
- 1ZooKeeper分布式协调框架_绘制zookeeper对分布式habse进行集群支持协同管理的流程架构图
- 2SQLite3 使用基础_sqlite编译后如何作为服务启动
- 3springboot-集成flink最佳实践和打包部署_springboot flink
- 4leetcode刷题
- 5前端必会的7种设计模式(学习笔记)_前端设计
- 6Android 13运行时权限变更一览_android 13授权
- 7数据湖存储解决方案之Paimon_paimon文件系统
- 8E: Unable to locate package gcc
- 9关于XGBoost模型的浅理解以及用法
- 10合肥特殊教育中专学校计算机,安徽省特殊教育中专学校
文本向量化模型新突破——acge_text_embedding勇夺C-MTEB榜首_acge-embedding
赞
踩
在人工智能的浪潮中,以GPT4、Claude3、Llama 3等大型语言模型(LLM)无疑是最引人注目的潮头。这些模型通过在海量数据上的预训练,学习到了丰富的语言知识和模式,展现了出惊人的能力。在支撑这些大型语言模型应用落地方面,文本向量化模型(Embedding Model)的重要性也不言而喻。
近期,我在浏览huggingface发现,国产自研文本向量化模型acge_text_embedding(以下简称“acge模型”)已经在业界权威的中文语义向量评测基准C-MTEB(Chinese Massive Text Embedding Benchmark)中获得了第一名。今天这篇文章将围绕以下问题,为大家带来acge_text_embedding模型解读以及应用思考:
• 文本向量化acge模型是什么?原理是什么?
• acge模型能达到什么样的效果,取得了什么样的成绩?
• 文本向量化模型的突破与检索增强生成RAG的联系?
一、文本向量化模型新突破——acge模型
1.1、文本向量化模型
文本向量化模型是自然语言处理(NLP)中的一项核心技术,它可以将单词、句子或图像特征等高维的离散数据转换为低维的连续向量,从而将文本数据转换为计算机能够处理的数值型向量形式。如下图所示,文本向量化模型通过将“家常菜烹饪指南”转换为数值向量,可以将文本信息表示成能够表达文本语义的向量。
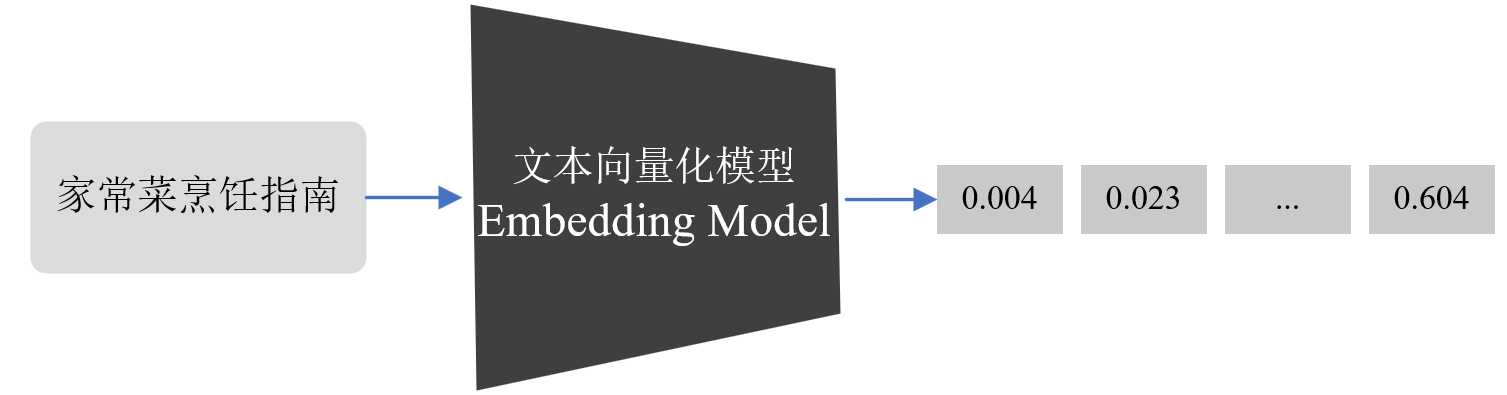
当文本信息被转换为向量形式后,输出的结果能够进一步地为多种后续任务提供有力支持,如:
- 搜索:向量化使得搜索引擎能够根据查询字符串和文档之间的向量相似性来排名搜索结果,排名靠前的结果通常与查询字符串最相关。
- 聚类:在文本聚类任务中,向量化可以被用来度量文本之间的相似性,从而将文本分组成不同的类别或簇。
- 推荐:向量化可帮助构建用户和项目的表示特征,使得推荐系统可以根据用户历史行为或偏好,计算用户向量与项目向量之间的相似度,从而向用户推荐具有相关性的项目。
- 异常检测:在异常检测任务中,向量化可用于将文本数据映射到一个向量空间中,并通过度量文本向量与正常数据之间的距离或相似性来识别与正常行为不同的异常值。
- 多样性测量:通过向量化,可以分析文本数据在向量空间中的分布情况,从而评估文本数据的多样性。
- 分类:向量化能够将文本数据转换为数值型向量表示,从而使得分类算法可以根据文本向量与不同类别之间的相似性来将文本数据分类到最相似的标签或类别中。
而acge模型则是文本向量化模型的一种。
1.2、acge模型简述
在主体框架上,acge_text_embedding模型主要运用了俄罗斯套娃表征学习(Matryoshka Representation Learning,以下简称MRL)这一灵活的表示学习框架。

类似于俄罗斯套娃结构,MRL 产生的嵌入向量也是一个嵌套结构,其旨在创建一个嵌套的、多粒度的表示向量,每个较小的向量都是较大向量的一部分,并且可以独立用于不同的任务。在训练时,MRL根据指定维度[64,128,...,2048,3072]的向量来计算多个loss。使得用户在推理时,可以根据自己的实际需求,输入维度参数,来得到指定维度的向量。
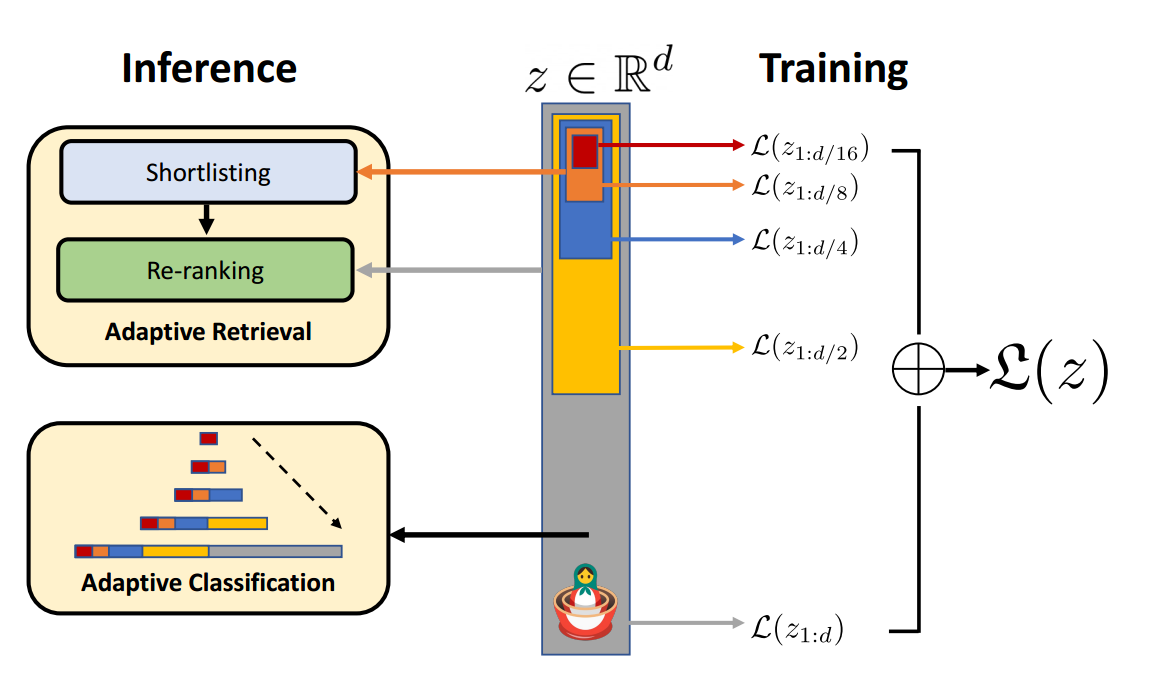
MRL的优化问题可以表示为 min { W ( m ) } m ∈ M , θ F 1 N ∑ i ∈ [ N ] ∑ m ∈ M c m ⋅ L ( W ( m ) ⋅ F ( x i ; θ F ) 1 : m ; y i ) \min_{\{W(m)\}_{m \in M}, \theta_F} \frac{1}{N} \sum_{i \in [N]} \sum_{m \in M} c_m \cdot L(W(m) \cdot F(x_i; \theta_F)_{1:m}; y_i) {W(m)}m∈M,θFminN1i∈[N]∑m∈M∑cm⋅L(W(m)⋅F(xi;θF)1:m;yi)
其中, L : R L × [ L ] → R + L: \mathbb{R}^{L \times [L]} \rightarrow \mathbb{R}^+ L:RL×[L]→R+是多类softmax交叉熵损失函数,而 F ( ⋅ ; θ F ) : X → R d F(\cdot; \theta_F): X \rightarrow \mathbb{R}^d F(⋅;θF):X→Rd是由参数 θ F \theta_F θF参数化的深度神经网络,N是数据点的数量,L是类别的数量。
这种方法的核心思想是学习不同粒度的信息,允许一个嵌入向量在保持准确性和丰富性的同时,适应不同计算资源的需求,并可以无缝地适应大多数表示学习框架,并且可以扩展到多种标准计算机视觉和自然语言处理任务。
运用MRL技术,实现一次训练,获取不同维度的表征,acge模型实现了从粗到细的层次化表示,从而提供了一种在推理和部署时不需要额外成本的灵活表示。另外,具体实践上,为做好不同任务的针对性学习,acge模型使用策略学习训练方式,显著提升了检索、聚类、排序等任务上的性能;引入持续学习训练方式,克服了神经网络存在灾难性遗忘的问题,使模型训练迭代能够达到相对优秀的收敛空间。
二、acge模型效果评估
2.1、acge模型结果复现
下面我们对acge模型进行结果复现,acge模型提供了预训练好的模型供试用与性能复现,首先安装sentence_transformers依赖:
!pip install --upgrade sentence_transformers
- 1
安装完成后,我们可以将源文本source_text设置为“家常菜烹饪指南”,将想要计算相似度的目标文本target_text设置为[“西红柿炒鸡蛋做法”, “农家小炒肉做法”, “上海本帮菜肴传统烹饪技艺”, “汽车维修指南——检测、维修、拆装与保养”]进行测试:
from sentence_transformers import SentenceTransformer
# 若无法访问huggingface,可以在先离线下载模型到本地
model = SentenceTransformer('acge_text_embedding')
source_text = ["家常菜烹饪指南"]
target_text = ["西红柿炒鸡蛋做法", "农家小炒肉做法", "上海本帮菜肴传统烹饪技艺", "汽车维修指南——检测、维修、拆装与保养"]
embs1 = model.encode(source_text, normalize_embeddings=True)
embs2 = model.encode(target_text, normalize_embeddings=True)
similarity = embs1 @ embs2.T
print(similarity)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
也可以通过huggingface上给的API来进行试用:
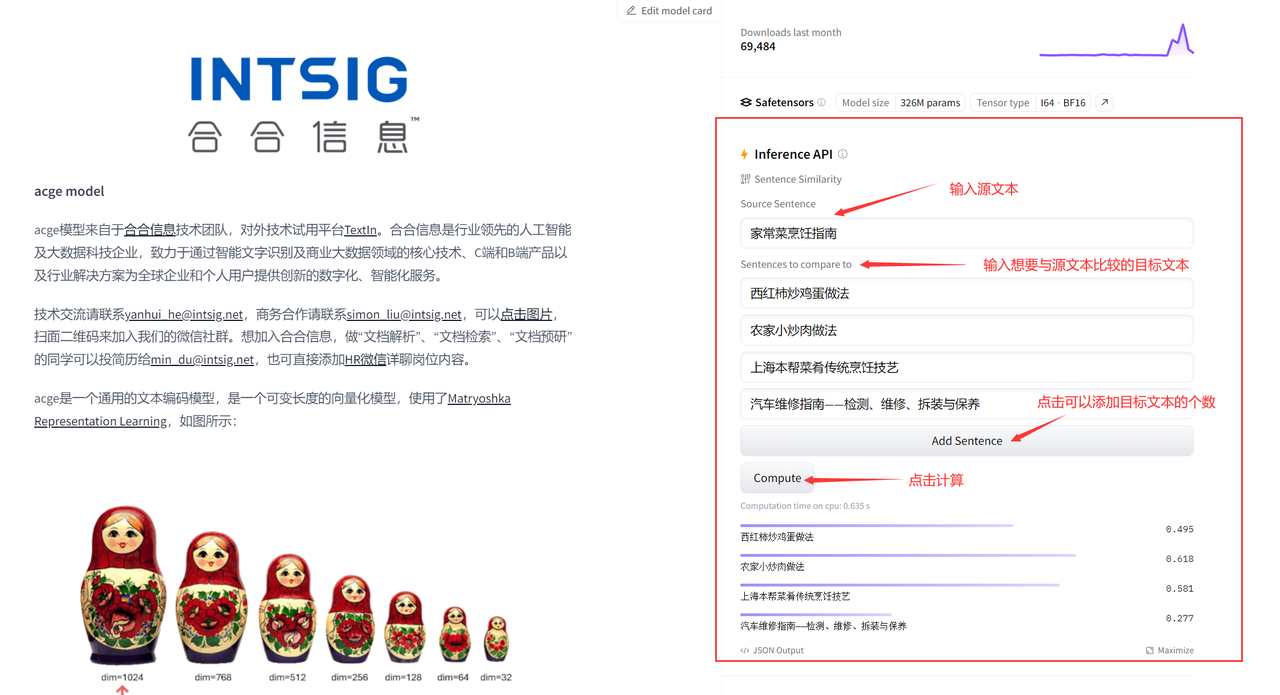
最终计算结果如下:
西红柿炒鸡蛋做法:0.495
农家小炒肉做法:0.618
上海本帮菜肴传统烹饪技艺:0.581
汽车维修指南——检测、维修、拆装与保养:0.277
其中,数值代表了表示源文本与目标文本之间的语义相关性,相似度值越接近于1,文本之间的语义相关性越强,在这个例子中,我们可以看到不同领域的文本与源文本 “家常菜烹饪指南” 之间的相似度评估结果。

对于与烹饪相关的文本(如 “西红柿炒鸡蛋做法”、“农家小炒肉做法”、“上海本帮菜肴传统烹饪技艺”),文本向量化模型表现出了较高的相似度值,这说明了该模型在捕捉烹饪领域文本之间的语义关联性方面的有效性。这种模型对于具有相似主题或语义的文本能够提供准确的相似度评估,这对于文本分类、推荐系统等任务具有重要意义。然而,对于与汽车维修相关的文本,相似度值较低,这是因为该文本与源文本的语义相关性较低。这突显了该模型的另一个优势,即其能够根据文本内容捕捉不同领域的语义特征,从而对文本进行有效的区分。
这说明acge模型能够有效地从文本中提取语义特征,并将其转化为向量表示,并且能够对文本之间的语义相关性进行准确的度量。
2.2、C-MTEB评估复现
C-MTEB是一个全面评估中文向量化模型通用性的基准,其收集35个公开可用的数据集,涵盖了六大类任务,收集了35个公开可用的中文数据集,这些数据集涵盖了分类、聚类、检索、排序、文本相似度、STS等多种任务类型,为中文向量化模型的研究提供了统一的评估标准和有力的支持。
下面复现acge模型在C-MTEB的效果,首先使用pip安装C_MTEB依赖:
pip install -U C_MTEB
- 1
然后输入以下代码对acge_text_embedding进行评估:
import torch import argparse import functools from C_MTEB.tasks import * from typing import List, Dict from sentence_transformers import SentenceTransformer from mteb import MTEB, DRESModel class RetrievalModel(DRESModel): def __init__(self, encoder, **kwargs): self.encoder = encoder def encode_queries(self, queries: List[str], **kwargs) -> np.ndarray: input_texts = ['{}'.format(q) for q in queries] return self._do_encode(input_texts) def encode_corpus(self, corpus: List[Dict[str, str]], **kwargs) -> np.ndarray: input_texts = ['{} {}'.format(doc.get('title', ''), doc['text']).strip() for doc in corpus] input_texts = ['{}'.format(t) for t in input_texts] return self._do_encode(input_texts) @torch.no_grad() def _do_encode(self, input_texts: List[str]) -> np.ndarray: return self.encoder.encode( sentences=input_texts, batch_size=512, normalize_embeddings=True, convert_to_numpy=True ) def get_args(): parser = argparse.ArgumentParser() parser.add_argument('--model_name_or_path', default="acge_text_embedding", type=str) parser.add_argument('--task_type', default=None, type=str) parser.add_argument('--pooling_method', default='cls', type=str) parser.add_argument('--output_dir', default='zh_results', type=str, help='output directory') parser.add_argument('--max_len', default=1024, type=int, help='max length') return parser.parse_args() if __name__ == '__main__': args = get_args() encoder = SentenceTransformer(args.model_name_or_path).half() encoder.encode = functools.partial(encoder.encode, normalize_embeddings=True) encoder.max_seq_length = int(args.max_len) task_names = [t.description["name"] for t in MTEB(task_types=args.task_type, task_langs=['zh', 'zh-CN']).tasks] TASKS_WITH_PROMPTS = ["T2Retrieval", "MMarcoRetrieval", "DuRetrieval", "CovidRetrieval", "CmedqaRetrieval", "EcomRetrieval", "MedicalRetrieval", "VideoRetrieval"] for task in task_names: evaluation = MTEB(tasks=[task], task_langs=['zh', 'zh-CN']) if task in TASKS_WITH_PROMPTS: evaluation.run(RetrievalModel(encoder), output_folder=args.output_dir, overwrite_results=False) else: evaluation.run(encoder, output_folder=args.output_dir, overwrite_results=False)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
在https://huggingface.co/spaces/mteb/leaderboard上可以看到,acge模型已经在目前业界最全面、最权威的中文语义向量评测基准C-MTEB(Chinese Massive Text Embedding Benchmark)的榜单中获得了第一名的成绩。
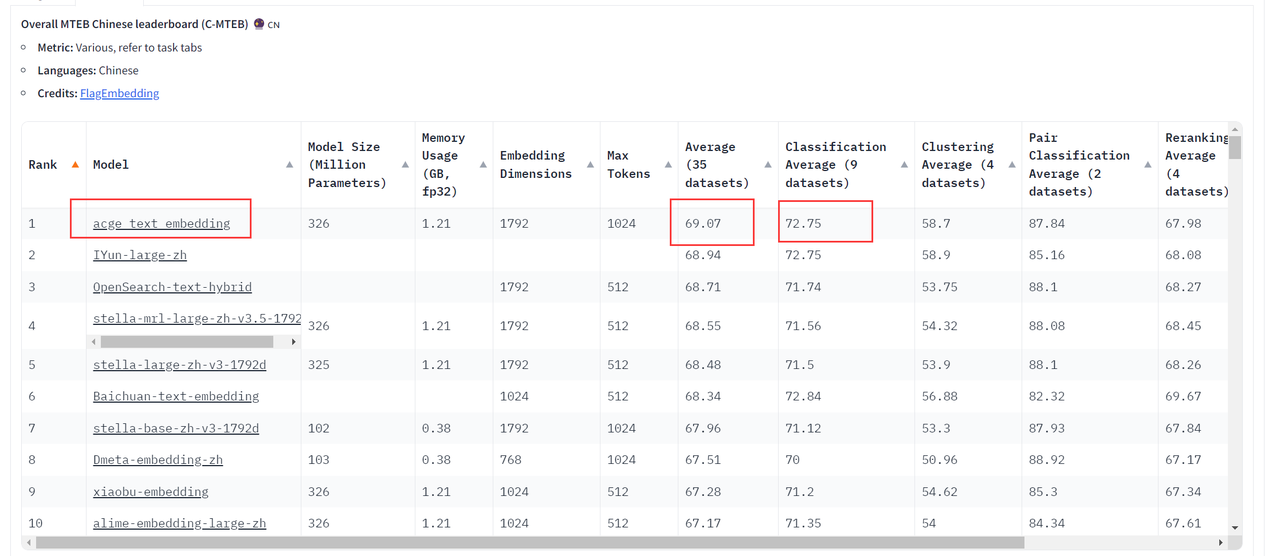
由上表可以看到,acge_text_embedding模型在“Classification Average (9 datasets)”这一列中,acge_text_embedding取得了72.75的分数,显示出在文本分类任务上的优秀性能,在“Average (35 datasets)”这一列中取得了69.07的最高分数,表明在多个数据集上的综合出色表现,另外其相对适中的模型大小和内存大小,在模型规模和计算效率方面达到了良好的平衡。
与Baichuan-text-embedding相比,它在性能上更为出色,同时在处理多样化任务时具有更高的灵活性。而与阿里云的OpenSearch-text-hybrid相比,acge_text_embedding的通用性更强,能够适用于多种文本处理任务。
除此之外,据合合信息开发团队成员介绍,相比于传统的预训练或微调垂直领域模型,acge模型支持在不同场景下构建通用分类模型、提升长文档信息抽取精度,且应用成本相对较低,可帮助大模型在多个行业中快速创造价值,为构建新质生产力提供强有力的技术支持。
三、文本向量化模型的突破与检索增强生成RAG
截至今天,以GPT4、Claude3、Llama 3等大型语言模型在各种任务上已经表现得越来越为出色,然而,在应用当中仍然存在一定局限性:
- 知识的局限性:现有的主流大模型的训练集基本都是构建于网络公开的数据,但是当询问某个最新事件的细节或者关于特定领域的深入知识时,虽然模型会努力生成一个答案,但由于它并没有直接接触过这个事件的相关信息,其细节并不准确。
- 幻觉问题:所有的AI模型的底层原理都是基于数学概率,其模型输出实质上是一系列数值运算,大模型也不例外,所以它有时候会一本正经地胡说八道,这种幻觉问题非常容易导致信息的误判
- 数据安全性:对于企业来说,数据安全至关重要,没有企业愿意承担数据泄露的风险,将自身的私域数据上传第三方平台进行训练。
为了应对这类应用场景,检索增强生成模型RAG应运而生,RAG模型的核心思想是在生成阶段引入检索机制,从预定义的知识库中检索相关信息,并将其合并到生成的文本中。这种方式能够弥补LLM在特定领域或最新知识方面的不足,从而提高了生成文本的准确性和相关性。其主要流程如下:
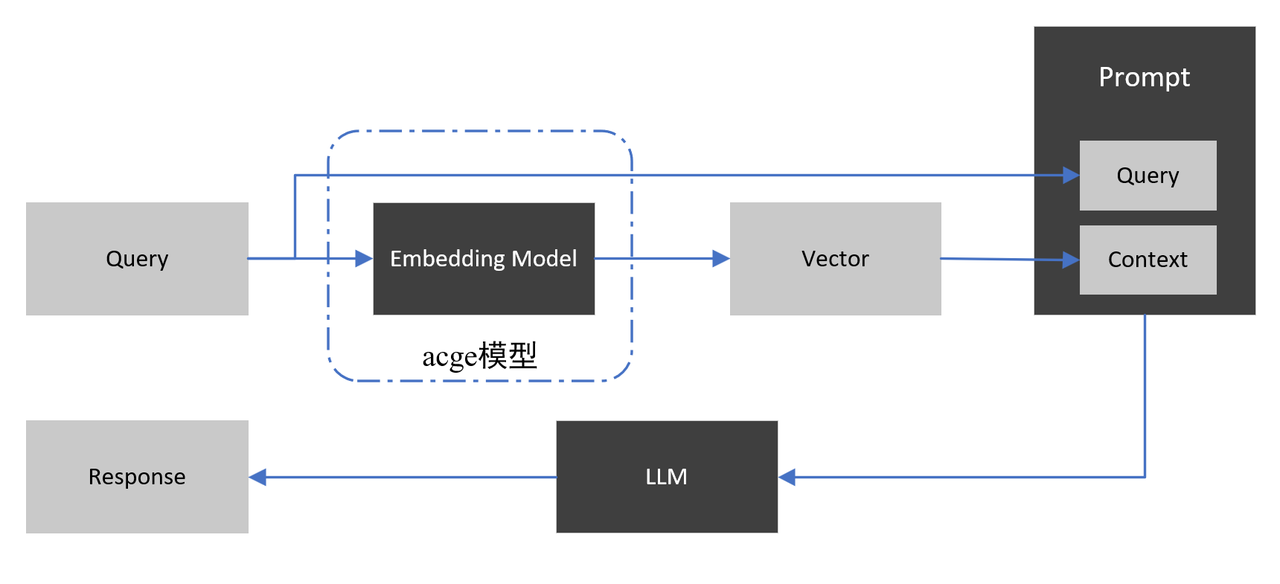
在RAG流程中,向量化模型负责将文档集合中的信息编码成向量表示,并且在用户查询时帮助检索出最相关的文档片段,这些文档片段的内容被并入用户输入中,并指导大语言模型基于这些文档片段生成回应。
用户可能会提出类似于“西红柿炒鸡蛋需要放糖吗?放多少合适?”这样的问题。在这种情况下,向量化模型可以把各种食材、烹饪技巧、口味偏好等关键特征翻译成机器能够理解的“语言”,然后捕捉并理解它们之间的关系,比如它们常常一起出现在哪些菜谱中,这些菜谱又有着怎样的口味特点。这样,通过构建相关领域核心概念间的关联关系,RAG就能轻松地在海量的烹饪数据中检索到相关的信息,从而有更大的机会检索到与用户查询匹配的最相关文档片段。最终生成的答案就更准确、权威,并且更能满足用户的需求。
acge模型正是这样一种向量化模型,其具备良好的文本理解能力和表示学习能力,能够将文档的语义信息转化为高质量的向量表示,有效地捕捉文档的语义和内容信息,从而帮助模型准确地检索到与查询相关的文档片段。
随着acge模型在文本向量化任务上的提升,可以预见的是,幻觉和时效性的问题将得到进一步解决,大模型的可用性也将得到了有效提升,从而更好为诸如金融、咨询、教育等行业的智能客服、知识问答、合规风控、营销顾问等场景提供加持。

可以说,合合信息在深研智能文档处理领域之后,再次突破了文本向量化领域,达到了文本向量化模型的新高度。合合信息TextIn智能文字识别产品基于自研的文字识别技术、智能文档处理技术,能够快速将纸质文档或图片中的文字信息转化为计算机可读的文本格式,在纸质文档电子化、办公文档/报表识别、教育类文本识别、快递面单识别、切边增强、弯曲矫正、阴影处理、印章检测、手写擦除等诸多场景中提供更好的文档管理解决方案,帮助企业实现数字化转型和自动化管理。
欢迎登录textin官网了解详情:https://www.textin.com/?from=market-csdn-cmteb
数十年前,图灵抛出的时代之问“Can machines think?”将人工智能从科幻拉至现实,奠定了后续人工智能发展的基础。之后,无数计算机科学的先驱开始解构人类智能的形成,希望找到机器智能的蛛丝马迹。时至今日,我们又站在了一个新的起点上,机器不仅能够“思考”,更能够通过学习新知识和私有知识库,与我们进行自然而流畅的对话。

