
- 1Linux——详细模拟实现shell(进程控制综合运用)_综合利用进程控制的相关知识,结合对shell功能的和进程间通信手段的认知,编写简易s
- 2食品饮料厂做配送小程序的作用是什么
- 3BCELoss BCEWithLogitsLoss 多标签损失函数_bcewithlogitsloss小于0
- 4国科大人工智能技术学院揭牌,第一批研究生正式入学_国科大ai
- 5m基于FPGA的8FSK调制解调系统verilog实现,包含testbench测试文件_fpga实现fsk
- 6【管理】管理者三种思维_管理者的三大思维观看感想
- 7谷歌浏览器所有历史版本下载_谷歌历史版本
- 8UML活动图与流程图的区别
- 9微信小程序不使用插件,渲染富文本中的视频,图片自适应,plus版本_微信小程序富文本
- 10bert+lstm+crf ner实体识别_bert + crf 实体识别 tensorflow
覆盖100种语言的多模态语言翻译模型 SeamlessM4T_seamless_communication
赞
踩
近期,Meta又发布了新的语音识别大模型 SeamlessM4T(大规模多语言和多模态机器翻译),模型支持多种语言的语音到语音翻译、语音到文本翻译、文本到语音翻译、文本到文本翻译以及自动语音识别,最多可覆盖100种语言。
论文描述了构建这一模型的方法,包括使用100万小时的开放式语音音频数据学习自监督语音表示以及创建多模态语音翻译语料库。
文章最后提到了SeamlessM4T在多种目标语言的翻译中取得了显著的改进,以及在性能、鲁棒性、性别偏见和评估方面的成果。
SeamlessM4T支持对近百种语言进行语音以及文本识别,同时支持近 100 种输入语言和 36 种输出语言的语音到语音翻译。

• 论文:https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf
• Demo:Seamless Communication Translation Demo
• Hugging Face:https://huggingface.co/spaces/facebook/seamless_m4t
01 动机
主旨是为了创建能够帮助个人在任何两种语言之间进行翻译的工具,即巴别鱼(Babel Fish)。之前的研究尽管文本模型在机器翻译领域取得了重大突破,覆盖范围已扩展到200多种语言,但语音到语音翻译模型尚未取得类似的进展。
文章指出传统的语音到语音翻译系统依赖于级联系统,由多个子系统逐步执行翻译,使得统一的可扩展高性能语音翻译系统难以实现。
本论文为了填补这些差距,作者提出了SeamlessM4T一体化语音到语音翻译的大模型。
02 方法

图 4 概述了 SeamlessM4T模型,包括其四个构建模块:
(1) SEAMLESSM4T-NLLB,一种大规模多语言 T2TT 模型;
(2) w2v-BERT 2.0,一种利用未标记语音音频数据的语音表示学习模型;
(3) T2U 文本到单元的序列到序列模型;
(4) 用于从单元合成语音的多语言 HiFi-GAN 单元声码器。
SeamlessM4T多任务 UNITY 模型集成了前三个构建块的组件,并分三个阶段进行了微调,从仅具有英语目标的 X2T 模型 (1,2) 开始,到成熟的多任务 UNITY (1,2,3) 系统结束执行 T2TT、S2TT 和 S2ST 以及 ASR。
03 无监督语音预训练
用于语音识别和翻译任务的已标记数据稀缺且昂贵,尤其是对于资源匮乏的语言。在监督能力有限的情况下训练语音翻译模型具有挑战性。
因此,使用未标记的语音音频数据进行自监督预训练是减少模型训练中监督需求的实用方法。与未经预训练的模型相比,该方法有助于以更少的标记数据实现相同的识别和翻译质量。它还有助于使用相同数量的标记数据突破模型性能的极限。
最新且公开的最先进的多语言语音预训练模型是 MMS Pratap 等人提出的,它扩展了其前身(XLS-R Babu et al., 2022提出),增加了 55K 小时的训练数据,涵盖 1300 多种新语言。
除了 MMS 之外,USM Zhang et al., 2023提出一种专有的 SOTA 多语言语音预训练模型,它利用最新的模型架构 BEST-RO,具有最大的规模训练数据(1200 万小时),涵盖 300 多种语言。w2v-BERT 2.0 遵循 w2v-BERT,将对比学习和屏蔽预测学习结合起来,并在两个学习目标中通过附加码书改进了 w2v-BERT。
对比学习模块用于学习Gumbel矢量量化(GVQ)码本和上下文表示,这些表示被馈送到后续的掩蔽预测学习模块中。后者通过直接预测GVQ代码的不同学习任务来细化上下文表示,而不是极化预测概率屏蔽位置处的正确和错误代码w2v-BERT 2.0 没有使用单个 GVQ 码本,而是遵循 Baevski 等人(2021)使用带有两个 GVO 码本的乘积量化。
ts 对比学习损失 L 与 w2v-BERT 中的相同,包括码本多样性损失以鼓励代码的统一使用。在 w2v-BERT 之后,本文使用 GVO 码本进行屏蔽预测学习,并将相应的损失表示为 Lmevo。
本文还使用随机投影量化器 Chiu 等人 2022 (RPO) 创建了一个额外的屏蔽预测任务。本文将相应的损失表示为 Lmrpo 整体 w2v-BERT 2.0 训练损失 定义如下:
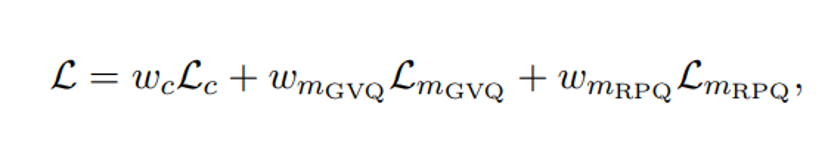
本文遵循 w2v-BERT XL 架构(Chung 等人,2021 年 SEAMLESSM4T-LARGE 中的 w2v-BERT 2.0 预训练语音编码器。其中有 24 个 Conformer Lavers Gulatiet al., 2020 和大约 6 亿个模型参数。w2v-BERT 2.0 模型在 100 万小时的开放语音音频数据上进行训练,涵盖超过 143 种语言。
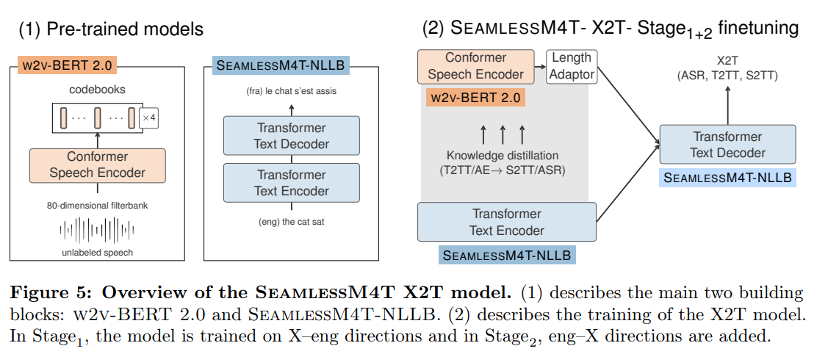
04 X2T:文本翻译和转录
本文的多任务 UnitY 框架的核心是 X2T 模型,这是一种多编码器序列到序列模型,其中一个用于语音输入的基于 Conformer 的编码器,另一个用于基于 Transformer 的编码器用于文本输入——两者它们与相同的文本解码器连接。本文的 X2T 模型是根据 S2TT 数据进行训练的将源语言的语音音频与目标语言的文本配对。
05 语音到语音翻译
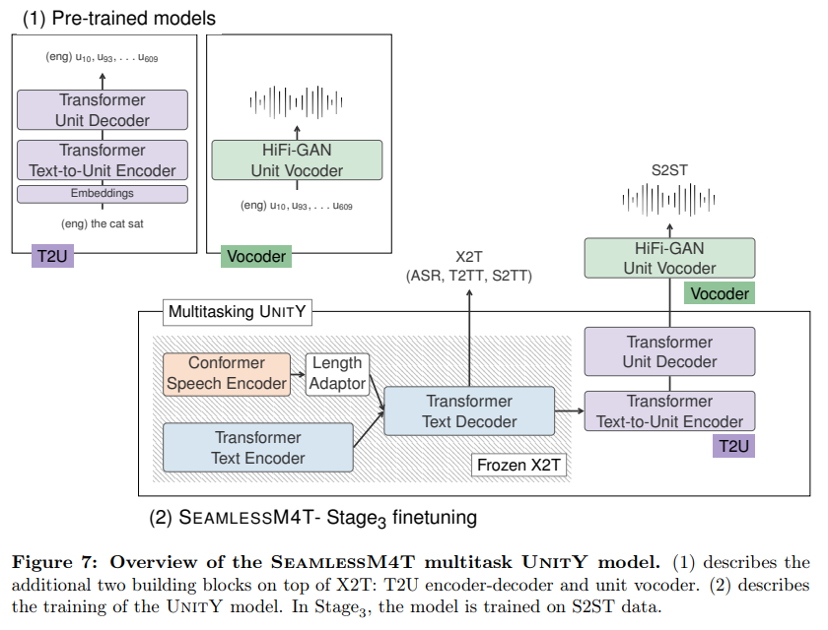
本文提出的语音到语音翻译模型的关键是使用自监督离散声学单元来表示目标语音,从而将 S2ST 问题分解为语音到单元翻译(S2UT)步骤和单元到单元语音(U2S)转换步骤。对于 S2UT,图 4 所示的 SeamlessM4T 模型使用 UnitY 作为两遍解码框架,该框架首先生成文本,然后预测离散声学单元。
与普通的 UnitY 模型相比,(1) 从头开始初始化的核心 S2TT 模型被预先训练的 X2T 模型取代,以联合优化 T2TT、S2TT 和 ASR,(2) 浅层 T2U模型(在 Inaguma 等人中称为 T2U 单元编码器和第二通道单元解码器)被替换为具有 6 个 Transformer 层的更深层的基于 Transformer 的编码器解码器模型,(3) T2U 模型也在T2U 任务而不是从头开始训练。X2T 的预训练产生了更强大的语音编码器和更高质量的首次通过文本解码器,而 T2U 模型的缩放和预训练使本文能够更好地处理多语言单元生成而不受干扰。
利用前面几节中列出的所有组件,本文在概述的三个阶段中训练了 SEAMLESSM4T-LARGE模型。SEAMLESSM4T-LARGE 具有 2.3B 参数,在 T2TT 上针对与英语配对的 95 种语言进行了微调,在 ASR 上针对 96 种语言进行了微调,在 S2TT 上针对与英语配对的 89 种语言进行了微调,在 S2ST 上针对 95 种英语方向和英语中的 35 种目标语言进行了微调,每个方向的监督数据量详见表 35 和 36。
这意味着,对于某些源语言,本文的模型将进行零样本评估,以达到 100-eng 的表 2 中描述的覆盖范围。为了提供合理大小的模型,本文遵循训练 SEAMLESSM4T-MEDIUM 的方法相同。
该模型的参数比 SEAMLESSM4T-LARGE 少 57%,旨在成为一个可访问的测试台,用于微调、改进或参与分析。
SEAMLESSM4T-MEDIUM 具有与 SEAMLESSM4T-LARGE 相同的覆盖范围,但建立在更小、更多的参数上 -高效组件(见图 4)。
本文预训练了一个具有 300M 参数的小型w2v-BERT 2.0,并使用 NLLB Team et al2022 的蒸馏模型 (NLLB-600M-DISTILLED) 来初始化多任务 UNIrY 的 T2TT 模块。参见表中 SEAMLESSM4T-LARGE 和 SEAMLESSM4T-MEDIUM 之间的比较见表13。

06 优势
提出的SeamlessM4T模型在多个评估指标上取得了显著的提升,支持多种语言的翻译,并且具有更好的鲁棒性和翻译安全性。通过自监督学习和自对齐构建了一个支持多语言和多模态的机器翻译系统,取得了显著的性能提升。
SeamlessM4T支持以下功能:
• 近100种语言的自动语音识别
• 近100种输入和输出语言的语音到文本翻译
• 近100种输入语言和35种(包括英语)输出语言的语音到语音翻译
• 近100种语言的文本到文本翻译
• 近100种输入语言和35种(包括英语)输出语言的文本到语音翻译
语音翻译相较于文本翻译在覆盖范围和性能上有所不足。当前的语音翻译系统主要是将其他语言翻译成英语,而不是从英语进行翻译。语音是一种比文本更丰富的媒介,通过语调、表达和交互传递更多信息,这使得语音翻译具有挑战性,但也更自然和社交性。
对于许多群体,如文盲或视力障碍者,语音比文本更易于访问,能够翻译语音的系统能够促进包容性。对于使用不同文字的语言,语音翻译避免了文本翻译可能出现的无法辨认的输出问题。
目前的语音翻译依赖级联系统,将自动语音识别(ASR)、机器翻译(MT)和文本到语音合成(TTS)模型链式组合。这可能会传播错误并导致失配。
本文提出了一个统一的模型SeamlessM4T,可以处理语音识别、语音到语音、语音到文本、文本到语音和文本到文本翻译。
SeamlessM4T扩展了源语言和目标语言的覆盖范围,从100种语言翻译到英语,以及从英语翻译到35种语言。达到了新的最先进水平,在翻译到英语的语音到文本翻译上,BLEU分数比以前的模型提高了20%。该模型开源,并且还开源了对齐的语音数据、挖掘工具和其他资源,以促进语音翻译研究。
参考文献
[1]SeamlessM4T - a large-scale multi-language and multi-modal translation machine https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf
[2] SeamlessM4T—大规模多语言和多模式机器翻译 https://zhuanlan.zhihu.com/p/652652292

