/blog/exploiting-ampere-structured-sparsity-with-cusparselt/
[23]How Sparsity Adds Umph to AI Inference: https://blogs.nvidia.com/blog/2020/05/14/sparsity-ai-inference/
[24]Automatic SParsity: https://github.com/NVIDIA/apex/tree/082f999a6e18a3d02306e27482cc7486dab71a50/apex/contrib/sparsity
[25]NVIDIA's Tensor-TFLOPS values for their newest GPUs include sparsity: https://www.reddit.com/r/MachineLearning/comments/ioa9za/d_psa_nvidias_tensortflops_values_for_their/
[26]Pruning BERT to accelerate inference: https://blog.rasa.com/pruning-bert-to-accelerate-inference/
[27]Which GPU(s) to Get for Deep Learning: My Experience and Advice for Using GPUs in Deep Learning: https://timdettmers.com/2020/09/07/which-gpu-for-deep-learning/
[28]NVIDIA RTX 3080: Performance Test: https://rockingreview.com/posts/nvidia-rtx-3080-performance-test
[29]PyTorch Quantization Aware Training: https://leimao.github.io/blog/PyTorch-Quantization-Aware-Training/
[30]Pytorch QUANTIZATION: https://pytorch.org/docs/stable/quantization.html
[31]NVIDIA官方提供的pytorch-quantization-toolkit: https://docs.nvidia.com/deeplearning/tensorrt/pytorch-quantization-toolkit/docs/userguide.html
[32]ResNet-50 v1.5 for TensorFlow: https://github.com/NVIDIA/DeepLearningExamples/tree/master/TensorFlow/Classification/ConvNets/resnet50v1.5
[33]BERT Inference Using TensorRT: https://github.com/NVIDIA/TensorRT/tree/master/demo/BERT
[34]Questions about int8 inference procedure: https://github.com/NVIDIA/TensorRT/issues/1271
[35]onnx2trt: https://github.com/onnx/onnx-tensorrt
[36]torch2trt: https://github.com/NVIDIA-AI-IOT/torch2trt
[37]trtorch: https://github.com/NVIDIA/TRTorch
[38]onnx2trt: https://github.com/onnx/onnx-tensorrt
[39]torch2trt: https://github.com/NVIDIA-AI-IOT/torch2trt
[40]trtorch: https://github.com/NVIDIA/TRTorch
[41]trtorch: https://github.com/NVIDIA/TRTorch
本文仅做学术分享,如有侵权,请联系删文。
下载1
在「3D视觉工坊」公众号后台回复:3D视觉,即可下载 3D视觉相关资料干货,涉及相机标定、三维重建、立体视觉、SLAM、深度学习、点云后处理、多视图几何等方向。
下载2
在「3D视觉工坊」公众号后台回复:3D视觉github资源汇总,即可下载包括结构光、标定源码、缺陷检测源码、深度估计与深度补全源码、点云处理相关源码、立体匹配源码、单目、双目3D检测、基于点云的3D检测、6D姿态估计源码汇总等。
下载3
在「3D视觉工坊」公众号后台回复:相机标定,即可下载独家相机标定学习课件与视频网址;后台回复:立体匹配,即可下载独家立体匹配学习课件与视频网址。
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、orb-slam3等视频课程)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近2000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、可答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~ 

