
- 1【Spring Boot】深入解密Spring Boot日志:最佳实践与策略解析_springboot日志策略
- 22021-08-02 uni-app基础教程 环境配置_idea运行uniapp hbuilderx工具未配置
- 3文本情感分析_情感分析,分本长度不一致怎么办
- 4创建图表_【译】用 React 和 D3 创建图表
- 5融合大数据、物联网和人工智能的智慧校园云平台源码 智慧学校源码_大数据教学平台源码
- 6jsp+servlet+jdbc实现对数据库简单的增删改查_jsp连接数据库增删改查
- 7uniapp - [全端兼容] “纯前端“ 将文件上传到阿里云 OSS,全端通用的阿里云 OSS 直传音视频、图片、word、excel、ppt、office 文档(详细示例代码,无需后端稳定可靠)_uniapp上传视频到oss
- 8浅谈共识机制_pow,pos,dpos,pbft的去中心化程度
- 9自然语言处理中的文本分类技术_自然语言处理文本分类算法
- 10安全设备默认地址账密总结_网御星云防火墙默认密码
Text-to-SQL小白入门(九)InstructGPT论文:教你如何训练ChatGPT_txt2sql
赞
踩
论文概述
InstructGPT和ChatGPT 的训练流程基本一致 ,ChatGPT是改进后的InstructGPT,比如InstructGPT是基于GPT-3训练,而ChatGPT是基于GPT-3.5训练。
基本信息
- 英文标题:Training language models to follow instructions with human feedback
- 中文标题:通过人类反馈的指令训练语言模型
- 发表时间:2023年3月 arxiv
- 作者单位:Open AI
- 论文链接:https://arxiv.org/pdf/2203.02155.pdf
- 代码链接:GitHub - openai/following-instructions-human-feedback
学习InstructGPT论文之前,想了解了基本的LLM或者RLHF流程,可以看看组织「eosphoros-ai」(今年的8000+star的开源项目DB-GPT的开源社区)提出的LLM+Text2SQL汇总项目:https://github.com/eosphoros-ai/Awesome-Text2SQL,里面也收集了一些微调SFT(lora, qlora, p-tuning等),RLHF相关的论文(比如RLHF,RRHF,RLTF, RRTF, RLAIF等等),目前也有300+的star,持续更新中,欢迎围观使用star!
摘要
背景
使语言模型更大并不能使它们更好地遵循用户的意图。例如,大型语言模型可能生成不真实的(untruthful)、有害的(toxic)或对用户没有帮助(not helpful)的输出。
贡献/方法
在本文中,作者展示了一种方法,通过使用人类反馈进行微调,在广泛的任务中使语言模型与用户意图保持一致。
- 先使用有监督微调SFT
- 然后收集一批rank排序的模型输出
- 再使用人类反馈的强化学习rlhf微调
- 最终得到的模型叫做InstructGPT
结果:参数量小了100倍,性能差不多。 真实性⬆️、有毒⬇️、精度⬇️(轻微)
结果惊艳:
- 1.3b参数的InstructGPT的模型输出和175b GPT-3的输出很类似。
- 在公共NLP数据集上,InstructGPT模型显示出真实性的改进和有毒输出生成的减少,同时性能下降最小
结论:
尽管InstructGPT仍然会犯一些简单的错误,但结果表明,根据人类反馈进行微调是使语言模型与人类意图保持一致的一个有希望的方向。
结果
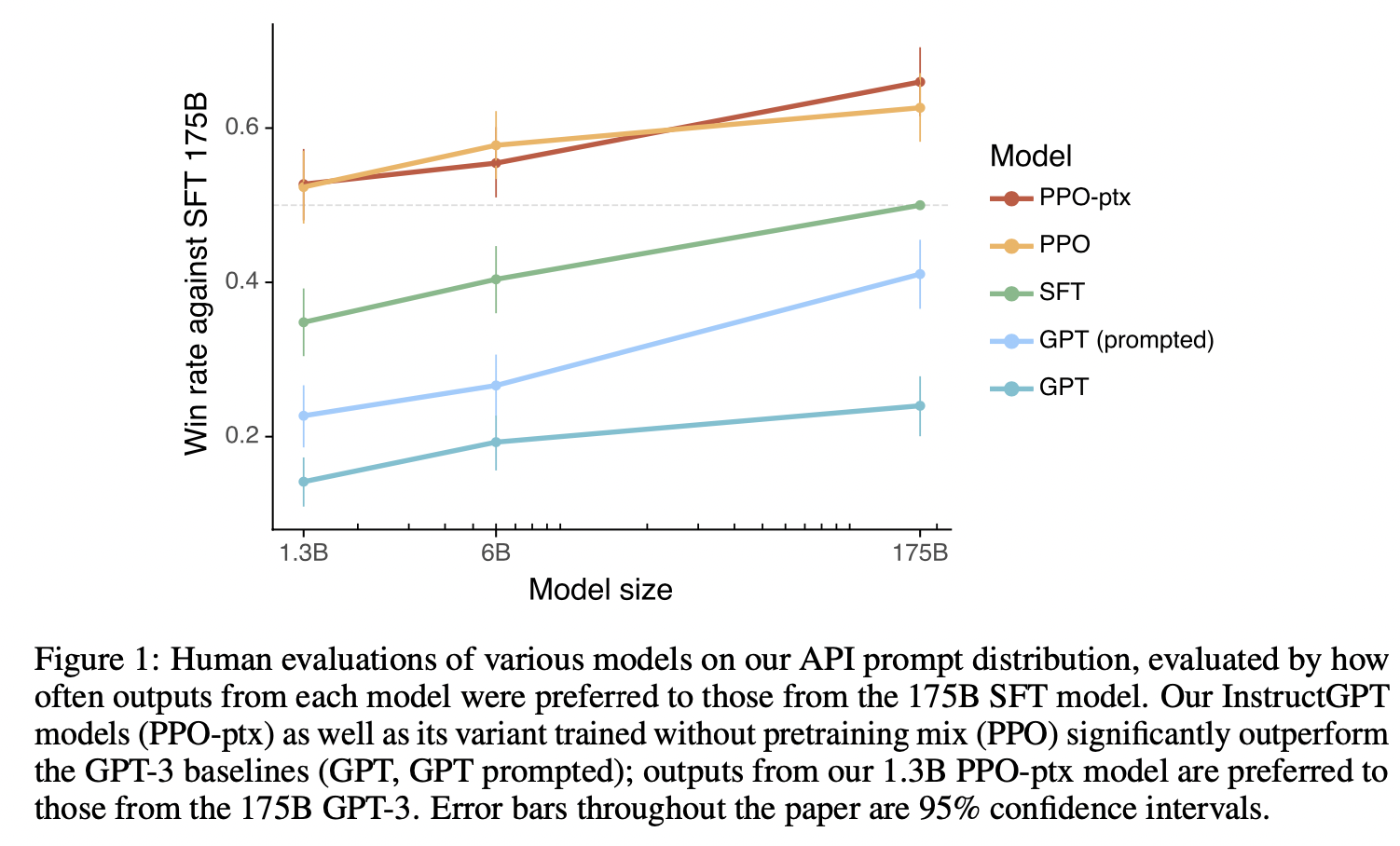
API prompt distribution
- 参数说明:
-
- 横坐标是模型参数大小,纵坐标是和175B GPT SFT比较赢的概率(比如绿色的线条,横坐标为175B时候,赢的概率刚好为0.5,此时就是175B GPT SFT vs 175B GPT SFT )
- GPT就是最普通的模型
- GPT(prompted)就是给几个例子few-shot
- SFT 有监督微调
- PPO 用强化学习
- PPO-ptx: 在PPO算法期间,使用pretraining mix (但是几乎没有什么效果)
- 对比的模型是SFT 175B,可以发现的是1.3B PPO或者PPO-ptx已经超过0.5的概率赢175B,说明方法很有效。
- InstructGPT就是PPO-ptx
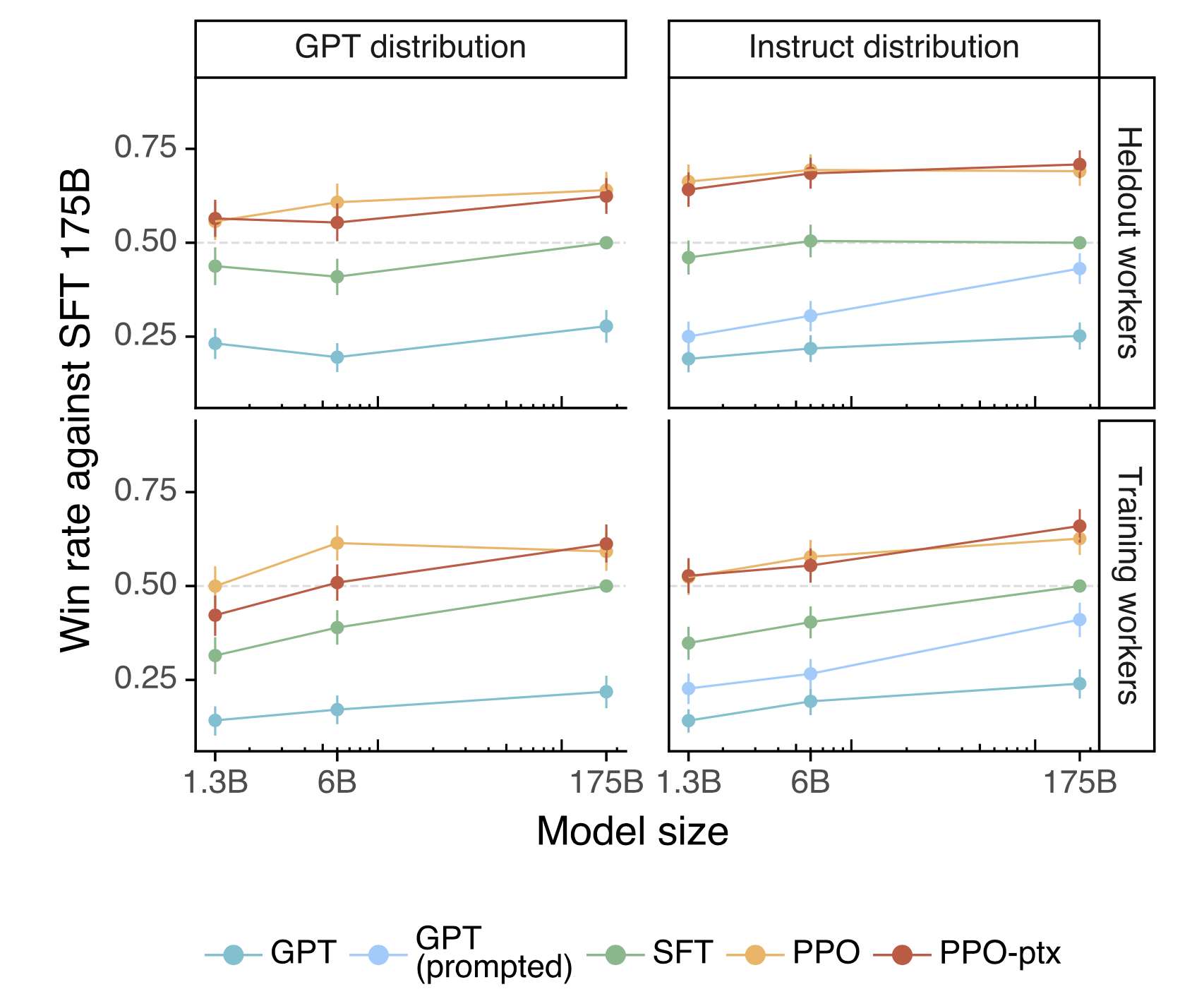
论文还在 public NLP dataset进行了实验,InstructGPT模型在公有NLP数据集上有“对齐税”导致性能下降,可能是因为API prompt 训练的原因。
论文还公布了qualitative results,InstructGPT模型泛化能力很强,具体实验参考原论文。
结论
对齐研究alignment research的影响
- 提高模型对齐度的成本比预训练低。
- InstructGPT泛化能力强,可以推广到没有监督数据的领域。
- 通过微调,可以减少性能下降
- 验证了对齐技术在现实生活中应用
对齐的是什么?
人类偏好,人类价值观 --> 标注者的偏好、OpenAI 研究人员的偏好、API 用户的偏好。
核心方法
RLHF架构图
基础背景知识
- RLHF方法最早是2017年提出:Deep reinforcement learning from human preferences(2017)
- 在2020年RLHF文章「Learning to summarize from human feedback(2020」中,RM训练使用了两个模型在相同input情况下的output进行比较,使用交叉熵损失。——InstructGPT使用KL散度
- PPO算法,也是Open AI 2017年提出的:Proximal policy optimization algorithms(2017),这篇文章的作者「John Schulman」也在InstructGPT作者名单中。
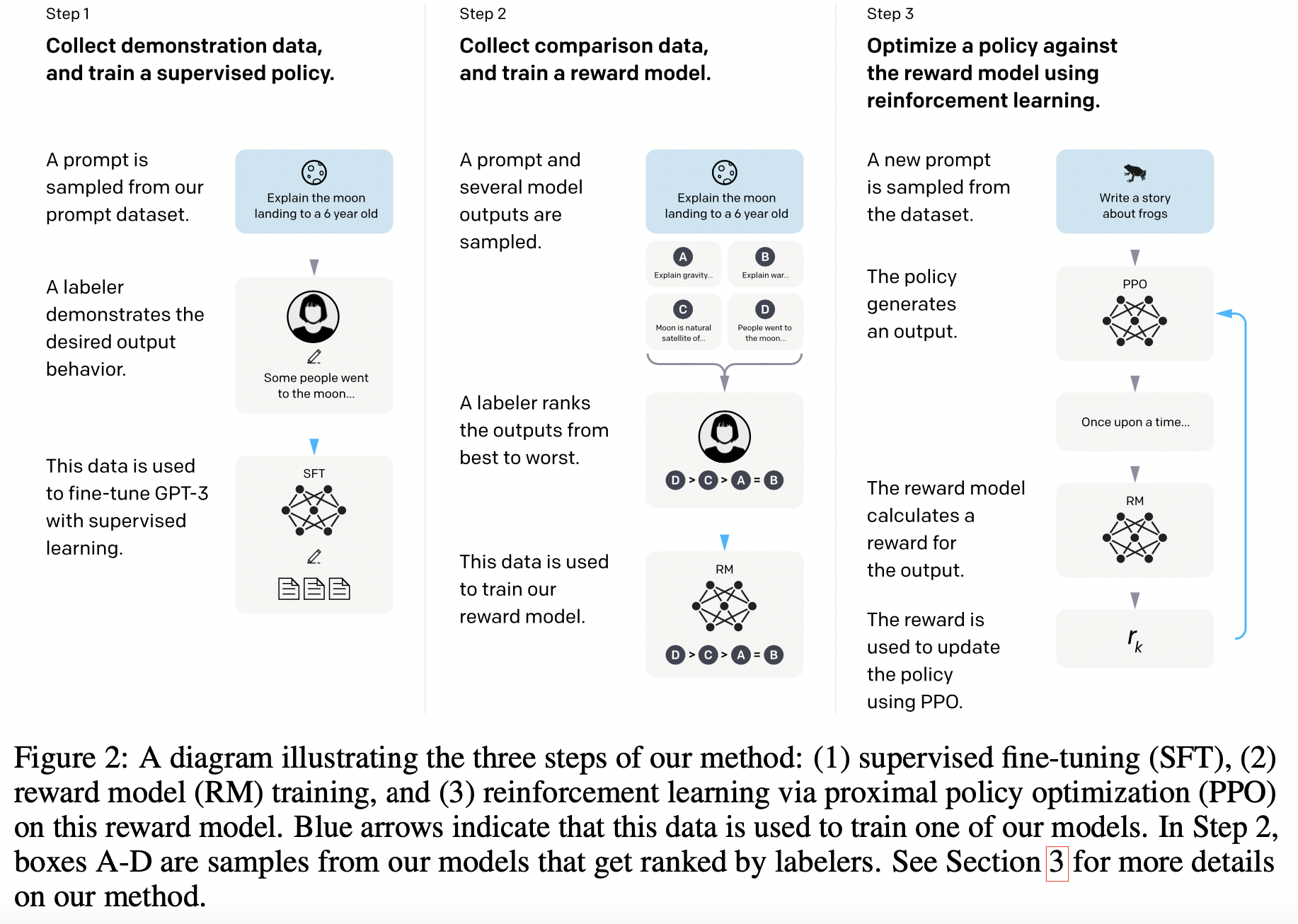
这个图也是经典大图了,RLHF实践参考的范式,RLHF主要分成了3个阶段:
- 第一阶段:SFT
- 第二阶段:RM
- 第三阶段:RL (使用PPO算法:proximal policy optimization 最近策略优化),对第三阶段进行一个简单解释:
-
- 输入一个标注数据,模型经过PPO算法输出一个response
- RM模型对response打分
- 根据打分score更新PPO策略。
PPO算法具体是什么呢?——(留个坑,后续补上)
详情参考论文:Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. (2017). Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347.
SFT
数据格式
- prompt - output
更直观一点,以一个具体的小任务比如Text2SQL为例子,构造的数据集如下所示:
{"prompt": "I want you to act as a SQL terminal in front of an example database, you need only to return the sql command to me.Below is an instruction that describes a task, Write a response that appropriately completes the request.\n\"\n##Instruction:\ndepartment_management contains tables such as department, head, management. Table department has columns such as Department_ID, Name, Creation, Ranking, Budget_in_Billions, Num_Employees. Department_ID is the primary key.\nTable head has columns such as head_ID, name, born_state, age. head_ID is the primary key.\nTable management has columns such as department_ID, head_ID, temporary_acting. department_ID is the primary key.\nThe head_ID of management is the foreign key of head_ID of head.\nThe department_ID of management is the foreign key of Department_ID of department.\n###Input:\nHow many heads of the departments are older than 56 ?\n\n###Response:","output": "SELECT count(*) FROM head WHERE age > 56"}实验参数
参数如下:
- base model——GPT-3
- epoch——16
- lr decay——cosine
- dropout——0.2
选择最终的SFT模型时,是根据验证集上的RM分数。
惊讶点:
- 1个epoch后已经过拟合了,但是为了后续的RM分数,还是多跑几轮epoch

RM
数据格式
- prompy-chosen-rejected
同样的,以Text2SQL任务为例子,构造的数据集如下所示:
{"prompt": "I want you to act as a SQL terminal in front of an example database, you need only to return the sql command to me.Below is an instruction that describes a task, Write a response that appropriately completes the request.\n\"\n##Instruction:\ndepartment_management contains tables such as department, head, management. Table department has columns such as Department_ID, Name, Creation, Ranking, Budget_in_Billions, Num_Employees. Department_ID is the primary key.\nTable head has columns such as head_ID, name, born_state, age. head_ID is the primary key.\nTable management has columns such as department_ID, head_ID, temporary_acting. department_ID is the primary key.\nThe head_ID of management is the foreign key of head_ID of head.\nThe department_ID of management is the foreign key of Department_ID of department.\n###Input:\nHow many heads of the departments are older than 56 ?\n\n###Response:","chosen": "SELECT count(*) FROM head WHERE age > 56","rejected":"SELECT COUNT(head_name) FROM head WHERE age > 56;"}实验参数
- base model: 是GPT-3 SFT之后的模型,但是去掉了最后一层
-
- 因为原始模型输入是prompt,输出是response
- 现在需要模型输入是prompt + response,输出是score
- 参数量仅选择的6B大小
为什么RM模型选6B,不是175B?
-
- 6B 减少计算量
- 175B 训练不稳定
- 标注者,需要对K=4 和 K=9之间的response进行排序,会产生C(k, 2)个两两比较pair
- 一个epoch中,对所有的C(k, 2)比较对训练,一次传播loss
损失函数:

- x代表输入的prompt;y_w代表chosen_data; y_l代表rejected_data; D代表实验数据集
- r_θ(x,y)代表RM模型输入prompt x和response y的输出得分
最后要对奖励归一化,使得平均奖励为0。
RL
数据格式
- prompt-output
和SFT阶段数据格式一致。
{"prompt": "I want you to act as a SQL terminal in front of an example database, you need only to return the sql command to me.Below is an instruction that describes a task, Write a response that appropriately completes the request.\n\"\n##Instruction:\ndepartment_management contains tables such as department, head, management. Table department has columns such as Department_ID, Name, Creation, Ranking, Budget_in_Billions, Num_Employees. Department_ID is the primary key.\nTable head has columns such as head_ID, name, born_state, age. head_ID is the primary key.\nTable management has columns such as department_ID, head_ID, temporary_acting. department_ID is the primary key.\nThe head_ID of management is the foreign key of head_ID of head.\nThe department_ID of management is the foreign key of Department_ID of department.\n###Input:\nHow many heads of the departments are older than 56 ?\n\n###Response:","output": "SELECT count(*) FROM head WHERE age > 56"}实验参数
1.RM可以和RL重复多轮迭代——这样构建更多数据,越来越趋近于人类偏好。
- SFT训练->训练一个RM->训练一个RL->不断重复下面的步骤:
-
- 构建RM数据->重新训练一个RM->重新训练一个RL->
- 构建RM数据->重新训练一个RM->重新训练一个RL->
- 构建RM数据->重新训练一个RM->重新训练一个RL->
2.实践中,大部分的比较数据来源于SFT的数据,少部分数据来源于RL模型的比较数据。
- 继2020文章「Learning to summarize from human feedback」之后,作者再次使用PPO对环境中的SFT模型进行了微调。
- 额外增加了 KL散度。
- 额外增加了预训练梯度——目的是为了减少在NLP数据集上性能倒退,所以InstructGPT模型 == PPO-ptx

- π^RL代表学习到的强化学习RL模型; π^SFT代表SFT阶段训练的模型。
为什么用π表示?为什么用除法表示?这就是强化学习的基本概念
从状态State到动作Action的过程就称之为一个策略Policy,一般用π表示(可以理解为一个函数表示),也就是在强化学习阶段需要找到一个关系:a=π(s) 或者是 π(a|s), a 就是action, s就是state
- D_pretrain代表预训练阶段的数据分布;D_π^RL代表强化学习阶段的数据分布
- r_θ(x,y)代表RM模型输入prompt x和response y的输出得分
- β是控制KL奖励的系数; γ是控制预训练梯度的系数,如果是普通的PPO,那么γ=0
数据收集
之前听一个大学教授的讲座,有个观点很有意思:Open AI做大模型为什么比谷歌强,因为包括transformer在内的一些创新模型大多是谷歌研究的,那为什么Open AI在大模型领域为什么比谷歌强?答:因为Open AI在数据清洗,数据质量把控这方面做的很好。——所以数据是相当重要的!
API数据
为了训练本文的最终InstructGPT
prompt dataset 主要由OpenAI 的API获得,用户和API交互,把这些数据收集起来(前提是用户使用的时候就告知数据要被收集),此时的API是早期的InstructGPT模型,并且没有使用用户在生产中使用API的数据。
API数据分布如下,主要有9类。

那么问题来了?早期的InstructGPT模型的训练数据怎么来?
- 通过人工标注的有监督学习训练得到的
对API收集的数据做了一些处理:
- 去除重复的提示:通过检查公共前缀(感觉回到了leetcode刷题,求两个字符串的最长公共前缀)
- 每个用户不超过200条prompt:应该是避免单独个体的偏好
- 基于用户id,划分train,val,test——这样验证集和测试集就不包含来自训练集中的用户的数据
-
- 比如训练数据用id 1, 2, 3, 4的所有数据
- 测试的数据用id 5的数据。
- 过滤掉了个人身份信息的数据
人工标注数据
主要是为了训练早期的InstructGPT
标注者被要求手写以下三种类型的prompt:
- plain:标记人员提出任意的简单任务,同时保证任务的多样性
- few-shot:标注人员提出一条指令instruction,以及该指令的多个查询/响应对(query/response)
- user-based:标注人员在OpenAI 提供的API中获取用例,标注人员需要给出这些用例相对应的instruction
数据量级
数据中96%以上是英文,其它20个语种例如中文,法语,西班牙语等加起来不到4%,这可能导致InstructGPT/ChatGPT能进行其它语种的生成时,效果应该远不如英文
- SFT 数据,大概13k
- RM 数据,大概33k
- PPO数据,大概31k
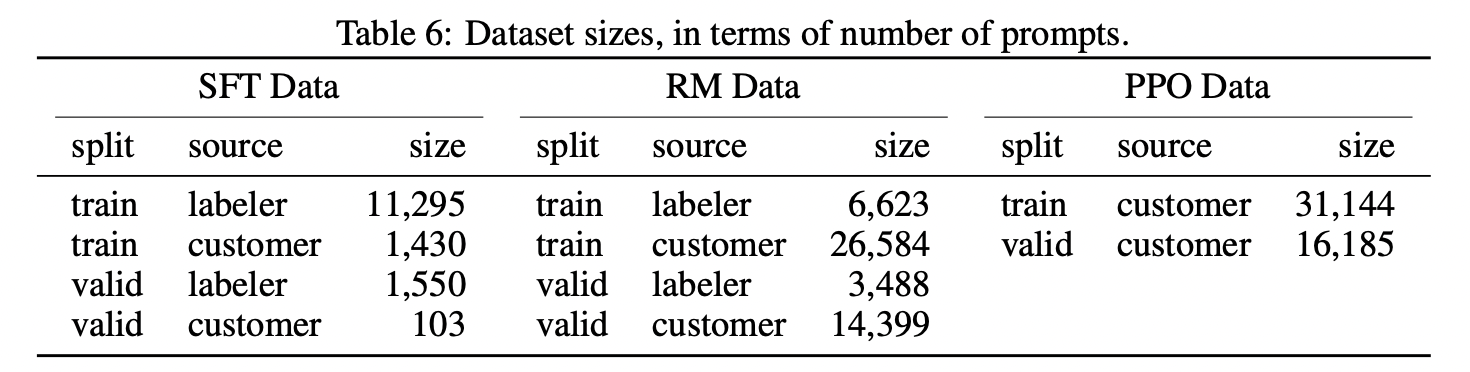
论文还有大量的附录数据详情,可以参考论文原文,比如标注人员分布,数据示例,数据标注等等,不得不说,Open AI数据扎实,正文20页,附录48页,总共68页。
其他文章
Text-to-SQL小白入门(二)Transformer学习
Text-to-SQL小白入门(三)IRNet:引入中间表示SemQL
Text-to-SQL小白入门(四)指令进化大模型WizardLM
Text-to-SQL小白入门(五)开源代码大模型Code Llama
Text-to-SQL小白入门(六)Awesome-Text2SQL项目介绍

