
- 1力扣第797题 所有可能的路径 C++ 深度优先搜索 +java_leetcode797c++
- 2java毕业设计——基于JSP+access的网络故障管理平台设计与实现(毕业论文+程序源码)——网络故障管理平台_jsp acce
- 3人脸识别门禁系统java实现_基于 Java 实现的人脸识别功能(附源码)
- 4数字技术能让古籍“活过来”吗?
- 5JVM垃圾收集器之CMS垃圾收集器和G1垃圾收集器_java cms垃圾回收器 g1垃圾回收
- 6adb 常用命令总结_adb常用指令
- 7mysql面试题10:MySQL中有哪几种锁?表级锁、行级锁、页面锁区别和联系?
- 8容联云孔淼:大模型落地与全域营销中台建设_容联云孔淼:大模型落地与全域营销中台建设
- 9数字经济时代,区块链能否担当产业数字化转型核心赋能者?
- 10“区块链+营销”:科技力量助力行业前行_区块链与市场营销的结合
分布式与一致性协议之一致哈希算法(二)
赞
踩
一致哈希算法
使用哈希算法有什么问题
通过哈希算法,每个key都可以寻址到对应的服务器,比如,查询key是key-01,计算公式为hash(key-01)%3,警告过计算寻址到了编号为1的服务器节点A,如图所示。
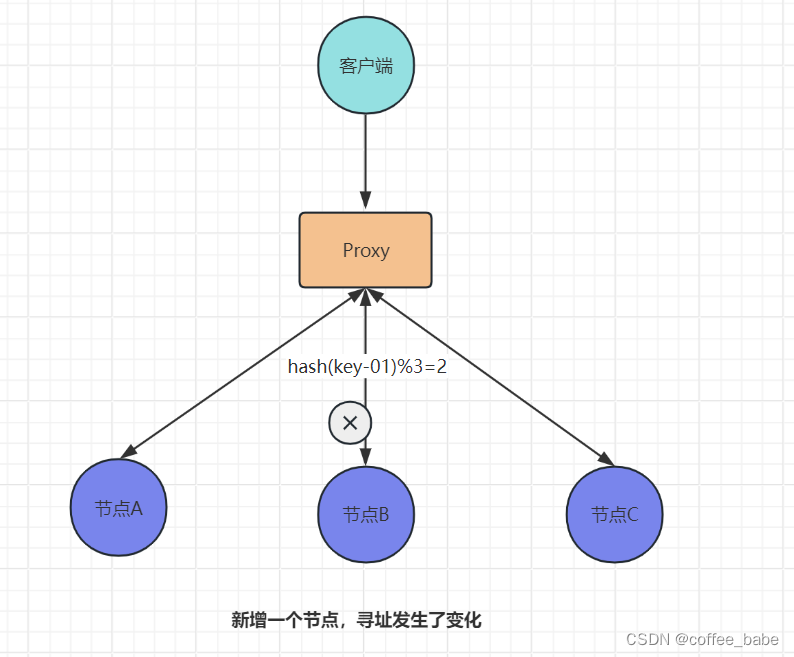
但如果服务器数量发生变化,我们基于新的服务器数量来执行哈希算法时,就会出现路由寻址失败的秦广,导致Proxy无法找到之前寻址到的那个服务器节点,这是为什么呢?
想象以下,加入3个节点不能满足当前的业务虚要,这时我们增加了一个节点,节点数量从3变为4,那么之前的hash(key-01)%3=1就变成了hash(key-01)%4=X,因为取模运算发生了变化,所以这个X大概率不是1(可能是2),这时你再查询,就会找不到数据,因为key-01对应的数据存储再节点A上,而不是节点B上,如图所示。
同样的道理,如果我们需要下线1个服务器节点(也就是缩容),也会存在类似的问题。而解决这个问题的办法在于我们要迁移数据,基于新的计算公式hash(key-01)%4来重新对数据和节点做映射。需要注意的是,数据的迁移成本是非常高的。
为了便于理解,我们用一个示例来说明。对于1000万个key 的3节点KV存储,如果我们增加1个节点,即3节点集群变为4节点集群,则需要迁移75%的数据,如代码所示
package main import ( "flag" "fmt" ) var keysPtr = flag.Int("keys", 10000000, "key number") var nodesPtr = flag.Int("nodes", 3, "node number of old cluster") var newNodesPtr = flag.Int("new-nodes", 4, "node number of new cluster") func hash(key int, nodes int) int { return key % nodes } func main() { flag.Parse() var keys = *keysPtr var nodes = *nodesPtr var newNodes = *newNodesPtr migrate := 0 for i := 0; i < keys; i++ { if hash(i, nodes) != hash(i, newNodes) { migrate++ } } migrateRatio := float64(migrate) / float64(keys) fmt.Printf("%f%%\n", migrateRatio*100) }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
go run ./hash.go -keys 10000000 -nodes 3 -new-nodes 4
74.999980%
- 1
- 2
从示例代码的输出可以看到,迁移成本非常高昂,这在实际生产环境中也是无法想象的
如何使用一致哈希算法实现哈希寻址
一致哈希算法也采用取模运算,但与哈希算法是对节点的数量进行取模不同,一致哈希算法是对2 ^ 32进行取模。你可以想象以下,一致哈希算法是将整个哈希空间组织成一个虚拟的圆环,也就是哈希换,如图所示,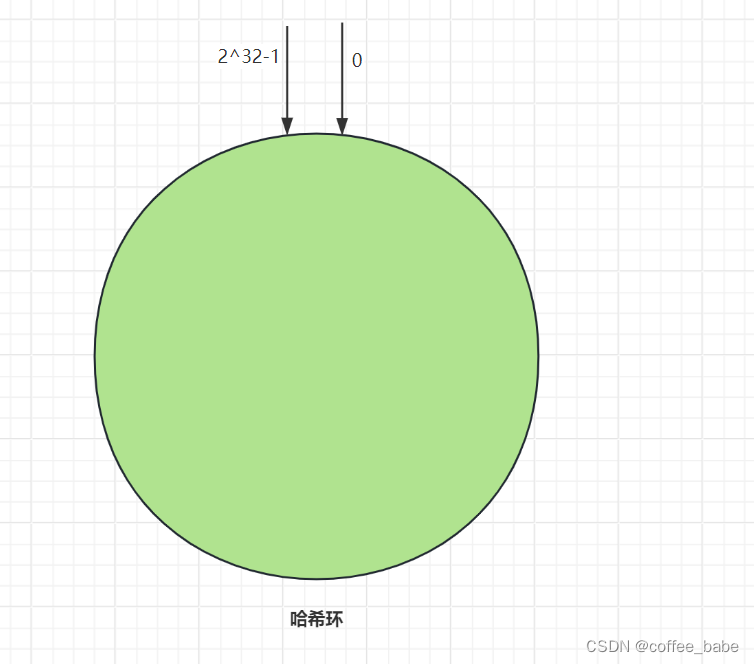
从图中可以看到,哈希环的空间是按顺时针方向组织的,圆环的正上方点的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、5、6…知道2 ^ 32-1,也就是说0点左侧的第一个点代表2^32-1.在一致哈希算法中,你可以通过执行哈希算法(为了演示方便,假设哈希算法函数为c-hash())将节点映射到哈希环上,比如选择节点的主机名作为参数进行c-hash()函数运算,确定每个节点在哈希环上的位置,如图所示。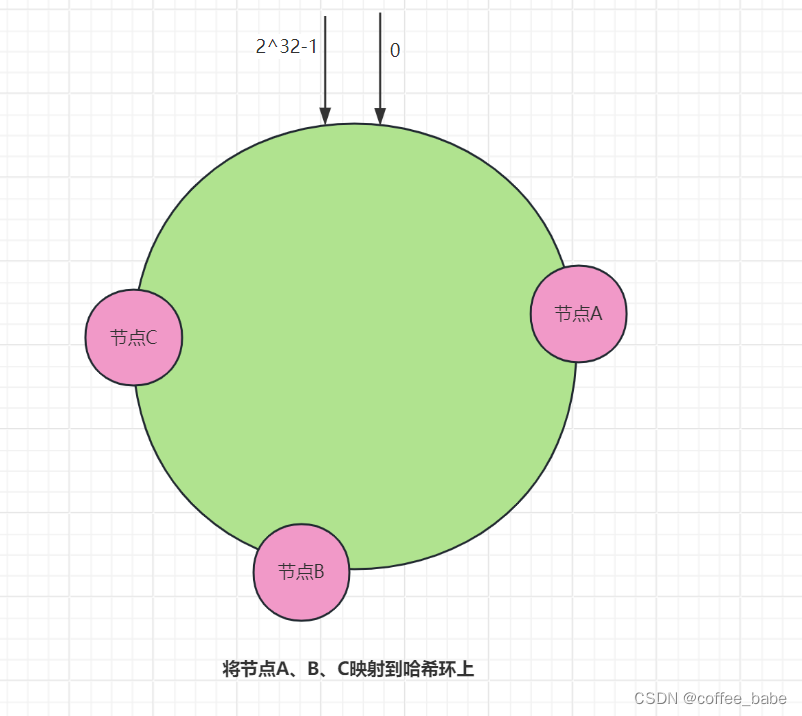
当需要对指定的key的值进行读写的时候,你可以通过下面两步进行寻址:
- 1.首先,将key作为参数进行c-hash()函数运算,计算哈希值,并确定此key在环上的位置
- 2.然后,从这个位置沿着哈希环顺时针"行走",遇到的第一节点就是key对应的节点
为了更好地理解如何通过一致哈希寻址,用一个示例来说明。假设key-01、key-02、key-03 3个key经过哈希算法c-hash()函数计算后,在哈希环上的位置如图所示。

那么根据一致哈希算法,key-01将寻址到节点A,key-02将寻址到节点B,key-03将寻址到节点C.你可能会问,那一致哈希是如何避免哈希算法的问题的呢?
假设现在有一个节点故障了(比如节点C),如图所示。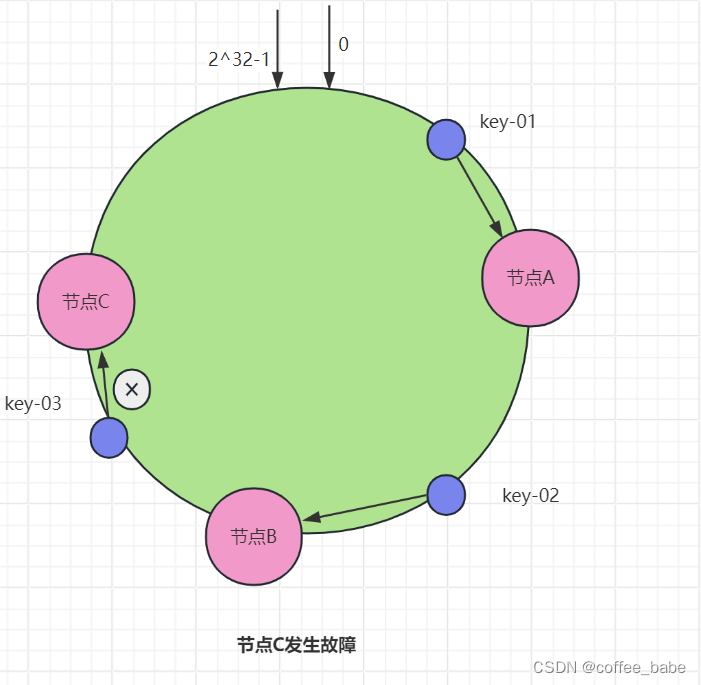
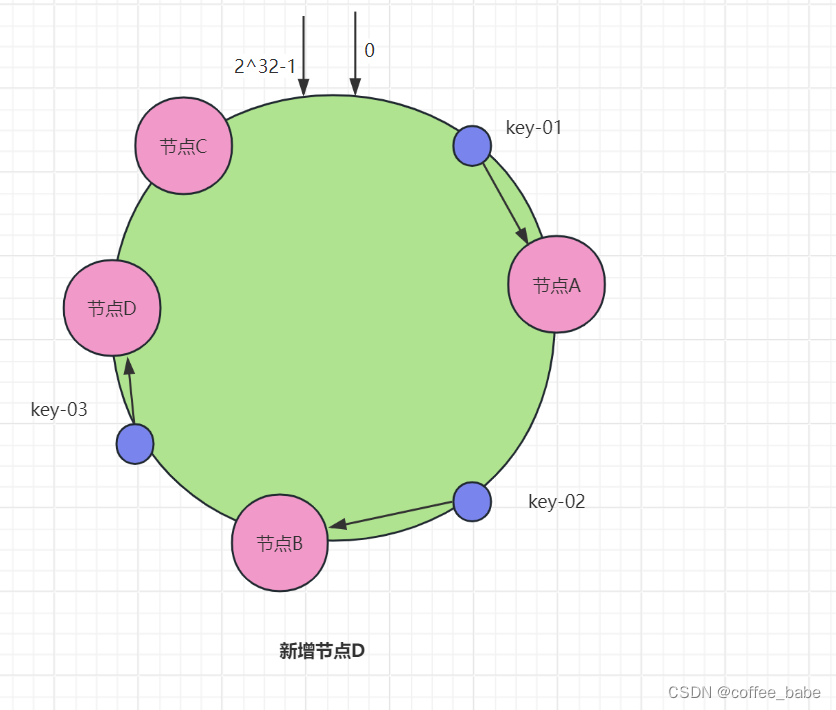
可以看到,key-01和key-02不会受到影响,而key-03得寻址将被重定位到A.一般来说,在一致哈希算法中,如果某个节点宕机不可用了,那么受影响的数据仅仅是会寻址到此节点和前一节点之间的数据。比如当节点C宕机时,受影响的数据是会寻址到节点B和节点C之间的数据(例如key-03),而寻址到其他哈希环空间的数据(例如key-01)不会受到影响。如果此时集群不能满足业务的需求,则需要扩容一个节点(也就是增加一个节点,比如D),如图所示.
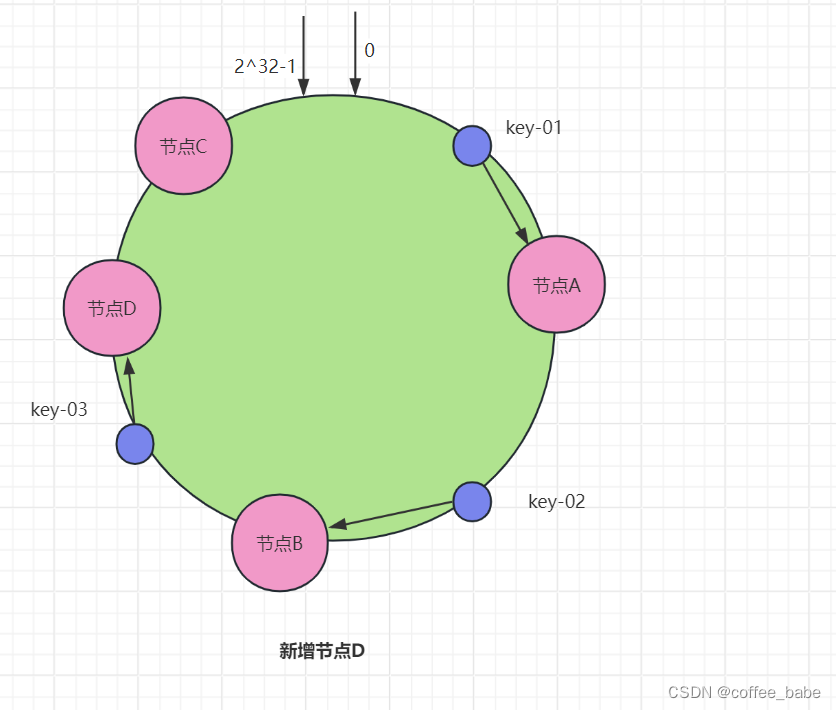
可以看到,key-01、key-02不会受到影响,而key-03的寻址被重定位到新节点D.一般而言,在一致哈希算法中,如果增加一个节点,受影响的数据仅仅是会寻址到新节点和前一节点之间的数据,其他数据则不会受到影响。

