
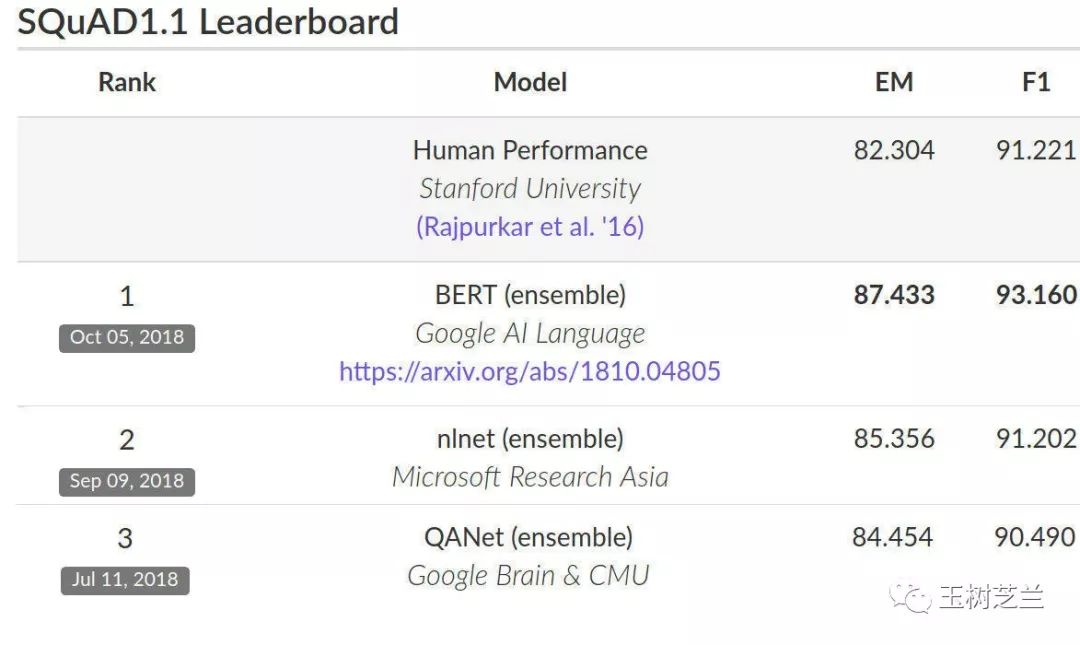
- 12024百度Create大会:李彦宏带来三大AI开发工具,让人人都是开发者
- 2IDEA怎么部署MyEclipse得web项目_idea 发布 myeclipse web
- 3Android工程源码版本信息_安卓系统源码编译的编译系统版本号
- 4Android Studio新建java项目_android studio 新建项目怎么选择java而不是kotlin
- 5国外新闻媒体推广:多元化媒体分发投放-大舍传媒
- 6【Web】HNCTF 2022 题解(全)
- 7简单又实用!朋友圈定时发布就这样设置!_微信定时分享朋友圈
- 8【2024年MathorCup数模竞赛】C题完整解析(代码与技术文档)_2024mathorcupc题
- 9《AI编程类工具之四——GitHub copiot》_github aiops
- 10如何在Github上快速下载代码_github下载代码
如何用 Python 和 BERT 做多标签(multi-label)文本分类?
赞
踩

10余行代码,借助 BERT 轻松完成多标签(multi-label)文本分类任务。
疑问
之前我写了《如何用 Python 和 BERT 做中文文本二元分类?》一文,为你讲解过如何用 BERT 语言模型和迁移学习进行文本分类。
不少读者留言询问:
王老师,难道 BERT 只能支持二元分类吗?
当然不是。
BERT 是去年以来非常流行的语言模型(包括 ELMO, Ulmfit, BERT, Ernie, GPT-2等)的一种,长期霸榜,非常强悍。
研究者已经证明,它可以很好地处理多种自然语言处理任务。甚至在部分任务上,超越了人类水平。
它处理自然语言任务,靠的是迁移学习的威力。
复习一下,我在《如何用 Python 和深度迁移学习做文本分类?》一文里,给你讲过迁移学习的范例 ULMfit (Universal language model fine-tuning for text classification)。
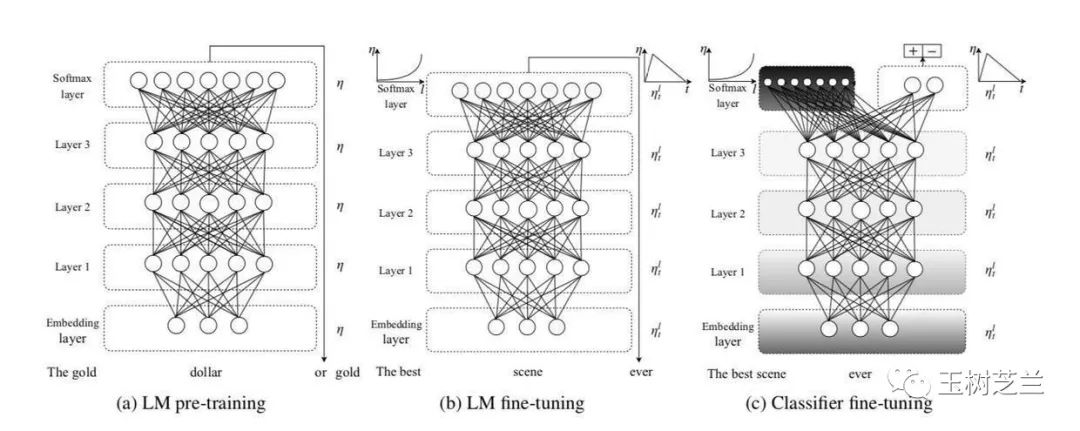
其原理就是首先让一个深度神经网络在海量文本上自监督学习(self-supervised learning)。
自监督和非监督(unsupervised)学习的区别,在于自监督学习,实际上是有标记的。
例如我们找到大量的语料,把常出现的词语放在一起,配对成(输入,输出)格式,例如(France, Paris)。这里 Paris 就可以看做是 France 的标记。然后学习的方式跟监督学习没有差别。
这也是著名的 word2vec 训练方式。
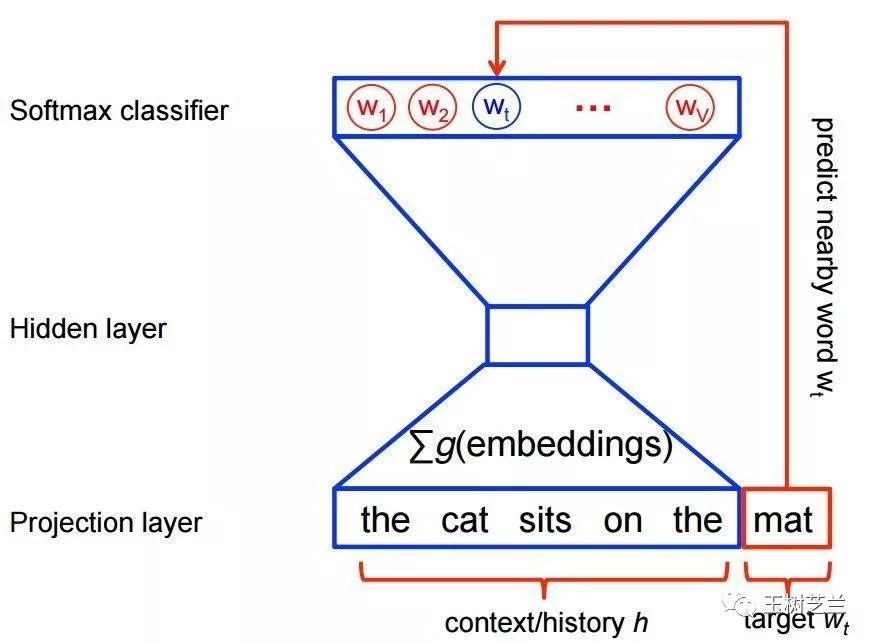
那问题来了,为什么不干脆叫监督学习?
因为监督学习,往往是指需要人工参与打标记的。例如你已经熟悉的情感分类任务,都是人阅读以后标记1或者0的。
可在语言模型这里,你利用了语料自身中词语的自然位置关系,没有主动人工打标记。所以为了区分,我们叫它“自监督学习”。
经过足够长时间的训练,这个神经网络就学会了该领域语言的特性。
然后,我们给这个神经网络,加上一个头部,就可以让它来完成特定的目标。
加上全连接层作为分类器,就可以把输入文本做分类(classification),例如我们讲解过的情感分析。
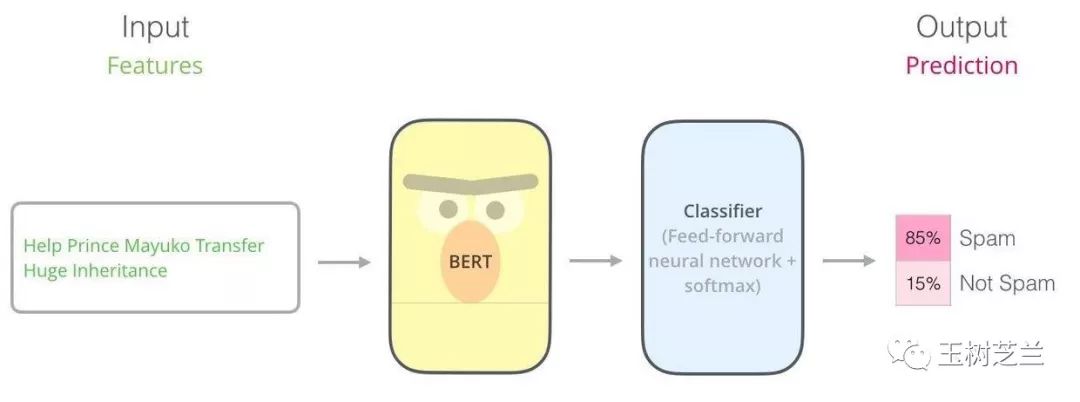
加上解码器(decoder),就可以把输入文本序列,转换成另一种序列。这就可以完成文本翻译、问答,甚至是文本转语音。
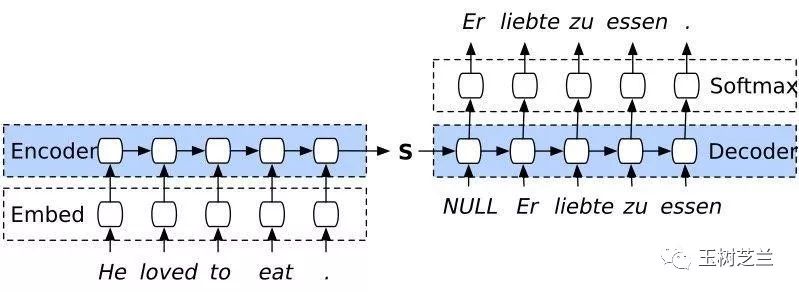
加上生成器(generator),例如卷积神经网络,就可以把序列转换成多层矩阵。这样,机器就可以根据你的文字输入,为你输出对应的图像来。
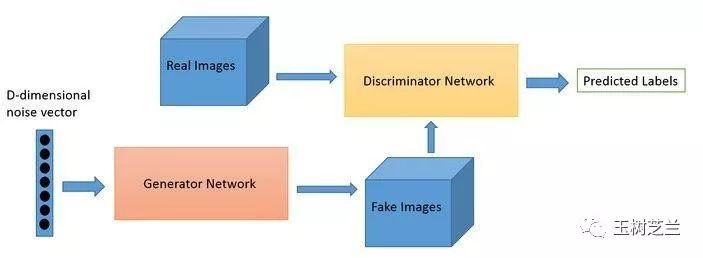
我以二元分类任务举例,仅仅是因为它足够简单,便于说明。
你完全可以举一反三,直接使用它来做多类别(multi-class)分类任务,例如三分类情感分析(正向、负向、中性)之类。
这时候,《如何用 Python 和 BERT 做中文文本二元分类?》一文中其他的代码,都是可以复用的。
你只需要调整一下测量指标(Evaluation Metrics)。
例如说,f1 分数专门针对二分类。你用它衡量多分类任务,程序会无所适从。
把它删除,或者替换成 micro f 或者 macro f 分数,就好了。
本文,我们来看看其他同学提出的这个更有挑战性的问题:
老师,BERT 能否做多标签(multi-label)分类?
多标签
先来解释一下,什么叫做多标签(multi-label)文本分类问题。
这里咱们结合一个 Kaggle 上的竞赛实例。
竞赛的名字叫做:恶毒评论分类挑战(Toxic Comment Classification Challenge),链接在这里。
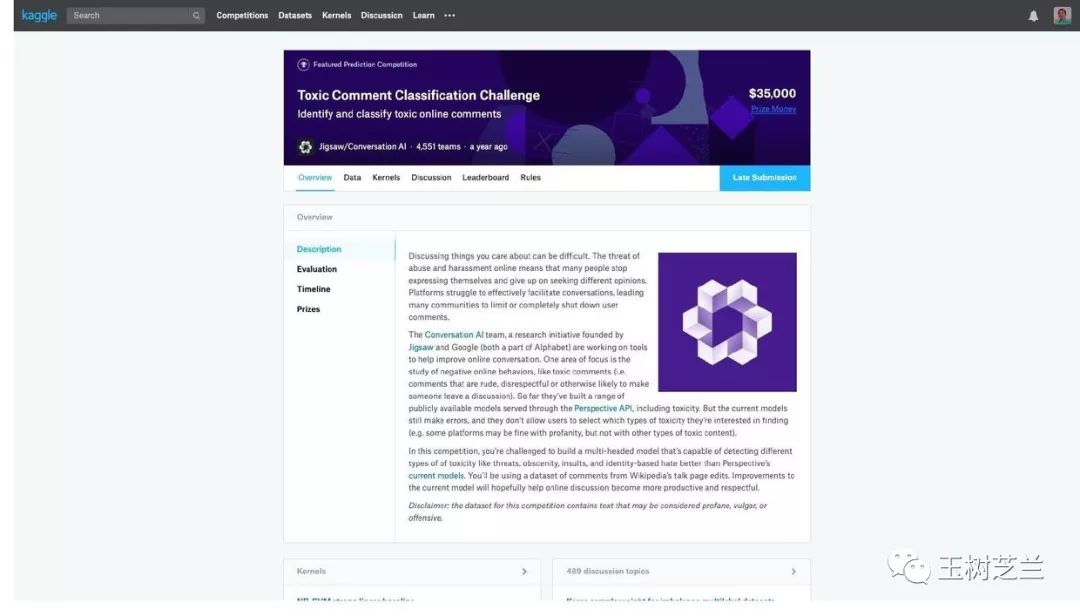
这个竞赛的数据,取自真实的网络评论。
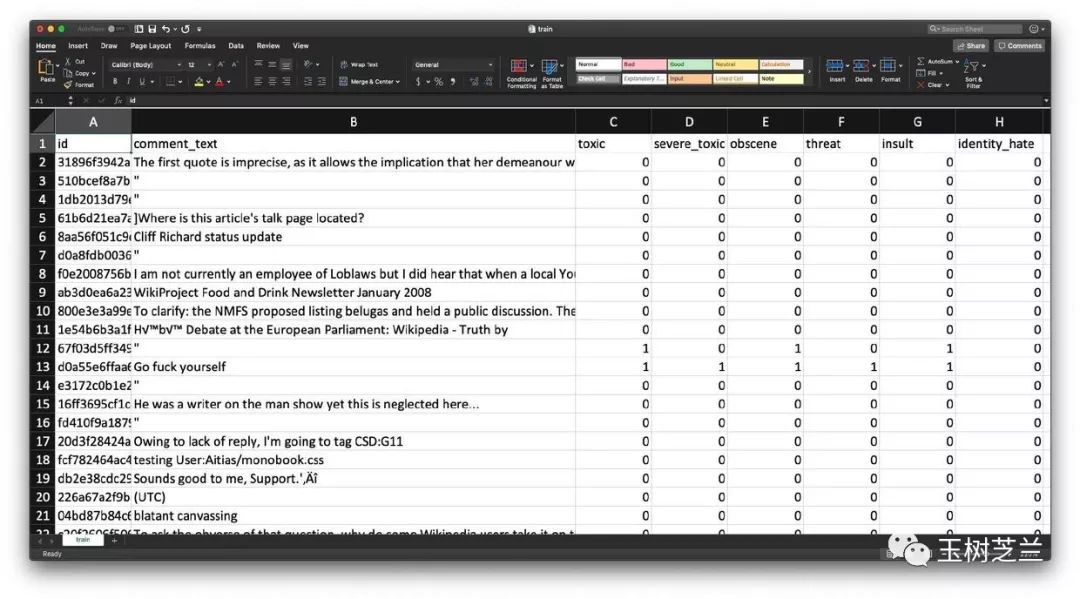
除了序号和原始文本以外,每行数据都包含了6个维度的标注,分别是:
toxic(恶毒)
severe_toxic(非常恶毒)
obscene(污言秽语)
threat(威胁)
insult(侮辱)
identity_hate(憎恨)
这就是我们的任务:
对于一个样本,需要同时在6个不同维度上判断它是否属于该标签范畴。
我觉得这个竞赛的初衷非常好。
因为网上恶毒评论过多,会降低用户高质量内容贡献度,让社区变得沉寂。
而人工处理,显然效率和速度都不理想,而且成本过高。
用机器自动甄别,可以第一时间直接屏蔽恶毒评论,有助于打造良好的网络社群环境和讨论氛围。
并且,成本还很低。
你可以很容易看出,这种多标签标注和多元分类标注的区别。
多元分类任务里面,分类互斥。一个样本属于某种分类,不能同时属于另一种分类。
例如一条评论,不能同时属于“正向”或者“负向”情感。
一张图片,不能同时属于“哆啦A梦”或者“瓦力”。
但是这个多标签分类例子里面,我们不难看出,一个“非常恶毒”的评论,同时也必定是“恶毒”的评论。
因此一个样本,可能同时属于上述两种,甚至全部六种类别。
当然,也有可能不属于任何一种类别。
了解了任务后,下一个问题自然是:怎么做?
最简单的偷懒办法,是分别建立6个独立的模型。
第一个模型,判断是否“恶毒”。
……
最后一个模型,判断是否“憎恨”。
这样一来,我们就可以把一个多标签分类问题,转化成6个二元分类问题。
解决了?
对。
很多论文,就是这么处理多标签分类任务的。
这样做有问题吗?
有。
因为6个独立模型,可能会判断出某条评论“非常恶毒”的同时,却认为它不“恶毒”。
这显然是个荒唐结论。
但既然模型是独立的,哪里管得了这么多?
好在,多标签分类任务,其实是可以只用一个模型来解决的。
一个模型的好处有很多。
例如可以对上述荒唐结论进行惩罚(penalize),从而让机器避免得出这样不合乎逻辑的判定结果。
而且,可以节省大量的时间、存储和计算资源。
本文,我们就讨论如何基于 BERT ,构造这样的多标签分类模型。
发现
本来,我是打算在之前 BERT 二元分类代码的基础上,实现多标签分类功能,然后把代码和教程提供给你的。
再次强调,我做的工作主要是简化(而非从头撰写)代码,使得你可以利用它学习,以及替换成你自己的数据来使用。
但是,现在正是 Tensorflow 大版本切换的过渡期。
之前分享的 BERT 二元分类原始代码采用 Tensorflow 1.X 代码编写,底层代码处理起来非常麻烦。
而且一旦 2.0 正式版推出,之前写好的 1.X 版代码需要大幅修改,甚至重来。
这种西西弗斯推石头般的无用功,让人望而却步。
这时,有人捷足先登了。
完成这件事的,就是我的 LinkedIn 好友 Kaushal Trivedi 。
早在今年1月份,他就在 medium 发布了关于 BERT 多标签分类的文章。
那一篇文章的配套代码,他是直接基于 PyTorch 撰写的,包含了大量底层细节。
对于应用来说,源代码包含底层细节过多,可不是什么好事儿。
因为这意味着以下几个特点:
代码很长
为了适应自己的任务,找需要修改的地方很麻烦
出错之后,不容易检查
这就是为什么软件工程会强调封装。
所谓封装,就是把已经通过反复测试的内容包裹起来。只在更高层次上,让开发者或者用户跟输入输出接口打交道。
这样可以避免重复造轮子,而且更不容易发生错误。
受 fast.ai 的启发,Kaushal Trivedi 做了一个新的项目,叫做 fast-bert 。
看,连名字都向 fast.ai 致敬了。
这次的代码简洁明快多了。
Kaushal Trivedi 还专门写了一篇文章,讲述了如何用 fast-bert 来进行多标签分类。用的样例就是咱们刚才提到的恶毒评论分类数据。
然而,由于这个软件包刚刚研发出来,所以坑非常多,包括但不限于:
文章内的代码不完整
Github 上的样例 ipynb 文件需要特定底层 Linux 编译软件包支持
样例数据过大,导致执行时间过长
Colab 上执行,会出现内存耗尽报错
……
把所有坑都踩过来之后,我觉得还是有必要整理出一个可以在 Google Colab 上让你直接执行,并且可以套用自己数据的版本。
毕竟,我们都喜欢免费的 GPU,对吧?
现在,我已经完成了这项工作。
这篇文章就将成果分享给你。
数据
如果你使用恶毒评论分类数据全集的话,训练数据有十几万条。
即便用上了 Colab 的 GPU ,执行起来也会花费好几个小时的时间。
顺便说一句,Colab 的免费 GPU 最近升级了,已经从原来速度慢、内存容量小的 K80,换成了 Tesla T4 。
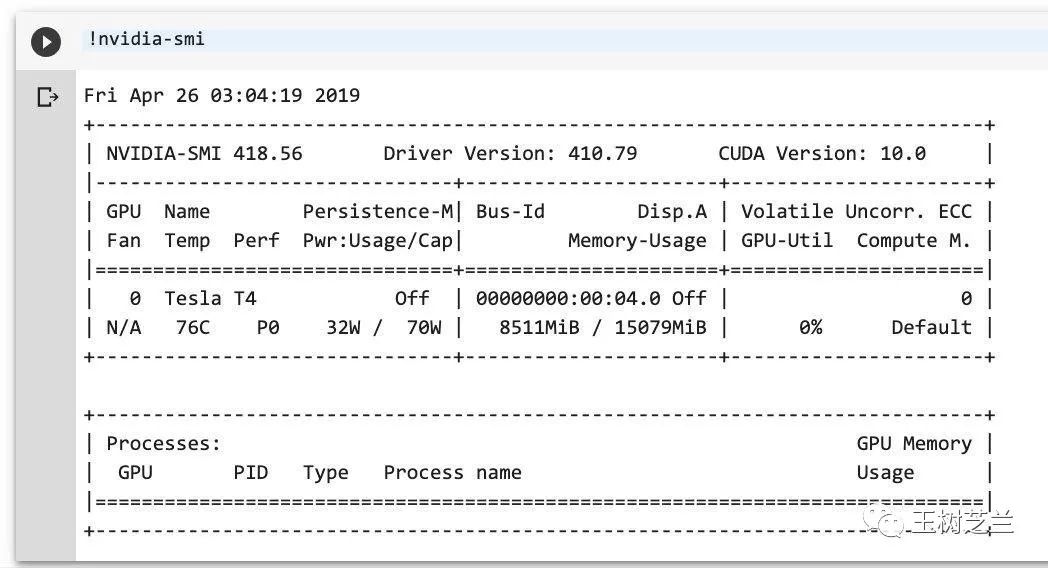
这里为了让你快速看到运行结果,我对数据进行了采样。
目前的训练集包含 4000 条数据,验证集只有 1000 条。比起原始数据,这只是不到20分之一而已。
同样,对于测试集,我也只采样了 1000 条。
这样做,会有不利的影响,那就是分类效果会降低。
请记住现在的结果,是在数据相对较少的基础上训练出来的。因此结果如果不理想,并不能代表 BERT 的能力不够强。
环境
本文的配套源代码,我放在了 Github 上。链接获取方式请见本文末尾。
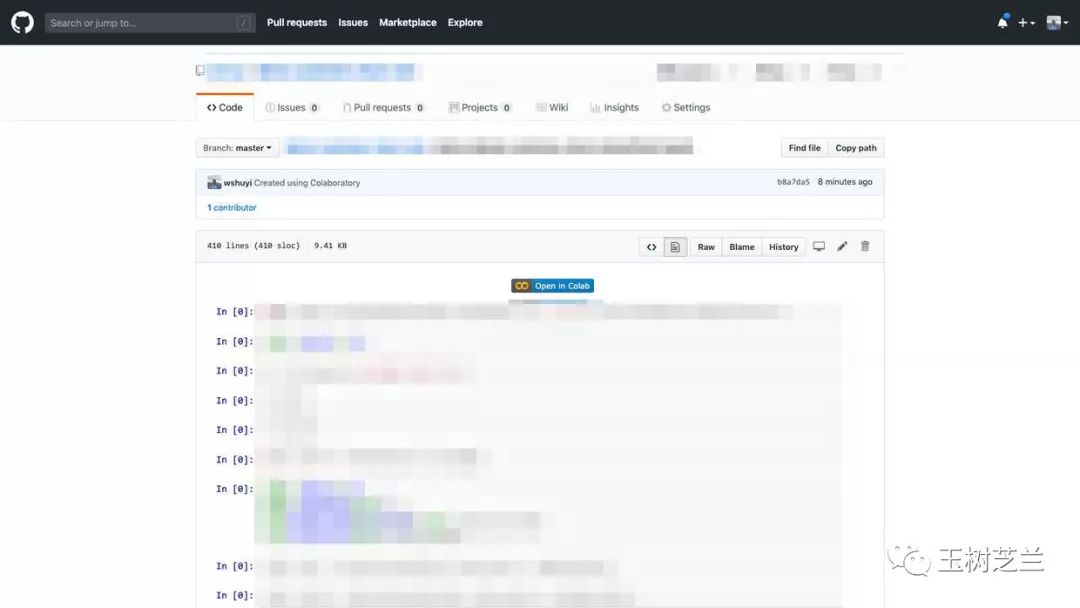
如果你对我的教程满意,欢迎在页面右上方的 Star 上点击一下,帮我加一颗星。谢谢!
注意这个页面的中央,有个按钮,写着“在 Colab 打开”(Open in Colab)。请你点击它。
然后,Google Colab 就会自动开启。
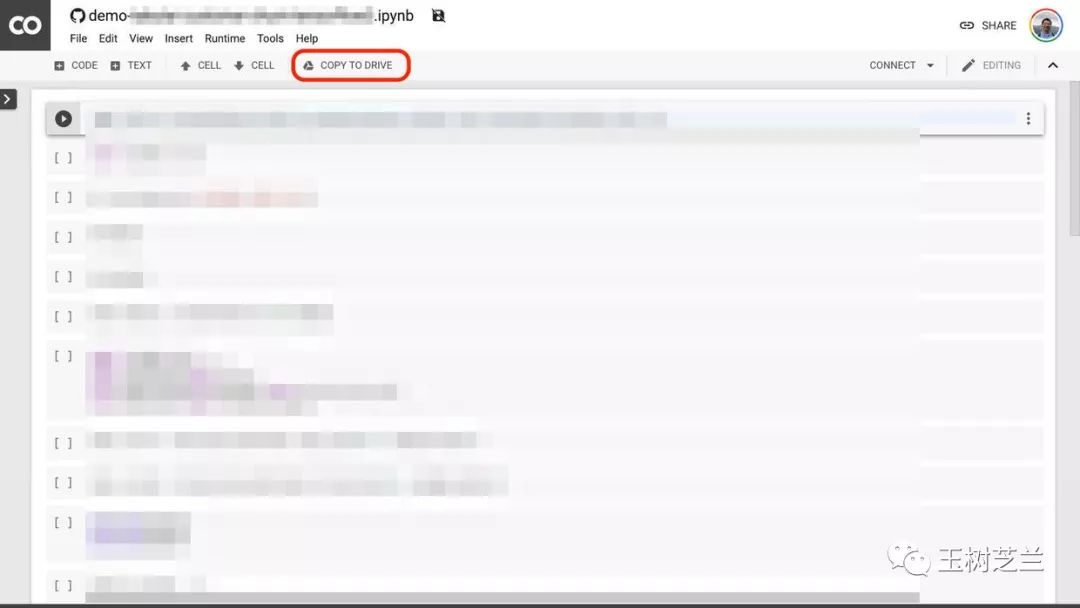
我建议你点一下上图中红色圈出的 “COPY TO DRIVE” 按钮。这样就可以先把它在你自己的 Google Drive 中存好,以便使用和回顾。
Colab 为你提供了全套的运行环境。你只需要依次执行代码,就可以复现本教程的运行结果了。
如果你对 Google Colab 不熟悉,没关系。我这里有一篇教程,专门讲解 Google Colab 的特点与使用方式。
为了你能够更为深入地学习与了解代码,我建议你在 Google Colab 中开启一个全新的 Notebook ,并且根据下文,依次输入代码并运行。在此过程中,充分理解代码的含义。
这种看似笨拙的方式,其实是学习的有效路径。
代码
为了让你把注意力集中在重要的环节,我这里把全部的准备工作都集中在了第一个代码段落,并且隐藏了其内容。
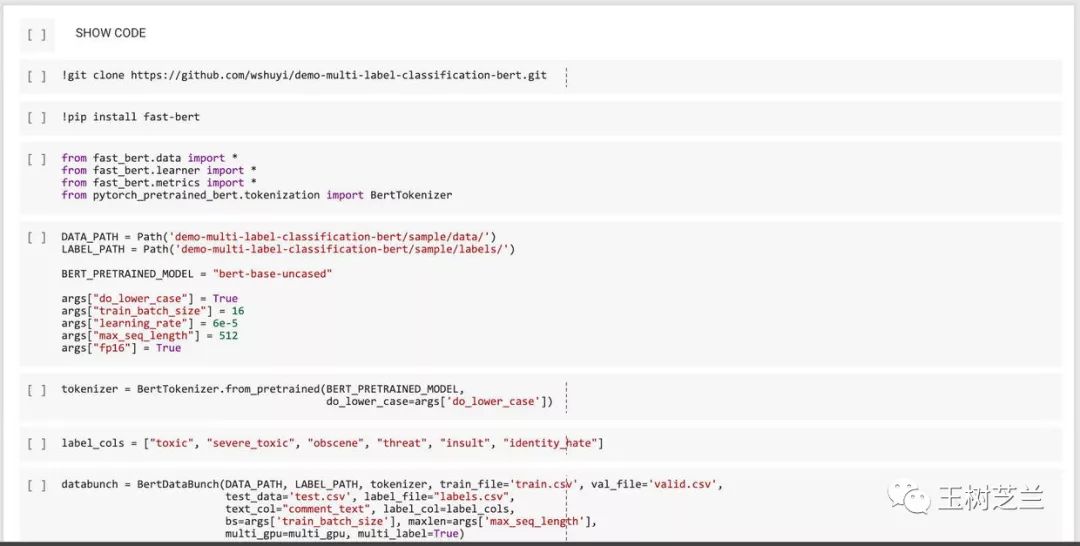
如果你需要查看和修改,只需要点击该代码段即可。
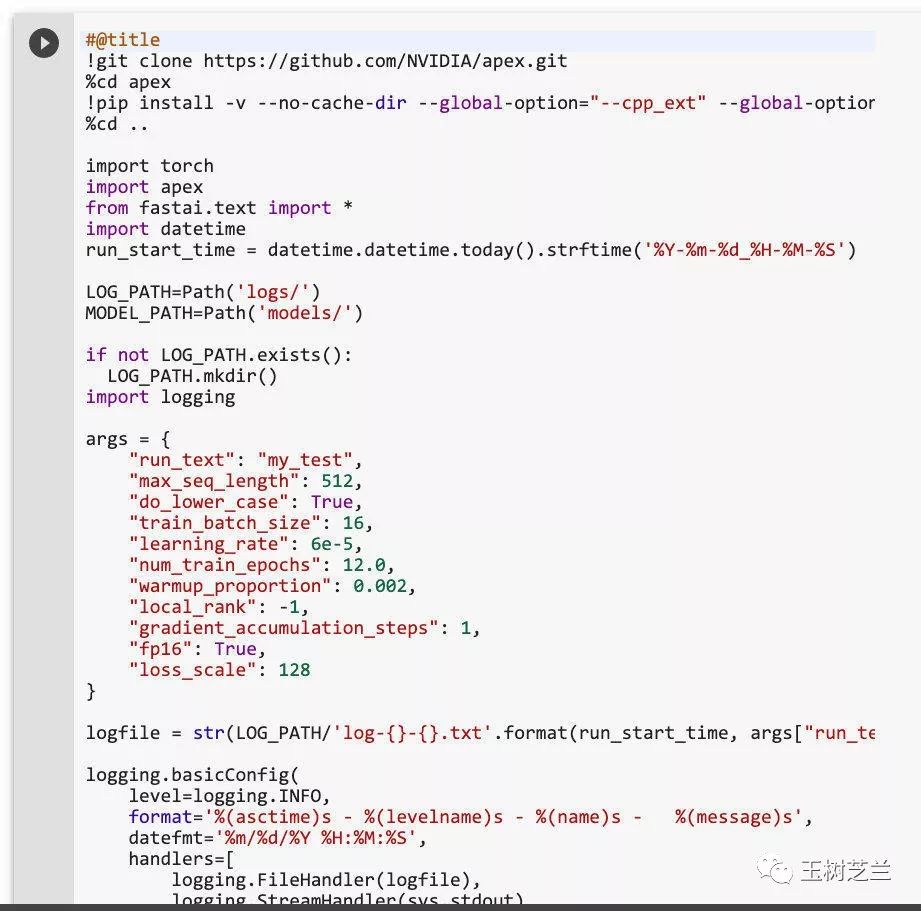
或者,你现在可以忽略并直接执行它。这大概需要花几分钟的时间。因为有个底层的软件包需要编译,才能支持 fast-bert 软件包。
下面,才是咱们要关注和讲解的部分。
首先,我们把数据下载下来。
!git clone https://github.com/wshuyi/demo-multi-label-classification-bert.git
注意这里包含的数据,不只有采样版本,也包含了原始数据。
你在尝试过本教程后,也可以重新载入原始数据,看模型效果是否会有显著提升。
之后,是咱们的主角 fast-bert 登场。
!pip install fast-bert我们需要从 fast-bert 以及它依赖的软件包 pytorch_pretrained_bert 读入一些预置函数。
- from fast_bert.data import *
- from fast_bert.learner import *
- from fast_bert.metrics import *
- from pytorch_pretrained_bert.tokenization import BertTokenizer
之后,是参数设定。
- DATA_PATH = Path('demo-multi-label-classification-bert/sample/data/')
- LABEL_PATH = Path('demo-multi-label-classification-bert/sample/labels/')
-
-
- BERT_PRETRAINED_MODEL = "bert-base-uncased"
-
-
- args["do_lower_case"] = True
- args["train_batch_size"] = 16
- args["learning_rate"] = 6e-5
- args["max_seq_length"] = 512
- args["fp16"] = True
这里为你解释一下各项参数的含义:
DATA_PATH:数据路径。包含训练、验证和测试集的csv文件。LABEL_PATH:标记路径。注意它只是把所有标记的类别每个一行,写在了一个 csv 中,短小精悍。BERT_PRETRAINED_MODEL:使用的预训练模型。我们这里使用的是英文不分大小写版本bert-base-uncased。args["do_lower_case"]:数据处理中是否全部转换小写。这里设定为“是”。args["train_batch_size"]:训练集批次大小。这里设定为16。如果设定为32的话,Colab 的 GPU 会报告内存溢出错误。args["learning_rate"]:学习速率。args["max_seq_length"]:最大序列长度。这里我们设定为512。当然如果你处理 Twitter 数据,140就够了。args["fp16"]:以16位浮点精度来进行运算。可以加快运算速度,节省存储空间。
下面我们从预训练模型中,获得数据处理器。
- tokenizer = BertTokenizer.from_pretrained(BERT_PRETRAINED_MODEL,
- do_lower_case=args['do_lower_case'])
把全部的标签类别输入到列表中。
label_cols = ["toxic", "severe_toxic", "obscene", "threat", "insult", "identity_hate"]终于可以正式读取数据了。
- databunch = BertDataBunch(DATA_PATH, LABEL_PATH, tokenizer, train_file='train.csv', val_file='valid.csv',
- test_data='test.csv', label_file="labels.csv",
- text_col="comment_text", label_col=label_cols,
- bs=args['train_batch_size'], maxlen=args['max_seq_length'],
- multi_gpu=multi_gpu, multi_label=True)
这里填充的参数,基本上都可以通过其名称直接了解含义。所以我这里只给你讲解以下几个重点:
text_col是指训练集、验证集和测试集里面,文本所在那一列的表头名称。multi_gpu是指要不要使用多 GPU 并行运算。这里前面代码已经自动获取了取值,你不需要修改它。multi_label说明了咱们要进行的是多标签分类任务。
读取后的数据,存在了 databunch 中。模型可以直接使用。
我们指定模型效果测量标准。
metrics = [{'name': 'accuracy', 'function': accuracy_multilabel}]因为是多标签分类,所以我们用的是准确率衡量指标是 accuracy_multilabel 。
我们把当前的参数设置,存入到日志记录器中。
logger.info(args)开始构造模型了。
- learner = BertLearner.from_pretrained_model(databunch, BERT_PRETRAINED_MODEL, metrics, device, logger,
- is_fp16=args['fp16'], loss_scale=args['loss_scale'],
- multi_gpu=multi_gpu, multi_label=True)
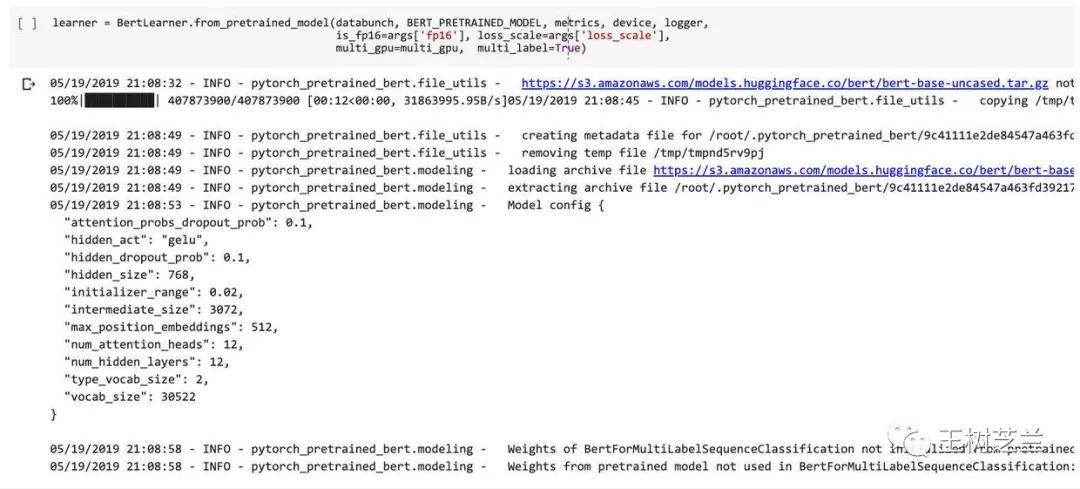
因为指定了 multi_label=True ,程序会自己构造模型的头部,以便正确处理多标签分类任务。
训练开始。
这里我们设定跑4个周期(cycle)。
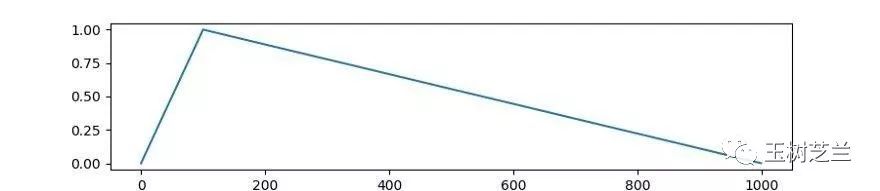
learner.fit(4, lr=args['learning_rate'], schedule_type="warmup_linear")根据 BERT 的设定,训练中间学习速率是要进行变化的。我们设定变化方式为 warmup_linear 。
它将在每一个周期中,把学习速率按类似下图这样的方式进行调整:
运行结果如下:
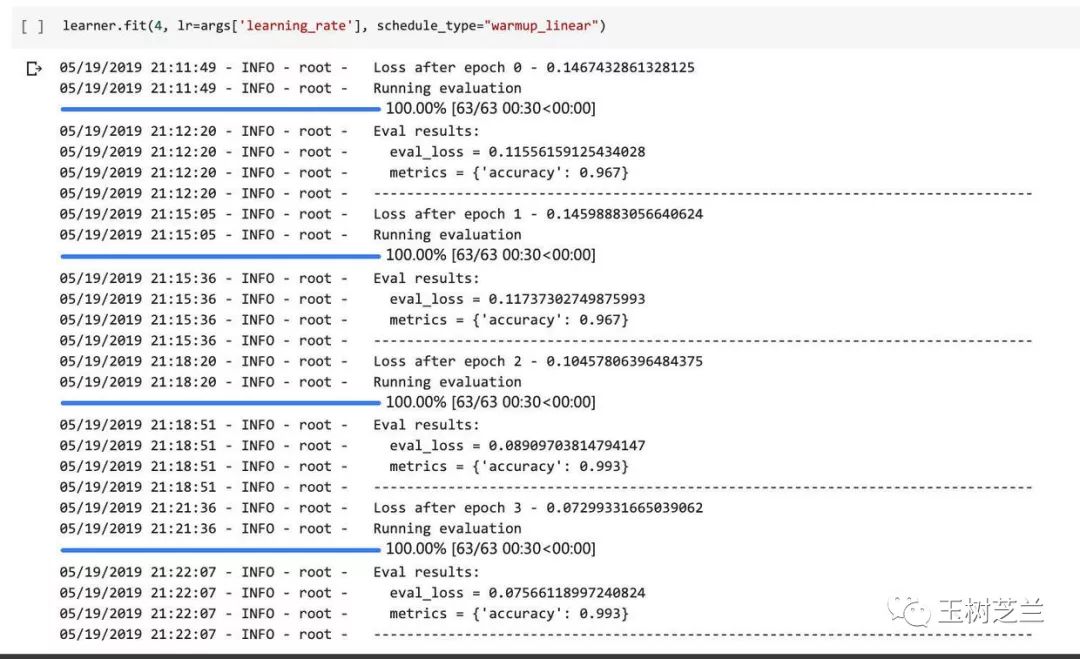
4轮周期跑下来,模型在验证集准确率达到了 0.993 。这就意味着平均每 1000 个样本,多标签分类准确数量 993 个。
这个结果怎么样?
够不够好?为什么?
这个问题作为今天的思考题。欢迎你把自己的想法记录下来写在留言区,咱们一起交流讨论。
小结
通过阅读本文,希望你已经掌握了以下知识点:
除二元分类外,语言模型(例如 BERT )的其他应用场景
多类别(multi-class)分类和多标签(multi-label)分类的区别
自监督学习(self-supervised learning)的概念
多标签分类的独立模型转化法
使用 BERT 单模型进行多标签分类
希望这些知识和技能,可以帮助你解决研究和工作中遇到的实际问题。
祝深度学习愉快!
延伸阅读
你可能也会对以下话题感兴趣。点击链接就可以查看。
喜欢请点赞。
特别喜欢的话,欢迎点击“喜欢作者”,请我喝杯咖啡。谢谢!
由于微信公众号外部链接的限制,文中的部分链接可能无法正确打开。如有需要,请点击文末的“阅读原文”按钮,访问可以正常显示外链的版本。
订阅我的微信公众号“玉树芝兰”,第一时间免费收到文章更新。别忘了加星标,以免错过新推送提示。

知识星球入口在这里:
题图:Photo by Pro Church Media on Unsplash
代码链接获取方法
第一步,微信关注公众号“玉树芝兰”(nkwangshuyi)。
第二步,在后台回复“bert”(注意大小写)。


